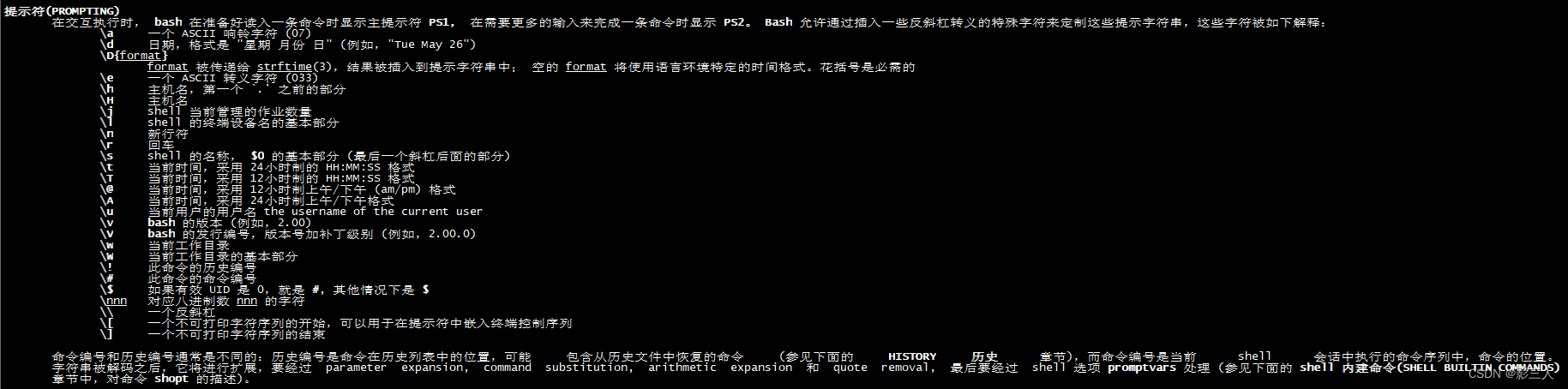
本文为霍格沃兹测试学院学院学员课程学习笔记。
公众号搜索:TestingStudio 霍格沃兹的干货都很硬核
AppCrawler 是由霍格沃兹测试学院校长思寒开源的一个项目,通过名字我们大概也能猜出个方向,Crawler 是爬虫的意思,App 的爬虫,遍历 App :
官方 GitHub 上对这款工具的解释是:
一个基于自动遍历的 App 爬虫工具。支持 Android 和 iOS,支持真机和模拟器。最大的特点是灵活性,可通过配置来设定遍历的规则。
这里顺便提一下的是谷歌也发布了一款自动遍历的工具,名字几乎一样,叫做 App Crawler (差了一个空格),设计的思想也一致,但是这款工具目前还在开发完善中,思寒大佬的工具比谷歌的早了两年时间,厉害啊!
Google App Crawler 链接:
https://developer.android.com/training/testing/crawler
下面来看看 AppCrawler 的作用和价值。
需求背景
互联网的业务需求背景:
- 业务变更快速
- 业务线众多
- 业务流程复杂
- 依赖第三方接口较多
测试工作常见问题:
- UI 自动化只能覆盖核心业务逻辑,新功能来不及上自动化
- 产品业务测试量较大,新版发布后,老功能来不及全面回归,容易漏测
- 时间长,强度大的工作后,人容易产生疲乏,对数字的位数,文字的显示等错误信息的敏感度下降
- 产品的界面深度很深,且包含大量的展示信息功能
- 专项测试回归难度大:内存泄漏、健壮性测试、弱网等测试太多
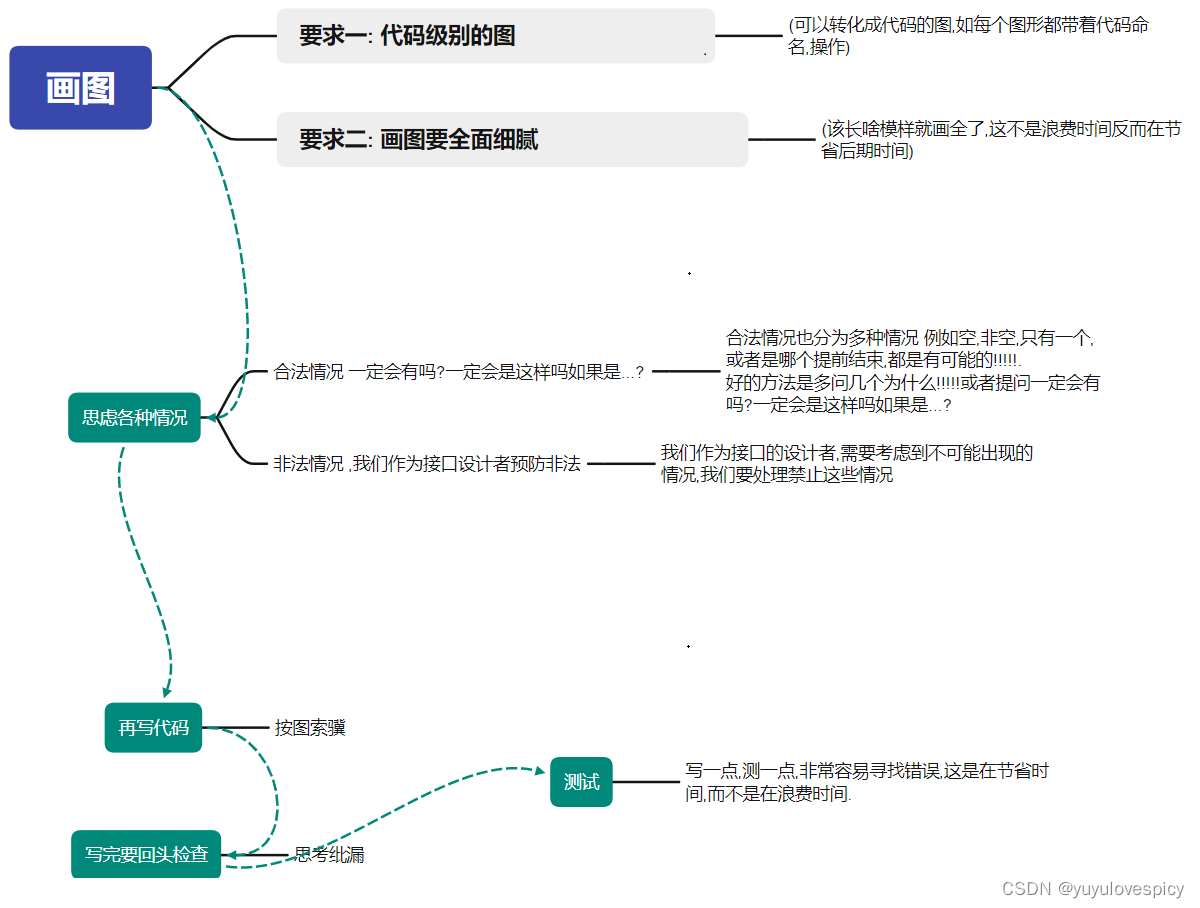
这个时候我们需要一种手段,可以达到两方面的目的:
- Code less: UI 自动化用例维护成本降到最低
- Automate: 尽可能的自动化覆盖回归业务
而自动遍历就可以满足我们对上述的业务的需求;接着再来看我们对自动遍历测试的一些需求,既然要用自动遍历,那么具体要等到什么样的效果?
工具选择
2.1 遍历工具需求
自动遍历的需求:
- 可控:可以定义遍历的路径,指定需要测试的业务,保证核心业务的覆盖优先级
- 可定制:可实现自动输入、自动滑动等基础行为
结果分析:
- 点击前后的截图对比
- 结果的数据建模
2.2 工具对比
2.2.1 Monkey
首先来看业界用的较早也是经常听过的一款工具—— Monkey
参考链接:
Monkey 官方链接:developer.android.com/studio/test/monkey
Monkey Script :github.com/gb112211/Android-Platform-Development/blob/master/cmds/monkey/src/com/android/commands/monkey/MonkeySourceScript.java
