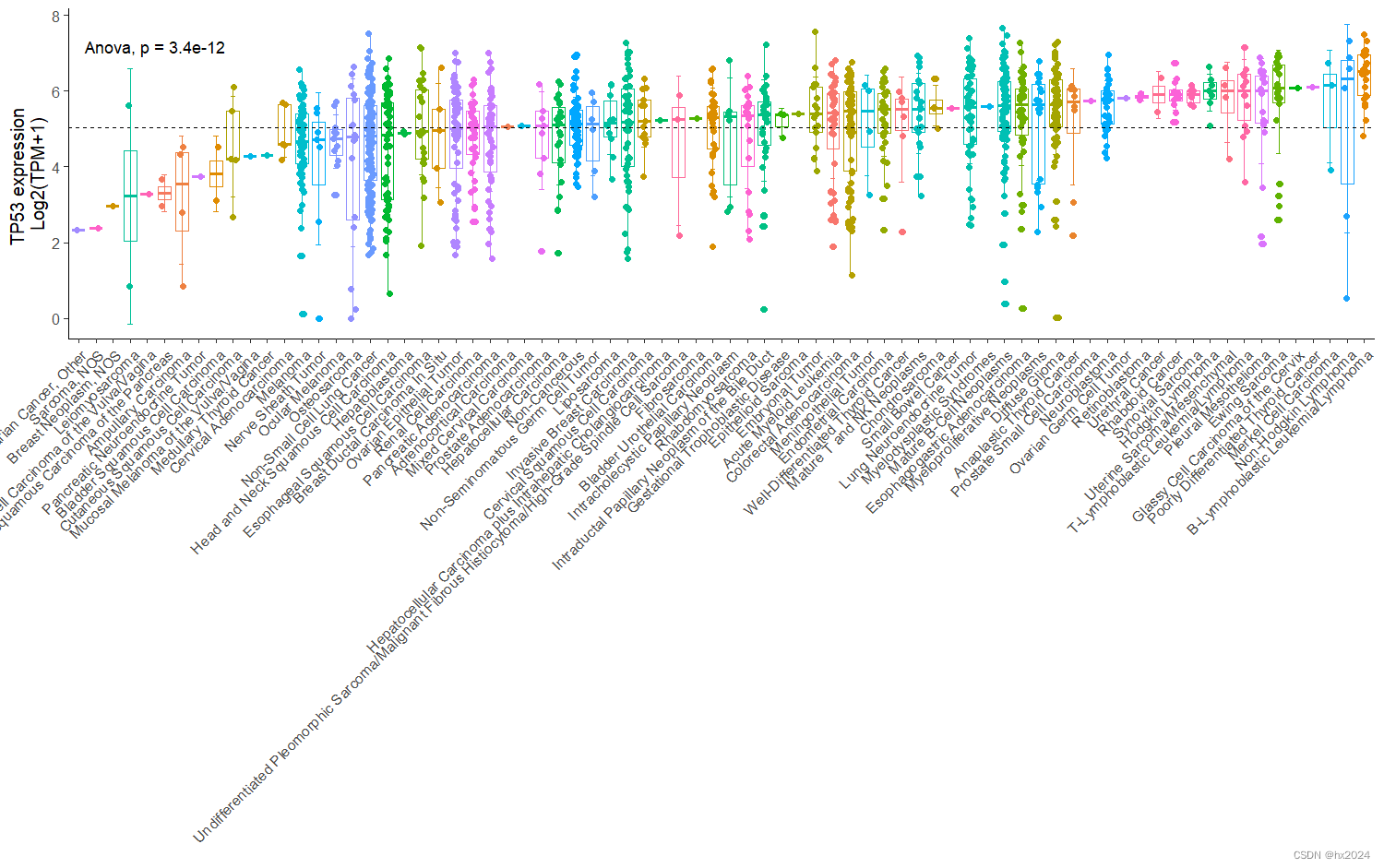
文章目录
- 什么是哈希
- 哈希函数
- 直接定址法
- 除留余数法
- 哈希冲突
- 闭散列
- 线性探测法
- 二次探测法
- 负载因子和闭散列的扩容
- 开散列
- 开散列的扩容
- 非整形关键码
什么是哈希
我们来重新认识一下数据查找的过程:
在顺序结构以及平衡树中,记录的关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( l o g 2 N log_2 N log2N),搜索的效率取决于搜索过程中元素的比较次数。
顺序结构: 指的是顺序表、链表等线性数据结构,具体在C++中表现为像vector、list这样的容器;
平衡树: 指的是AVL树、红黑树等树形数据结构,具体在C++中表现为map、set这样的容器;
记录: 指的是容器或数据结构中存储的元素(或者说数据),为了方便后面表述什么哈希的相关知识,特地用这个名词来指代;
关键码: 它是一个记录的唯一标识,可能是记录本身或者记录中的某一项。举个例子,假如说记录是一个整数 or 字符串,记录的关键码就是记录本身,假设记录是一个键值对,记录的关键码就是键值对中的key;假设记录是某个类对象,记录的关键码就是对象中的某几个成员变量;
存储位置: 顾名思义,就是一个记录在 容器 or 数据结构 之中的存储位置。
这里有一组水果相关的英文单词,它们存储在不同容器之中,可以看到记录的关键码与其存储位置之间没有对应的关系。
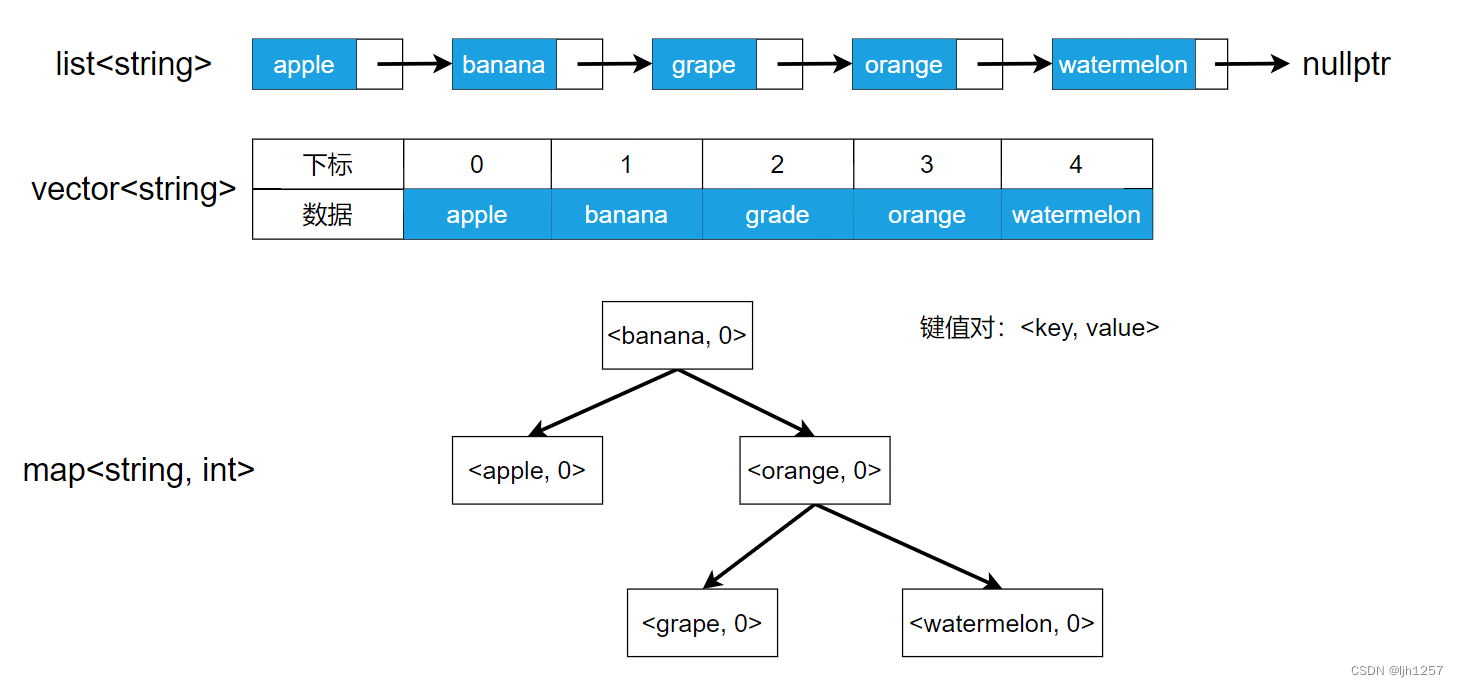
