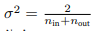本文主要介绍两个包Uber漏桶,time/rate令牌桶 可以了解到:
- 使用方法
- 漏桶/令牌桶 两种限流思想 and 实现原理
- 区别及适用场景
- 应用Case
背景
我们为了保护系统资源,防止过载,常常会使用限流器。
使用场景:
- API速率限制:防止用户恶意刷接口(当然这部分现在有公司风控部门来管控,例如whale);
- 刷数据:控制对数据库的访问速率,避免瞬时大流量打崩数据库,保护实例;
- 服务降级:例如节假日对一些非关键服务进行服务降级,保证关键服务的可用性;
- 爬虫:大多数网站具有反爬能力,需要控制爬虫速率;
限流器通用实现方案
- 固定窗口限流:
在这种方法中,时间被分割成固定的窗口,每个窗口都有一个请求的最大限制。这种方法简单易实现,但可能在窗口交界处出现请求的瞬时峰值。 - 滑动窗口限流:
滑动窗口限流是对固定窗口限流的改进,它将时间分割成更小的窗口,从而使请求分布更加均匀。这种方法可以更好地控制请求的速率,但实现起来更复杂。 - 并发限流:
并发限流是限制系统中同时处理的请求的数量。这种方法可以防止系统过载,但需要注意防止长时间的请求阻塞其他请求。 - 漏桶限流(Leaky Bucket) :
系统将请求放入桶中,然后以固定的速率从桶中取出请求进行处理,就像水从漏桶中以固定的速率漏出一样。如果桶已满,则新的请求会等待。漏桶的优点是输出数据的速率总是恒定的,无论输入数据的速率如何变化。 - 令牌桶限流(Token Bucket):
系统以固定的速率向桶中添加令牌,请求在处理前需要从桶中获取令牌,只有获取到令牌的请求才会被处理。如果桶中没有足够的令牌,则请求需要等待或被拒绝。令牌桶的优点是能够应对突发流量,因为在低流量时期,未使用的令牌可以积攒起来,用于应对突发的高流量。 - 自适应限流
根据系统能够承载的最大吞吐量,来进行限流,当当前的流量大于最大吞吐的时候就限制流量进入,反之则允许通过;需要一个机器指标来做触发阈值,常见的选择一般是机器负载、CPU 使用率,总体平均响应时间、入口 QPS 和并发线程数等。
本文我们主要聚焦于 漏桶限流 和 令牌桶限流。这两种方法分别有两种代表性的包
- 漏桶限流:Uber开源的第三方包,目前4k Stars,MIT license 主要用于服务限流GitHub - uber-go/ratelimit: A Go blocking leaky-bucket rate limit implementation
- 令牌桶限流:Go标准库,应用广泛golang.org/x/time/rate
Uber “改良版”的漏桶限流
漏桶的基本思想是将该组件想象成一个出口大小固定的桶,输出的数据流只能以固定的速率输出。
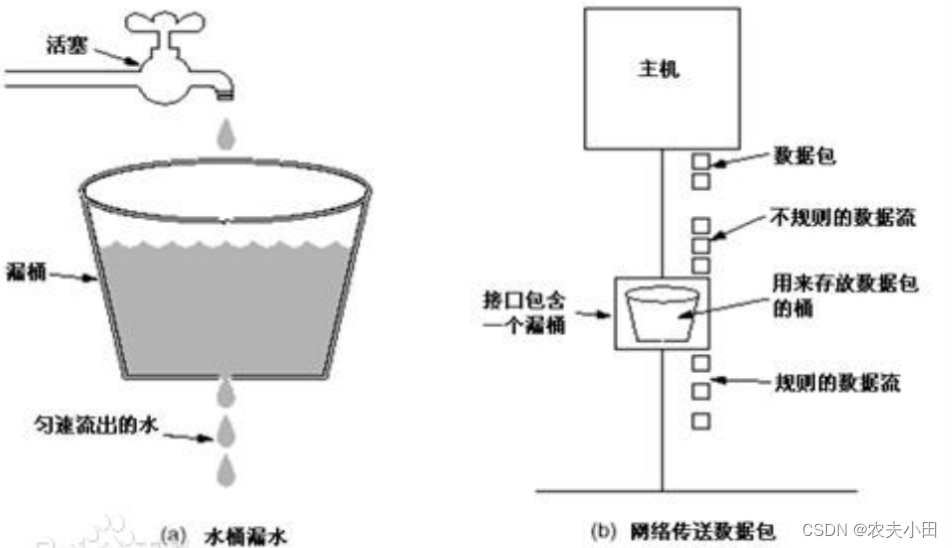
GitHub - uber-go/ratelimit: A Go blocking leaky-bucket rate limit implementation 包采用的是“改良版的漏桶”方式实现。
为什么这么说呢?因为有两部分做了相关的改进:
| 漏桶实现方案 | “改良版的漏桶”方式实现 |
|---|---|
| 待处理队列Queue | 无待处理队列,直接处理 or 等待(或者可以理解为待处理队列长度=1) |
| 最大输出速率固定 | 通过松弛的方式保证整体上的QPS,输出速率可能瞬时增高,允许短时间的突发流量 |
1. 使用方法
1.1 初始化
rl := ratelimit.New(100) // per second
第一个参数代表每秒可以处理多少个请求。
1.2 限流
now := rl.Take()
如果不满足条件(请求速率过快),Take方法将会阻塞一段时间,直至满足条件。如果时间条件满足则直接返回。(可以类比下文标准库中的 Wait 方法)
1.3 举个🌰
import (
"fmt"
"time"
"go.uber.org/ratelimit"
)
func main() {
rl := ratelimit.New(100) // per second
prev := time.Now()
for i := 0; i < 10; i++ {
now := rl.Take()
fmt.Println(i, now.Sub(prev))
prev = now
}
}
// Output
0 0s
1 10ms
2 10ms
3 10ms
4 10ms
5 10ms
6 10ms
7 10ms
8 10ms
9 10ms
可以看到,每次执行的间隔时间为10ms
2. 原理分析
(下文介绍2023.7更新的V3版本,本人认为该思路更好理解,网上也有许多介绍V1/V2版本的做法,参考文档)
