CSDN成就一亿技术人
目录
一.操作符
一.算数操作符:
二.位移操作符:
三.位操作符:
四.赋值操作符:
五.单目操作符:
六.关系操作符:
七.逻辑操作符:
八.条件操作符:
九.逗号表达式:
十.下标引用,函数调用和结构成员:
十一.表达式求值:
二.数据类型的存储
一.数据的类型的介绍:
1.整形家族:有符号和无符号的定义。
2.浮点型:
3.构造类型:(自定义类型)
4.指针类型:
5.空类型:
二.整形在内存中的存储:源码,反码,补码
练习:
三.大小端字节序的介绍及判断:
四.浮点型在内存中的存储解析:
操作符分类:
算数操作符
移位操作符
位操作符
赋值操作符
单目操作符
关系操作符
逻辑操作符
条件操作符
逗号表达式
下标引用,函数调用和结构成员
一.操作符
一.算数操作符:
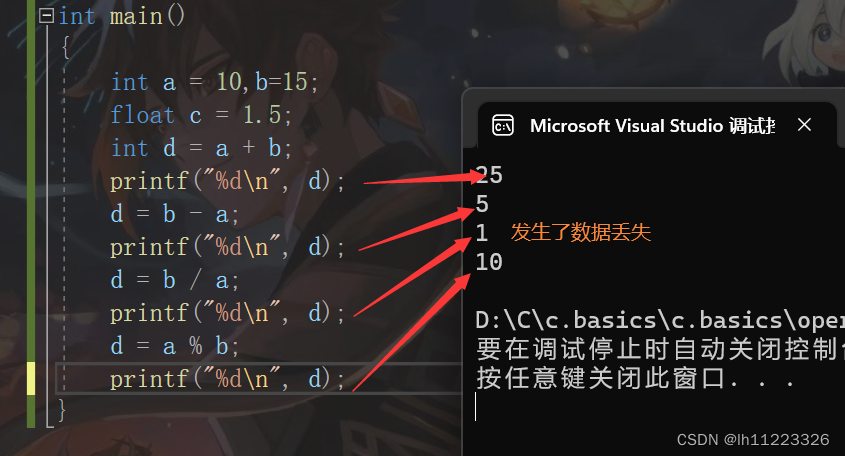
+(加法操作) -(减法操作符) *(乘法操作符) /(除法操作符) %(取余操作符)
除了%操作符之外,其他的几个操作符可以作用于正数和浮点数。
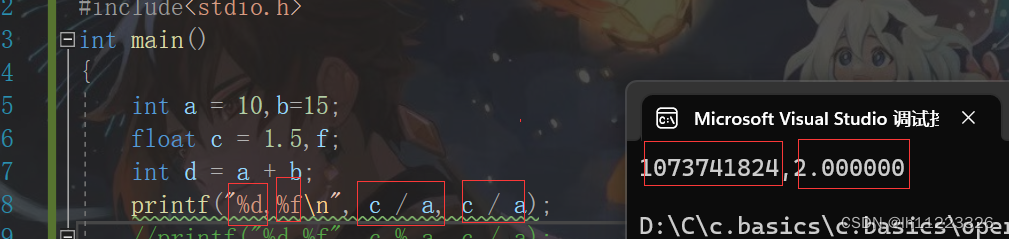
对于/操作符如果两个操作符都为整数,执行整数除法,而只要有浮点数执行除法就是浮点数除法。
