文章目录
- Set接口
- > Set 接口和常用方法
- > Set接口实现类 - HashSet
- HashSet 底层机制(HashMap)
- > Set接口实现类 - LinkedHashSet
Set接口
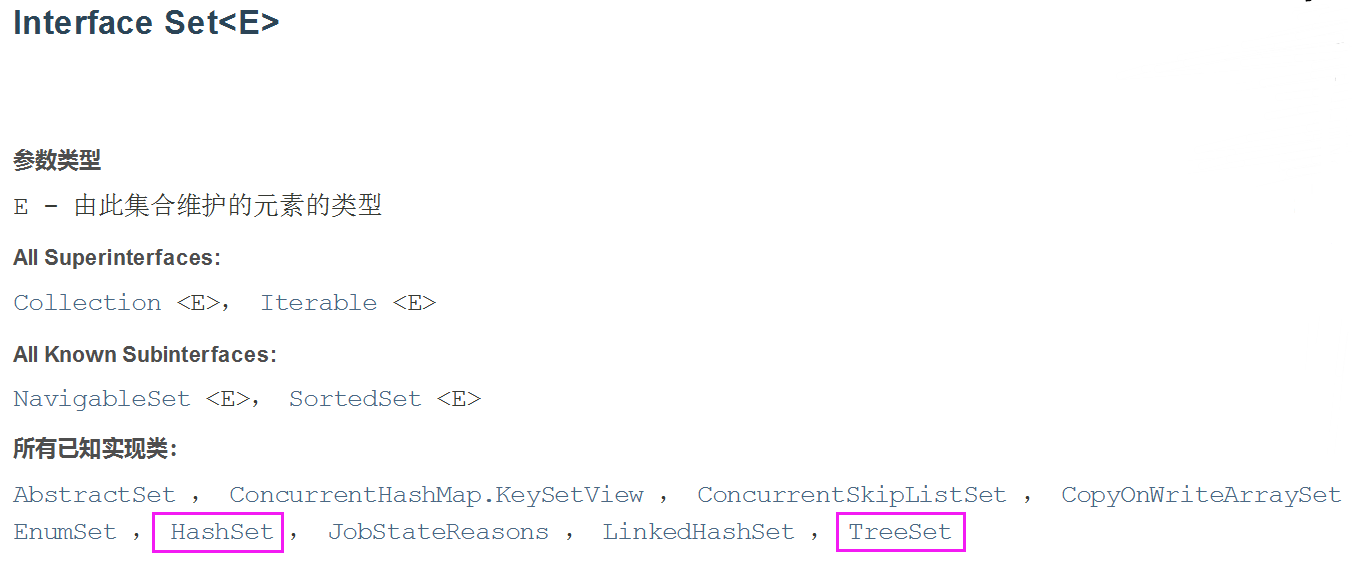
Set 接口介绍:
- 无序(添加和取出的顺序不一致),没有索引;
- 不允许重复元素,所以最多包含一个null;
- JDK API 中Set的常用实现类有:HashSet 和 TreeSet;
> Set 接口和常用方法
Set 接口的常用方法
- 和 List 接口一样,Set 接口也是 Collection 的子接口,所以常用方法和Collection接口一样
Set 接口的遍历方式
- 同 Collection 的遍历一样:
- 迭代器遍历
- 增强 for
- 但 不能用索引 的方式来获取; (因为Set无序)
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class SetMethod {
public static void main(String[] args) {
//以Set接口的实现类 HashSet 来演示
//Set接口的实现类对象(Set接口对象),不能存放重复元素
//Set接口对象存放和读取数据无序
//取出的顺序虽然不是添加的顺序,但是,是固定有序的
Set set = new HashSet();
set.add("John");
set.add("Lucy");
set.add("Jack");
set.add(null);
set.add(null);
System.out.println(set);//[null, John, Lucy, Jack] 执行多遍都是这个结果
set.remove(null);//等常用方法可以依照Colleciotn常用方法,是一致的
//遍历:迭代器
Iterator iterator = set.iterator();
while(iterator.hasNext()){
Object o = iterator.next();
System.out.println(o);
}
//遍历:增强for (底层还是迭代器)
for(Object o:set){
System.out.println(o);
}
//不能索引遍历,且set接口对象没有get()方法
}
}
> Set接口实现类 - HashSet
- HashSet实现了Set接口;
- HashSet实际上是HashMap,可以从源码看出;
- 可以存放 null 值,但是只能有一个null;
- HashSet 不保证元素是有序的,取决于hash后,再确定索引的结果;
- 不能有重复元素 / 对象;
import java.util.HashSet;
public class HashSet01 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
//1.在执行add方法后,会返回一个boolean值
//2.如果添加成功,返回true,否则返回false
System.out.println(hashSet.add("john"));//true
System.out.println(hashSet.add("lucy"));//true
System.out.println(hashSet.add("john"));//false
System.out.println(hashSet.add("jack"));//true
System.out.println(hashSet.add("rose"));//true
hashSet.remove("john");//指定删除某对象