这是 Android 官方提供的一个工具,在 Android 的官网我们可以看到对这款工具的解释如下:

没错,谷歌原本设计这款工具是为了对 App 进行压力测试的,而并不是自动遍历测试,注意的是这里的压力测试并不是我们平常意义上的对服务端的压力,而是对 App 前端的压力。下面是思寒对 App 压力测试的原因解释:
谷歌早期在设计 Android 的时候,Android 需要响应滑动、输入、音量、电话等事件,早期 activity 设计不完善的时候,谷歌希望测试 activity 的性能,把所有的数据批量化的输出给 activity,看 activity 一秒钟可以处理多少数据。所以早期 Monkey 是用来做 Android 的一个压力测试的工具。
由于 Monkey 在测试过程中的“随机”性,恰巧可以被用来做自动遍历测试,但是 monkey 的缺点行业很明显,就是不满足我们的两个自动遍历需求:可控性和可定制。
- 缺点:不支持业务行为定制,无法灵活的控制,经常会点到外部的 App 无法回归原测试 App;或者点击到注销和退出,造成无法继续后面的测试;因此 monkey 在经过调研了解后没有成为我们做自动遍历测试的首选。
2.2.2 Maxim
Maxim 也是一款自动遍历工具,由我们国内的一名叫做 zhangzhao 的工程师开发,官方给出的定义是:
An efficient Android Monkey Tester, available for emulators and real devices 基于遍历规则的高性能 Android Monkey,适用于真机/模拟器的 APP UI 压力测试。
官方 GitHub 地址:github.com/zhangzhao4444/Maxim
我们来看看这款工具的优缺点:
优点:
- 基于Monkey二次开发,也用了一些 AppCrawler 的设计思路,拥有定制化功能;
- 因为底层基于了 Monkey,所以运行速度还是比较快的;
缺点:
- 因为是基于 Monkey,所以不具备跨平台性,只能测试 Android,不能测试 iOS,Web 等;
这款工具没有开源,但是可以直接使用,在 GitHub 上下载后根据官方说明操作即可,这里不做重点说明。
重点来看一下工具的特点和选择性:
- 配置文件,官方给出了配置文件的示例,以 json 格式进行编写:
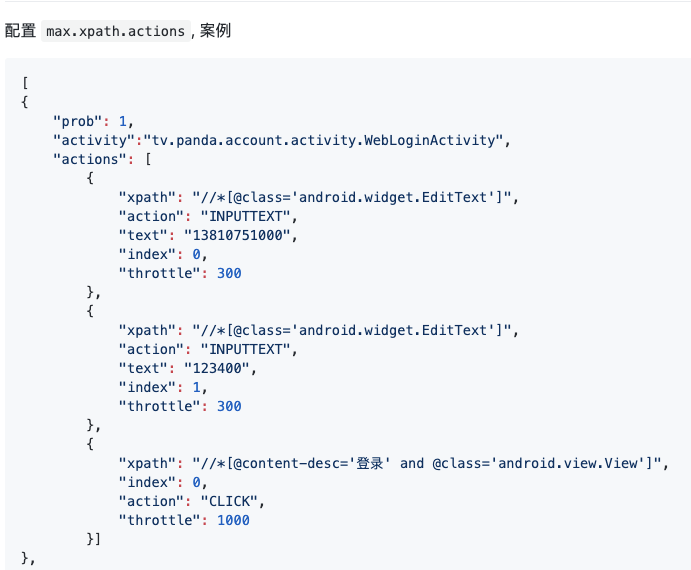
接触过 AppCrawler 后会发现写法非常相似,只不过 AppCrawler 是以 YAML 文件进行书写。
选择:
这也是一款很优秀的工具,可在一定程度上进行定制,如果只测试 Android 系统的话,可以考虑选用 Maxim 做自动遍历,速度相对较快;如果想要跨平台或者对开源工具进行二次开发,那就要 AppCrawler 登场了。
2.2.3 AppCrawler
再来看今天的主角