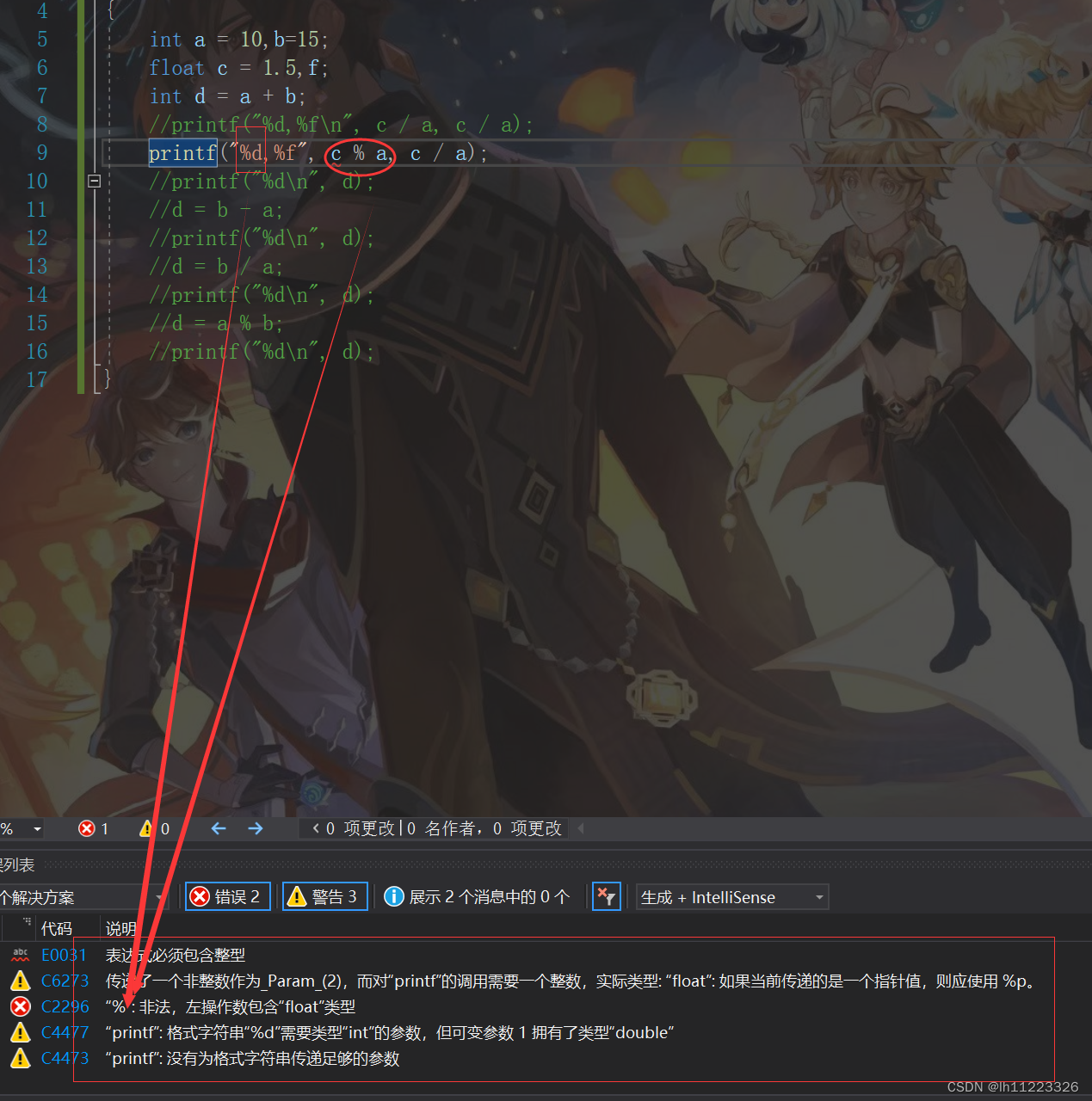
%操作符的两个操作数必须为整数。返回的是整除之后的余数。
这样的写法是错误的:
二.位移操作符:
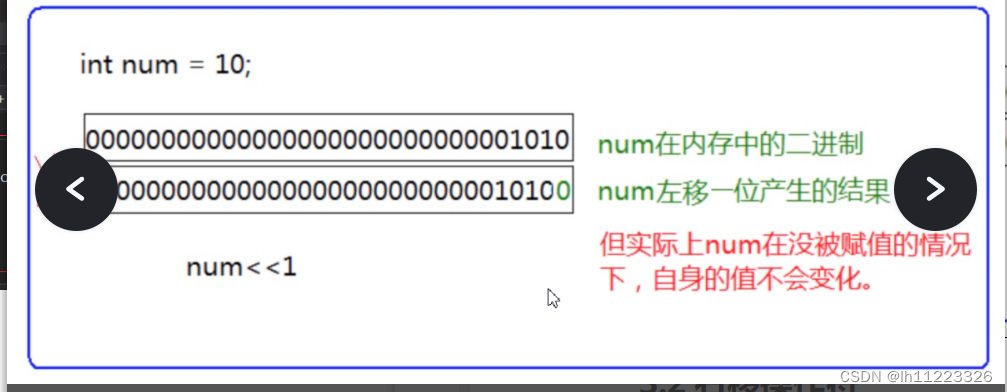
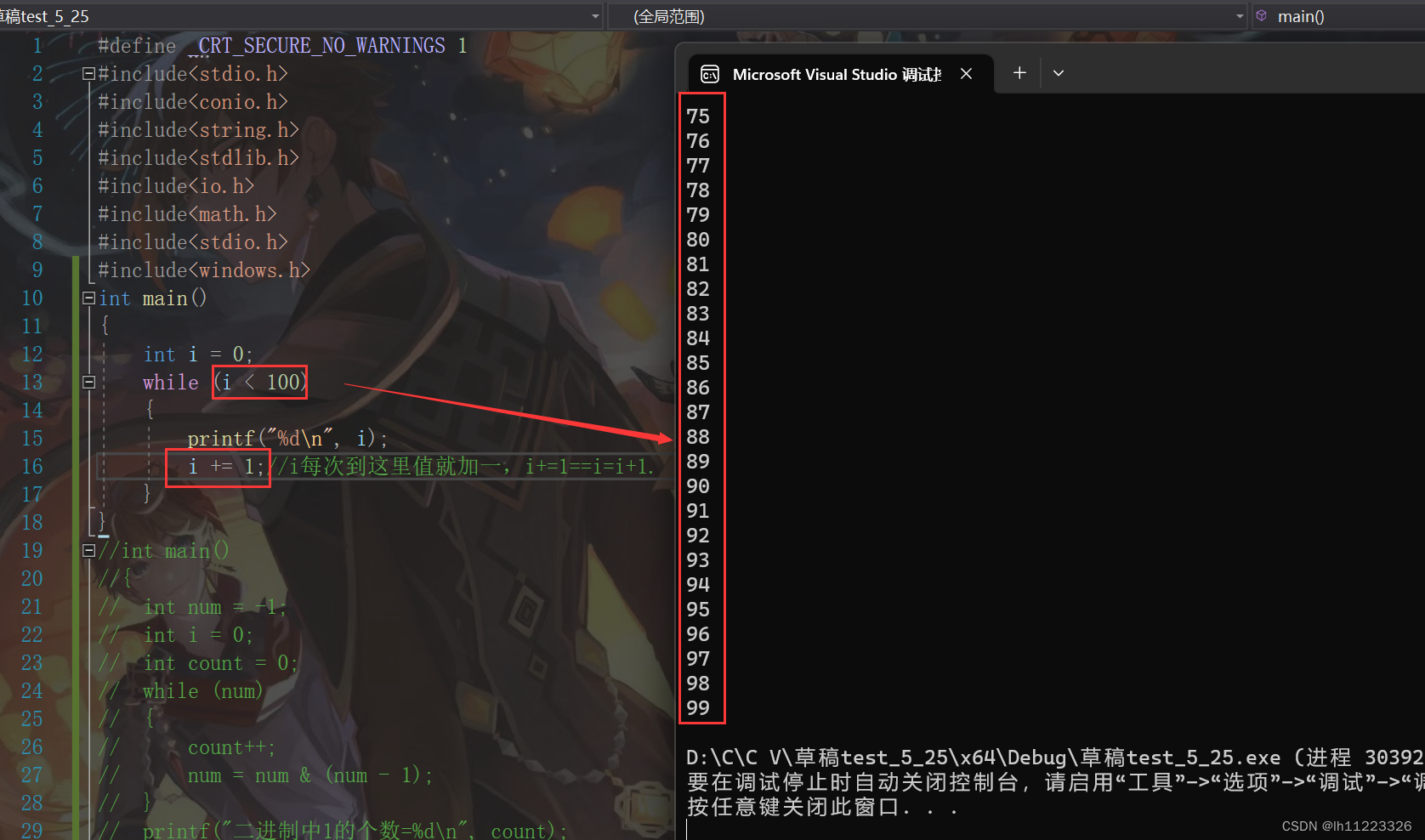
左移操作符:<< 左边抛弃,右边补0。
右移操作符:>> 逻辑位移:左边用0填充,右边丢弃。
算数移位:左边有原该值的符号位填充,右边丢弃。
对于位移运算符,不要移动负数位,这个是标准定义的:
int num=10;
num>>-1; //error

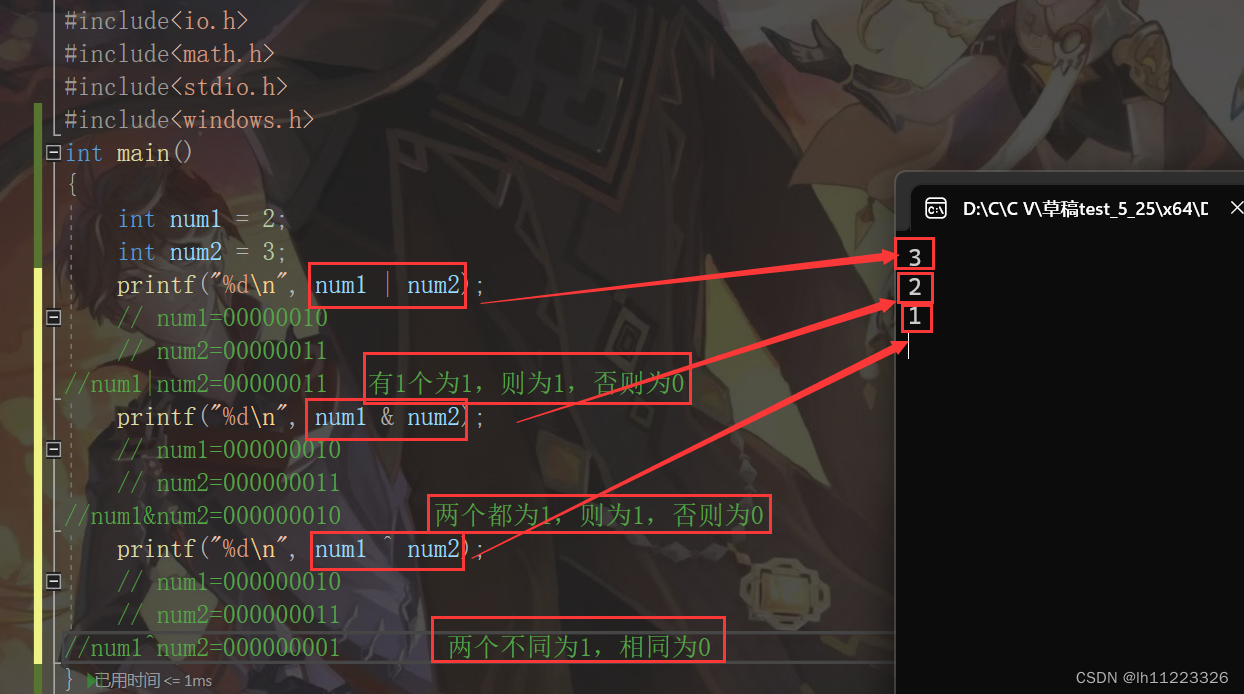
三.位操作符:
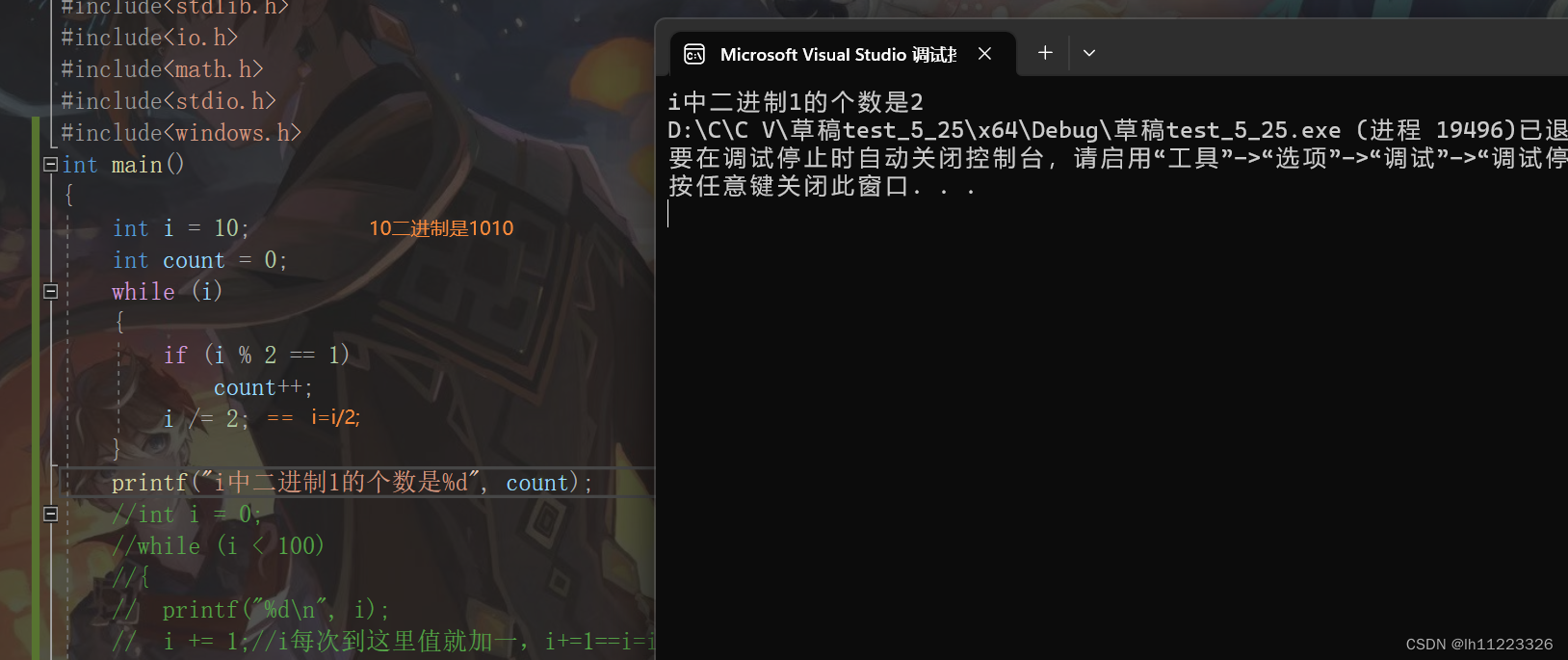
& //按位与
| //按位或
^ //按位异或
他们的操作数必须是整数。
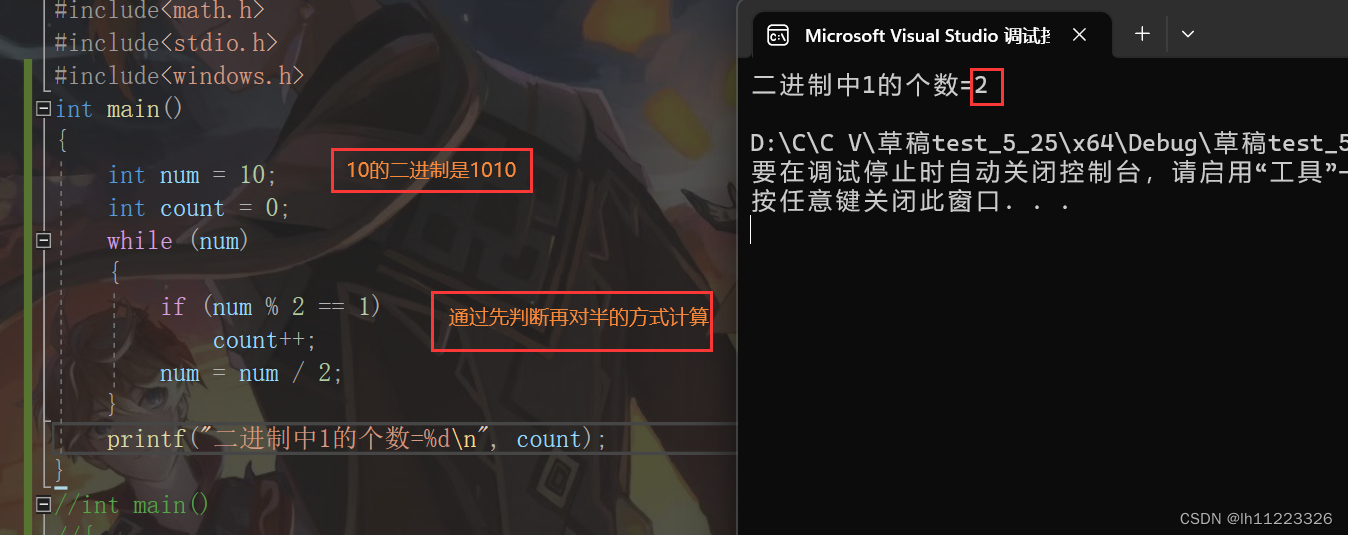
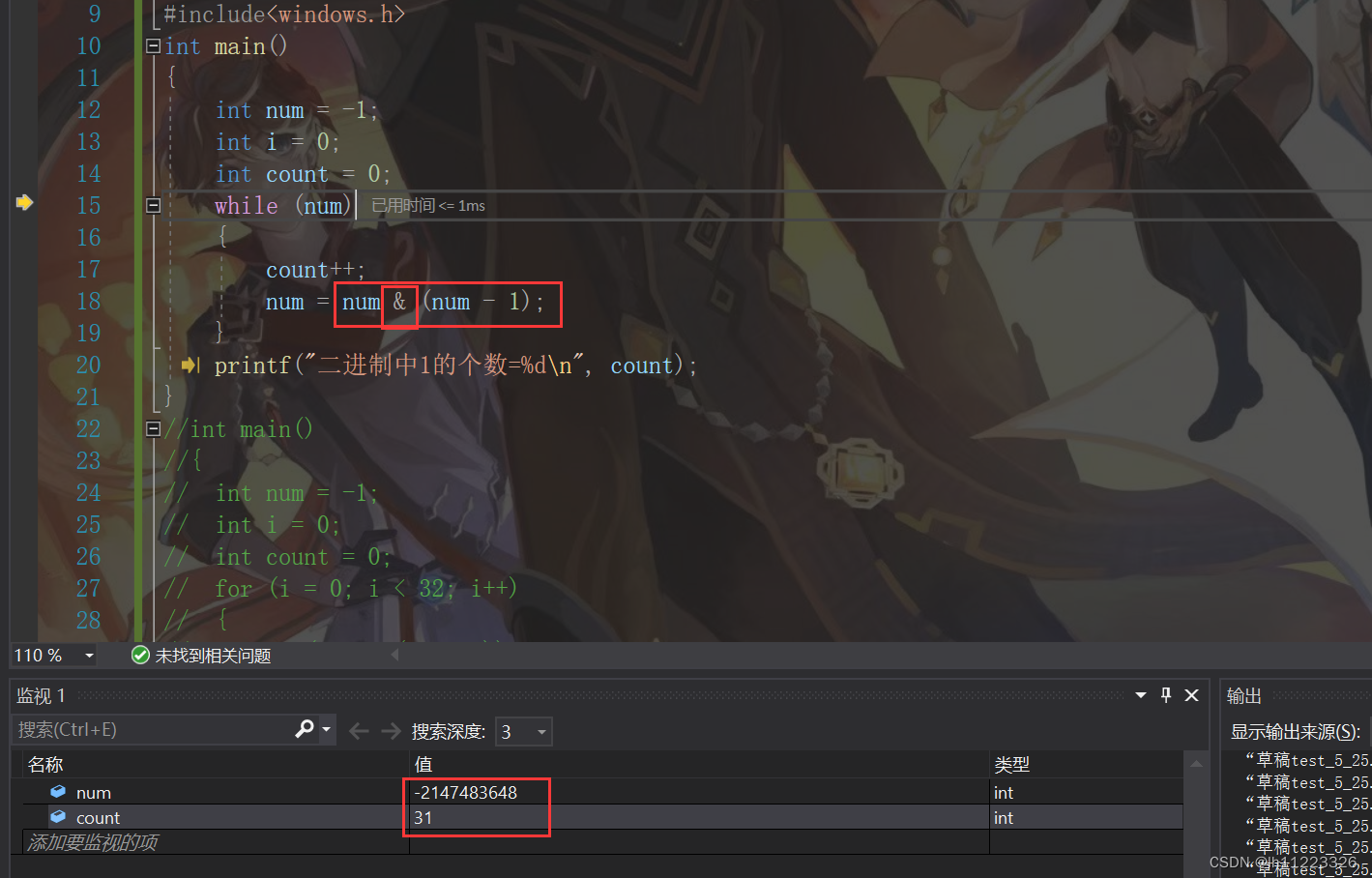
