接上篇《50、当当网Scrapy项目实战(三)》
上一篇我们讲解了使用Scrapy框架在当当网抓取多页书籍数据的效果,本篇我们来抓取电影天堂网站的数据,同样采用Scrapy框架多页面下载的模式来实现。
一、抓取需求
打开电影天堂网站(https://dy2018.com/),点击最新电影的更多页面(https://www.dy2018.com/html/gndy/dyzz/index.html),这里需要抓取最新电影的名字,以及详情页的图片:

要完成这个目标,我们需要造Scrapy框架中封装一个里外嵌套的item对象。下面我们来进行开发。
二、创建工程及爬虫文件
首先我们打开编辑器,打开控制台,进入爬虫文件夹,使用“scrapy startproject 项目名”指令,来创建我们的爬虫工程: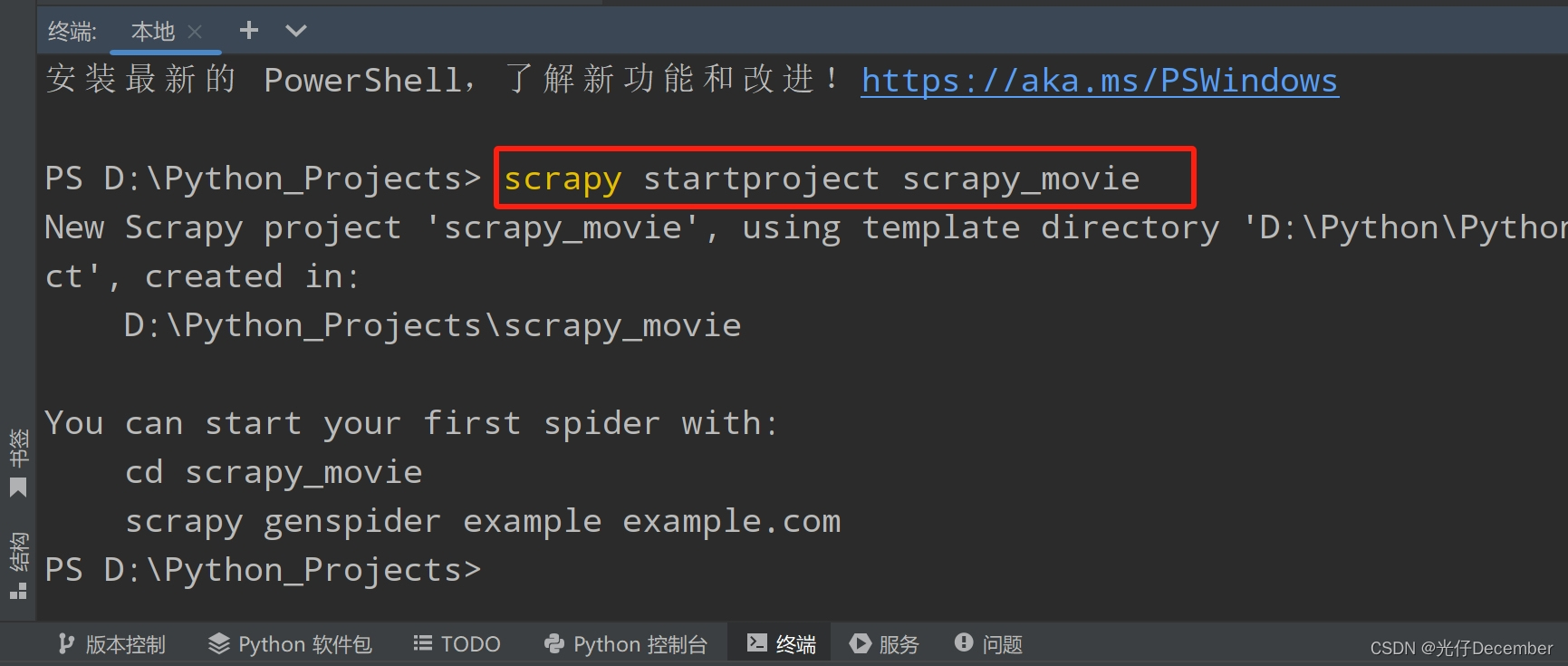

然后进入配置文件settings.py,设置ROBOTSTXT_OBEY参数为false,即不遵循robots协议。
然后进入工程文件的spiders文件夹下,使用“scrapy genspider 爬虫文件名 爬取路径”创建我们的爬虫文件,这里我命名爬虫文件为“movies”: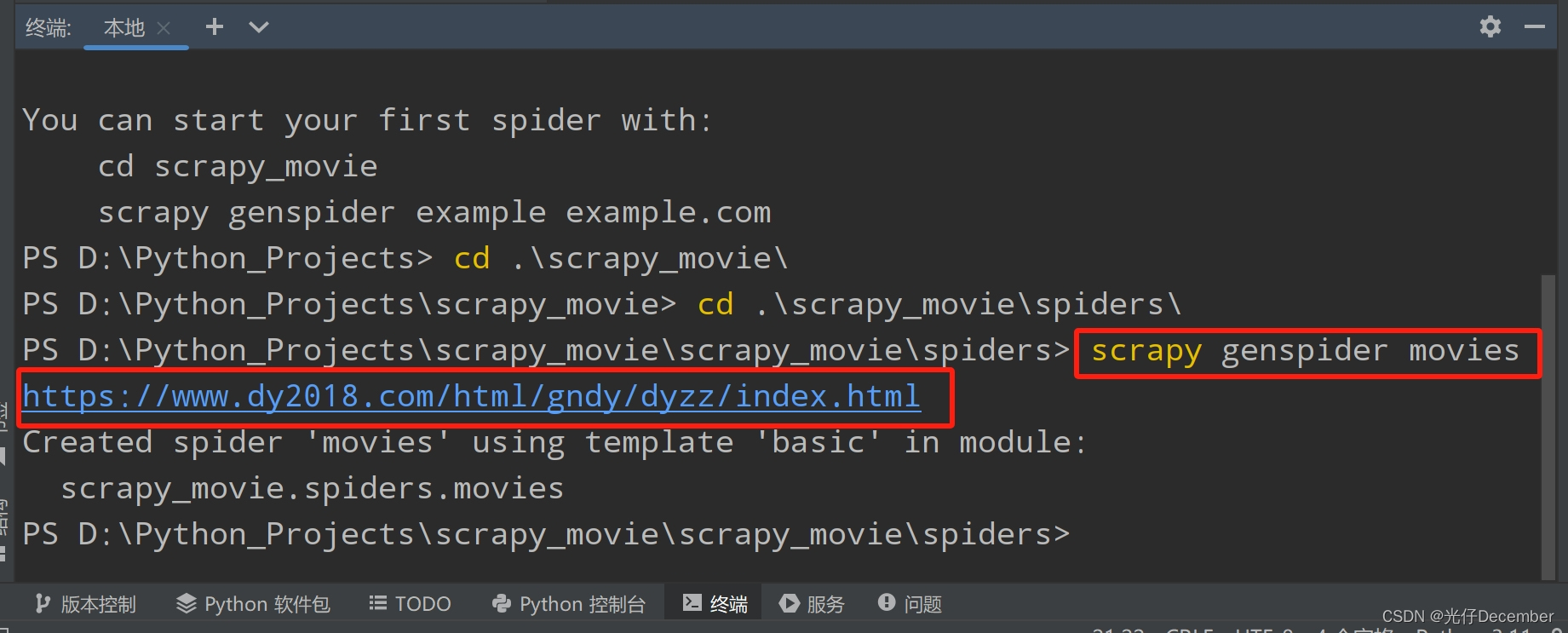

三、编写爬虫逻辑
默认生成的spider爬虫代码如下:
import scrapy
class MoviesSpider(scrapy.Spider):
name = "movies"
allowed_domains = ["www.dy2018.com"]
start_urls = ["https://www.dy2018.com/html/gndy/dyzz/index.html"]
def parse(self, response):
pass我们把其中的“pass”替换为“print("=============")”,使用“scrapy crawl 爬虫文件名”执行该爬虫:
可以看到正常输出了我们打印的等于号,可以证明网站并没有设置反爬虫。下面我们来编写实际内容,首先我们先定义我们最终要包装成的item对象:
import scrapy