正因为没有关系,假设我现在查找的目标记录是"watermelon",就只能从起点开始,挨个地比较每个记录的关键码和目标记录的关键码的值是 “ = ” 还是 “ ≠ ”,直到出现相等或者找完才算是有结果,所以才说,元素的查找效率取决于关键码的比较次数。
那么有没有一种理想化的状态:查找的过程中,可以不通过任何的比较,而是让记录的关键码和记录的存储位置通过某种手段建立起一种一对一的映射关系,通过关键码直接就可以找到目标记录。
而达成这种理想化的查找状态的方法就是 “ 哈希 ”(或者说 “ 散列 ”),通过这个方法实现的存储结构,我们称之为 “ 哈希表 ”(或者说 “ 散列表 ”),记录的关键码和记录的存储位置建立映射关系的手段我们称之为 “ 哈希函数 ”(或者说 “ 散列函数 ”),哈希函数的作用是将记录的关键码转换成记录在哈希表的地址,对于这个地址我们一般称之为 “ 哈希值 ”(或者 “ 哈希地址 ”)。
" 哈希 "一词源自于英文单词 " hash ",而 " 散列 " 则是 " hash " 的中文翻译。最初,这两个术语可能在不同的语境中出现,但随着时间的推移,它们逐渐成为了同义词,并在计算机科学领域中得到广泛使用。哈希是直接音译,散列则是意译。
哈希表的插入操作大致为,“ 使用哈希函数计算出待插入记录的关键码的哈希值,即记录插入在哈希表的位置 ,然后插入 ” ;查找操作大致为,“ 使用哈希函数计算出待插入记录的关键码的哈希值,在哈希表中按此位置取元素比较,若关键码相等,则查找成功 ” 。
哈希函数