AppCrawler,看看它为何满足我们的测试需求,它的优缺点有在哪里。
先来看它与其他框架的关系结构
- 与其他框架的关系
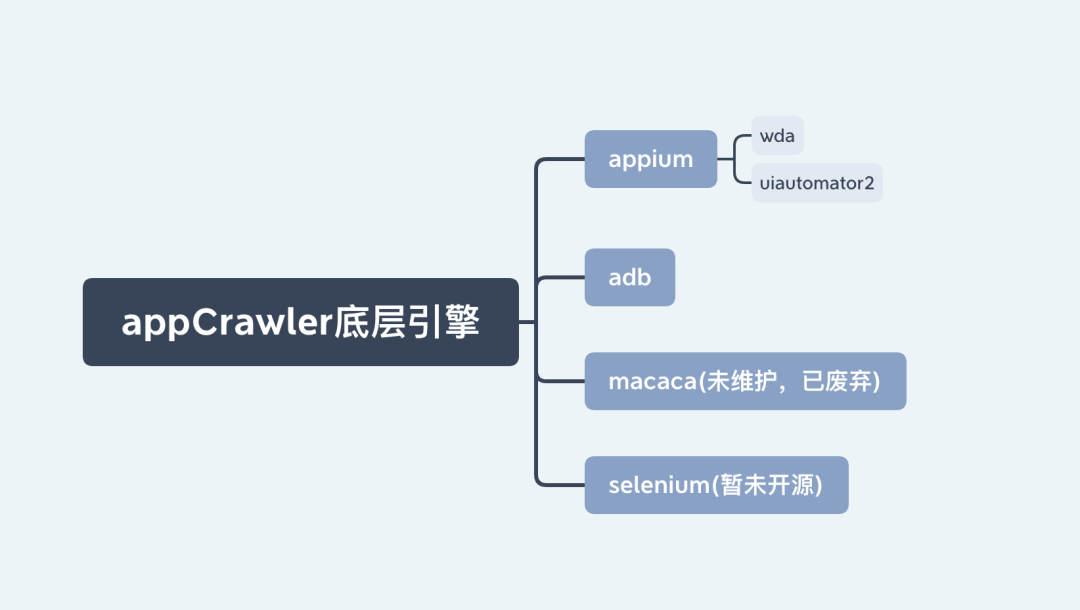
优点:
- 跨平台性:
AppCrawler是基于Appium开发的,所以支持Android和iOS。 - 可控性:对测试的页面,控件类型的选择,测试的深度等都可自由控制;
- 可定制:可自定义操作,如输入,滑动等;
缺点:
- 运行速度较慢:
AppCrawler是基于Appium开发具备了跨平台的优点,但是也因为这层封装造成了运行速度相对较慢; - 使用门槛高:正因为使用灵活性的问题,也造成了使用门槛的提高,主要基于 YAML 文件中使用
Appium的相关技术知识进行配置,这就对使用者有了一定的技术要求;
安装和启动
3.1 下载
因为较大,官方也给出了打包后的百度网盘下载地址
最新版本下载地址: https://pan.baidu.com/s/1dE0JDCH
这里以目前最新的2.4.0为例
如何自己编译打包:
1)从 GitHub 上 Clone 源码,当前开源的最新 2.4.0 版本对应的分支是 2.3.1 AppCrawler 官方 GitHub 地址:
github.com/seveniruby/AppCrawler
 2)切换到分支:
2)切换到分支:git checkout 2.3.1
3)执行 mvn clean compile
4)使用 maven 构建:执行 mvn assembly:single 命令进行编译即可
安装 :
AppCrawler 本身是个 jar 包,不需要安装,需要安装的是运行时所依赖的环境:
Java版本:Java8、Java10 (未测试过,作者说支持)
Appium:Appium 1.8 以上 因为 AppCrawler 是基于 Appium 开发的,
所以 Appium 的环境是必不可少的Appium的安装方式可参考另外一篇博客: Windows (Win10)、Mac 下安装 Appium;
查看帮助文档:
直接使用命令 java -jar appcrawler-2.4.0-jar-with-dependencies.jar,可以看到如下帮助文档信息 相关参数含义和部分注解如下:
$ java -jar appcrawler-2.4.0-jar-with-dependencies.jar
----------------
AppCrawler 2.4.0 [霍格沃兹测试开发学社特别纪念版]
Appium 1.8.1 Java8 tested
app爬虫, 用于自动遍历测试. 支持Android和iOS, 支持真机和模拟器
项目地址: https://github.com/seveniruby/AppCrawler
--------------------------------
Usage: appcrawler [options]