class ScrapyMovieItem(scrapy.Item):
name = scrapy.Field()
src = scrapy.Field()这里我们主要定义了两个参数,一个是电影名字name,一个是电影封面地址src。
然后我们回到电影天堂列表界面,F12查看电影名字的Html代码:
可以看到是由td包裹的标签,其中a标签中的内容即为电影名字,其中的href参数为电影的详情页面地址。
然后邮件Html中的电影名所在标签,使用xpath工具,获取到电影名字的xpath路径:
xpath地址为:
/html/body/div/div/div[3]/div[6]/div[2]/div[2]/div[2]/ul/table[1]/tbody/tr[2]/td[2]/b/a这里full xpath获取的地址太长,我们再观察一下,发在它是在class为co_content8的div下面的: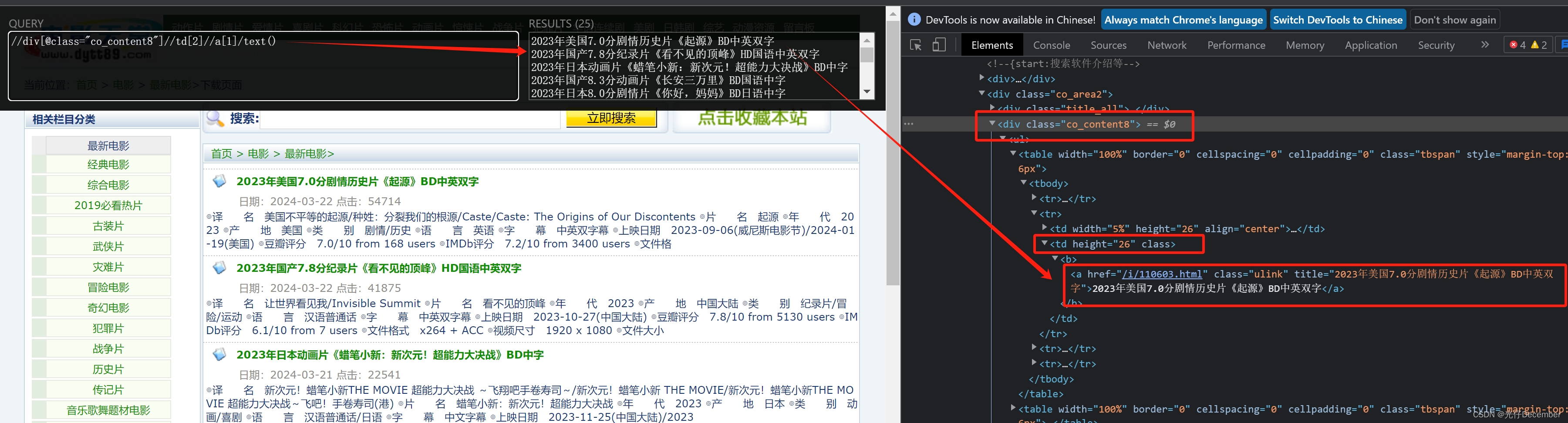
xpath地址可以缩减为:
(1)电影名称
//div[@class="co_content8"]//td[2]//a[1]/text()(2)详情地址
//div[@class="co_content8"]//td[2]//a[1]/@href所以爬虫代码可以编写为:
import scrapy
class MoviesSpider(scrapy.Spider):
name = "movies"
allowed_domains = ["www.dy2018.com"]
start_urls = ["https://www.dy2018.com/html/gndy/dyzz/index.html"]
def parse(self, response):
# 抓取电影名称以及详情页的封面
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[1]')
for a in a_list:
# 获取第一页的name和要点击的详情链接地址
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
