返回:OpenCV系列文章目录(持续更新中......)
上一篇:OpenCV4.9.0开源计算机视觉库核心功能(核心模块)

目标
我们将寻求以下问题的答案:
- 如何浏览图像的每个像素?
- OpenCV 矩阵值是如何存储的?
- 如何衡量我们算法的性能?
- 什么是查找表,为什么要使用它们?
测试用例
让我们考虑一个简单的颜色还原方法。通过使用无符号字符 C 和 C++ 类型存储矩阵项,像素通道最多可以有 256 个不同的值。对于三通道图像,这可能会形成太多的颜色(准确地说是 1600 万)。使用如此多的色调可能会对我们的算法性能造成沉重打击。但是,有时使用更少的人就足以获得相同的最终结果。
在这种情况下,我们通常会减少色彩空间。这意味着我们将色彩空间当前值除以新的输入值,最终得到更少的颜色。例如,0 到 9 之间的每个值都取新值 0,10 到 19 之间的每个值都取值 10,依此类推。
当您将 uchar(无符号 char - 又名值介于 0 和 255 之间)值除以 int 值时,结果也将是 char。这些值只能是 char 值。因此,任何分数都将四舍五入。利用这一事实,uchar 域中的上层操作可以表示为:
Inew=(Iold10)∗10
一个简单的色彩空间缩减算法将包括仅通过图像矩阵的每个像素并应用此公式。值得注意的是,我们进行了除法和乘法运算。对于一个系统来说,这些操作的成本非常高。如果可能的话,通过使用更便宜的操作来避免它们是值得的,例如一些减法、加法,或者在最好的情况下是简单的分配。此外,请注意,我们只有有限数量的上部操作的输入值。在 uchar 系统的情况下,准确地说是 256。
因此,对于较大的图像,明智的做法是事先计算所有可能的值,并且在分配期间使用查找表进行分配。查找表是简单的数组(具有一个或多个维度),对于给定的输入值变体,它保存最终输出值。它的优点是我们不需要进行计算,我们只需要读取结果。
我们的测试用例程序(以及下面的代码示例)将执行以下操作:读取作为命令行参数传递的图像(可以是彩色或灰度),并使用给定的命令行参数整数值应用约简。在 OpenCV 中,目前有三种主要方法可以逐像素浏览图像。为了让事情变得更有趣,我们将使用这些方法中的每一种对图像进行扫描,并打印出花费的时间。
你可以在这里下载完整的源代码,或者在 OpenCV 的 samples 目录中查找 cpp 教程代码 for the core 部分。其基本用途是:
how_to_scan_images imageName.jpg intValueToReduce [G]最后一个参数是可选的。如果给定,图像将以灰度格式加载,否则使用 BGR 色彩空间。首先是计算查找表。
int divideWith = 0; // convert our input string to number - C++ style
stringstream s;
s << argv[2];
s >> divideWith;
if (!s || !divideWith)
{
cout << "Invalid number entered for dividing. " << endl;
return -1;
}
uchar table[256];
for (int i = 0; i < 256; ++i)
table[i] = (uchar)(divideWith * (i/divideWith));在这里,我们首先使用 C++ 字符串流类将第三个命令行参数从文本转换为整数格式。然后我们使用简单的外观和上面的公式来计算查找表。这里没有 OpenCV 特定的东西。
另一个问题是我们如何测量时间?OpenCV提供了两个简单的函数来实现这一点 cv::getTickCount() 和 cv::getTickFrequency() 。第一个返回系统 CPU 从某个事件(例如自启动系统以来)的滴答次数。第二个返回 CPU 在一秒钟内发出滴答声的次数。因此,测量两个操作之间经过的时间量就像以下几点一样简单:
double t = (double)getTickCount();
// do something ...
t = ((double)getTickCount() - t)/getTickFrequency();
cout << "Times passed in seconds: " << t << endl;图像矩阵是如何存储在内存中的?
