一.map介绍和使用
map是一种无序的基于key-value的数据结构,Go语言的map是引用类型,必须初始化才可以使用。
1. 定义
Go语言中,map类型语法如下:
map[KeyType]ValueType- KeyType表示键类型
- ValueType表示值类型
map类型的变量默认初始值为nil,需要使用make函数来分配内存。语法为:
make(map[KeyType]ValueType, [cap])
map[KeyType]ValueType{} //底层也是使用的make
map[KeyType]Value{ //底层也是使用的make
key:value,
key:value,
...
}其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量。
可以使用len()内置函数来获取map键值对的个数。
注意:map保存的键值对中,键不能被修改,只能修改值。
2.基本使用
package main
import "fmt"
func main() {
scoreMap := make(map[string]int, 8)
scoreMap["张三"] = 100
scoreMap["小明"] = 90
fmt.Println(scoreMap)
fmt.Printf("key num is %d\n", len(scoreMap))
fmt.Println(scoreMap["小明"])
fmt.Printf("type(scoreMap)=%T\n", scoreMap)
}
map也支持在声明时填充元素:
package main
import "fmt"
func main() {
userInfo := map[string]string{
"username": "zhansan",
"password": "123456",
}
fmt.Println(userInfo)
}3. 判断某个键是否存在
Go语言中有个判断map中的键是否存在的特殊写法:
value, ok := map[key]例子:
package main
import "fmt"
func main() {
userInfo := map[string]string{
"username": "zhansan",
"passward": "123456",
}
value, ok := userInfo["passward"]
if ok {
fmt.Println(value)
} else {
fmt.Println("passward is not exit")
}
value, ok = userInfo["sex"]
if ok {
fmt.Println(value)
} else {
fmt.Println("sex is not exit")
}
}
4. map的遍历
遍历key和value:
package main
import "fmt"
func main() {
scoreMap := make(map[string]int, 8)
scoreMap["小明"] = 100
scoreMap["张三"] = 80
scoreMap["李四"] = 60
for key, value := range scoreMap {