从上面来看,哈希函数可以说是哈希这个思想的关键,所以我们就来看看常用的哈希函数都有哪些。
直接定址法
直接定址法的做法是直接取记录的关键码的某个线性函数值来作为哈希地址。
哈希函数的公式:
Hash(Key)
=
A
×
Key
+
B
\text{Hash(Key)} = A \times \text{Key} + B
Hash(Key)=A×Key+B
我们来看下面这两个例子(例子来自《大话数据结构》,因为比较好懂,我就直接拿来借用一下)。

这个的哈希函数的优点就是简单,但它只适合记录关键码分布范围较小且数据重复度高度的场景,在某些极端场景下可能会造成极大的空间浪费。

因此,直接定址法虽然因为简单而常见但是却不使用,真正实用的哈希函数还得是接下来讲的除留余数法。
除留余数法
假设散列表的长度为
c
a
p
a
i
c
t
y
capaicty
capaicty,
p
p
p 是一个不大于
c
a
p
a
i
c
t
y
capaicty
capaicty,但最接近或者等于
c
a
p
a
i
c
t
y
capaicty
capaicty 的质数,除留余数法的公式如下:
Hash(Key)
=
Key
%
p
,
(
p
≤
capacity
)
\text{Hash(Key)} = \text{Key} \% p, \quad (p \leq \text{capacity})
Hash(Key)=Key%p,(p≤capacity)
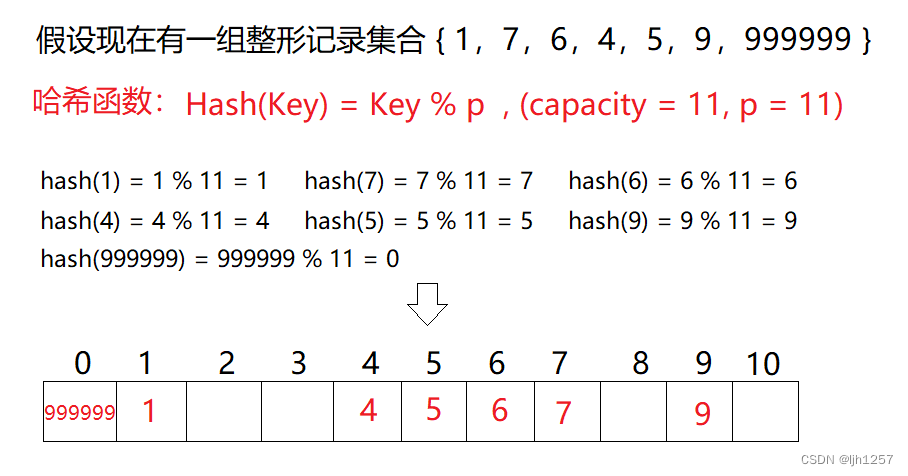
