目录
- 第一门课:神经网络和深度学习 (Neural Networks and Deep Learning)
- 第二周:神经网络的编程基础 (Basics of Neural Network programming)
- 2.15 Python 中的广播(Broadcasting in Python)
- 2.16 关于 python _ numpy 向量的说明(A note on python or numpy vectors)
- 2.17(选修)logistic 损失函数的解释(Explanation of logistic regression cost function)
第一门课:神经网络和深度学习 (Neural Networks and Deep Learning)
第二周:神经网络的编程基础 (Basics of Neural Network programming)
2.15 Python 中的广播(Broadcasting in Python)
这是一个不同食物(每 100g)中不同营养成分的卡路里含量表格,表格为 3 行 4 列,列表示不同的食物种类,从左至右依次为苹果,牛肉,鸡蛋,土豆。行表示不同的营养成分,从上到下依次为碳水化合物,蛋白质,脂肪。
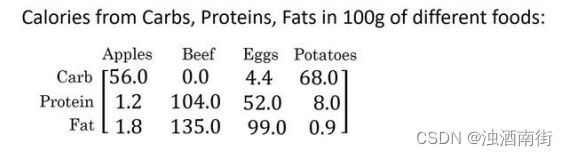
那么,我们现在想要计算不同食物中不同营养成分中的卡路里百分比。
现在计算苹果中的碳水化合物卡路里百分比含量,首先计算苹果(100g)中三种营养成分卡路里总和 56+1.2+1.8 = 59,然后用 56/59 = 94.9%算出结果。
可以看出苹果中的卡路里大部分来自于碳水化合物,而牛肉则不同。
对于其他食物,计算方法类似。首先,按列求和,计算每种食物中(100g)三种营养成分总和,然后分别用不用营养成分的卡路里数量除以总和,计算百分比。那么,能否不使用 for 循环完成这样的一个计算过程呢?
假设上图的表格是一个 3 行 4 列的矩阵𝐴,记为 𝐴3×4,接下来我们要使用 Python 的numpy 库完成这样的计算。我们打算使用两行代码完成,第一行代码对每一列进行求和,第二行代码分别计算每种食物每种营养成分的百分比。
import numpy as np
A = np.array([[56.0,0.0,4.4,68.0],
[1.2,104.0,52.0,8.0],
[1.8,135.0,99.0,0.9]])
# print(A)
cal =A.sum(axis=0)
# print(cal)
percentage=100*A/cal.reshape(1,4)
print(percentage)
下面再来解释一下 A.sum(axis = 0)中的参数 axis。axis 用来指明将要进行的运算是沿着哪个轴执行,在 numpy 中,0 轴是垂直的,也就是列,而 1 轴是水平的,也就是行。
而第二个 A/cal.reshape(1,4)指令则调用了 numpy 中的广播机制。这里使用 3 × 4的矩阵𝐴除以 1 × 4的矩阵𝑐𝑎𝑙。技术上来讲,其实并不需要再将矩阵𝑐𝑎𝑙 reshape(重塑)成1 × 4,因为矩阵𝑐𝑎𝑙本身已经是 1 × 4了。但是当我们写代码时不确定矩阵维度的时候,通常会对矩阵进行重塑来确保得到我们想要的列向量或行向量。重塑操作 reshape 是一个常量时间的操作,时间复杂度是𝑂(1),它的调用代价极低。
在 numpy 中,当一个 4 × 1的列向量与一个常数做加法时,实际上会将常数扩展为一个 4 × 1的列向量,然后两者做逐元素加法。结果就是右边的这个向量。这种广播机制对于行向量和列向量均可以使用。
再看下一个例子。
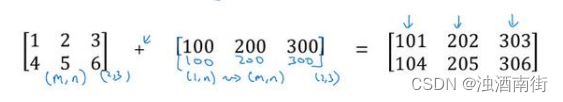