fmt.Printf("scoreMap[%s] = %d\n", key, value)
}
}
只遍历key:

注意:遍历map时的元素顺序与添加键值对的顺序无关。
5. 删除键值对
使用delete()内置函数从map中删除一组键值对,格式如下:
delete(map, key)
//map:为需要删除键值对的map
//key:表示要删除键值对的键package main
import "fmt"
func main() {
scoreMap := make(map[string]int, 8)
scoreMap["小明"] = 100
scoreMap["张三"] = 80
scoreMap["李四"] = 60
value, ok := scoreMap["李四"]
if ok {
fmt.Println(value)
} else {
fmt.Println("李四 is not exit")
}
//删除键值对
delete(scoreMap, "李四")
value, ok = scoreMap["李四"]
if ok {
fmt.Println(value)
} else {
fmt.Println("李四 is not exit")
}
}
6. 按照指定顺序遍历map
实际时先获取到所有的键,将键设置成指定顺序,再通过键来遍历map。
package main
import (
"fmt"
"math/rand"
"sort"
"time"
)
func main() {
rand.Seed(time.Now().UnixNano()) //初始化随机种子
scoreMap := make(map[string]int, 200)
for i := 0; i < 100; i++ {
key := fmt.Sprintf("stu%02d", i)
scoreMap[key] = rand.Intn(100) //获取0-100的随机数
//fmt.Println(key, scoreMap[key])
}
keys := make([]string, 0, 200)//保存key
//按照排序后的key遍历scoreMap
for key := range scoreMap {
keys = append(keys, key)
}
//fmt.Println(keys)
sort.Strings(keys) //对keys进行排序
for _, key := range keys {
fmt.Printf("scoreMap[%s] = %d\n", key, scoreMap[key])
}
}7. 元素为map类型的切片
package main
import "fmt"
func main() {
mapSlice := make([]map[string]string, 3, 10) //并没有为map分配地址空间
for index, val := range mapSlice {
fmt.Printf("mapSlice[%d] = %v\n", index, val)
}
//分配地址空间
for index, _ := range mapSlice {
mapSlice[index] = make(map[string]string, 10)