2.1 初始化New方法
// New returns a Limiter that will limit to the given RPS.
func New(rate int, opts ...Option) Limiter {
return newAtomicInt64Based(rate, opts...)
}
type Limiter interface {
// Take should block to make sure that the RPS is met.
Take() time.Time
}

创建了一个Limiter Interface,库中有四个实现,如下所示:
- atomicInt64Limiter: 使用sync/atomic并发安全+高性能的限流版本,V3版本限流
- atomicLimiter: 使用sync/atomic并发安全的限流版本
- mutexLimiter: 使用sync.Mutex并发安全的限流版本
- unlimited: 不限流
2.2 atomicInt64Limiter 对象
type atomicInt64Limiter struct {
prepadding [64]byte // 防止伪共享缓存
state int64 // 理论上本次应该执行的时间,从0开始累计(纳秒)
postpadding [56]byte // 防止伪共享缓存
perRequest time.Duration // 每次请求理论间隔时间
maxSlack time.Duration // 最大松弛量,默认值是10个请求理论间隔时间(V3版本这里是正值)
clock Clock // 休眠时间
}
// 初始化
func newAtomicInt64Based(rate int, opts ...Option) *atomicInt64Limiter {
config := buildConfig(opts)
perRequest := config.per / time.Duration(rate)
l := &atomicInt64Limiter{
perRequest: perRequest,
maxSlack: time.Duration(config.slack) * perRequest,
clock: config.clock,
}
// 原子操作,保证对state值修改过程的并发安全
atomic.StoreInt64(&l.state, 0)
return l
}
// 默认一些通用的配置
func buildConfig(opts []Option) config {
c := config{
clock: clock.New(),
slack: 10,
per: time.Second,
}
for _, opt := range opts {
opt.apply(&c)
}
return c
}
atomicInt64Limiter 对象中,prepadding和postpadding 字段,主要是用于填充 CPU 缓存行,防止伪共享缓存的。不了解的朋友可以参考这篇文章 CPU缓存体系对Go程序的影响。
2.3 限流Take 方法
该方法可以阻塞请求,保证每次请求的时间间隔。
func (t *atomicInt64Limiter) Take() time.Time {
var (
newTimeOfNextPermissionIssue int64 // 下一次请求理论执行时间
now int64 // 当前时间,纳秒
)
for {
now = t.clock.Now().UnixNano()
timeOfNextPermissionIssue := atomic.LoadInt64(&t.state) // 上一次理论执行时间
switch {
case timeOfNextPermissionIssue == 0 || (t.maxSlack == 0 && now-timeOfNextPermissionIssue > int64(t.perRequest)):
// 第一个请求 or 无最大松弛时间,不控制速度
newTimeOfNextPermissionIssue = now
case t.maxSlack > 0 && now-timeOfNextPermissionIssue > int64(t.maxSlack):
// 当前请求-上一次请求时间中间的间隔过长,大于最大松弛时间,下一次理论执行时间定义为now-最大松弛时间,即保留了最大松弛时间的长度用来调整
newTimeOfNextPermissionIssue = now - int64(t.maxSlack)