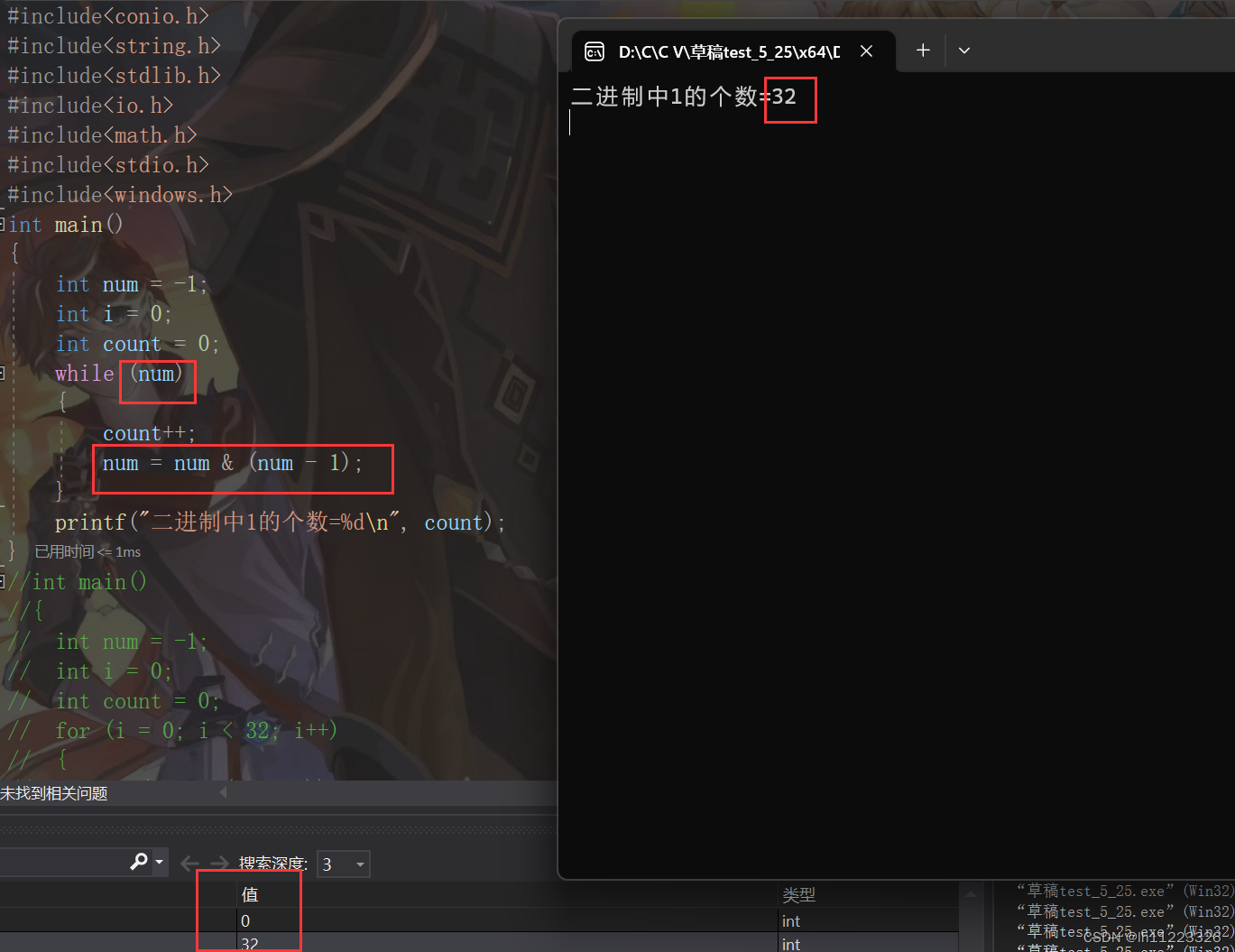
下面有几种计算一个整数中二进制的个数的方法。
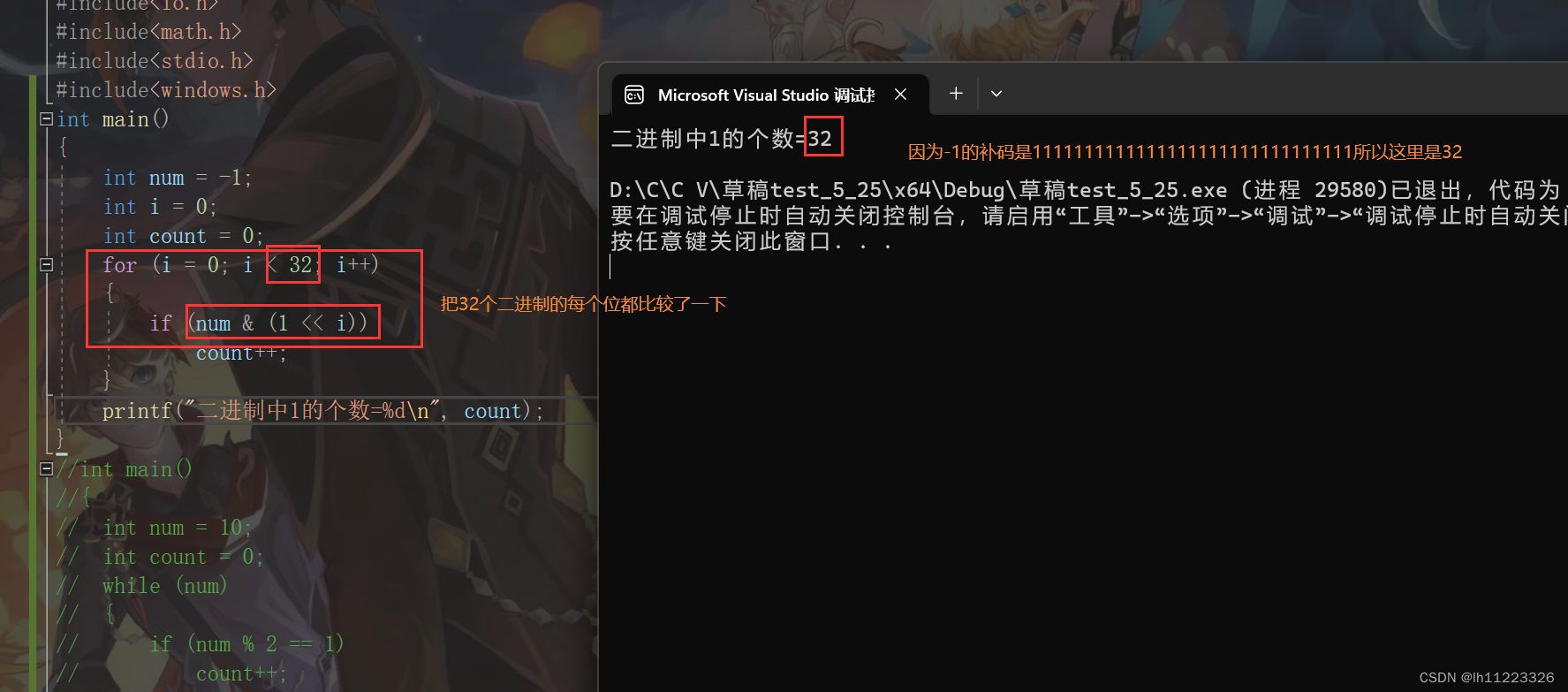
这个程序是利用了数据类型在存储中的特性
四.赋值操作符:
赋值操作符他可以让你对不满意的值,进行重新赋值比如:
int weight=120; //体重
weight=89; //不满意就赋值
double salary=10000.0;
salary=20000.0; //使用赋值操作符赋值
赋值操作符可以连续使用:
int a=10;
int x=0;
int y=20;
a=x=y+1; //连续赋值
复合赋值符:
+= -= *= /= %= >>= <<= &= |= ^=
可以这样写:
int x=10;
x=x+10;
x+=10; //复合赋值
可以用复合赋值符写这几种代码:
五.单目操作符:
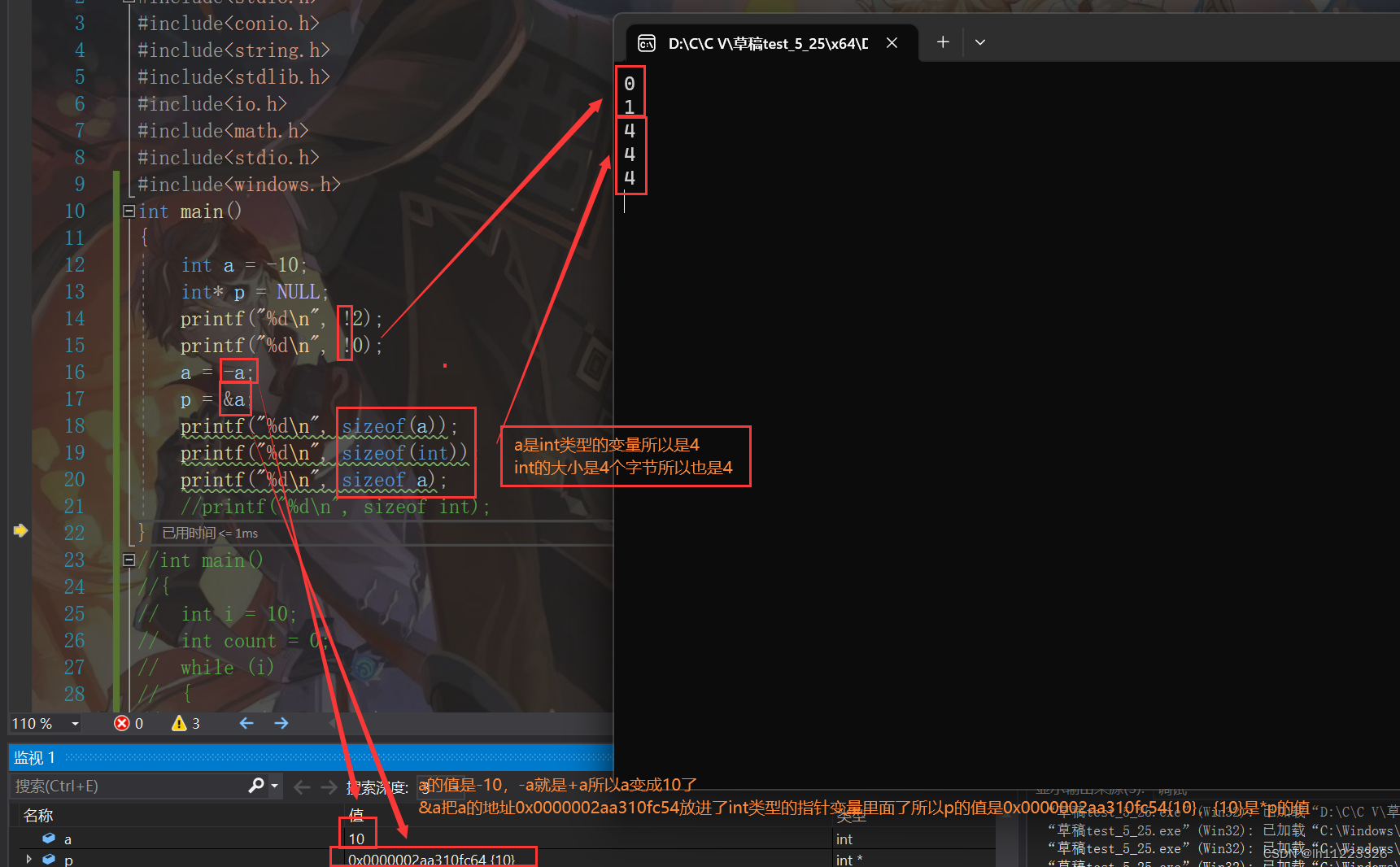
! 逻辑反操作
- 负数
+ 正数
& 取地址
sizeof 操作数的类型长度(以字节为单位)
~ 对一个数的二进制按位取反
-- 前置,后置--
++ 前置,后置++