从这个例子中我们能看到,哪怕最大值和最小值之间相差了999998,进行取模运算之后,我们也可以在表中找到一个位置存储记录。
然而,除留余数法还有一个致命的问题,假设我们再往表里插入记录 48 48 48 时,此时就会出现 H a s h ( 4 ) Hash(4) Hash(4) 和 H a s h ( 48 ) Hash(48) Hash(48) 的哈希值都是 4 4 4 的现象,像这样的,当不同关键码通过相同哈希哈函数数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。
而关键码不同、哈希地址相同的记录,我们称为 “ 同义词 ” 。
发生哈希冲突该如何处理呢?
哈希冲突
解决哈希冲突两种常见的方法是:闭散列和开散列。
闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。,那如何寻找下一个空位置呢?
线性探测法
线性探测的做法是,从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
哈希函数的公式为:
Hash(Key)
=
(
Hash(key)
+
d
i
)
%
p
,
(
d
i
=
1
,
2
,
3
,
…
,
p
−
1
)
\text{Hash(Key)} = (\text{Hash(key)} + d_i) \% p, \quad (d_i = 1, 2, 3, \dots, p-1)
Hash(Key)=(Hash(key)+di)%p,(di=1,2,3,…,p−1)
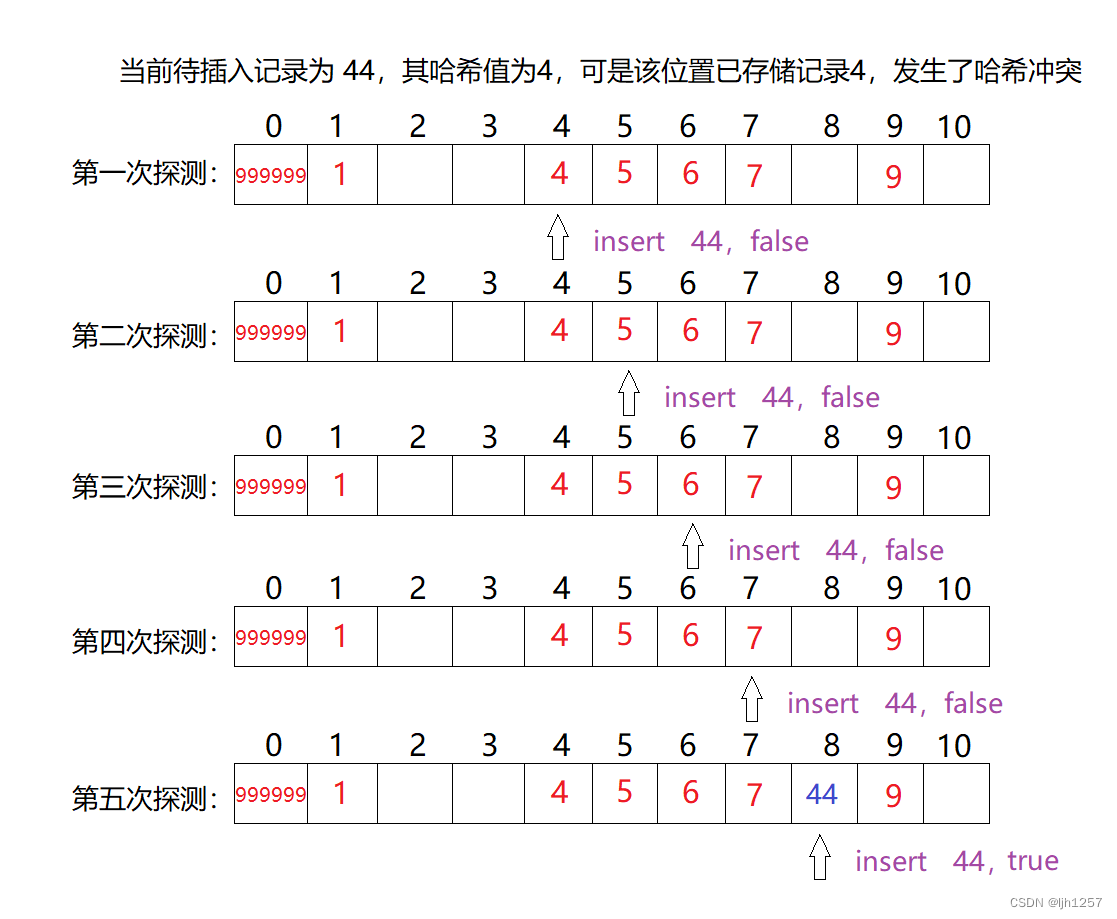