default:
// 最正常的情况,下一次请求理论执行时间 = 上一次理论执行时间 + 理论实践间隔
newTimeOfNextPermissionIssue = timeOfNextPermissionIssue + int64(t.perRequest)
}
// 更新t.state 执行时间的状态,改为newTimeOfNextPermissionIssue,如果修改成功,跳出死循环,保证并发安全
if atomic.CompareAndSwapInt64(&t.state, timeOfNextPermissionIssue, newTimeOfNextPermissionIssue) {
break
}
}
// 计算需要休眠的时间,如果是正数,那么需要休眠对应的时间
sleepDuration := time.Duration(newTimeOfNextPermissionIssue - now)
if sleepDuration > 0 {
t.clock.Sleep(sleepDuration)
return time.Unix(0, newTimeOfNextPermissionIssue)
}
return time.Unix(0, now)
}
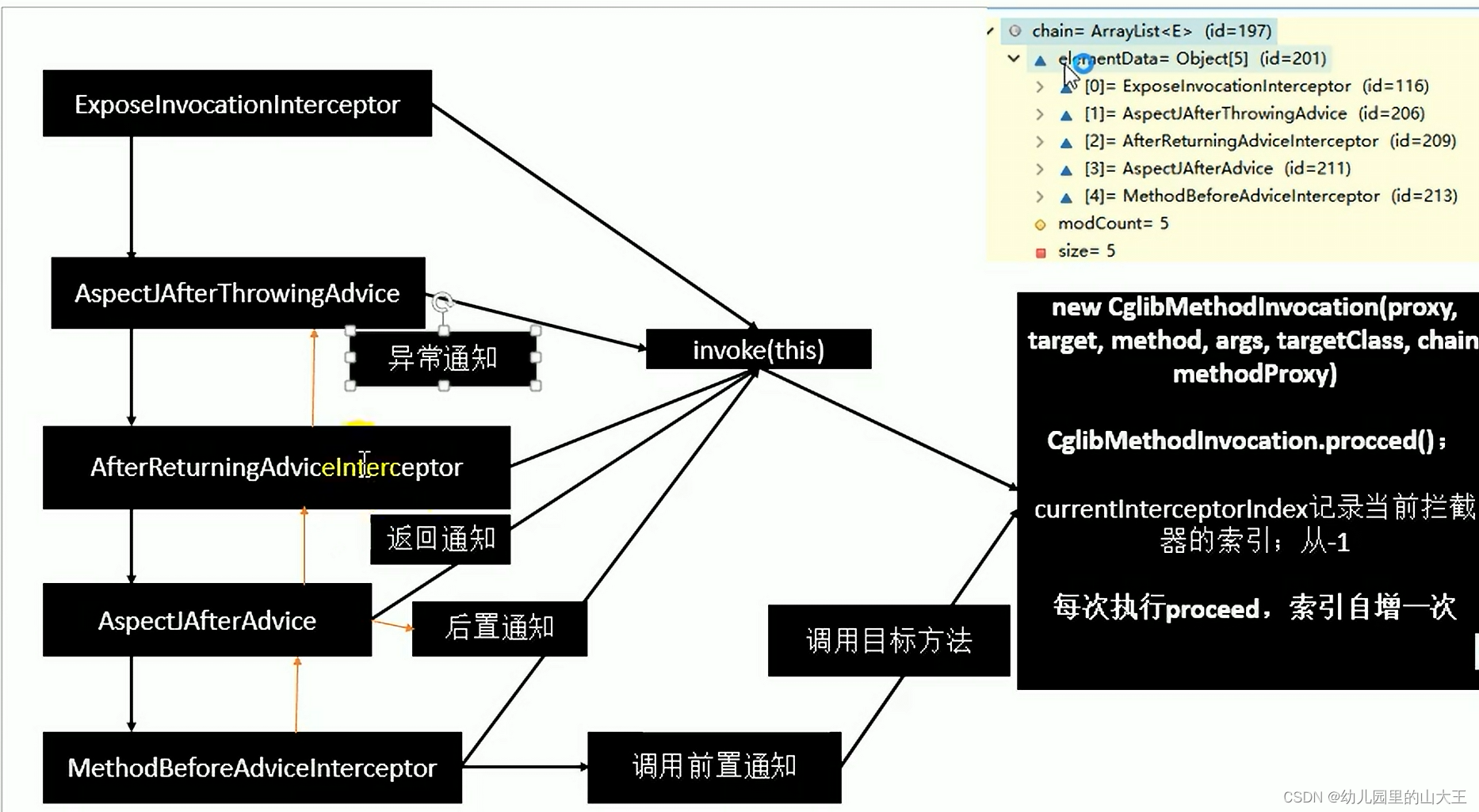
刚看到这么复杂的逻辑,一定心里发怵,但是说实话已经比V2版本的清晰多了。下面画个图跟大家讲一下。
3. Case分析
假定限定 100ms 执行一个请求
-
Case1:如果请求2提前到来
-
结论:会等待到理论时间间隔再执行
1. 请求1到来,命中switch中第一个条件 case timeOfNextPermissionIssue == 0 ,为(t *atomicInt64Limiter).State = now = 0,sleepDuration=0,请求1直接执行
2. 请求2在50ms时到来,命中switch中default条件,计算得到请求2的理论执行时间newTimeOfNextPermissionIssue = timeOfNextPermissionIssue + int64(t.perRequest) = 0+100ms = 100ms并更新(t *atomicInt64Limiter).State =newTimeOfNextPermissionIssus = 100ms,由于sleepDuration := time.Duration(newTimeOfNextPermissionIssue - now) = 100ms - 50ms = 50ms,系统休眠50ms,即阻塞执行,最后返回请求2实际执行时间 100ms -
Case2:如果请求2延迟到来,请求3提前到来
-
结论:请求2直接执行,请求3仅需要等待到200ms时执行,使三个请求整体上看间隔时间平均100ms,具有一定的松弛度
1. 请求1到来,同上,(t *atomicInt64Limiter).State = now = 0,sleepDuration=0,请求1直接执行
2. 请求2在130ms时到来,命中switch中default条件,计算得到请求2的理论执行时间newTimeOfNextPermissionIssue = timeOfNextPermissionIssue + int64(t.perRequest) = 0+100ms = 100ms并更新(t *atomicInt64Limiter).State =newTimeOfNextPermissionIssus = 100ms,由于sleepDuration := time.Duration(newTimeOfNextPermissionIssue - now) = 100ms - 130ms = -30ms,休眠时间为负数,即请求2直接在到来时刻130ms时执行
3. 请求3在180ms时到来,命中switch中default条件,计算得到请求2的理论执行时间newTimeOfNextPermissionIssue = timeOfNextPermissionIssue + int64(t.perRequest) = 100ms+100ms = 200ms并更新(t *atomicInt64Limiter).State =newTimeOfNextPermissionIssus = 200ms,由于sleepDuration := time.Duration(newTimeOfNextPermissionIssue - now) = 200ms - 180ms = 20ms,休眠时间为正数,系统休眠20ms,即阻塞执行,最后返回请求3实际执行时间 200ms,这里比较关键,请求3与请求2的间隔实际为200ms-130ms=70ms,并不是理论上每个间隔严格保证100ms,仅是保证整体上间隔平均时间为100ms -