-a, --app <value> Android或者iOS的文件地址, 可以是网络地址, 赋值给appium的app选项 #安装App,实际中使用较少
-e, --encoding <value> set encoding, such as UTF-8 GBK #在Windows下可能会产生乱码,对其编码格式进行设置
-c, --conf <value> 配置文件地址 #复杂且重要,是AppCrawler定制的核心
-p, --platform <value> 平台类型android或者ios, 默认会根据app后缀名自动判断
-t, --maxTime <value> 最大运行时间. 单位为秒. 超过此值会退出. 默认最长运行3个小时
-u, --appium <value> appium的url地址 #运行依赖于appium,不加此参数就使用默认的appium地址端口
-o, --output <value> 遍历结果的保存目录. 里面会存放遍历生成的截图, 思维导图和日志
--capability k1=v1,k2=v2... # 和appium的capability设置一致
appium capability选项, 这个参数会覆盖-c指定的配置模板参数, 用于在模板配置之上的参数微调
-r, --report <value> 输出html和xml报告
--template <value> 输出代码模板
--master <value> master的diff.yml文件地址
--candidate <value> candidate环境的diff.yml文件
--diff 执行diff对比
-vv, --verbose 是否展示更多debug信息
--demo 生成demo配置文件学习使用方法
--help
示例
appcrawler -a xueqiu.apk
appcrawler -a xueqiu.apk --capability noReset=true
appcrawler -c conf/xueqiu.json -p android -o result/
appcrawler -c xueqiu.json --capability udid=[你的udid] -a Snowball.app
appcrawler -c xueqiu.json -a Snowball.app -u 4730
appcrawler -c xueqiu.json -a Snowball.app -u http://127.0.0.1:4730/wd/hub
#生成demo例子
appcrawler --demo
#启动已经安装过的app
appcrawler --capability "appPackage=com.xueqiu.android,appActivity=.view.WelcomeActivityAlias"
#从已经结束的结果中重新生成报告
appcrawler --report result/
#新老版本对比