print(name,href)执行一下爬虫,可以看到能拿到相应结果: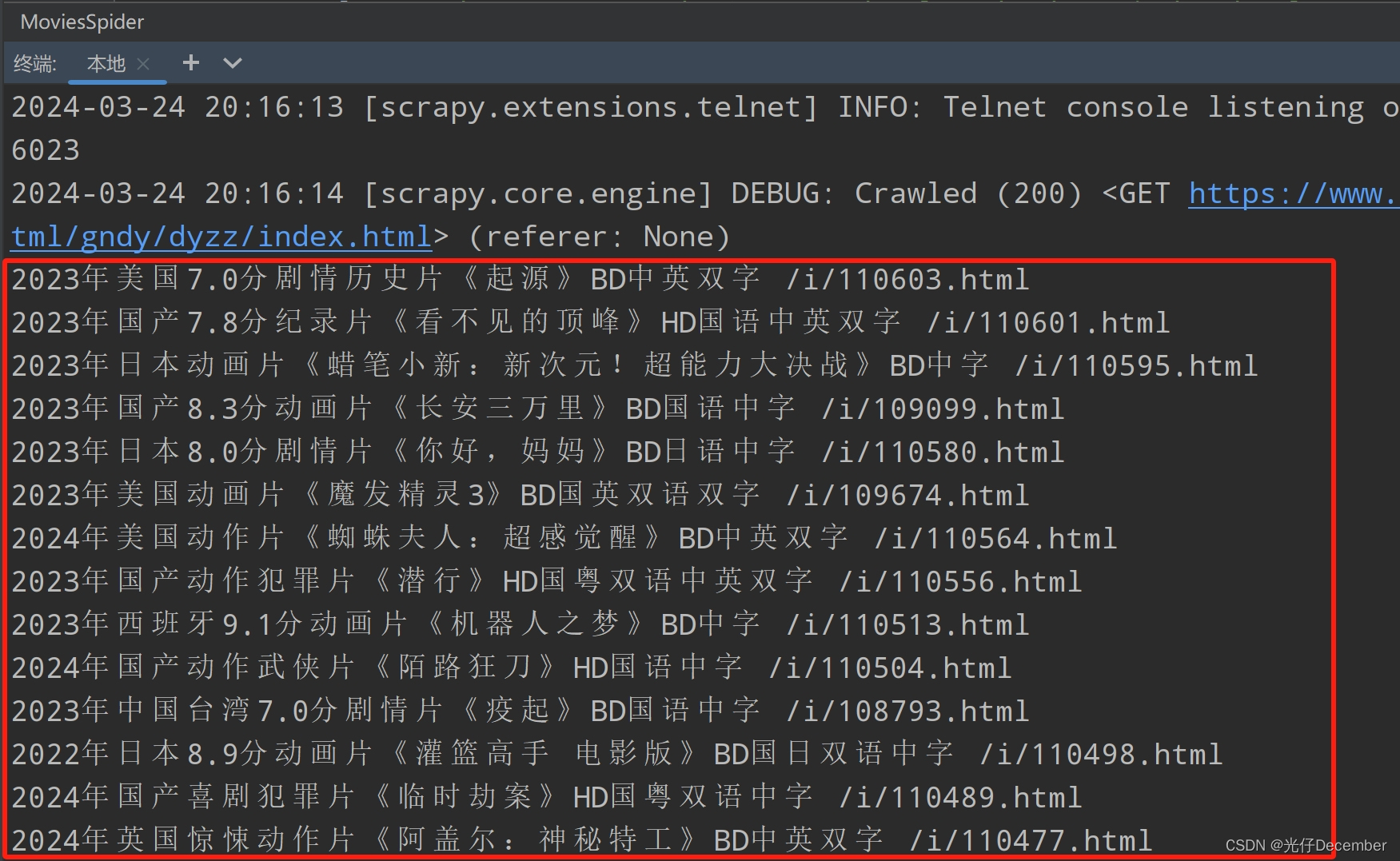
然后完善详情界面的地址,进入详情地址,然后获取详情页的图片:
import scrapy
class MoviesSpider(scrapy.Spider):
name = "movies"
allowed_domains = ["www.dy2018.com"]
start_urls = ["https://www.dy2018.com/html/gndy/dyzz/index.html"]
def parse(self, response):
# 抓取电影名称以及详情页的封面
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[1]')
for a in a_list:
# 获取第一页的name和要点击的详情链接地址
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# 拼接得到详情页地址
url = 'https://www.dy2018.com'+href
# 对第二页的链接发起访问
yield scrapy.Request(url=url, callback=self.parse_second, meta={'name': name})
def parse_second(self, response):
print("第二个解析方法")这里我们执行了第二个解析方法,并在下面定义了这个方法“parse_second”,并在上一个函数中,将name作为meta参数带入进去。
此时我们去电影天堂网站打开第一个电影的详情页,右键或F12查看电影封面:
可以大致推断出封面路径的xpath地址为:
//div[@id="Zoom"]//img[1]/@src所以解析详情图片的代码为(ScrapyMovieItem需要import一下):
def parse_second(self, response):
src = response.xpath('//div[@id="Zoom"]//img[1]/@src').extract_first()