用一个 2 × 3的矩阵和一个 1 × 3 的矩阵相加,其泛化形式是 𝑚 × 𝑛 的矩阵和 1 × 𝑛的矩阵相加。在执行加法操作时,其实是将 1 × 𝑛 的矩阵复制成为 𝑚 × 𝑛 的矩阵,然后两者做逐元素加法得到结果。针对这个具体例子,相当于在矩阵的第一列加 100,第二列加 200,第三列加 300。这就是在前一张幻灯片中计算卡路里百分比的广播机制,只不过这里是除法操作(广播机制与执行的运算种类无关)。
广播机制的一般原则如下:
首先是 numpy 广播机制
如果两个数组的后缘维度的轴长度相符或其中一方的轴长度为 1,则认为它们是广播兼容的。广播会在缺失维度和轴长度为 1 的维度上进行。
总结一下 broadcasting,可以看看下面的图:

总结:广播机制,就是为了尽可能满足矩阵的加减乘除规范,当不满足时,通过复制行或列的值使其满足规则;
2.16 关于 python _ numpy 向量的说明(A note on python or numpy vectors)
本节主要讲 Python 中的 numpy 一维数组的特性,以及与行向量或列向量的区别。并介绍了老师在实际应用中的一些小技巧,去避免在 coding 中由于这些特性而导致的 bug。
Python 的特性允许你使用广播(broadcasting)功能,这是 Python 的 numpy 程序语言库中最灵活的地方。而我认为这是程序语言的优点,也是缺点。优点的原因在于它们创造出语言的表达性,Python 语言巨大的灵活性使得你仅仅通过一行代码就能做很多事情。但是这也是缺点,由于广播巨大的灵活性,有时候你对于广播的特点以及广播的工作原理这些细节不熟悉的话,你可能会产生很细微或者看起来很奇怪的 bug。例如,如果你将一个列向量添加到一个行向量中,你会以为它报出维度不匹配或类型错误之类的错误,但是实际上你会得到一个行向量和列向量的求和。
在 Python 的这些奇怪的影响之中,其实是有一个内在的逻辑关系的。但是如果对 Python不熟悉的话,我就曾经见过的一些学生非常生硬、非常艰难地去寻找 bug。所以我在这里想做的就是分享给你们一些技巧,这些技巧对我非常有用,它们能消除或者简化我的代码中所有看起来很奇怪的 bug。同时我也希望通过这些技巧,你也能更容易地写没有 bug 的 Python和 numpy 代码。
为了演示 Python-numpy 的一个容易被忽略的效果,特别是怎样在 Python-numpy 中构造向量,让我来做一个快速示范。首先设置𝑎 = 𝑛𝑝. 𝑟𝑎𝑛𝑑𝑜𝑚. 𝑟𝑎𝑛𝑑𝑛(5),这样会生成存储在数组 𝑎 中的 5 个高斯随机数变量。之后输出 𝑎,从屏幕上可以得知,此时 𝑎 的 shape(形状)是一个(5, )的结构。这在 Python 中被称作一个一维数组。它既不是一个行向量也不是一个列向量,这也导致它有一些不是很直观的效果。举个例子,如果我输出一个转置阵,最终结果它会和𝑎看起来一样,所以𝑎和𝑎的转置阵最终结果看起来一样。而如果我输出𝑎和𝑎的转置阵的内积,你可能会想:𝑎乘以𝑎的转置返回给你的可能会是一个矩阵。但是如果我这样做,你只会得到一个数。
import numpy as np
a = np.random.rand(5)
print(a.shape)
print(a)
print(np.dot(a,a.T))
结果如下:
(5,)
[0.25952355 0.63937714 0.92832645 0.21007159 0.68871566]
1.856404924677065