appcrawler --candidate result/ --master pre/ --report ./
这里顺便说一下的是当前版本的diff功能还不完善,也相对较复杂,目前先不做深入研究
Quick Start:
1) 启动appium
$ appium
[Appium] Welcome to Appium v1.14.1
[Appium] Appium REST http interface listener started on 0.0.0.0:4723
2)启动模拟器或真机,保证 adb devices 可有找到你的设备
$ adb devices
List of devices attached
FKFBB19120151100 device
3) 根据参考文档中的命令,启动遍历一个已经安装过的 App (以示例中的雪球 App 为例):
java -jar appcrawler-2.4.0-jar-with-dependencies.jar --capability
"appPackage=com.xueqiu.android,appActivity=.view.WelcomeActivityAlias"
这个命令执行后会以默认的方式去执行用例,然后遍历
-
遍历原则:它的遍历原则是,找页面的里层次最深的元素,也就是处于中心位置元素会被优先遍历
-
部分遍历效果展示:
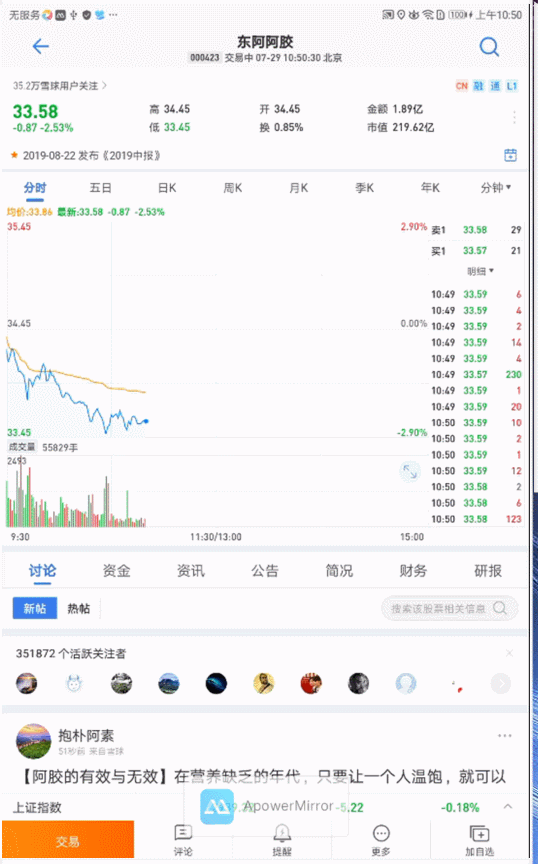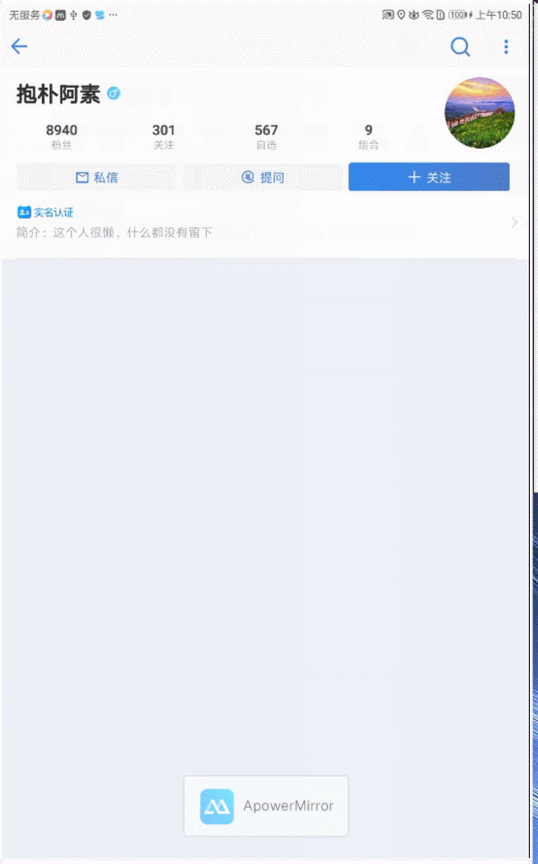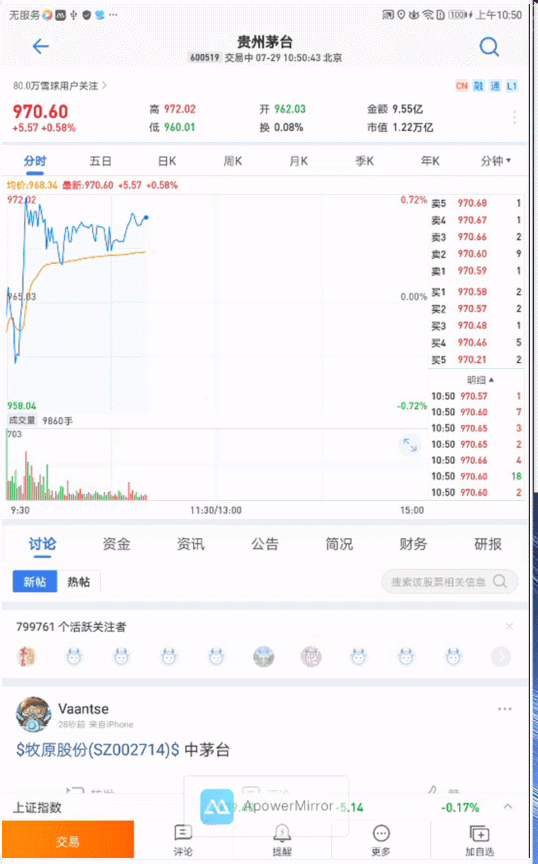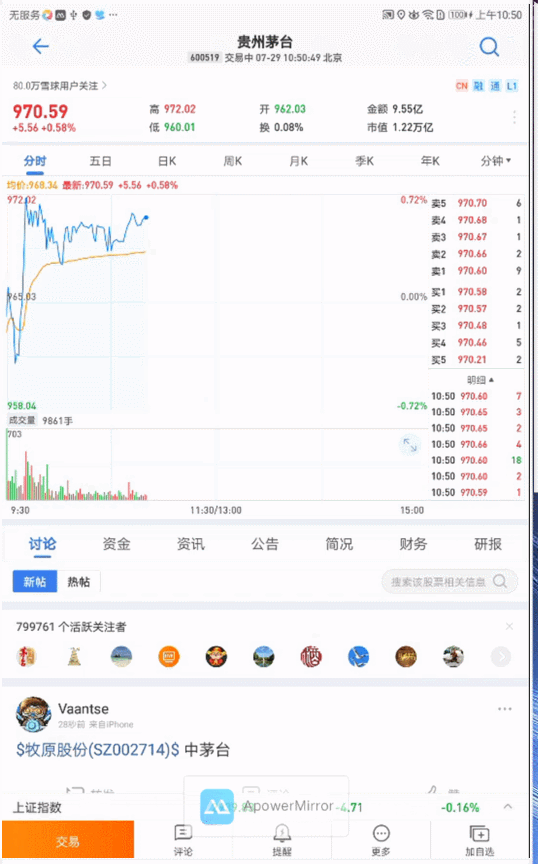
-
测试结果
如果没有使用
-o参数指定 log 输出的路径,AppCrawler就会在当前目录下生成以时间为命名的文件夹,里面保存了所有的数据,文件、截图、log
$ ls
20191129154742
appcrawler-2.4.0-jar-with-dependencies.jar
打开文件夹会发现如下,每一步都会进行截图(这也是速度变慢的原因之一吧)以及对于的 dom 文件,这里会看到有几个 steps 文件,这个只是随意点了某个操作来告知用户正在操作,真正的执行步骤是从这之后开始。
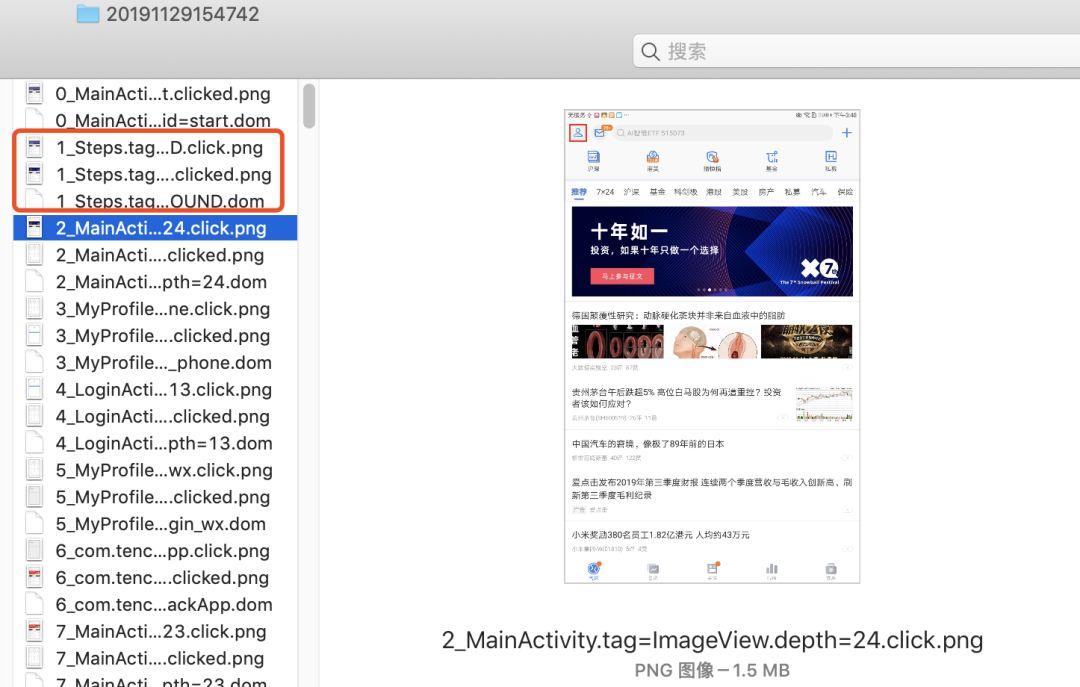
-
测试报告
在测试 log 中有一个 index.html 文件,打开它会看到刚才运行的测试报告,AppCrawler 会把每一次点击当做一个测试用例,没一个页面当做是一个测试套件;将界面和界面内的控件点击模拟成了测试套件和测试用例的关系;

成功的用 Succeed 表示,Canceled 是遍历的时候发现有这个可点击的控件,但是最后却没遍历到的控件。
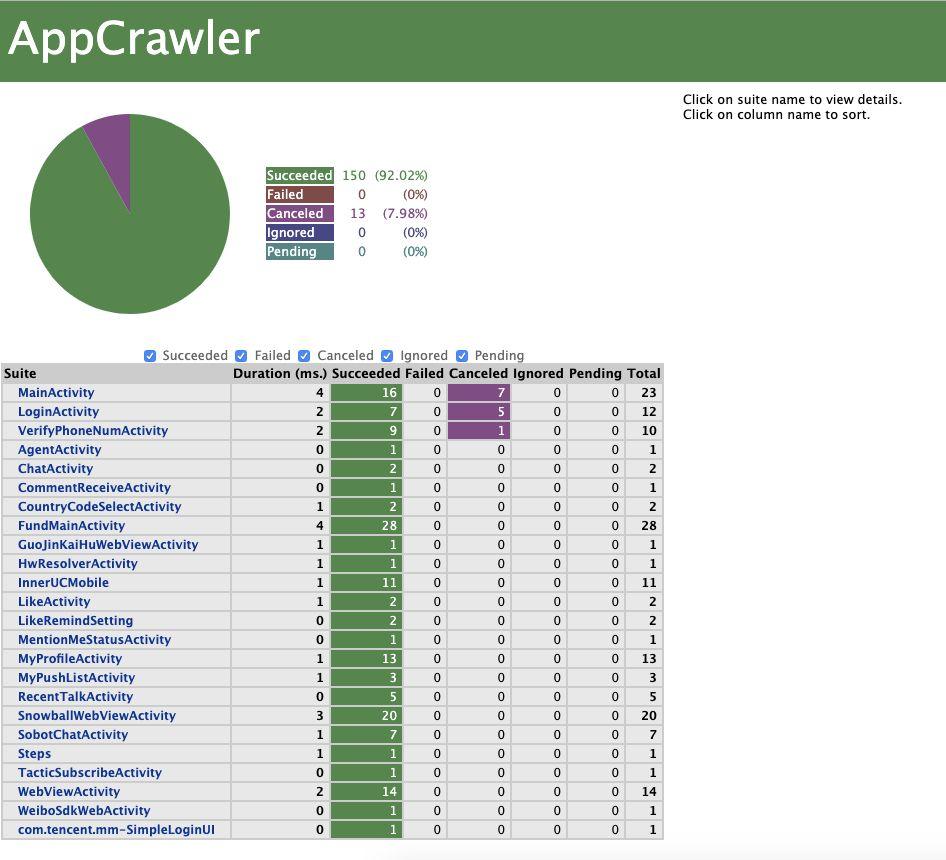