}
fmt.Println("---------插入键值对后---------")
//插入键值对
mapSlice[0]["name"] = "张三"
mapSlice[0]["passwd"] = "123123"
mapSlice[1]["name"] = "李四"
mapSlice[1]["passwd"] = "321321"
mm := map[string]string{
"name": "小明",
"passwd": "123465",
}
mapSlice = append(mapSlice, mm)
for index, val := range mapSlice {
fmt.Printf("mapSlice[%d] = %v\n", index, val)
}
}
8. 值为切片类型的map
package main
import "fmt"
func main() {
sliceMap := make(map[string][]string, 10) //没有为slice分配空间
sliceMap["中国"] = make([]string, 0, 10)
sliceMap["中国"] = append(sliceMap["中国"], "北京", "上海", "长沙")
key := "美国"
value, ok := sliceMap[key]
if !ok {
value = make([]string, 0)
}
value = append(value, "芝加哥", "华盛顿")
sliceMap[key] = value
for key, val := range sliceMap {
fmt.Printf("sliceMap[%s] = %v\n", key, val)
}
}
二.map底层原理
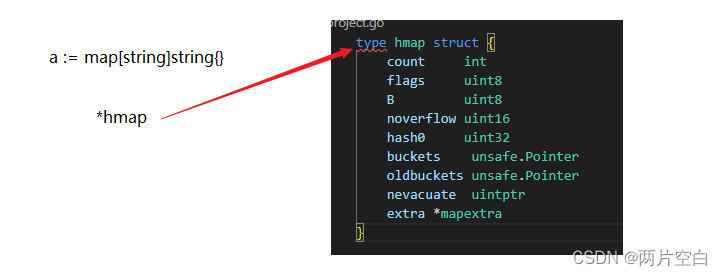
Go语言的map底层数据结构为哈希表(散列表),但是与C++的哈希表实现不同。想要了解Go语言map的底层实现,需要先了解两个重要的数据结构 hmap和bmap。
2.1 map头部数据结构——hmap
hmap中有几个重要的属性:
- count:记录了map中实际元素的个数
- B:控制哈希桶的个数为2^B个
- buckets:是一个指向长度为2^B大小的类型为bmap的数组
- oldbuckets:与buckets一样也是指向一个多桶的数组,不同的是oldbuckets指向的是旧桶的地址,当oldbuckets不为空时,表示map正处于扩容阶段。
type hmap struct {
// map中元素的个数,使用len返回就是该值
count int
// 状态标记
// 1: 迭代器正在操作buckets
// 2: 迭代器正在操作oldbuckets
// 4: go协程正在像map中写操作
// 8: 当前的map正在增长,并且增长的大小和原来一样
flags uint8
// buckets桶的个数为2^B
B uint8
// 溢出桶的个数
noverflow uint16
// key计算hash时的hash种子
hash0 uint32
// 指向的是桶的地址
buckets unsafe.Pointer