所以我建议当你编写神经网络时,不要在它的 shape 是(5, )还是(𝑛, )或者一维数组时使用数据结构。相反,如果你设置 𝑎 为(5,1),那么这就将置于 5 行 1 列向量中。在先前的操作里 𝑎 和 𝑎 的转置看起来一样,而现在这样的 𝑎 变成一个新的 𝑎 的转置,并且它是一个行向量。请注意一个细微的差别,在这种数据结构中,当我们输出 𝑎 的转置时有两对方括号,而之前只有一对方括号,所以这就是 1 行 5 列的矩阵和一维数组的差别。
import numpy as np
a = np.random.rand(5,1)
print(a.shape)
print(a)
print(np.dot(a,a.T))
(5, 1)
[[0.59478491]
[0.66576404]
[0.05868431]
[0.04864699]
[0.63411704]]
[[0.35376909 0.3959864 0.03490454 0.02893449 0.37716325]
[0.3959864 0.44324176 0.0390699 0.03238742 0.42217232]
[0.03490454 0.0390699 0.00344385 0.00285481 0.03721272]
[0.02893449 0.03238742 0.00285481 0.00236653 0.03084788]
[0.37716325 0.42217232 0.03721272 0.03084788 0.40210442]]
就我们刚才看到的,再进一步说明。首先我们刚刚运行的命令是这个 (𝑎 =𝑛𝑝. 𝑟𝑎𝑛𝑑𝑜𝑚. 𝑟𝑎𝑛𝑑𝑛(5)),而且它生成了一个数据结构 (𝑎. 𝑠ℎ𝑎𝑝𝑒),𝑎. 𝑠ℎ𝑎𝑝𝑒是(5, ),一个有趣的东西。这被称作 𝑎 的一维数组,同时这也是一个非常有趣的数据结构。它不像行向量和列向量那样表现的很一致,这也让它的一些影响不那么明显。所以我建议,当你在编程练习或者在执行逻辑回归和神经网络时,你不需要使用这些一维数组。
我写代码时还有一件经常做的事,那就是如果我不完全确定一个向量的维度(dimension),我经常会扔进一个断言语句(assertion statement)。像这样,去确保在这种情况下是一个(5,1)向量,或者说是一个列向量。这些断言语句实际上是要去执行的,并且它们也会有助于为你的代码提供信息。所以不论你要做什么,不要犹豫直接插入断言语句。如果你不小心以一维数组来执行,你也能够重新改变数组维数 𝑎 = 𝑟𝑒𝑠ℎ𝑎𝑝𝑒,表明一个(5,1)数组或者一个(1,5)数组,以致于它表现更像列向量或行向量。
我有时候看见学生因为一维数组不直观的影响,难以定位 bug 而告终。通过在原先的代码里清除一维数组,我的代码变得更加简洁。而且实际上就我在代码中表现的事情而言,我从来不使用一维数组。因此,要去简化你的代码,而且不要使用一维数组。总是使用 𝑛 × 1维矩阵(基本上是列向量),或者 1 × 𝑛 维矩阵(基本上是行向量),这样你可以减少很多assert 语句来节省核矩阵和数组的维数的时间。另外,为了确保你的矩阵或向量所需要的维数时,不要羞于 reshape 操作。
总之,我希望这些建议能帮助你解决一个 Python 中的 bug,从而使你更容易地完成练习。
2.17(选修)logistic 损失函数的解释(Explanation of logistic regression cost function)
在前面的视频中,我们已经分析了逻辑回归的损失函数表达式,在这节选修视频中,我将给出一个简洁的证明来说明逻辑回归的损失函数为什么是这种形式。
回想一下,在逻辑回归中,需要预测的结果 y ^ \hat{y} y^,可以表示为 y ^ = σ ( w T x + b ) \hat{y} = σ(w^Tx + b) y^=σ(wTx+b),𝜎是我们熟悉的𝑆型函数 σ ( z ) = σ ( w T x + b ) = 1 1 + e − z σ(z) = σ(w^Tx + b) =\frac{1}{1+e^{-z}} σ(z)=σ(wTx+b)=1+e−z1。我们约定 y ^ = p ( y = 1 ∣ x ) \hat{y} = p(y = 1|x) y^=p(y=1∣x) ,即算法的输出 y ^ \hat{y} y^ 是给定训练样本 𝑥 条件下 𝑦 等于 1 的概率。