假设哈希地址为 8 8 8 和 10 10 10 的位置已经存储有记录,这时候要 “ 回头 ” 找空位置。
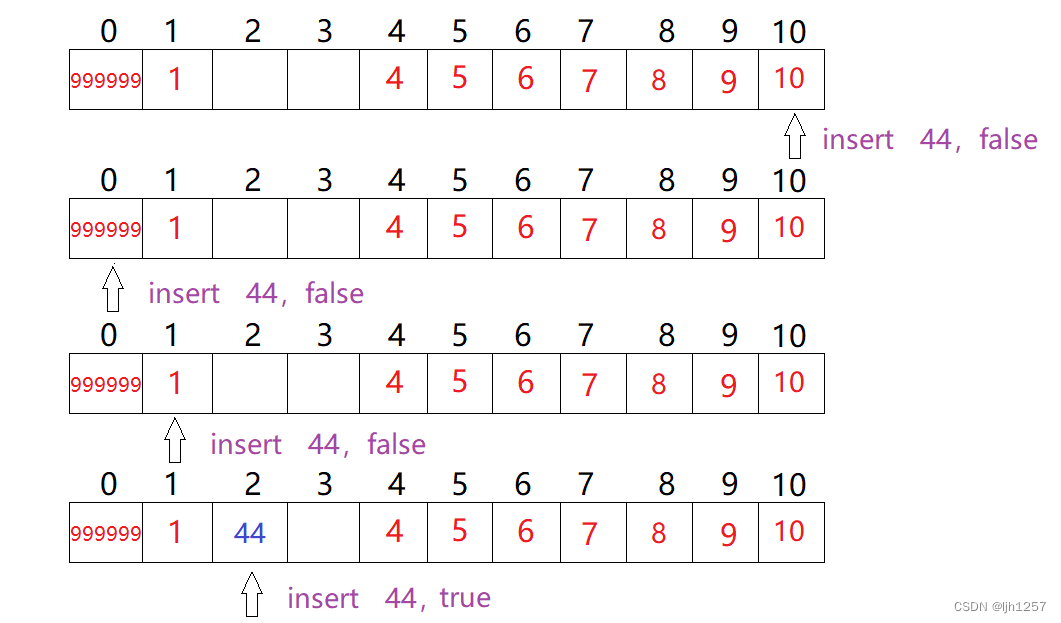
从上面的插入例子,我们能看到:
-
线性探测优点:实现非常简单。
-
线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低(就像哈希值为 8 8 8 和 10 10 10 的位置存在记录时插入记录 44 44 44 一样)。
二次探测法
为了避免线性探测法产生 “ 堆积 ” 现象,还有一种找空位置的方法叫做二次探测法,与线性探测法不同的是,二次探测法使用的增量序列是 d i = 1 2 , − 1 2 , 2 2 , − 2 2 , … , q 2 , − q 2 , ( q ≤ p 2 ) d_i = 1^2, -1^2, 2^2, -2^2, \dots, q^2, -q^2, (q \leq \frac{p}{2}) di=12,−12,22,−22,…,q2,−q2,(q≤2p),这样的增量序列会让记录更加均匀的分布,从而达到降低哈希碰撞的概率。
二次探测法的哈希函数公式:
Hash(Key)
=
(
Hash(key)
+
d
i
)
%
p
,
(
d
i
=
1
2
,
−
1
2
,
2
2
,
−
2
2
,
…
,
q
2
,
−
q
2
,
q
≤
p
2
)