# 获取上一步得到的meta参数中的name
name = response.meta['name']
movie = ScrapyMovieItem(name=name, src=src)
yield movie最后将封装好的movie对象返回给管道。完整代码:
import scrapy
from scrapy_movie.items import ScrapyMovieItem
class MoviesSpider(scrapy.Spider):
name = "movies"
allowed_domains = ["www.dy2018.com"]
start_urls = ["https://www.dy2018.com/html/gndy/dyzz/index.html"]
def parse(self, response):
# 抓取电影名称以及详情页的封面
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[1]')
for a in a_list:
# 获取第一页的name和要点击的详情链接地址
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# 拼接得到详情页地址
url = 'https://www.dy2018.com' + href
# 对第二页的链接发起访问
yield scrapy.Request(url=url, callback=self.parse_second, meta={'name': name})
def parse_second(self, response):
src = response.xpath('//div[@id="Zoom"]//img[1]/@src').extract_first()
# 获取上一步得到的meta参数中的name
name = response.meta['name']
print(name, src)
movie = ScrapyMovieItem(name=name, src=src)
yield movie四、开启并定义管道
此时我们前往settings.py开启管道(将ITEM_PIPELINES注释取消即可):
ITEM_PIPELINES = {
"scrapy_movie.pipelines.ScrapyMoviePipeline": 300,
}然后打开pipelines.py,编写一段逻辑,将获取的电影名字和封面地址写入一个json文件中:
# 如果需要使用管道,要在setting.py中打开ITEM_PIPELINES参数
class ScrapyMoviePipeline:
# 1、在爬虫文件开始执行前执行的方法
def open_spider(self, spider):
print('++++++++爬虫开始++++++++')
# 这里写入文件需要用'a'追加模式,而不是'w'写入模式,因为写入模式会覆盖之前写的
self.fp = open('movies.json', 'a', encoding='utf-8') # 打开文件写入
# 2、爬虫文件执行时,返回数据时执行的方法
# process_item函数中的item,就是爬虫文件yield的movie对象
def process_item(self, item, spider):
# write方法必须写一个字符串,而不能是其他的对象
self.fp.write(str(item)) # 将爬取信息写入文件
return item
# 在爬虫文件开始执行后执行的方法
def close_spider(self, spider):
print('++++++++爬虫结束++++++++')
self.fp.close() # 关闭文件写入五、执行测试
编写完item、spider、pipeline之后,我们运行爬虫,查看输出的json文件: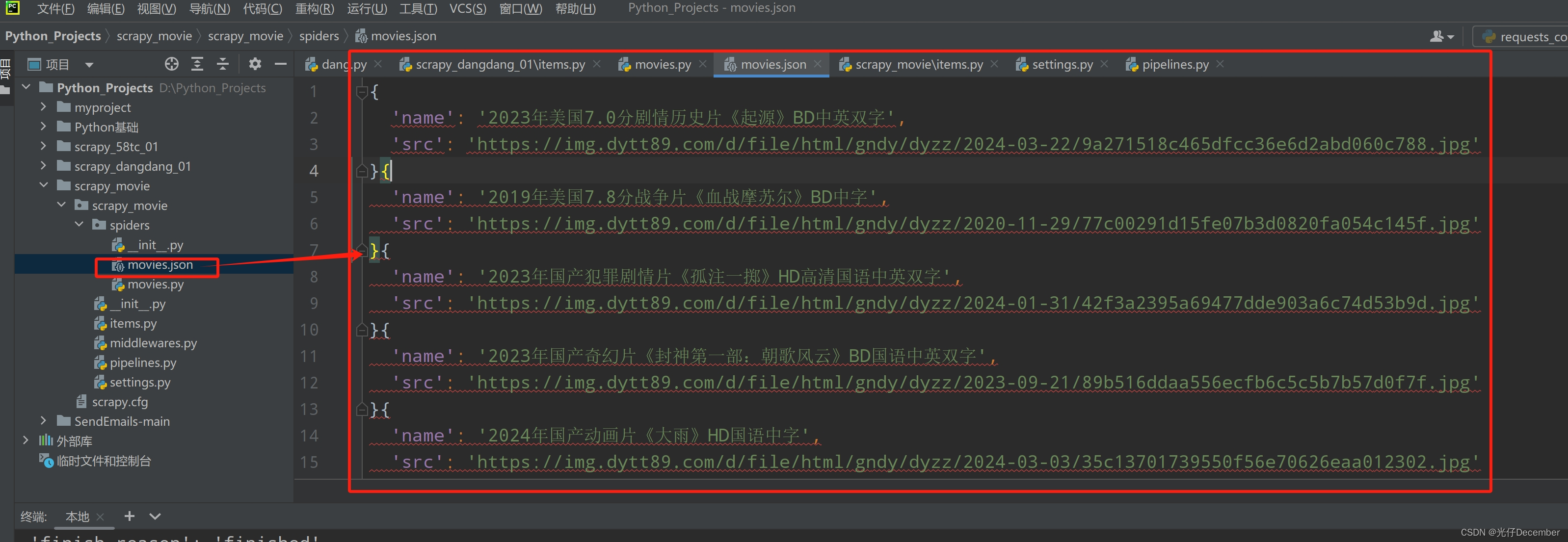
可以看到完整获取电影的名称以及封面图片的下载地址。
以上就是电影天堂网站多页面下载的实战内容。下一篇我们来讲解scrapy中链接提取器的使用。
参考:尚硅谷Python爬虫教程小白零基础速通
转载请注明出处:https://guangzai.blog.csdn.net/article/details/136994919