// 旧桶的地址,当map处于扩容时旧桶才不为nil
oldbuckets unsafe.Pointer
//扩容之后数据迁移的计数器,记录下次迁移的位置,当nevacuate>旧桶元素个数,数据迁移完
nevacuate uintptr
// 额外的map字段,存储溢出桶信息
// 这个字段是为了优化GC扫描而设计的。当key和value均不包含指针,并且都可以inline时使用。extra是指向mapextra类型的指针。
extra *mapextra
}创建一个map实际是创建一个指针,指向hmap结构。
mapextra结构:
如果一个哈希表要分配桶的数目大于2^4个,就认为使用溢出桶的几率比较大,就会预分配2^(B-4)个溢出桶备用,这些溢出桶与常规桶内存中是连续的,只是前2^B个作为常规桶。
type mapextra struct {
// 如果 key 和 value 都不包含指针,并且可以被 inline(<=128 字节)
// 就使用 hmap的extra字段 来存储 overflow buckets,这样可以避免 GC 扫描整个 map
// 然而 bmap.overflow 也是个指针。这时候我们只能把这些 overflow 的指针
// 都放在 hmap.extra.overflow 和 hmap.extra.oldoverflow 中了
// overflow 包含的是 hmap.buckets 的 overflow 的 buckets
// oldoverflow 包含扩容时的 hmap.oldbuckets 的 overflow 的 bucket
overflow *[]*bmap //记录已使用的溢出桶的地址
oldoverflow *[]*bmap //扩容阶段旧桶使用的溢出桶地址
// 指向空闲的 overflow bucket 的指针
nextOverflow *bmap //指向下一个空闲溢出桶
}2.2 bmap
bmap是每一个桶的数据结构,每一个bmap包含8个key和value。
type bmap struct {
tophash [bucketCnt]uint8
// len为8的数组,用来快速定位key是否在这个bmap中
// 一个桶最多8个槽位,如果key所在的tophash值在tophash中,则代表该key在这个桶中
}上面是bmap的静态结构,在编译过程中runtime.bmap会扩展成以下结构:
- topbits :用来快速定位桶中键值对的位置。
- keys:键值对的键
- values:键值对的值
- overflow:当8个key满的时候,需要新创建一个桶,overflow保存下一个桶的地址。
细节:
这里将键和键保存到了一起,值和值保存在了一起,为什么不讲键和值保存在一起?
因为键和值的类型可能不同,结构体内存对齐会浪费空间。
type bmap struct{
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr // 内存对齐使用,可能不需要
overflow uintptr // 当bucket 的8个key 存满了之后
// overflow 指向下一个溢出桶 bmap,