报告中也可以查看对应页面操作事件的截图
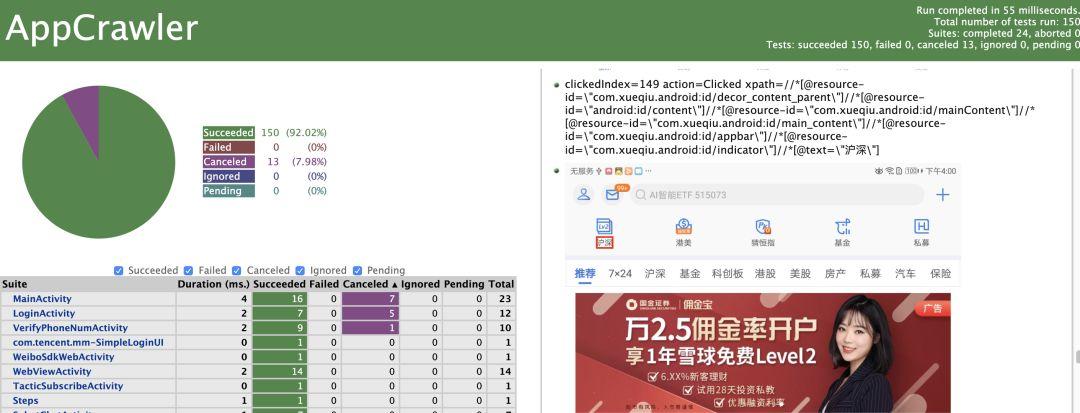
-
测试 log
在生成的文件夹中有 appcrawler.log,里面记录了详细的执行步骤的 log 信息(加上
-vv参数运行的话会得到更多更多的 log 信息)
截取部分 log 展示如下:
2019-11-29 15:48:10 INFO [Crawler.996.doElementAction] current element = MainActivity.tag=ImageView.depth=24
2019-11-29 15:48:10 INFO [Crawler.997.doElementAction] current index = 2
2019-11-29 15:48:10 INFO [Crawler.998.doElementAction] current action = click
2019-11-29 15:48:10 INFO [Crawler.999.doElementAction] current xpath = //*[@resource-id="com.xueqiu.android:id/decor_content_parent"]//*[@resource-id="android:id/content"]//*[@resource-
id="com.xueqiu.android:id/mainContent"]//*[@resource-id="com.xueqiu.android:id/main_content"]//*[@resource-
id="com.xueqiu.android:id/pager"]//*[@resource-id="com.xueqiu.android:id/layout_refresh"]//*[@resource-
id="com.xueqiu.android:id/list"]//*[@resource-id="com.xueqiu.android:id/today_topic_container"]//*[@resource-
id="com.xueqiu.android:id/time_line_topic_item_case2"]//*[@resource-
id="com.xueqiu.android:id/today_topic_container"]//*[@resource-
id="com.xueqiu.android:id/time_line_topic_footer"]//*[@resource-id="com.xueqiu.android:id/feedback"]
2019-11-29 15:48:10 INFO [Crawler.1000.doElementAction] current url = MainActivity