* 间接访问操作符(解引用操作符)
(类型) 强制类型转换
sizeof和数组。
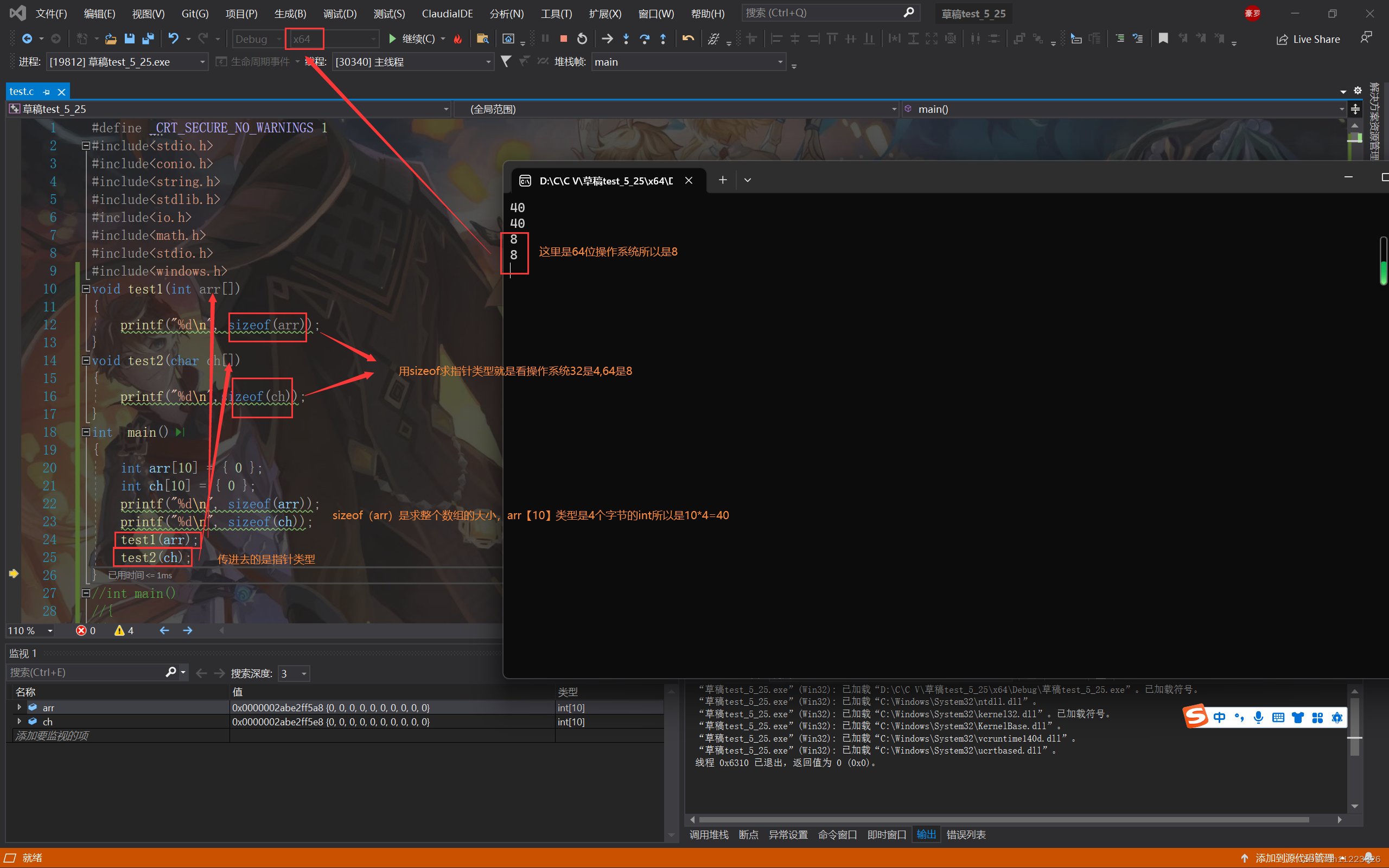
前置和后置--,++的区别:前置
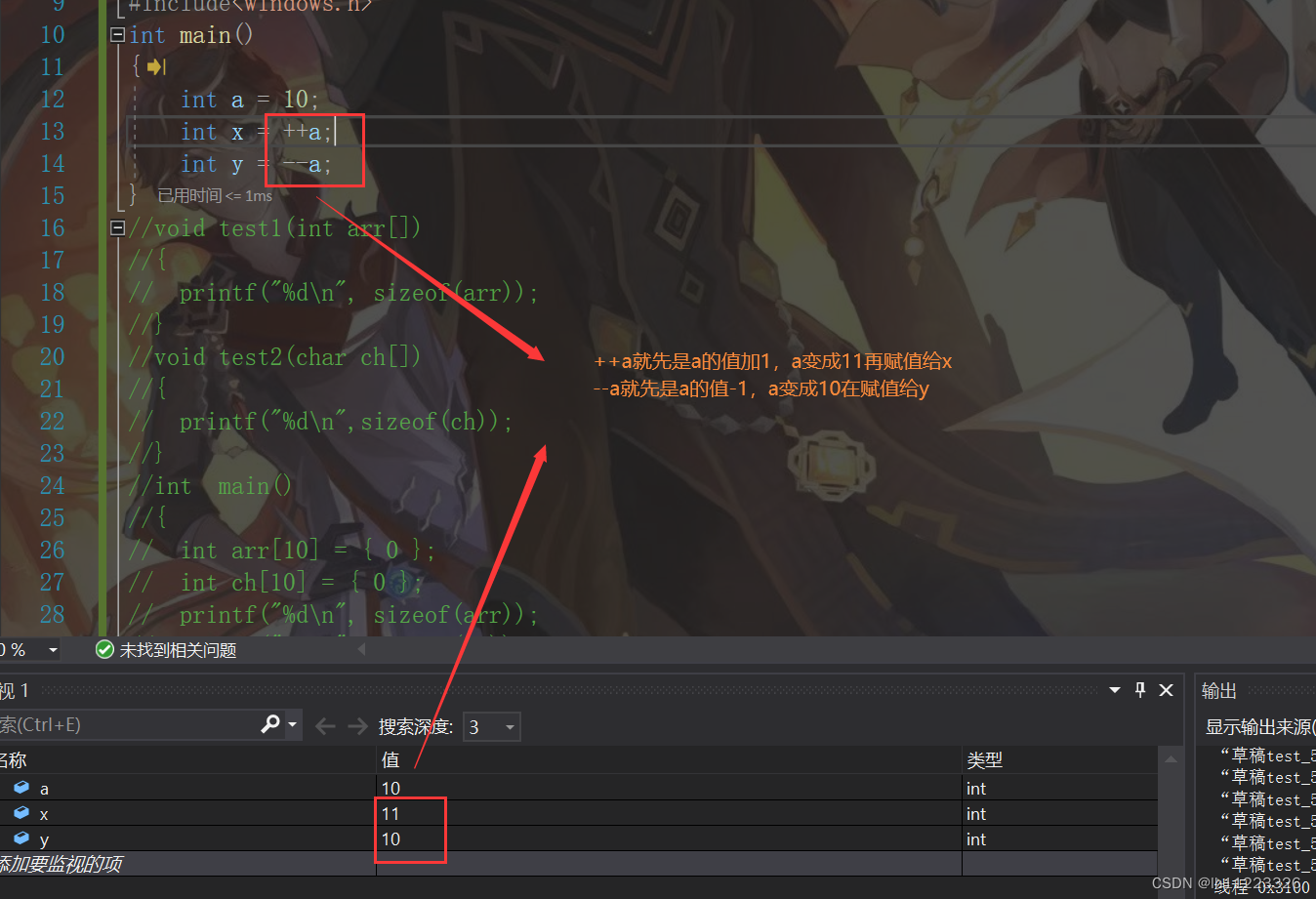
后置:
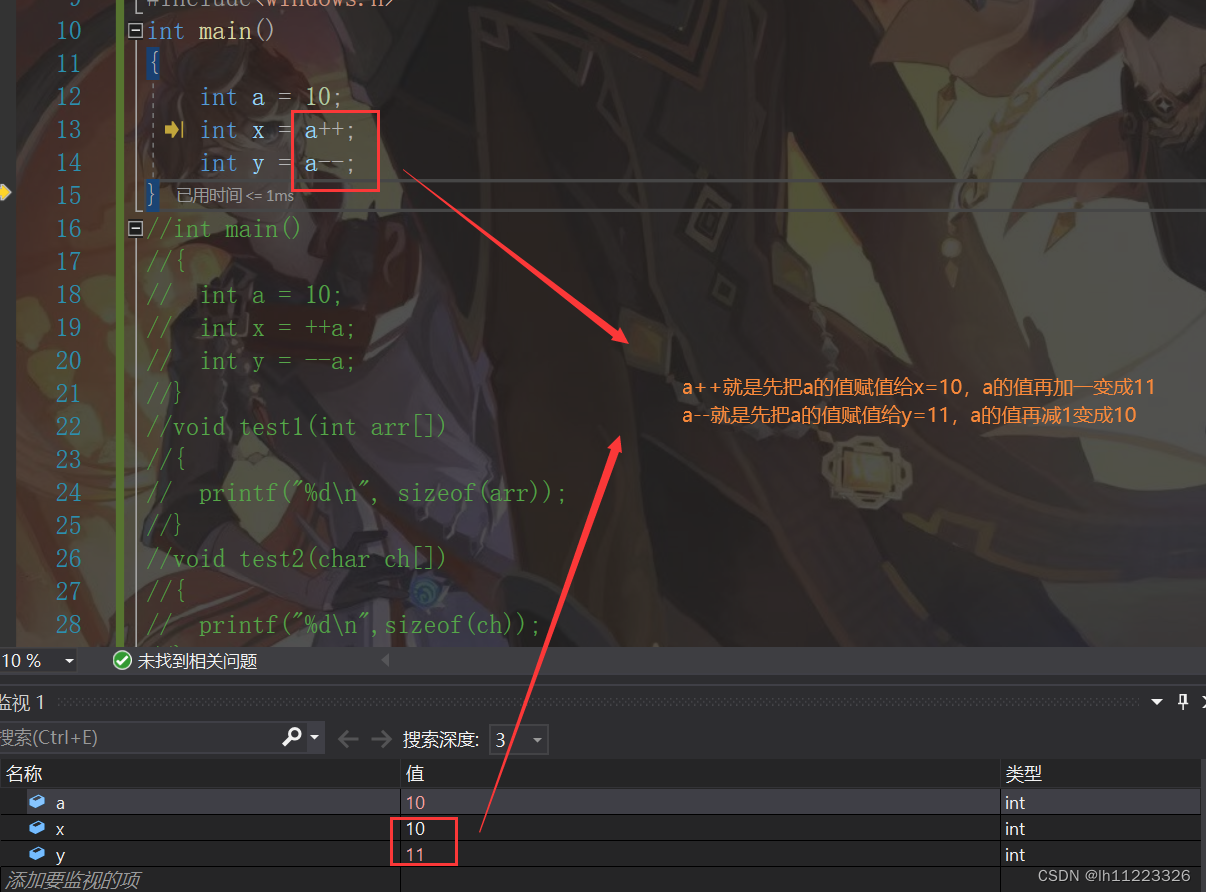
六.关系操作符:
>
>=
<
<=
!= 用于测试“不相等”
== 用于测试“相等”
七.逻辑操作符:
&& 逻辑与:两个为真才为真,否则都为假。
| | 逻辑或:有真就为真,都为假才为假。
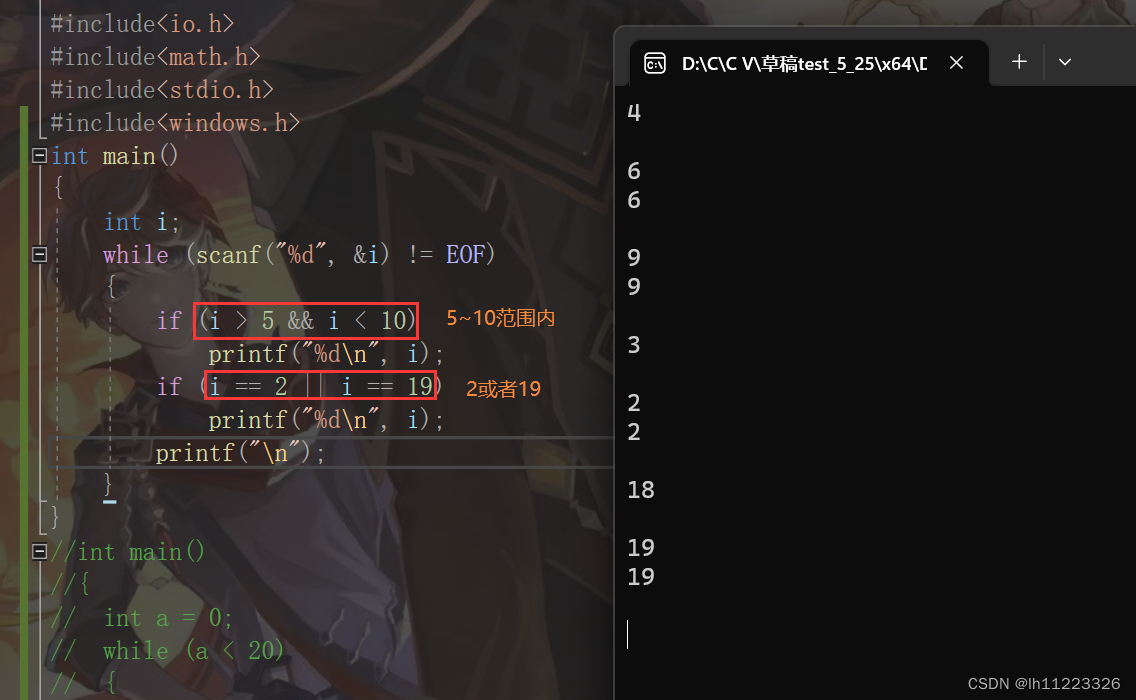
八.条件操作符:
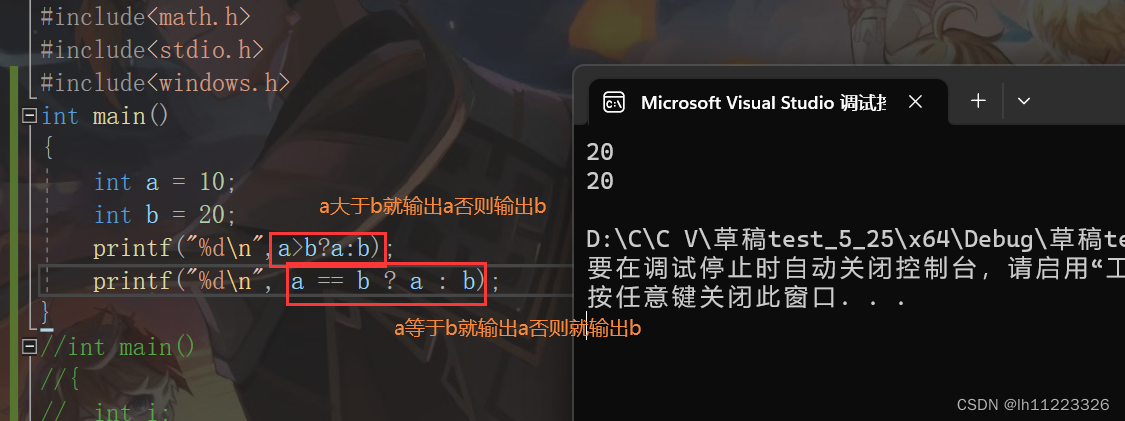
exp1?exp2:exp3 exp1语句成立就为exp2不成立就为exp3
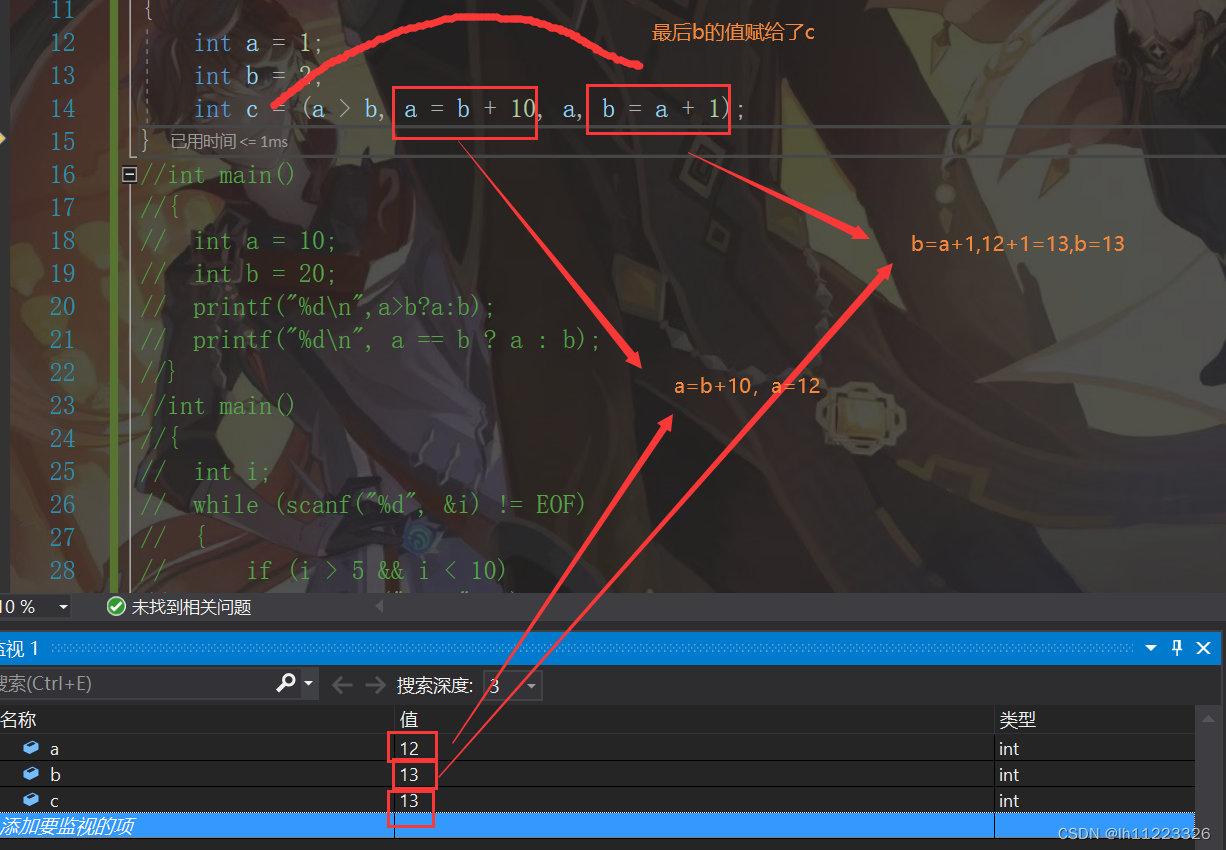
九.逗号表达式:
逗号表达式,就是用逗号隔开的多个表达式。
逗号表达式,从左向右依次执行,整个表达式的结果是最后一个表达式的结果。
exp1,exp2,exp3.......expN