换句话说,如果y = 1,在给定训练样本 𝑥 条件下
y
=
y
^
y = \hat{y}
y=y^;
反过来说,如果y = 0,在给定训练样本𝑥条件下 (
y
=
1
−
y
^
y = 1 − \hat{y}
y=1−y^),
因此,如果
y
^
\hat{y}
y^ 代表y = 1 的概率,那么
1
−
y
^
1-\hat{y}
1−y^ 就是 y = 0的概率。
接下来,我们就来分析这两个条件概率公式。
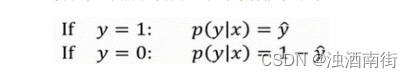
这两个条件概率公式定义形式为 𝑝(𝑦|𝑥)并且代表了 𝑦 = 0 或者 𝑦 = 1 这两种情况,我们可以将这两个公式合并成一个公式。需要指出的是我们讨论的是二分类问题的损失函数,因此,𝑦的取值只能是 0 或者 1。上述的两个条件概率公式可以合并成如下公式:
接下来我会解释为什么可以合并成这种形式的表达式:(
1
−
y
^
1 − \hat{y}
1−y^)的(1 − y)次方这行表达
p
(
y
∣
x
)
=
y
^
y
(
1
−
y
^
)
(
1
−
y
)
p(y|x) =\hat{y}^y (1-\hat{y})^{(1-y)}
p(y∣x)=y^y(1−y^)(1−y)
式包含了上面的两个条件概率公式,我来解释一下为什么。

第一种情况,假设 y = 1,由于y = 1,那么
(
y
^
)
y
=
y
^
(\hat{y})^y = \hat{y}
(y^)y=y^,因为
y
^
\hat{y}
y^的 1 次方等于
y
^
\hat{y}
y^,
1
−
(
1
−
y
^
)
(
1
−
y
)
1 −(1 − \hat{y})^{(1−y)}
1−(1−y^)(1−y)的指数项(1 − y)等于 0,由于任何数的 0 次方都是 1,
y
^
\hat{y}
y^乘以 1 等于
y
^
\hat{y}
y^。因此当𝑦 = 1时
p
(
y
∣
x
)
=
y
^
p(y|x) = \hat{y}
p(y∣x)=y^(图中绿色部分)。
第二种情况,当 y = 0 时 p(y|x) 等于多少呢? 假设y = 0, y ^ \hat{y} y^的𝑦次方就是 y ^ \hat{y} y^ 的 0 次方,任何数的 0 次方都等于 1,因此 p ( y ∣ x ) = 1 × ( 1 − y ^ ) ( 1 − y ) p(y|x) =1×(1 − \hat{y})^(1−y ) p(y∣x)=1×(1−y^)(1−y),前面假设 y = 0 因此(1 −𝑦)就等于 1,因此 p ( y ∣ x ) = 1 × ( 1 − y ^ ) p(y|x) =1×(1 − \hat{y}) p(y∣x)=1×(1−y^)。因此在这里当y = 0时, p ( y ∣ x ) = 1 − y ^ p(y|x) = 1− \hat{y} p(y∣x)=1−y^。这就是这个公式(第二个公式,图中紫色字体部分)的结果。
因此,刚才的推导表明
p
(
y
∣
x
)
=
y
^
(
y
)
(
1
−
y
^
)
(
1
−
y
)
p(y|x) = \hat{y}^{(y)}(1 − \hat{y})^{(1−y)}
p(y∣x)=y^(y)(1−y^)(1−y),就是 p(y|x) 的完整定义。由于 log 函数是严格单调递增的函数,最大化 log(p(y|x)) 等价于最大化 p(y|x) 并且地计算p(y|x) 的 log 对数,就是计算