System.out.println("hashset = "+hashSet);//hashset = [rose, lucy, jack]
hashSet = new HashSet();
//HashSet不能添加相同的元素、数据
hashSet.add("lucy");//添加成功
hashSet.add("lucy");//加入不了
hashSet.add(new Dog("tom"));//OK
hashSet.add(new Dog("tom"));//也能加入
System.out.println("hashset = "+hashSet);//hashset = [Dog{name='tom'}, lucy, Dog{name='tom'}]
//经典面试题
hashSet.add(new String("ok"));//可以加入
hashSet.add(new String("ok"));//无法加入
System.out.println("hashset = "+hashSet);//hashset = [Dog{name='tom'}, ok, lucy, Dog{name='tom'}]
//看源码 add到底发生了什么 --》底层机制
}
}
class Dog{
private String name;
public Dog(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}
HashSet 底层机制(HashMap)
HashSet 底层其实是HashMap,HashMap底层是(数组+链表+红黑树)
模拟数组+链表结构:
- 定义一个数组
- 数组里面放对象
- 一个对象还能指向下一个对象
public class HashSetStructure {
public static void main(String[] args) {
//模拟一个HashSet的底层(HashMap)
//1.创建一个数组,数组的类型是Node[]
//2.Node[] 也称为一个表
Node[] table = new Node[16];
//3.创建一个节点
Node john = new Node("john", null);
table[2] = john;
Node jack = new Node("jack", null);
john.next = jack;//将节点挂载到john
Node rose = new Node("rose",null);
jack.next = rose;//将rose节点挂载到jack
Node lucy = new Node( "lucy",null);
table[3] = lucy;//把lucy放到table表的索引为3的位置
System.out.println("table = "+table);
}
}
class Node{//节点,存储数据,可以指向下一个节点,从而形成链表
Object item;//存放数据
Node next;//指向下一个节点
public Node(Object item, Node next) {
this.item = item;
this.next = next;
}
}
debug后解读:
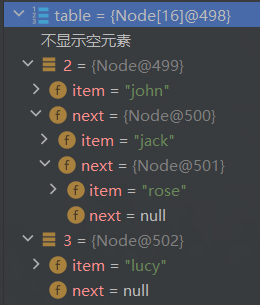
HashSet底层机制:

- HashSet 底层其实是 HashMap;
- 添加一个元素时,先得到 hash值-> 转成->索引值 ;
- 找到存储数据表 table ,看这个索引位置是否已经存放的所有元素;
- 如果没有,直接加入;
- 如果有,调用 equals 比较,如果相同,就放弃添加,如果不相同,则添加到最后;