// overflow是uintptr而不是*bmap类型,保证bmap完全不含指针,是为了减少gc,溢出桶存储到extra字段中
}
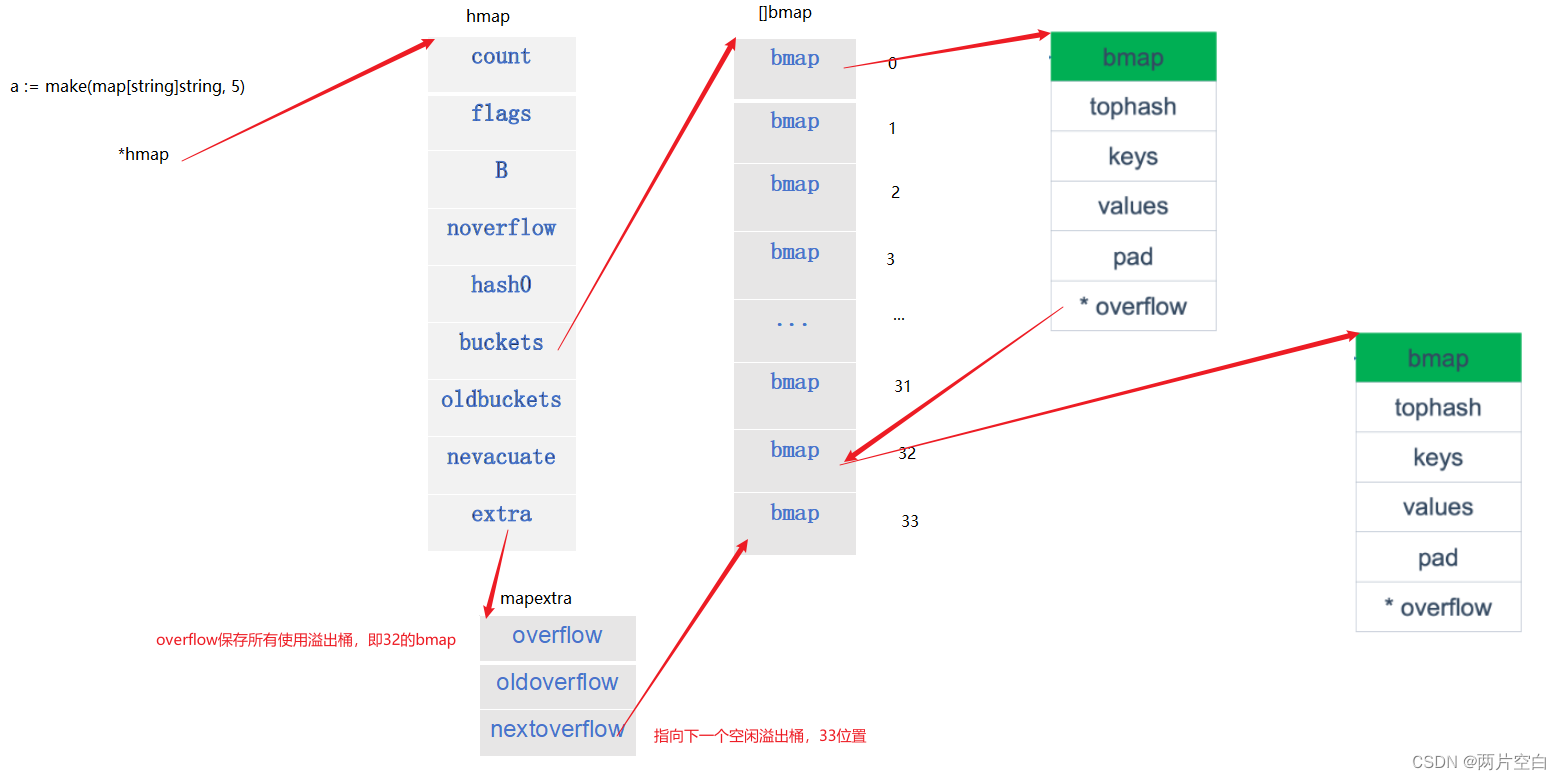
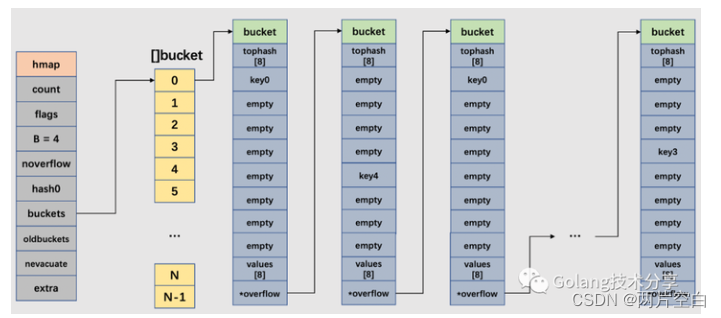
2.3 整体结构示意图
- 如下图,创建一个容量为5的map,此时B=5,分配桶数为2^5=32个(为[]bmap下标0-31),则备用溢出桶数为2^(5-4)=2个(为[]bmap下标32,33)。
- 此时,0号的bmap桶满了,overflow指向下一个溢出桶地址,即[]bmap下标为32位置。
- hmap中的noverflow表示使用溢出桶数量,这里为1,extra字段记录溢出桶mapextra结构体。
- mapextra中的overflow保存使用的溢出桶,nextoverflow指向下一个空闲溢出桶33号。
创建一个map,Go语言底层实际调用的是makemap函数,主要做的工作就是初始化hmap结构体的各个字段。比如:计算B的大小,设置哈希种子hash0,给buckets分配内存等。
func makemap(t *maptype, hint int, h *hmap) *hmap {
//计算内存空间和判断是否内存溢出
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
//计算出指数B,那么桶的数量表示2^B
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
if h.B != 0 {
var nextOverflow *bmap
//根据B去创建对应的桶和溢出桶
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
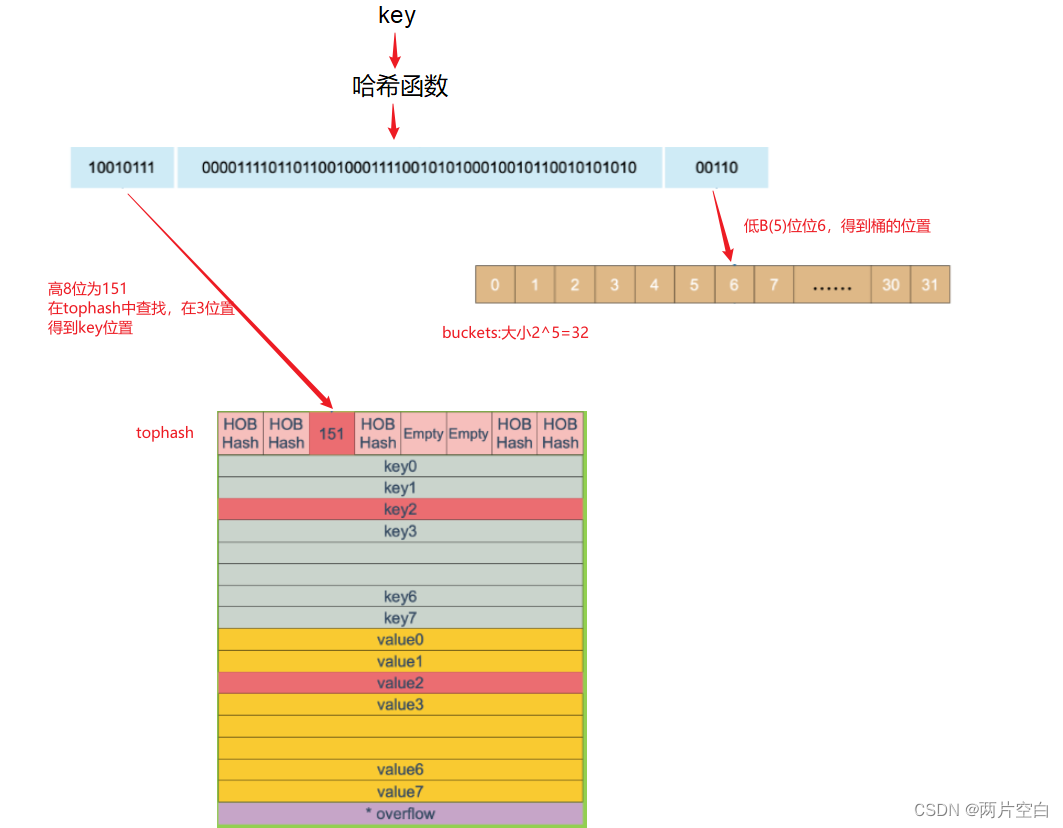
2.4 key定位原理
key通过哈希计算后得到哈希值,哈希值的低B位用于确定桶,哈希值的高8位,用于在一个独立的桶中找到键的位置。
例子:
当在6号buckets中每有找到对应的tophash,并且overflow不为空,还需要继续到overflow指向的buckets中的tophash中查找,直到找到或者所有的key槽位都找遍,包括该buckets下的所有溢出桶(overflow)。
2.5 插入元素
- 插入
key通过哈希函数得到哈希值,通过低B位确定桶位置,在桶中按顺序找空位置,找到后,将高8位保存在tophash中,key和value保存到keys和values中。如果当前桶中没有空闲位置,查看是否有溢出桶,有的话,在溢出桶中找空位置保存。没有溢出桶,添加溢出桶,将数据保存到第一个空位置。
- 哈希冲突
当两个不同的key键通过哈希函数落到了同一个桶中,这时就发生了哈希冲突。
Go语言的解决办法是链地址法:由于桶(bmap)的数据结构,一个桶保存8个键和值。在桶中按顺序寻找第一个空位,若有空位,则将其置于其中;若没有空位,判断是否有溢出桶;若有溢出桶,在溢出桶中寻找空位。若没有溢出桶,则添加溢出桶,并将其置于溢出桶的第一个空位(非扩容的情况)。
当不同的key通过哈希函数得到的哈希值相同时,低位和高位都相同,如何查找到对应的键值对?