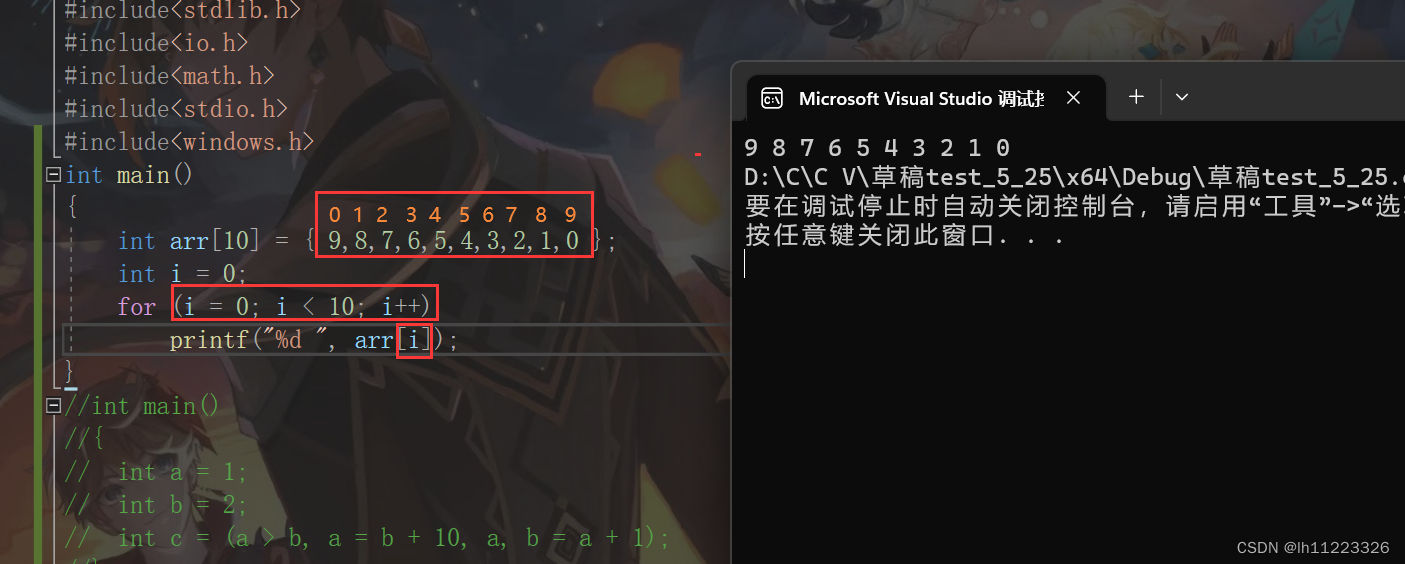
十.下标引用,函数调用和结构成员:
[ ]下标引用操作符
操作数:一个数组名+一个索引值
int arr[10]; //创建数组
arr[9]=10; //实用下标引用操作数。
[ ]的两个操作数是arr和9.
这里使用了i访问了arr的每一个数。
()函数调用操作符
接受一个或多个操作数:第一个操作符是函数名,剩余的操作数就是传给函数的参数。
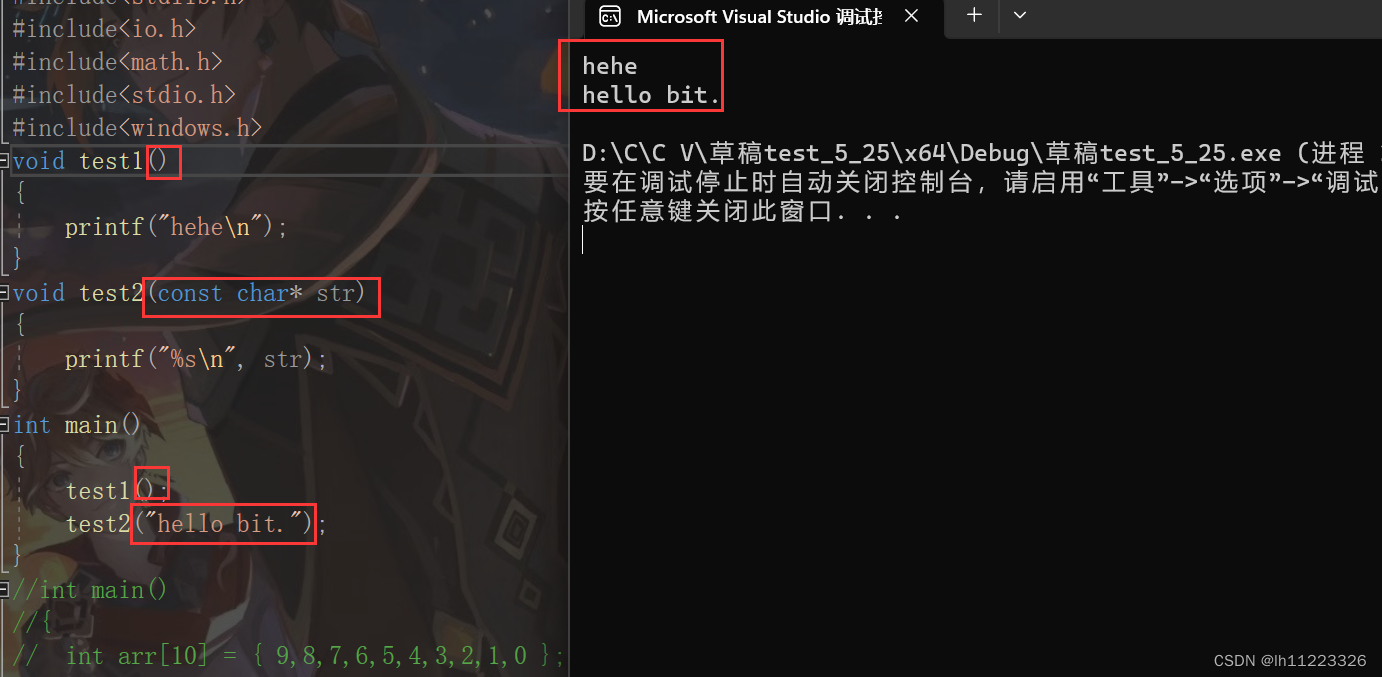
. 结构体.成员名
-> 结构体指针->成员名
struct Stu
{
char name[10];
int age;
char sex[5];
double score;
};
void set_age1(struct Stu stu)
{
stu.age = 18;
}
void set_age2(struct Stu* pStu)
{
pStu->age = 18;//结构成员访问
}
int main()
{
struct Stu stu;
struct Stu* pStu = &stu;//结构成员访问
stu.age = 20;//结构成员访问
set_age1(stu);
pStu->age = 20;//结构成员访问
set_age2(pStu);
return 0;
}十一.表达式求值:
表达式求值的顺序一部分是由操作符的优先级和结合性决定的。
同样,有些表达式的操作数在求值的过程中可能需要转换为其他类型。
隐式转换:
C的整形算术运算总是至少以缺省整形类型的精度来进行的。
为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整形,这种转换称为整形提升。
整形提升的意义:
表达式的整形运算要在CPU的相应运算器内执行,CPU内整形运算器(ALU)的操作数的字节长度一般是int的字节长度,同时也是CPU的通用寄存器的长度。
因此,即使两个char类型的相加,在CPU执行时实际上也要转换为CPU内整形操作数的标准长度。
通用CPU(general-purpose CPU)是难以直接实现两个8比特字节直接相加运算(虽然机器指令中可能有这种字节相加指令)。所以,表达式中各种长度可能小于int长度的整形值,都必须先转换为int或unsigned int,然后才能送入CPU去执行运算。
实例:
char a,b,c;
....