l
o
g
(
y
^
(
y
)
(
1
−
y
^
)
(
1
−
y
)
)
log(\hat{y}^{(y)}(1 −\hat{y})^{(1−y)})
log(y^(y)(1−y^)(1−y)) (其实就是将 p(y|x) 代入),通过对数函数化简为:
y
l
o
g
y
^
+
(
1
−
y
)
l
o
g
(
1
−
y
^
)
ylog\hat{y} + (1-y)log(1-\hat{y})
ylogy^+(1−y)log(1−y^)
而这就是我们前面提到的损失函数的负数 ( − L ( y ^ , y ) ) (−L(\hat{y} , y)) (−L(y^,y)),前面有一个负号的原因是当你训练学习算法时需要算法输出值的概率是最大的(以最大的概率预测这个值),然而在逻辑回归中我们需要最小化损失函数,因此最小化损失函数与最大化条件概率的对数log(p(y|x)) 关联起来了,因此这就是单个训练样本的损失函数表达式。
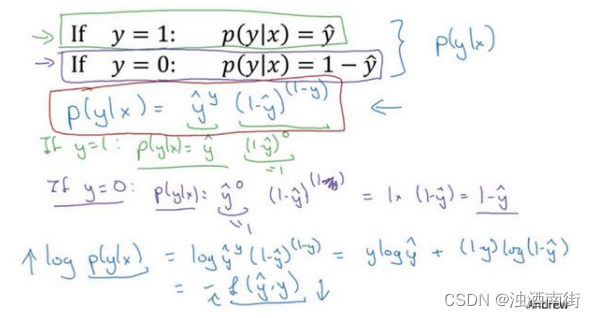
在 𝑚个训练样本的整个训练集中又该如何表示呢,让我们一起来探讨一下。让我们一起来探讨一下,整个训练集中标签的概率,更正式地来写一下。假设所有的训练样本服从同一分布且相互独立,也即独立同分布的,所有这些样本的联合概率就是每个样本概率的乘积:

如果你想做最大似然估计,需要寻找一组参数,使得给定样本的观测值概率最大,但令这个概率最大化等价于令其对数最大化,在等式两边取对数:
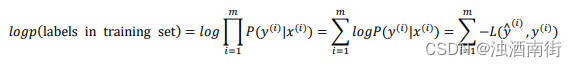
在统计学里面,有一个方法叫做最大似然估计,即求出一组参数,使这个式子取最大值,也就是说,使得这个式子取最大值,
∑ i = 1 m − L ( y ^ ( i ) , y ( i ) ) \sum_{i=1}^m−L(\hat{y}^{(i)}, y^{(i)}) ∑i=1m−L(y^(i),y(i)) ,可以将负号移到求和符号的外面, − ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) -\sum_{i=1}^mL(\hat{y}^{(i)}, y^{(i)}) −∑i=1mL(y^(i),y(i)),这样我们就推导出了
前面给出的 logistic 回归的成本函数 J ( w , b ) = ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) J(w, b) =\sum_{i=1}^mL(\hat{y}^{(i)}, y^{(i)}) J(w,b)=∑i=1mL(y^(i),y(i))。

由于训练模型时,目标是让成本函数最小化,所以我们不是直接用最大似然概率,要去掉这里的负号,最后为了方便,可以对成本函数进行适当的缩放,我们就在前面加一个额外的常数因子 1 m \frac{1}{m} m1,即:
J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) J(w, b) =\frac{1}{m}\sum_{i=1}^mL(\hat{y}^{(i)}, y^{(i)}) J(w,b)=m1i=1∑mL(y^(i),y(i))
总结一下,为了最小化成本函数𝐽(𝑤, 𝑏),我们从 logistic 回归模型的最大似然估计的角度出发,假设训练集中的样本都是独立同分布的条件下。尽管这节课是选修性质的,但还是感谢观看本节视频。我希望通过本节课您能更好地明白逻辑回归的损失函数,为什么是那种形式,明白了损失函数的原理,希望您能继续完成课后的练习,前面课程的练习以及本周的测验,在课后的小测验和编程练习中,祝您好运。