步骤和上面相同,低B为找到对应的桶,高8位找到对应的tophash位置,拿出key与要找的key比较是否相同,相同的话取出,不同的话,再在tophash中查找哈希值高8位的值,没找到,在溢出桶中找,直到找完所有key或者找到对应的key为止。
2.6 扩容
为什么要进行扩容:
当元素越来越多或者溢出桶的数量越来越多,导致查找的效率会变低。
2.6.1 负载因子
负载因子是决定哈希表是否进行扩容的关键指标。负载因子的值为6.5(经验所得),意思是平均每个桶中键值对的数量。当 总键值对个数 >= 桶总数 * 6.5,这个时候说明大部分的桶可能快满了。这个时候就可能需要扩容。
2.6.2 扩容的条件
扩容的条件有两个:
- 判断负载因子是否达到临界点(6.5),如果达到了,如果插入新的元素,大概率会需要挂在溢出桶上了。
- 判断溢出桶是否过多,当正常桶总数< 2^15时,如果溢出桶总数>=正常桶总数,则认为溢出桶过多。当正常桶总数>=2^15时,直接与2^15比较,当溢出桶总数>=2^15时,则认为溢出桶总数过多。
其实第二点是对第一点的补充。因为在负载因子比较小的情况下,有可能map的查找和插入的效率也可能很低。即map里的元素少,但是桶数量多(真实分配的桶数量多,包括大量的溢出桶)。
导致上面这种情况的原因是:对map中的元素不断的增删,增加会导致桶的数量变多,删除导致负载因子不高。
这样导致桶的使用率不高,存储的值比较稀疏,导致查找的效率变低。
2.6.3 解决方案
-
针对超过负载因子的情况:将B+1,新建一个buckets数组,新的buckets大小是原来的2倍,然后将旧buckets数据搬迁到新的buckets。该方法我们称之为增量扩容。
-
针对桶数量过多的情况:并不扩大容量,buckets数量维持不变,重新做一遍类似增量扩容的操作,就是将键值对重新映射到新buckets中,使得buckets的使用率变高。该方法我们称为等量扩容。
对于等量扩容,其实存在一种极端情况:如果插入map的key通过哈希函数后得到的哈希值一样,那它们就会落到同一个buckets中,查过8个就会产生overflow,结果也会照成溢出桶过多,移动元素其实解决不了问题,此时哈希表退化成了一个链表,操作效率编程了O(n),但Go的每一个map都会在初始阶段的makemap是定义一个随机哈希种子,所以要构成这种冲突是没有那么容易的。
扩容:首先分配新的buckets(不管增量扩容还是等量扩容都要新分配buckets),将老的buckets挂到oldbuckets字段上。buckes挂上新的buckets。然后将oldbuckets上的键值对重新哈希到buckets上,直到旧桶中的键值对全部搬迁完毕后,删除oldbuckets。 当oldbuckets值为nil表示扩容完毕。
2.6.4 渐进式扩容
由于map扩容需要使用将原有的键值对重新搬迁到新的内存地址,如果map储存了数以亿计的键值对,一次性搬迁会照成比较大的延时。因此Go语言map扩容采取了一种渐进式的方式。
原有的key不会一次性搬迁完毕,每次最多搬迁2个buckets,并且只有在插入,修改或删除key的时候,才会进行搬迁buckets工作。
参考文档:深入解析Golang的map设计 - 知乎

![[C语言]利用动态内存制作一个通讯录](https://img-blog.csdnimg.cn/direct/3cbf4b5987e74012b6df93e55487ee67.png)