\text{Hash(Key)} = (\text{Hash(key)} + d_i) \% p, \quad (d_i = 1^2, -1^2, 2^2, -2^2, \dots, q^2, -q^2, q \leq \frac{p}{2})
Hash(Key)=(Hash(key)+di)%p,(di=12,−12,22,−22,…,q2,−q2,q≤2p)
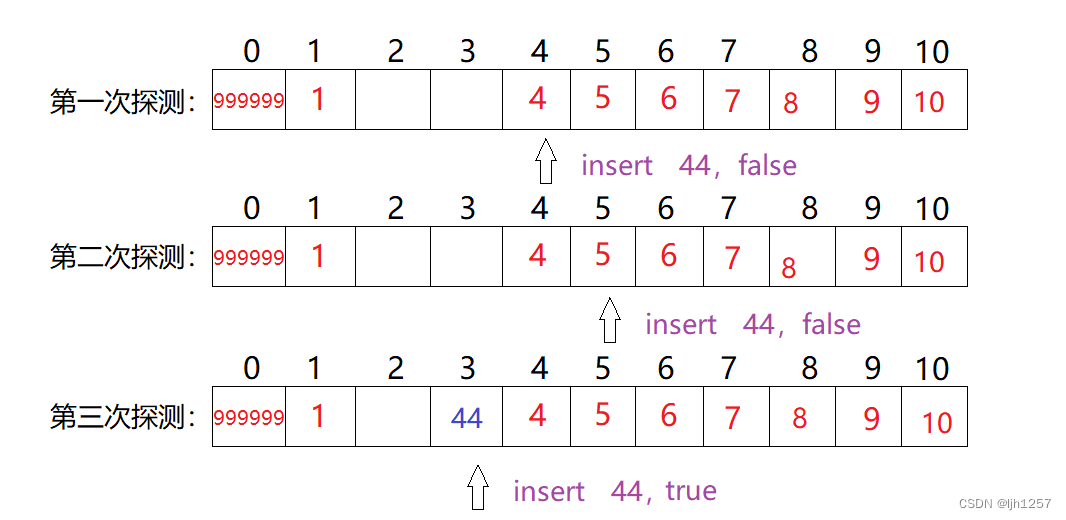
从上面的例子看到,用二次探测法来处理线性探测法的残局还是很有效的。
负载因子和闭散列的扩容
哈希表中还有一个叫做 “ 负载因子 ” 的概念,它的定义为:
负载因子
=
当前哈希表记录个数
哈希表的长度
\text{负载因子} = \frac{\text{当前哈希表记录个数}}{\text{哈希表的长度}}
负载因子=哈希表的长度当前哈希表记录个数
由于表的长度是一个定值,负载因子与 “ 填入表中的记录个数 ” 成正比,所以,当负载因子越大,表明填入表中的记录就越多,产生哈希冲突的可能性就越大,而哈希表的查找效率与哈希冲突的息息相关,在闭散列不可避免会产生哈希冲突的情况下,我们应当尽量降低哈希冲突的可能性。
存在研究表明:
当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次,如果插入过程中超过0.5就考虑对哈希表进行扩容,这种方法虽然查找效率极高,但是空间浪费也很严重。
而当负载因子超过0.8时,哈希表的空间利用率虽然提高了,但是查表时的CPU缓存不命中率次数会按照按照指数曲线上升,查找效率反而急速下降。
一般来说,负载因子控制在0.5到0.7之间空间利用率和操作效率之间取得较好的平衡。