正如您已经在我的 Mat - The Basic Image Container 教程中读到的那样,矩阵的大小取决于所使用的颜色系统。更准确地说,这取决于使用的通道数量。在灰度图像的情况下,我们有如下内容:
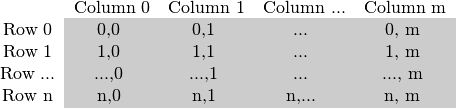
对于多通道图像,列包含的子列数与通道数一样多。例如,在 BGR 颜色系统的情况下:

请注意,通道的顺序是相反的:BGR 而不是 RGB。因为在许多情况下,内存足够大,可以以连续的方式存储行,所以行可以一个接一个地跟随,从而创建一个长行。因为所有东西都在一个地方,一个接一个地跟随,这可能有助于加快扫描过程。我们可以使用 cv::Mat::isContinuous() 函数来询问矩阵是否是这种情况。继续阅读下一节以查找示例。
高效之道
在性能方面,你不能打败经典的 C 风格运算符[](指针)访问。因此,我们可以推荐的最有效的分配方法是:
Mat& ScanImageAndReduceC(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
int channels = I.channels();
int nRows = I.rows;
int nCols = I.cols * channels;
if (I.isContinuous())
{
nCols *= nRows;
nRows = 1;
}
int i,j;
uchar* p;
for( i = 0; i < nRows; ++i)
{
p = I.ptr<uchar>(i);
for ( j = 0; j < nCols; ++j)
{
p[j] = table[p[j]];
}
}
return I;
}在这里,我们基本上只是获取指向每行开头的指针,然后遍历它直到它结束。在矩阵以连续方式存储的特殊情况下,我们只需要请求指针一次,并一直到最后。我们需要注意彩色图像:我们有三个通道,因此我们需要在每行中传递三倍的项目。还有另一种方法。Mat 对象的数据数据成员返回指向第一行第一列的指针。如果此指针为 null,则该对象中没有有效输入。检查这是检查图像加载是否成功的最简单方法。如果存储是连续的,我们可以使用它来遍历整个数据指针。如果是灰度图像,则如下所示:
uchar* p = I.data;
for( unsigned int i = 0; i < ncol*nrows; ++i)
*p++ = table[*p];你会得到同样的结果。但是,以后很难阅读此代码。如果你在那里有一些更先进的技术,那就更难了。此外,在实践中,我观察到你会得到相同的性能结果(因为大多数现代编译器可能会自动为你做这个小的优化技巧)。
迭代器(安全)方法
在有效的情况下,确保您通过正确数量的 uchar 字段并跳过行之间可能出现的间隙是您的责任。迭代器方法被认为是一种更安全的方法,因为它从用户那里接管了这些任务。您需要做的就是询问图像矩阵的开始和结束,然后增加开始迭代器,直到到达终点。要获取迭代器指向的值,请使用 * 运算符(在它前面添加它)。
Mat& ScanImageAndReduceIterator(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
const int channels = I.channels();
switch(channels)
{
case 1:
{
MatIterator_<uchar> it, end;
for( it = I.begin<uchar>(), end = I.end<uchar>(); it != end; ++it)
*it = table[*it];
break;
}
case 3:
{
MatIterator_<Vec3b> it, end;
for( it = I.begin<Vec3b>(), end = I.end<Vec3b>(); it != end; ++it)
{
(*it)[0] = table[(*it)[0]];
(*it)[1] = table[(*it)[1]];
(*it)[2] = table[(*it)[2]];
}
}
}
return I;
}对于彩色图像,我们每列有三个 uchar 项目。这可以被认为是 uchar 项目的简短向量,已在 OpenCV 中以 Vec3b 名称受洗。为了访问第 n 个子列,我们使用简单的 operator[] 访问。重要的是要记住,OpenCV 迭代器会遍历列并自动跳到下一行。因此,对于彩色图像,如果您使用简单的 uchar 迭代器,您将只能访问蓝色通道值。
On-the-fly address calculation with reference returning
使用引用返回进行动态地址计算
不建议将最终方法用于扫描。它是为了以某种方式获取或修改图像中的随机元素而制作的。它的基本用法是指定要访问的项目的行号和列号。在我们之前的扫描方法中,您已经注意到,通过我们查看图像的类型很重要。这里没有什么不同,因为您需要手动指定在自动查找时要使用的类型。在以下源代码的灰度图像中,您可以观察到这一点(使用 + cv::Mat::at() 函数):