Case3:如果请求2与请求1间隔时间非常长,请求3及其后续密集到来
这个场景非常极端,由于请求2-请求1过长,后续都会在请求发送时刻执行,导致后续会限流失效,因为并没有违背整体上的10QPS的要求。
所以这里引入了一个概念最大松弛时间(10倍的请求间隔时间),用来保证后续限流的正常执行。 -
结论:请求2直接执行,请求3-请求12在请求发送时刻执行,请求13休眠,开始限流。
1. 请求2在2100ms时到来,命中switch中t.maxSlack > 0 && now-timeOfNextPermissionIssue > int64(t.maxSlack)(2100ms-0>1000ms)条件,给予最大松弛时间的额度,newTimeOfNextPermissionIssue = now - int64(t.maxSlack) = 2100ms - 1000ms = 1100ms,远大于正常用default计算出来的100ms。由于sleepDuration := time.Duration(newTimeOfNextPermissionIssue - now) = 1100ms - 2100ms = -1000ms,休眠时间为负数,即请求2直接在到来时刻2100ms时执行
2. 请求3在2105ms到来,命中switch中的default条件,newTimeOfNextPermissionIssue = timeOfNextPermissionIssue + int64(t.perRequest)=1100ms+100ms = 1200ms,由于sleepDuration := time.Duration(newTimeOfNextPermissionIssue - now) = 1200ms - 2105ms = -905ms,休眠时间为负数,即请求3直接在到来时刻2105ms时执行
3. 请求4-请求12与请求3类似,命中switch中的default条件,直接执行。(假设间隔5ms到来)
4. 请求13在2155ms到来,命中switch中的default条件,newTimeOfNextPermissionIssue = timeOfNextPermissionIssue + int64(t.perRequest)=1200ms+10*100ms = 2200ms,由于sleepDuration := time.Duration(newTimeOfNextPermissionIssue - now) = 2200ms - 2155ms = 45ms,休眠45ms,在2200ms时执行
time/rate令牌桶Plus
标准令牌桶方案,想象有一个固定大小的桶,系统会以恒定速率向桶中放Token,桶满则暂时不放。 而用户则从桶中取Token,如果有剩余Token就可以一直取。如果没有剩余Token,则需要等到系统中被放置了Token才行。
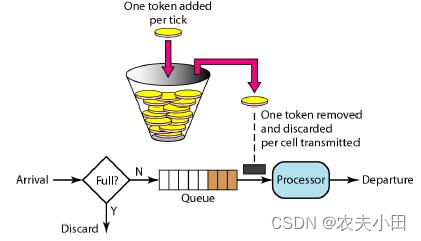
golang.org/x/time/rate 包也做了对应的改进
| 令牌桶实现方案 | “改良版的令牌桶”方式实现 |
|---|---|
| 待处理队列Queue | 无待处理队列,直接处理 or 等待(或者可以理解为待处理队列长度=1) |
| 定时产生token | 懒加载方式,新请求到来时才根据时间差更新token数目 |
1. 使用方法
1.1 初始化
limiter := NewLimiter(10, 1);
这里有两个参数:
- 第一个参数是r Limit,(QPS)代表每秒可以向Token桶中产生多少token。
- 第二个参数是b int。b代表Token桶的容量大小。(通过设置较大的 桶容量 值,服务可以在短时间内处理大量的请求,从而更好地应对请求峰值。然后,当请求峰值过去后,你的服务可以以 limit 指定的速率继续处理请求,从而避免长期占用过多的系统资源——换句话说这个参数就是“瞬时能处理的上限”)
1.2 限流
- Wait/WaitN
func (lim *Limiter) Wait(ctx context.Context) (err error)
func (lim *Limiter) WaitN(ctx context.Context, n int) (err error)
- Wait实际上就是WaitN(ctx,1)。
- 该方法可以类比上文中的Take方法。
- 当使用Wait方法消费Token时,如果此时桶内Token数组不足(小于N),那么Wait方法将会阻塞一段时间,直至Token满足条件。如果充足则直接返回。