哈希表的扩容一般是1.5倍扩容或者是2倍扩容,对哈希表进行扩容操作之后有一个点要处理,除留余数法的的操作让关键码除以表长后的余数作为哈希值,因此需要重新计算所有记录的哈希值,并将它们重新分配到新的哈希表中。
这个过程涉及以下几个步骤:
- 创建一个新的、更大容量的哈希表。
- 将旧哈希表中的所有键值对重新计算哈希值,并根据新的表长,将它们插入到新的哈希表中的相应位置。
- 销毁旧的哈希表,释放内存空间。
开散列
闭散列处理哈希冲突的思路是,这个位置有 “ 人 ” 了,我就找一个新的位置,但其实思路还可以再换一换,为了有冲突就一定得换地方呢?我们直接就在原地想办法不可以吗?
于是就有了这里的开散列法。
开散列法,又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同哈希地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
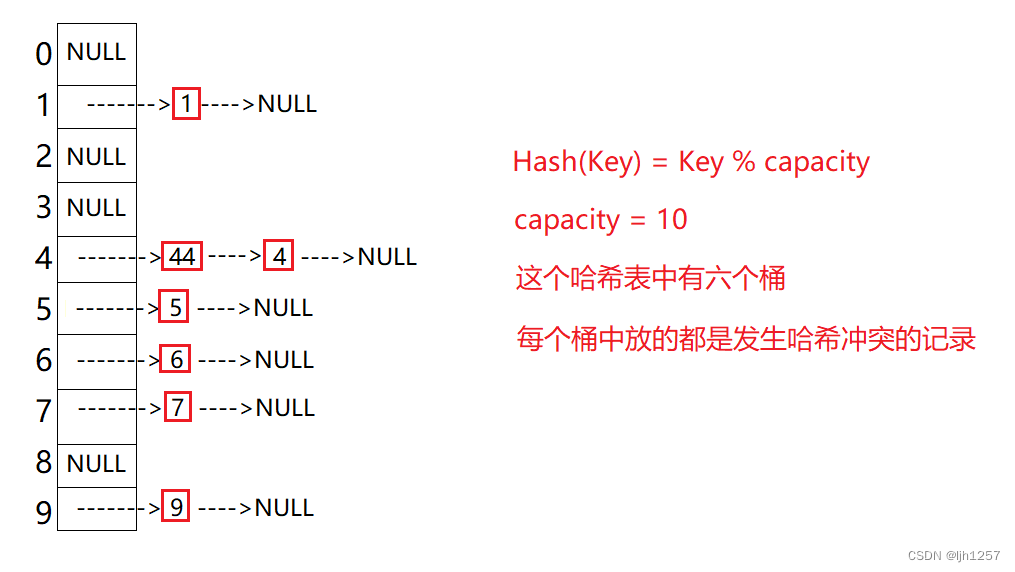
像上图那样,已经不存在什么冲突换地址的问题了,无论来多少个冲突的记录,都只是在当前位置给单链表增加结点的问题。
开散列对于可能会造成很多冲突的哈希函数来说,提供了绝对不会出现找不到地址的保障,但是这也并不是没有代价的,单链表来存储冲突记录就以为着需要遍历单链表的性能损耗。
开散列的扩容
桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希表进行增容,,那该条件怎么确认呢?