- 在Java8中,如果一条链表的元素个数达到 TREEIFY_THRESHOLD(默认是8),并且table大小>=MIN_TREEIFY_CAPACITY(默认是64),就会进行树化(红黑树);
用例:
定义一个Employee类,该类包含:private成员属性name,age
要求:
1.创建3个Employee对象放入HashSet中;
2.当name和age的值相同时,认为是相同员工,不能添加到HashSet集合中;
import java.util.HashSet;
import java.util.Objects;
public class HashSet_Exercise {
/**
* 定义一个Employee类,该类包含:private成员属性name,age
* 1.创建3个Employee对象放入HashSet中;
* 2.当name和age的值相同时,认为是相同员工,不能添加到HashSet集合中;
*/
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add(new Employee("jack",18));
hashSet.add(new Employee("tom",28));
hashSet.add(new Employee("rose",18));
//加入了三个成员
System.out.println(hashSet);//[Employee{name='jack', age=18}, Employee{name='rose', age=18}, Employee{name='tom', age=28}]
}
}
//创建Employee
class Employee{
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
//如果name和age相同,则返回相同的hash值
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age && Objects.equals(name, employee.name);
}
//name和age相同,hashcode相同
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
> Set接口实现类 - LinkedHashSet
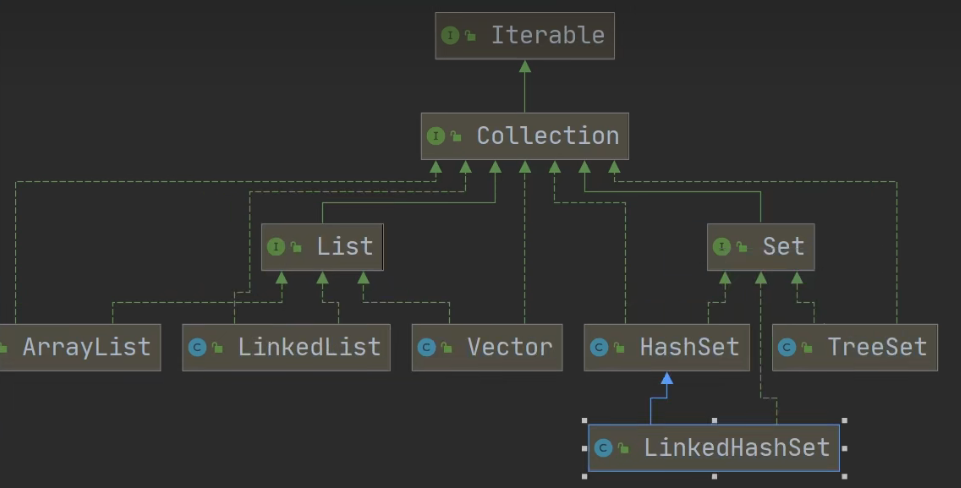
- LinkedHashSet 是 HashSet 的子类,继承HashSet,实现了Set接口;
- LinkedHashSet 底层是一个 LinkedHashMap,底层维护了一个 数组+双向链表;
- LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序,这使得元素看起来是以插入顺序保存的;
- LinkedHashSet 不允许添加重复元素;
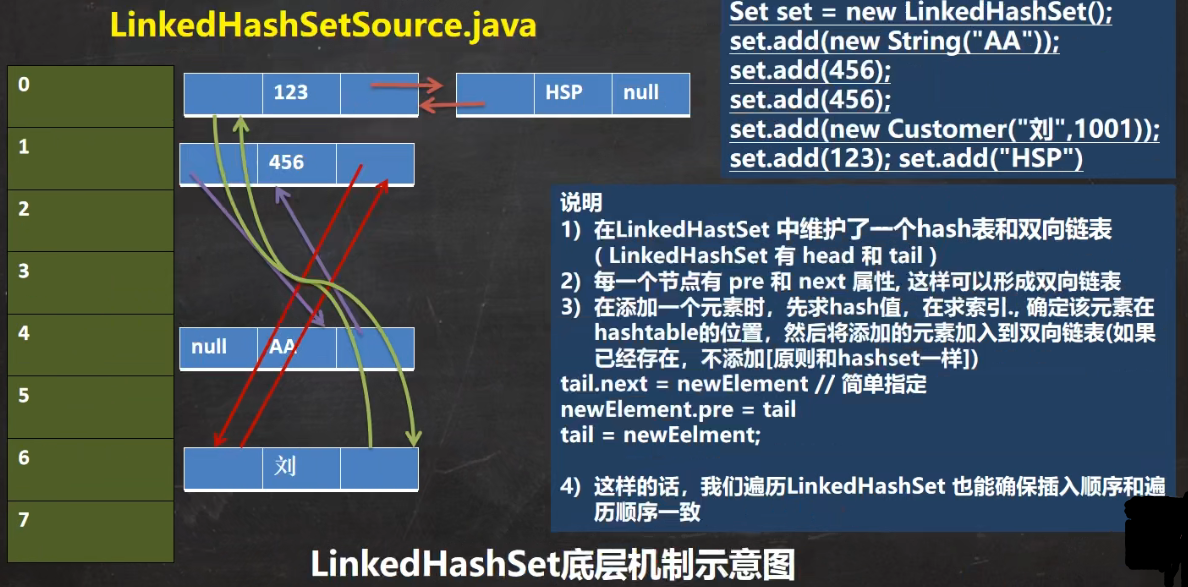
import java.util.LinkedHashSet;
import java.util.Set;
public class LinkedHashSetSource {
public static void main(String[] args) {
//LinkedHashSet底层机制
Set set = new LinkedHashSet();
set.add(new String("OK"));
set.add(128);
set.add(128);
set.add(new Customer("靳",1201));
set.add("JinYu");
System.out.println(set);
//[OK, 128, com.study.set_.Customer@677327b6, JinYu]