- 这里可以看到,Wait方法有一个context参数。 我们可以设置context的Deadline或者Timeout,来决定此次Wait的最长时间。
- Allow/AllowN
func (lim *Limiter) Allow() bool
func (lim *Limiter) AllowN(now time.Time, n int) bool
- 跟 wait 方法的区别是,返回了bool值,如果为true,则允许本次操作,如果为false,则不允许本次操作
- Reserve/ReserveN
func (lim *Limiter) Reserve() *Reservation
func (lim *Limiter) ReserveN(now time.Time, n int) *Reservation
- 必定会返回结构体 *Reservation,通过它的 Delay() 方法判断等待时间
1.3 举个🌰
控制循环的速率,保证每秒只能处理1个,高峰期最高能同时处理3个。
针对Allow方法,可以看到最开始同时处理了三个请求,后两个因为没有令牌导致不处理;
针对Wait和Reserve方法,可以看到每次间隔1s左右即可执行一个。
package main
import (
"fmt"
"golang.org/x/time/rate"
"time"
)
func main() {
limiter := rate.NewLimiter(1, 3) // 每秒生成1个令牌,桶的容量为3
// 使用 Allow 方法
for i := 0; i < 5; i++ {
if limiter.Allow() {
fmt.Println("Allow: Allowed")
} else {
fmt.Println("Allow: Not allowed")
}
}
// 使用 Wait 方法
for i := 0; i < 5; i++ {
lastTime := time.Now()
if err := limiter.Wait(context.Background()); err != nil {
fmt.Println("Error:", err)
} else {
fmt.Printf("Wait: Need to wait for %v\n", time.Now().Sub(lastTime))
lastTime = time.Now()
fmt.Println("Wait: Allowed")
}
}
// 使用 Reserve 方法
for i := 0; i < 5; i++ {
reservation := limiter.Reserve()
if !reservation.OK() {
fmt.Println("Reserve: 桶数量需要大于0")
} else {
delay := reservation.Delay()
fmt.Printf("Reserve: Need to wait for %v\n", delay)
time.Sleep(delay)
fmt.Println("Reserve: Allowed")
}
}
}
Output:
Allow: Allowed
Allow: Allowed
Allow: Allowed
Allow: Not allowed
Allow: Not allowed
Wait: wait 1.000398173s
Wait: Allowed
Wait: wait 999.442232ms
Wait: Allowed
Wait: wait 1.000598372s
Wait: Allowed
Wait: wait 999.837132ms
Wait: Allowed
Wait: wait 999.69229ms
Wait: Allowed
Reserve: wait 999.572574ms
Reserve: Allowed
Reserve: wait 999.376376ms
Reserve: Allowed
Reserve: wait 999.708594ms
Reserve: Allowed
Reserve: wait 999.769212ms
Reserve: Allowed
Reserve: wait 999.736995ms
Reserve: Allowed
2. 原理分析
2.1 初始化NewLimiter方法
func NewLimiter(r Limit, b int) *Limiter {
return &Limiter{
limit: r,
burst: b,
}
}
type Limiter struct {
mu sync.Mutex // 锁,并发安全