对于开散列来说最好的情况是:每个哈希桶中刚好挂一个节点,再继续插入元素时,每一次都会发生哈希冲突,因此,在记录个数刚好等于桶的个数时,即负载因子为 1 1 1 时,可以给哈希表增容。
扩容的过程为如下几个步骤:
- 创建一个新的、更大容量的哈希表。
- 遍历旧哈希表中的每个哈希桶,将其中的记录的关键码对重新计算哈希值,并将其挪到新的哈希表中的对应位置。
- 释放旧哈希表的内存空间。
非整形关键码
除留余数法中,% 运算符已经规定了左右操作数是整形,右边的运算符是表长,它本身就是一个整数,不用过多考虑,关键是记录的关键码,假如说记录的关键码是一个字符串而不是一个整数时,我们又该怎么处理呢?
其实就是一句话,关键码不是整形,那就转换成整型!
方法一:直接转换
通过观察我们发现,所谓字符串其实就是多个字符的组合,而字符的本质其实是ASCII码,也是一个整型值,最简单的处理我们可以考虑将一个字符串中所有字符的ASCII码加起来作为记录的关键码,比如说字符串 "hello",ASCII 码表中 'h' 的值是 104,'e' 的值是 101,'l' 的值是 108,'o' 的值是 111,那么,
关键码
=
104
+
101
+
108
+
108
+
111
=
532
关键码 = 104 + 101 + 108 + 108 + 111 = 532
关键码=104+101+108+108+111=532
但是,这个方法也有很大的缺陷,容易引发哈希冲突,假设字符串是 "olleh",它转换处理出来的关键码同样也是 532,这必然会导致哈希冲突。
方法二:加权转换
为了减少哈希冲突,可以为每个字符指定一个权值,然后将每个字符的ASCII码值乘以对应的权值再相加,得到一个关键码。这种方法可以根据实际情况调整权重,以尽可能地减少哈希冲突。
同样以字符串 "hello" 为例,给定一个权值数组,例如 [1, 3, 5, 7, 11],
hello 的关键码
=
104
×
1
+
101
×
3
+
108
×
5
+
108
×
7
+
111
×
11
=
2924
\text{hello 的关键码} = 104 \times 1 + 101 \times 3 + 108 \times 5 + 108 \times 7 + 111 \times 11 = 2924
hello 的关键码=104×1+101×3+108×5+108×7+111×11=2924
假设 "olleh" 的权值数组也是 [1, 3, 5, 7, 11],但是转换后的关键码,却不是一样的,
olleh 的关键码
=
111
×
1
+
108
×
3
+
108
×
5
+
105
×
7
+
104
×
11
=
2854
\text{olleh 的关键码} = 111 \times 1 + 108 \times 3 + 108 \times 5 + 105 \times 7 + 104 \times 11 = 2854
olleh 的关键码=111×1+108×3+108×5+105×7+104×11=2854
有兴趣的话,这里推荐一篇文章《各种字符串Hash函数》,里面的内容是关于如何调整权值来最大化的减少哈希冲突发生的可能性,以及各种字符串哈希函数之间的性能对比。
方法三:自定义转换
根据应用场景的特点,设计自定义的转换方法。例如,对于日期类型的关键码,可以将日期转换成天数或秒数作为整数哈希码;对于自定义类对象,可以根据对象的属性值计算出一个整数哈希码,这个就不好距离了,得根据实际需求来定。