a=b+c;
b和c的值被提升为普通整形,然后再执行加法运算。
加法运算之后,结果被截断,然后再存储于a中。
整形提升是按照变量的数据类型的符号位来提升的:
//负数的整形提升:
char c1=-1;
变量c1的二进制(补码)中只有8个比特位;
1111111
因为char是有符号的char
所以整形提升的时候,高位补充符号位,即为1
提升之后的结果是:
1111111111111111111111111111111
//整数的证书提升:
char c2=1;
变量c2的二进制位(补码)中只有8个比特位:
00000001
因为char是有符号的char
所以整形提升的时候,高位补充符号位,即为0
提升之后的结果是
0000000000000000000000000001
//无符号整形提升,高位补0
下面代码中a,b要进行整形提升,但是c不需要整形提升
a,b整形提升之后变成了负数,所以表达式a==0xb6,b==0xb600的结果是假,但是c不发生整形提升,则表达式c==0xb60000000的结果是真。
所以程序输出的是:c
int main()
{
char a=0xb6;
short b=0xb600;
int c=0xb60000000;
if(a==0xb60)
printf("a");
if(b==0xb600)
printf("b");
if(c==0xb6000000)
printf("c");
}
实例:
c只要参与了表达式运算就会发生整形提升,表达式+c,就会发生提升,所以sizeof(+c)是4个字节。
表达式-c也会发生整形提升,所以sizeof(-c)是4个字节,但是sizeof(c)就是1个字节。
int main()
{
char c=1;
printf("%u\n",sizeof(c));
printf("%u\n",sizeof(+c));
printf("%u\n",sizeof(-c));
}算数转换:
如果某个操作符的各个操作数不属于不同类型,难么除非其中一个操作数转换为另一个操作数的类型,否则操作就无法进行,下面的层次体系称为寻常算术转换。
long double
double
float
unsigned long int
long int
unsigned int
int
如果某个操作数的类型在上面这个列表中排名较低,那么首先要转换为另一个操作数的类型执行运算。
但是算术转换要合理,要不然会有一些潜在的问题。
float f=3.14;
int num=f;//隐式转换,会有精度丢失
操作数的属性:
1.操作符的优先级
2.操作符的结合性
3.是否控制求值顺序。
相邻的操作符先执行的因素是取决于他们的优先级,如果两者的优先级相同,取决于他们的结合性
操作符优先级可以参考这里:C++ 内置运算符、优先级和关联性 | Microsoft Learn
https://learn.microsoft.com/zh-cn/cpp/cpp/cpp-built-in-operators-precedence-and-associativity?view=msvc-170
一些问题表达式
//表达式的求值部分由操作符的优先级决定。
a*b+c*d+e*f
//代码1在计算的时候,由于*比+的优先级高,只能保证,*的计算是比+早,但是优先级并不能决定第三个*比第一个+早执行
所以表达式的计算顺序是:
a*b
c*d
a*b+c*d
e*f
a*b+c*d+e*f
或者:
a*b
c*d
e*f
a*b+c*d
a*b+c*d+e*f
表达式:
c+--c;
//同上,操作符的优先级只能决定自减--的运算在+的运算的前面,但是我们并没有办法得知,+操作符的左操作数的获取在右操作数之前还是之后求值,所以结果是不可预测的,是有歧义的。
非法 表达式,这种表达式在不同的编译器有不同的结果
int main()
{
int i=10;
i=i-- - --i*(i=-3)*i++ + ++i;
printf("i=%d\n",i);
}
代码:这个 代码虽然在大多数的编译器上求得结果都是相同的,但是上述代码answer=fun()-fun()*fun();中我们只能通过操作符的优先级得知:先算乘法,再算减法,函数的调用先后顺序无法通过操作符的优先级确定。
int fun()
{
static int count =1;return ++count;
}
int main()
{
int answer;answer=fun()-fun()*fun();
printf("%d\n",answer);
}
总结:我们写出的表达式如果不能通过操作符的属性确定唯一的计算路径,那这个表达式就是存在问题的。
二.数据类型的存储
一.数据的类型的介绍:
char //字符数据类型 —— 一个字节大小
short //短整型 —— 两个字节大小
int //整形 —— 四个字节大小
long //长整型 —— 四个字节大小
long long //更长的整形 —— 八个字节大小
float //单精度浮点数 —— 四个字节大小
double //双精度浮点数 —— 八个字节大小//C语言有没有字符串类型?
为什么有int整形了还要short和long?:这是因为int在32位机器上表示21亿多而且占4个字节但有时候用不到这么大的数比如年龄所以有short来表式而且只占2个字节有时候int也不够用所以又有了long类型来表示
1.整形家族:有符号和无符号的定义。
ASCLL可以参考:ASCII 表 | 菜鸟教程 (runoob.com)https://www.runoob.com/w3cnote/ascii.html
unsigned 是无符号 unsigned没有符号位只有数值位
signed 是有符号 存储时会把最高位当成符号位其他位是数值位
char :因为字符存储的时候,存储的是ASCII码值,是整形,所以归类的时候放在整形家族里
unsigned char
signed char
char是unsigned char 还是signed因为C语言没有给出标准所以不确定在 VS编译器上是char=signed char 如果要定义无符号的则要unsigned char这样写
short
unsigned short [int]
signed short [int]
short=signed short =-32878~32767
unsigned shor =0~65535
int
unsigned int
signed int
在32位机器下:其他的范围各有不同
int =signed int =-2147483648~2147483647
unsigned int =0~4294967296
long
unsigned long [int]
signed long [int]
long =signed long
unsigned long
2.浮点型:
float
double
3.构造类型:(自定义类型)
>数组类型
>结构体类型 struct
>枚举类型 enum
>联合类型 union
4.指针类型:
int* pi;
char* pc;
float* pf;
void* pv;
5.空类型:
void表示空类型(无类型)
通常应用于函数的返回类型,函数的参数,指针类型
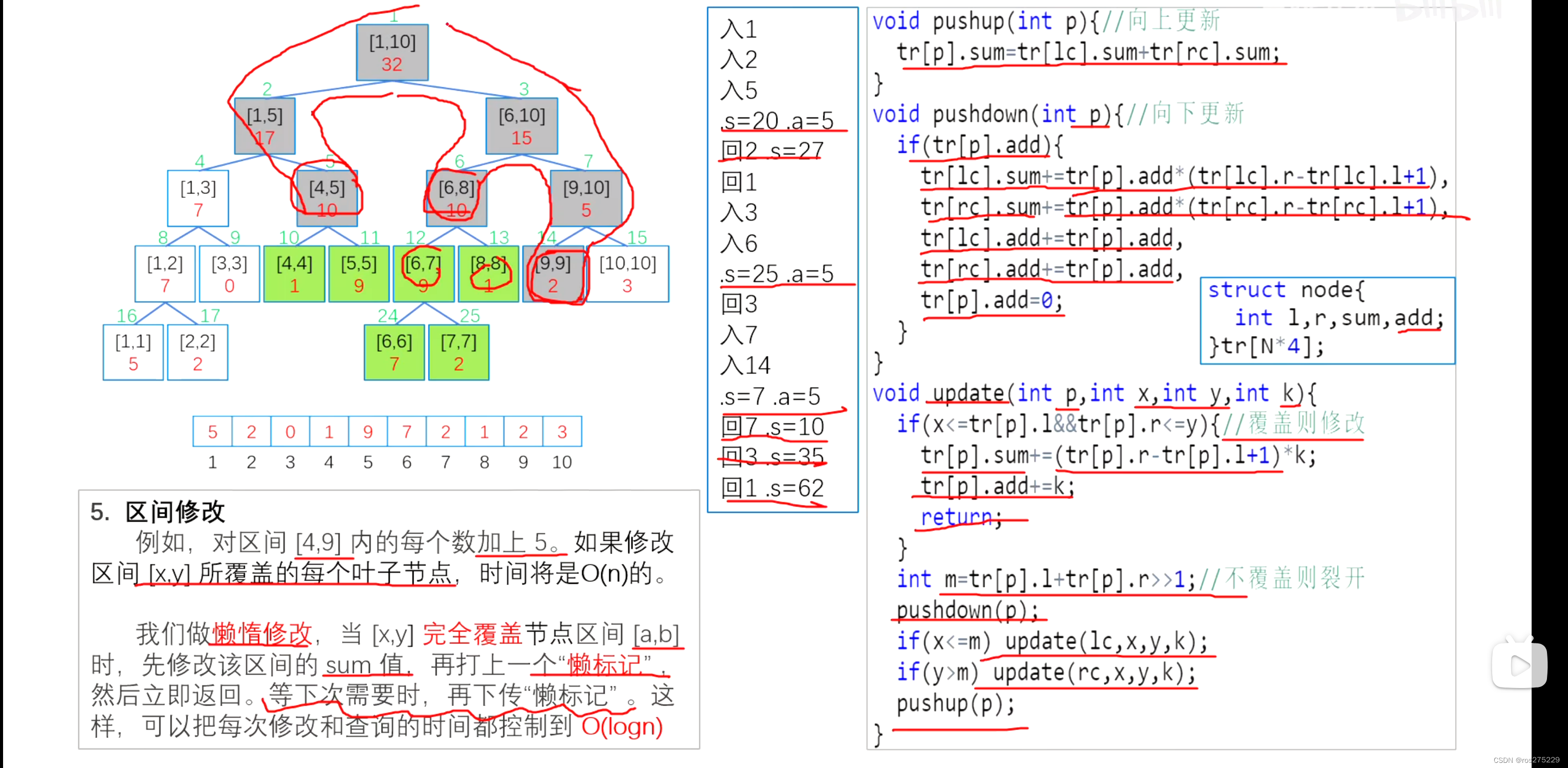
二.整形在内存中的存储:源码,反码,补码
计算机中的整数有三种2进制表示方法,即源码,反码和补码。
三种表示方式均有符号位和数值位两部分,符号位都是用0表示‘正’,用1表示‘负’,而数值位正数的原,反,补码都相同。(二级制最高位是符号位其他位是数值位)
负整数的三种表示方式各不相同。
源码:直接将数值按照正负数的形式翻译成二进制就可以得到源码。
反码:将源符号位不变,其他位依次按位取反就可以得到反码。
补码:反码+1就得到补码
int num=10;//创建一个整形变量叫num,这时num向内存中申请了4个字节空间来存放数据10
//4个字节-32个二进制
//源码:00000000000000000000000000001010
//反码:00000000000000000000000000001010
//补码:00000000000000000000000000001010
int num1=-10;//创建一个整形变量叫num1,这时num1向内存中申请了4个字节空间来存放数据-10
//4个字节-32个二进制
//源码: 10000000000000000000000000001010
//反码:111111111111111111111111111111110101 //源码转反码符号位之外其他位按位取反,反码转源码符号位之外其他位按位取反。反码+1=补码,补码-1=反码。
//补码:111111111111111111111111111111110110
对于整数来说:数据存放内存中其实放的是补码,在计算机系统中,数值一律用补码来表示和存储,原因在于,使用补码,可以将符号位和数值域统一处理,同时加减法也可一统一处理(CPU只有加法器)此外,补码于源码相互转换,其运算过程是相同的,不需要额外的硬件电路。
可以使用&num取出num的地址因为VS为了方便展示所以显示的是16进制,0a 00 00 00这是因为倒着存的num1负书可以验证
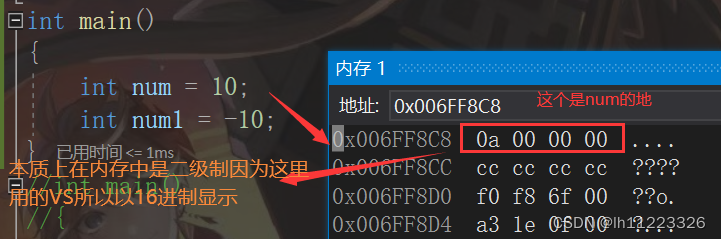
-10的补码是111111111111111111111111111111110110,16进制算出来是ox ff ff ff 6f而存入却是f6 ff ff ff这证实了内存中的数据是倒着存入的(后面大端小端会讲原因)
int main(){
int num1=10;
int num2=-10;
}
源码计算1-1可以表示1+(-1)
1=00000000000000000000000000000001
-1=10000000000000000000000000000001
1+(-1)=10000000000000000000000000000010=-2//结果显然是错误的
补码 计算1-1可以表示1+(-1)
1= 00000000000000000000000000000001
-1=1111111111111111111111111111111111111
1+(-1)=1111111111111111111111111111111111110计
算完之后是补码转为反码是:
1111111111111111111111111111111111111
在转为源码是:
00000000000000000000000000000000=0
所以在内存中存的是补码为了方便运算
练习:
#include<stdio.h>
int main()
{
char a=-1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d\n",a,b,c);