Mat& ScanImageAndReduceRandomAccess(Mat& I, const uchar* const table)
{
// accept only char type matrices
CV_Assert(I.depth() == CV_8U);
const int channels = I.channels();
switch(channels)
{
case 1:
{
for( int i = 0; i < I.rows; ++i)
for( int j = 0; j < I.cols; ++j )
I.at<uchar>(i,j) = table[I.at<uchar>(i,j)];
break;
}
case 3:
{
Mat_<Vec3b> _I = I;
for( int i = 0; i < I.rows; ++i)
for( int j = 0; j < I.cols; ++j ){
_I(i,j)[0] = table[_I(i,j)[0]];
_I(i,j)[1] = table[_I(i,j)[1]];
_I(i,j)[2] = table[_I(i,j)[2]];
}
I = _I;
break;
}
}
return I;
}该函数采用您的输入类型和坐标,并计算查询项的地址。然后返回对该的引用。当您获得值时,这可能是一个常量,而当您设置值时,这可能是一个非常量。作为仅在调试模式*下的安全步骤,将执行检查输入坐标是否有效且确实存在。如果不是这种情况,您将在标准错误输出流上收到一个很好的输出消息。与发布模式下的有效方式相比,使用它的唯一区别是,对于图像的每个元素,您将获得一个新的行指针,用于我们使用 C 运算符 [] 来获取列元素。
如果需要使用此方法对图像进行多次查找,则为每个访问输入类型和 at 关键字可能会很麻烦且耗时。为了解决这个问题,OpenCV 有一个 cv::Mat_ 数据类型。它与 Mat 相同,但额外的需求是,在定义时,您需要通过查看数据矩阵的内容来指定数据类型,但是作为回报,您可以使用 operator()来快速访问项目。为了让事情变得更好,这很容易从通常的 cv::Mat 数据类型转换到通常的 cv::Mat 数据类型。在上述函数的彩色图像的情况下,您可以看到此示例用法。不过,需要注意的是,相同的操作(具有相同的运行时速度)可以使用 cv::Mat::at 函数完成。这只是为懒惰的程序员技巧写的一个少。
核心功能
这是在图像中实现查找表修改的奖励方法。在图像处理中,通常要将所有给定的图像值修改为其他值。OpenCV提供了修改图像值的功能,无需编写图像的扫描逻辑。我们使用核心模块的 cv::LUT() 函数。首先,我们构建一个 Mat 类型的查找表:
Mat lookUpTable(1, 256, CV_8U);
uchar* p = lookUpTable.ptr();
for( int i = 0; i < 256; ++i)
p[i] = table[i];最后调用函数(I 是我们的输入图像,J 是输出图像):
LUT(I, lookUpTable, J);性能差异
为了获得最佳结果,请编译程序并自行运行。为了使差异更清晰,我使用了相当大的图像(2560 X 1600)。这里介绍的性能是针对彩色图像的。为了获得更准确的值,我将从函数调用中获得的值平均了一百次。
| 方法 | 时间 |
|---|---|
| Efficient Way | 79.4717 milliseconds |
| Iterator | 83.7201 milliseconds |
| On-The-Fly RA | 93.7878 milliseconds |
| LUT function | 32.5759 milliseconds |
我们可以得出几点结论。如果可能的话,请使用 OpenCV 已经制作的功能(而不是重新发明这些功能)。最快的方法是 LUT 函数。这是因为 OpenCV 库通过英特尔线程构建模块支持多线程。但是,如果需要编写简单的图像扫描,则首选指针方法。迭代器是一个更安全的赌注,但速度要慢得多。在调试模式下,使用动态参考访问方法进行完整图像扫描的成本最高。在发布模式下,它可能会击败迭代器方法,也可能不击败迭代器方法,但它肯定会为此牺牲迭代器的安全特性。
最后,您可以在我们的 YouTube 频道上发布的视频中观看该程序的示例运行。
参考文献:
1、《How to scan images, lookup tables and time measurement with OpenCV》----Bernát Gábor


![每日一题 --- 两两交换链表中的节点[力扣][Go]](https://img-blog.csdnimg.cn/direct/2a9479e8da8145c2bebb3303d1e20290.png)



![[leetcode] 240. 搜索二维矩阵 II](https://img-blog.csdnimg.cn/direct/a5a6570d40564dc3b6873b84f3a7ab62.png)