limit Limit // 每秒产生多少token,(QPS)
burst int // 桶的最大值
tokens float64 // 此刻桶内token数量
// last is the last time the limiter's tokens field was updated
last time.Time // 上一次tokens更新的时间
// lastEvent is the latest time of a rate-limited event (past or future)
lastEvent time.Time
}
2.2 限流方法
包中提供的限流算法本质都是一个reserveN
为了方便理解,我们重点看Wait方法(更方便和上文Take方法作比较)
func (lim *Limiter) Wait(ctx context.Context) (err error) {
return lim.WaitN(ctx, 1)
}
func (lim *Limiter) WaitN(ctx context.Context, n int) (err error) {
// The test code calls lim.wait with a fake timer generator.
// This is the real timer generator.
newTimer := func(d time.Duration) (<-chan time.Time, func() bool, func()) {
timer := time.NewTimer(d)
return timer.C, timer.Stop, func() {}
}
return lim.wait(ctx, n, time.Now(), newTimer)
}
// Params:
// ctx 用于计算最长超时不超过ctx存活时间
// n 每一个请求需要多少令牌数,一般为1
// t 当前时间
// newTimer 休眠定时函数
func (lim *Limiter) wait(ctx context.Context, n int, t time.Time, newTimer func(d time.Duration) (<-chan time.Time, func() bool, func())) error {
// 赋值上锁
lim.mu.Lock()
burst := lim.burst
limit := lim.limit
lim.mu.Unlock()
// 边界校验
if n > burst && limit != Inf {
return fmt.Errorf("rate: Wait(n=%d) exceeds limiter's burst %d", n, burst)
}
// 根据ctx判断需要等待的最长时间
select {
case <-ctx.Done():
return ctx.Err()
default:
}
waitLimit := InfDuration
if deadline, ok := ctx.Deadline(); ok {
waitLimit = deadline.Sub(t)
}
// 调用的核心方法,返回Reservation对象
r := lim.reserveN(t, n, waitLimit)
if !r.ok {
return fmt.Errorf("rate: Wait(n=%d) would exceed context deadline", n)
}
// 如果需要限流,休眠对应的时间
delay := r.DelayFrom(t) // 下次理论执行时间 - 当前时间
if delay == 0 {
return nil
}
ch, stop, advance := newTimer(delay)
defer stop()
advance() // only has an effect when testing
select {
case <-ch:
return nil
case <-ctx.Done():
r.Cancel()
return ctx.Err()
}
}
进一步观察reserveN方法,它最后会返回Reservation对象
type Reservation struct {
ok bool // 是否预占令牌成功,可以理解成是否执行成功
lim *Limiter // 额外存储一份外面的限流结构体
tokens int // 本次请求需要的token数量
timeToAct time.Time // 请求执行的时间
// This is the Limit at reservation time, it can change later.