2019-11-29 15:48:10 INFO [Crawler.1001.doElementAction] current tag path =
hierarchy/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.view.ViewGroup/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.RelativeLayout/android.view.ViewGroup/androidx.viewpager.widget.ViewPager/android.widget.RelativeLayout/android.view.ViewGroup/androidx.recyclerview.widget.RecyclerView/android.widget.LinearLayout/android.widget.FrameLayout/android.widget.FrameLayout/android.widget.LinearLayout/android.widget.RelativeLayout/android.widget.FrameLayout/android.widget.RelativeLayout/android.widget.FrameLayout/android.widget.ImageView
2019-11-29 15:48:10 INFO [Crawler.1002.doElementAction] current file name = MainActivity.tag=ImageView.depth=24
2019-11-29 15:48:10 INFO [Crawler.1071.doElementAction] need input click
2019-11-29 15:48:10 INFO [AppiumClient.53.findElementByURI] find by uri element= MainActivity.tag=ImageView.depth=24
2019-11-29 15:48:10 INFO [AppiumClient.245.findElementsByURI] findElementByAndroidUIAutomator new UiSelector().className("android.widget.ImageView")
2019-11-29 15:48:10 INFO [AppiumClient.60.findElementByURI] find by xpath success
2019-11-29 15:48:10 INFO [Crawler.1080.doElementAction] mark 20191129154742/1_Steps.tag=.name=NOT_FOUND.clicked.png to 20191129154742/2_MainActivity.tag=ImageView.depth=24.click.png