}-1的补码是11111111111111111111111111111111因为a是char类型大小只有8个字节所以只有
11111111存进来了再以%d打印%d比char a大会
发生整形提升之后的补码就是10000000000000000000000011111111
转为源码是100000000000000000000000000000001=-1
signed char b和a的类型都是有符号整形所以b=a=-1
因为unsigned char c是无符号整形所以
发生整形提升之后会变成0000000000000000011111111=255最高位是0变成了正数
经过计算补码和截断之后存储再按照类型整形提升之后得到的值是-1 -1 255
#include<stdio.h>
int main(){
char a=-1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d\n",a,b,c);
}
#include<stdio.h>
int main()
{
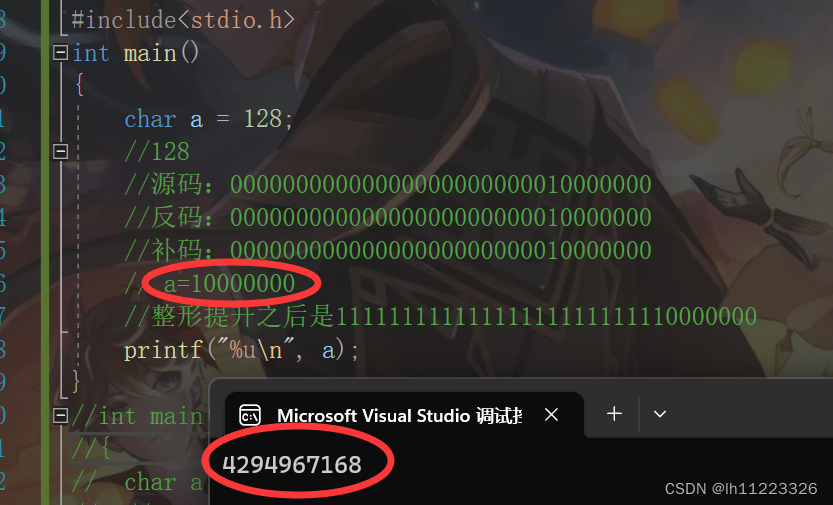
char a = -128;
printf("%u\n", a);
}-128的补码是11111111111111111111111110000000因为a是char类型大小只有8个字节所以只有10000000存进a里
在以%u(以十进制无符号打印)会发生整形提升所以打印的是:无符号数的原反补都是相同的所以直接打印
补码=源码=反码=11111111111111111111111100000000=4294967168

#include<stdio.h>
int main()
{
char a=128;
printf("%u\n",a);
}下面因为存进a里面的值是和上面一样的所以%u整形提升后打印出来的值也是一样的
#include<stdio.h>
int main()
{
int i = -20;
unsigned int j = 10;
printf("%d\n", i + j);
}i的补码是111111111111111111111111111101100
unsigned int j;补码是000000000000000000000000000001010
计算过程是:
i+j=111111111111111111111111111101100 +000000000000000000000000000001010
=补码:11111111111111111111111111110110=反码:111111111111111111111111111110101
=源码:100000000000000000000000000001010=-10

#include<stdio.h>
int main()
{
unsigned int i;
for(i=9;i>=0;i--)
{
printf("%u\n",i);
}
}死循环的原因是i 是无符号整形所以i=0也不成立出现4294967295是因为unsigned int 类型的范围是0~4294967296,所以i是0在继续减不会变成-1因为-1不再unsigned int类型的范围里所以会变成4294967295

int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
a[i] = -1 - i;
printf("%d", strlen(a));
}因为strlen到/0就不会继续了 而在ASCLL码中0就是/0实际255就是char -128道127的所有值

unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++)
printf("hello world\n");
}死循环是因为255超unsiged的0~255的上线了

三.大小端字节序的介绍及判断:
把0x 11 22 33 44存进内存一开始有这几种方法
低地址 高地址
11 | 22 | 33 | 44
44 | 33 | 22 | 11
11 | 22 | 44 | 33
11 | 44 | 33 | 22
存储进来主要是为了之后方便拿出来所以只留下了这两种称为大端字节序和小端字节序(字节序是以字节为单位来存储数据的)
11 | 22 | 33 | 44 大端:把一个数据的低位字节的内容,存放在高址值处,把一个高数据的高位字节内容,存放在低地址处。
44 | 33 | 22 | 11 小端:把一个数据的低位字节的内容,存放在低址值处,把一个高数据的高位字节内容,存放在高地址处。
char ch;类型是一个字节没有顺序
因为在计算机系统中是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语音中除了8 bit 的char之外,还有16 bit的short型,32 bit的long型(要看具体编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题,因此就导致了大端和小端存储模式。
列如:一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11位高字节,0x22为低字节,对于大端模式,就将0x11放在地址值中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反,我们常用的x86结构是小端模式,而KEIL C51则为大端模式,很多的ARM,DSP都为小端模式,有些ARM处理器可以有硬件来选择是大端还是小端模式
44 | 33 | 22 | 11 因为:小端:把一个数据的低位字节的内容,存放在低址值处,把一个高数据的高位字节内容,存放在高地址处。
所以这里是按照小端模式来存储的

还以这样判断大端和小端:&a的第一个地址如果是大端的话就是00小端是01再(char*)强制类型转换因为转化的类型char只有一个字节大小所以只保留了01让后再*解引用得出值和1比较就可以判断大端和小端了

要注意在Release x64下你电脑的杀毒软件会把你的程序认为是病毒换成Debug就行了

四.浮点型在内存中的存储解析:
浮点数的存储规则:num和*pFloat在内存中明明是同一个数,为什么浮点数和整数的读取结果会差别这么大?
根据国际标准IEEE(电子和电子工程协会)754,任意一个二进制浮点数V可以表示成下面形式·(-1)^S*M*2^E
·(-1)^S表示符号位,当S=0,v为正数,当S=1,v为负数
M表示有效数字,大于等于1,小于2
2^E表示指数位数
5.5-十进制浮点数=二进制的浮点数101.1=(-1)^0*1.011*2^2
1 0 1 . 1
= = = =
1*2^2 + 0*2^1 + 1*2^0 + 1*2^-1
十进制9.0=二进制1001.0
=1.001*2^3=(-1)^0*1.001*2^3
S=0 M=1.001,E=3
IEEE 754规定:
对于32位的浮点数,最高的1位是符号位S,接着的8为指数E,剩下的23位为有效数字M

对于64位浮点数,最高的1位是符号位S,接着的 11位是指数E,剩下的52位为有效数字M

IEEE 754对有效数字M和指数E,还有一些特别的规定
前面说过,1<=M<2,也就是说,M可以写成1.XXXX的形式,其中XXXX是小数部分
IEEE 754 规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的XXXX部分,比如保存1.01的时候,只保存01,等到读取的时候,在把第一位的1加上去,这样做目的是,节省1位有效数字,以32位浮点数为例,留给M只有23位1,将第一位的1舍去以后,等于可以保存24位有效数字
至于指数E,情况就比较复杂
首先,E为一个无符号整数(unsined int )
这意味着如果E为8位,它的取值范围为0~255;如果E为11为,它的取值范围为0~2047,但是我们知道,科学计算法中的E是可以取出
现负数的,所以IEEE754规定,存入内存时E的真实值必须加上一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023,比如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001,
然后指数E从内存中取出还可以再分成三种情况:
E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,在将有效数字M前面加上第一位的1.
比如:
0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为1.0*2^(-1),七阶码值为-1+127=126表示为
011111110,而尾数1.0去掉整数部分为0,补齐0到23位000000000000000000000000,则其二进制表示形式为:0 011111110 000000000000000000000000
E为全0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,
有效数字M不再加上第一位的1,而是还原为0.xxxxxxx的小数,这样是为了表示-+0,以及接近于0的很小的数字。
E为全1
这时,如果有效数字M全为0,表示+-无穷大(正负取决于符号位S);
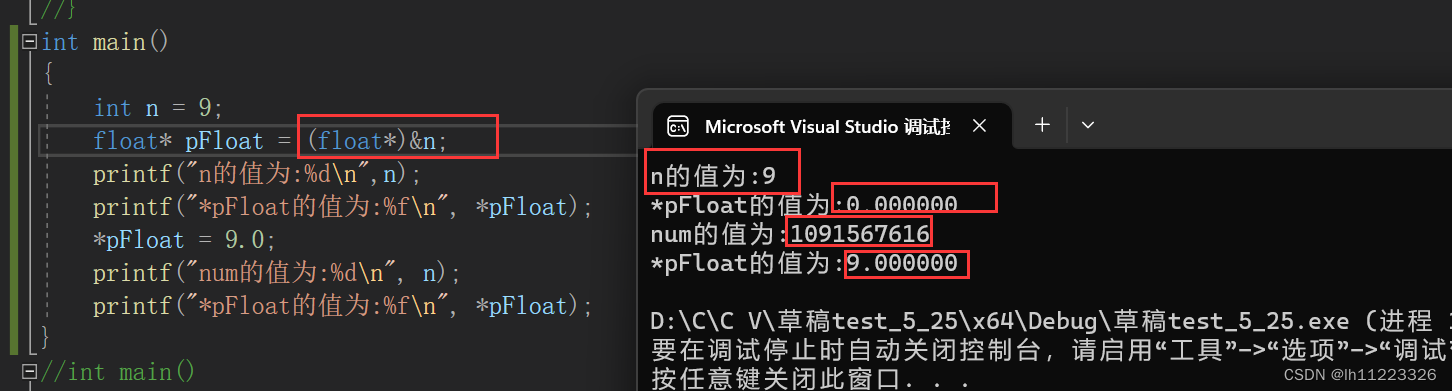
放一个整数9在整形n里,再类型转换为float*类型取地址放进float*pFloat里是
以0 000000000 00000000000000000000101
S E M
的形式存进来的
E在内存中为全0这时E等于1-127即为真实值有效数M不再加上第一位的1而是还原为0.XXXXX成了一个很小的小数
%f打印范围没有这么小就没打印出来
9.0存进*pFloat是以0 100000001 000100000000000000的形式
以%d打印0 100000001 00010000000000000000的值也就是09567616
把9.0小数存进*pFloat里后面*pFloat打印出来自然也是9.0
#include<stdio.h>
int main(){
int n=9;
float*pFloat=(float*)&n;
printf("n的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
*pFloat=9.0;
printf("num的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
}