limit Limit // QPS,每秒往桶中放置的数量,Limit是float64的别名
}
// Params
// t 当前时间
// n 每一个请求需要多少令牌数,一般为1
// maxFutureReserve 最长等待时间
func (lim *Limiter) reserveN(t time.Time, n int, maxFutureReserve time.Duration) Reservation {
// 实际处理过程中上锁
lim.mu.Lock()
defer lim.mu.Unlock()
// 异常校验
if lim.limit == Inf {
return Reservation{
ok: true,
lim: lim,
tokens: n,
timeToAct: t,
}
} else if lim.limit == 0 {
var ok bool
if lim.burst >= n {
ok = true
lim.burst -= n
}
return Reservation{
ok: ok,
lim: lim,
tokens: lim.burst,
timeToAct: t,
}
}
// 计算得到从当前时间桶内tokens数,具体见下面
t, tokens := lim.advance(t)
// 减去本次请求需要的token数,当前桶内还剩余的tokens数
tokens -= float64(n)
// 如果令牌数为负数,说明需要进行等待。
// 根据令牌数(token/limit)计算等待时长
var waitDuration time.Duration
if tokens < 0 {
waitDuration = lim.limit.durationFromTokens(-tokens)
}
// 边界校验,是否预占成功
ok := n <= lim.burst && waitDuration <= maxFutureReserve
r := Reservation{
ok: ok,
lim: lim,
limit: lim.limit,
}
if ok {
r.tokens = n
r.timeToAct = t.Add(waitDuration) // 需要等待的时间
// Update state
lim.last = t
lim.tokens = tokens
lim.lastEvent = r.timeToAct
}
return r
}
advance计算得到 此刻桶内tokens数
func (lim *Limiter) advance(t time.Time) (newT time.Time, newTokens float64) {
last := lim.last
if t.Before(last) {
last = t
}
// ((当前时间 - 上次请求时间) * 每秒产生的tokens数量)+ 桶内原有tokens数 = 当前桶内tokens数
elapsed := t.Sub(last)
delta := lim.limit.tokensFromDuration(elapsed)
tokens := lim.tokens + delta
if burst := float64(lim.burst); tokens > burst { // 不超过最大桶内tokens数量
tokens = burst
}
return t, tokens
}
tokensFromDuration计算一段时间内产生的tokens数量
// 核心计算 tokens 数量的函数,秒数*每秒产生的tokens数
func (limit Limit) tokensFromDuration(d time.Duration) float64 {
if limit <= 0 {
return 0
}
return d.Seconds() * float64(limit)
}
总结一下:
- 懒加载:每次请求时,根据时间差(本次减去上次保存的时间戳位置)计算 Token 数目,判断是否需要等待
- 使用sync.Mutex锁保证并发安全
- 当令牌桶数量>请求所需的令牌数时,可以获取令牌。
- 当令牌桶数量<请求所需的令牌数时,需要看等待时间先到还是ctx超时时间哪个短。
- 如果等待时间短,可以获取令牌。
- 如果ctx超时时间短,则无法获取令牌,需要回退令牌。
3. Case分析
分析Wait方法,假定限定 100ms 执行一个请求(QPS=10),桶容量为1
-
Case1:如果请求2提前到来
-
结论:会等待到理论时间间隔再执行
1. 请求1到来,lim.advance(t)返回此刻tokens数为1,消耗一个token,不需要等待。
2. 请求2在50ms时到来,lim.advance(t)计算逻辑,((当前时间 - 上次请求时间) * 每秒产生的tokens数量)+ 桶内原有tokens数 = (50ms-0)/ 1000 * 10+0 = 0.5 ,即当前时刻tokens=0.5,tokens -= float64(n) 消耗掉本次token需要的数目,tokens = -0.5,waitDuration = lim.limit.durationFromTokens(-tokens)=0.5 / 10 s= 50ms,通过r.DelayFrom(t)方法得到需要等待50ms,最后返回请求2实际执行时间 100ms -
Case2:如果请求2延迟到来,请求3提前到来
-
结论:请求2直接执行,请求3仍需要等待(与请求2间隔100ms)再执行——由于没有松弛度的概念,跟Uber方法的区别