2019-11-29 15:48:10 INFO [AppiumClient.141.mark] read from 20191129154742/1_Steps.tag=.name=NOT_FOUND.clicked.png
2019-11-29 15:48:11 INFO [AppiumClient.154.mark] write png 20191129154742/1_Steps.tag=.name=NOT_FOUND.clicked.png
2019-11-29 15:48:11 INFO [AppiumClient.161.mark] ImageIO.write newImageName 20191129154742/2_MainActivity.tag=ImageView.depth=24.click.png
2019-11-29 15:48:11 INFO [Crawler.1095.$anonfun$doElementAction$5] click element
index 等于几就表示第几次事件,action 表示当前的操作,xpath 就表示当前操作的元素的 xpath 表达式。
补充说明
总说 AppCrawler 慢,其他工具相对较快,原因为何,先来看他们的架构组成
- appcrawler
- appium、atx
- appium on Uiautomator2 server、atx on Uiautomator2、maxim、adb shell uiautomator、改进版本Uiautomator2 server
- Uiautomator2
- AccessibilityService
底层有个叫 AccessibleServices 东西,它可以获取 Android 所有界面的控件,uiautomator 获取元素进行操作的时候就是靠 AccessibleServices 去获取控件,然后去触发一定的行为,uiautomator 就是将其进行了包装;
基于 uiautomator,Appium 开发了一个 uiautomator server,ATX 开发了一个uiautomator2,maxim 就处于这一层。
Appium 走的是 HTTP 协议,ATX 走的是 JSON-RPC 协议,AppCrawler 处于最上层 所以 AppCrawler 由于多了两层封装,再加上运行过程中加入了截图(可以在配置中取消,但是取消后不利于结果的查看),运行起来自然就慢了。
-
改进期望:
后期期望 AppCrawler 团队可以将其根据需求指定底层操作,绕过很多不必要的流程来增加效率,这样功能非常完善的同时也能保证效率
到这里只是完成了 AppCrawler 的一个基本认识,既然提到了它的定制化的特点,就需要通过配置文件来完成了,下一篇将进行详细的介绍。