/*
1.添加元素和取出顺序一致
2.LinkedHashSet底层维护的是一个LinkedHashMap(是HashMap的子类)
3.LinkedHashSet底层结构:数组table+双向链表
4.添加第一次时,直接将数组table扩容到16,存放的结点类型是LinkedHashSetMap$Entry
5.数组是HashMap$Node[] 存放的元素/数据是LinkedHashSetMap$Entry类型
*/
}
}
class Customer{
private String name;
private int id;
public Customer(String name, int id) {
this.name = name;
this.id = id;
}
}
示例:Car类(属性name,price),如果name和price一样,则认为是相同元素,就不能添加
import java.util.LinkedHashSet;
import java.util.Objects;
import java.util.Set;
public class LinkedHashSetExercise {
public static void main(String[] args) {
Set set = new LinkedHashSet();
set.add(new Car("奥拓",1000));
set.add(new Car("奥迪",300000));
set.add(new Car("法拉利",9000000));
set.add(new Car("奥迪",300000));
set.add(new Car("保时捷",1000));
set.add(new Car("奥迪",300000));
System.out.println(set);
/* 未重写equals和hashCode方法:
[Car{name='奥拓', price=1000.0}
, Car{name='奥迪', price=300000.0}
, Car{name='法拉利', price=9000000.0}
, Car{name='奥迪', price=300000.0}
, Car{name='保时捷', price=1000.0}
, Car{name='奥迪', price=300000.0}
]*/
/* 重写equals和hashCode方法后:
[Car{name='奥拓', price=1000.0}
, Car{name='奥迪', price=300000.0}
, Car{name='法拉利', price=9000000.0}
, Car{name='保时捷', price=1000.0}
]
*/
}
}
class Car{
private String name;
private double price;
public Car(String name, double price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "Car{" +
"name='" + name + '\'' +
", price=" + price +
'}'+"\n";
}
//重写equals方法和hashCode方法
//当name和price相同时,返回相同的hashCode值
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
return Double.compare(car.price, price) == 0 && Objects.equals(name, car.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
}