1. 请求1直接执行
2. 请求2在50ms时到来,lim.advance(t)计算逻辑,((当前时间 - 上次请求时间) * 每秒产生的tokens数量)+ 桶内原有tokens数 = (130ms-0)/ 1000 * 10+0 = 1.3 ,即当前时刻tokens=1.3,tokens -= float64(n) 消耗掉本次token需要的数目,tokens = 0.3,不需要等待,直接执行。
3. 请求3在180ms时到来,lim.advance(t)计算逻辑,((当前时间 - 上次请求时间) * 每秒产生的tokens数量)+ 桶内原有tokens数 = (180ms-130ms)/ 1000 * 10+0 = 0.5 ,即当前时刻tokens=0.5,tokens -= float64(n) 消耗掉本次token需要的数目,tokens = -0.5,waitDuration = lim.limit.durationFromTokens(-tokens)=0.5 / 10 s= 50ms,通过r.DelayFrom(t)方法得到需要等待50ms,最后返回请求3实际执行时间 230ms -
Case3:桶容量=3,短时间内来了5个请求(每隔5ms)
-
结论:请求1-3直接执行,请求4-5需要等待——令牌桶的优越性
1. 请求1在0ms到来,lim.advance(t)计算逻辑,((当前时间 - 上次请求时间) * 每秒产生的tokens数量)+ 桶内原有tokens数 = (0-0)/ 1000 * 10+3 = 3 ,即当前时刻tokens=3,tokens -= float64(n) 消耗掉本次token需要的数目,tokens = 2,不需要等待,直接执行。
2. 请求2在5ms时到来,lim.advance(t)计算逻辑,((当前时间 - 上次请求时间) * 每秒产生的tokens数量)+ 桶内原有tokens数 = (5ms-0)/ 1000 * 10+2 = 2.05 ,即当前时刻tokens=2.05,tokens -= float64(n) 消耗掉本次token需要的数目,tokens = 1.05,不需要等待,直接执行。
3. 请求3在10ms时到来,lim.advance(t)计算逻辑,((当前时间 - 上次请求时间) * 每秒产生的tokens数量)+ 桶内原有tokens数 = (10ms-5ms)/ 1000 * 10+1.05 = 1.1 ,即当前时刻tokens=1.1,tokens -= float64(n) 消耗掉本次token需要的数目,tokens = 0.1,不需要等待,直接执行。
4. 请求4在15ms时到来,lim.advance(t)计算逻辑,((当前时间 - 上次请求时间) * 每秒产生的tokens数量)+ 桶内原有tokens数 = (15ms-10ms)/ 1000 * 10+0.1 = 0.15 ,即当前时刻tokens=0.15,tokens -= float64(n) 消耗掉本次token需要的数目,tokens = -0.85,waitDuration = lim.limit.durationFromTokens(-tokens)=0.85 / 10 *1000ms= 85ms,通过r.DelayFrom(t)方法得到需要等待85ms,最后返回请求3实际执行时间 100ms
对比一下
共同点
- 无待处理队列,直接处理 or 等待(或者可以理解为待处理队列长度=1)
- 可以支持限制请求的固定间隔
- 并发安全
不同点
| Uber | time/rate | |
|---|---|---|
| 限流结构体 | 较为简单 (设计了防止伪共享缓存的字段) | 较为复杂 |
| 计算方式 | 时间转化为int64,仅涉及加减 | float64形式计算,涉及乘法,成本较高 |
| 计算精确度 | 较高 | 一般高 |
| 处理突发流量 | 不支持 | 支持,通过桶最大容量 |
| 松弛度 | 支持 | 不支持 |
| 灵活度 | 可以设置是否采用最大松弛度 | 可以设置桶容量三种限流判定方法 wait, allow, reserve |
用哪个好呢?
用哪个好,从来没有标准答案,只有哪种方法最适合哪种场景。
- 请求QPS极高,要求按照时间平均
由于令牌桶的时间计算方式,是根据(时间差*QPS)获取桶的数目,这种float64+带乘法的计算过程,由于是float64形式的计算,高QPS的情况下(例如1000000),会存在一定的时间误差。因此这种情况更推荐采用Uber的包,采用int64的计算方式,且没有乘法操作,相比会有更高一些的精度。
(当然,通过本人实测,如果QPS1000以内,我感觉这两种方法没有本质的差别) - 需要具备一定量的突发流量处理能力
由于漏桶算法和令牌桶算法本质的区别,令牌桶算法能够很好地处理突发流量,因此这种场景推荐使用time/rate,可以通过设置比较大的brust(桶最大值)来保证处理突发流量的能力。 - 严格的限制请求的固定间隔
都可以,其中Uber方法时间把控更为严格,可以通过Uber方法中ratelimit.WithoutSlack参数,取消松弛量的影响。
limiter := ratelimit.New(100, ratelimit.WithoutSlack)
⭐️其他限流
分布式限流,例如Go Redis分布式限流库 https://github.com/go-redis/redis_rate
也有很多限流的包,还没来得及仔细研究,后面会做一个更加详细的对比