咦咦咦,各位小可爱,我是你们的好伙伴——bug菌,今天又来给大家普及Java之IO流啦,别躲起来啊,听我讲干货还不快点赞,赞多了我就有动力讲得更嗨啦!所以呀,养成先点赞后阅读的好习惯,别被干货淹没了哦~
前言
在进行Java编程时,避免不了要进行一些文件操作。虽然Java提供了很多类和方法来进行文件操作,但是由于I/O操作是比较费时的,所以我们需要考虑如何优化文件操作的效率。本文介绍了如何使用Java中的BufferedInputStream类来提高I/O操作的效率。
摘要
本文主要介绍了如何使用Java中的BufferedInputStream类来优化I/O操作。首先介绍了BufferedInputStream类的作用和原理,然后分别从文件读取和文件写入两个角度,介绍了如何使用BufferedInputStream类来提高文件操作的效率。最后通过测试用例来验证了BufferedInputStream类的优化效果。
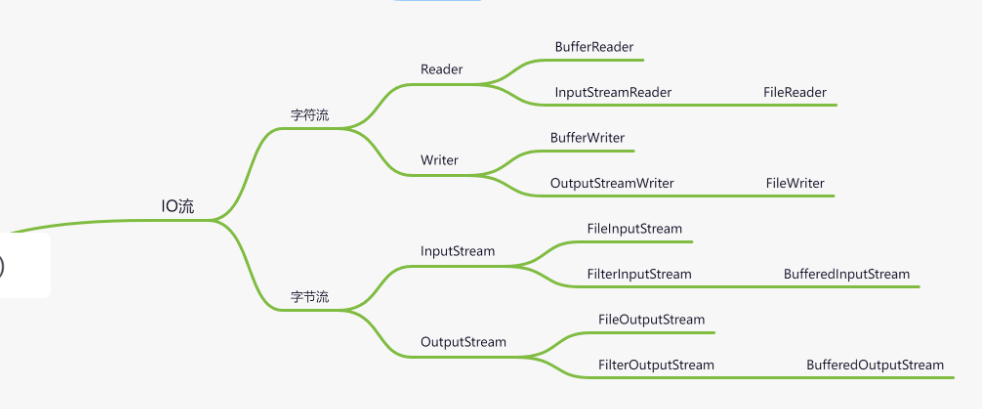
BufferedInputStream
简介
BufferedInputStream是Java中的一个输入流,它实现了输入流的缓冲功能,使读取数据更加高效。当从一个InputStream中读取数据时,Java在内部会一次读取一个字节。这种方式读取数据的效率非常低,因为每次读取都需要和硬盘或网络进行IO操作,而这些操作非常耗时。因此,使用BufferedInputStream可以先将读取的数据缓存到内存中,在内存中慢慢读取,这样就可以减少IO操作的次数,提高读取数据的效率。在使用BufferedInputStream时,可以通过调用read()方法来读取数据,该方法会从缓冲区中读取数据,如果缓冲区中没有数据,则会调用底层流来读取数据。
作用和原理
BufferedInputStream类是Java中的一个输入流缓冲器,它可以提高I/O操作的效率。BufferedInputStream类的原理是,当我们从文件中读取数据时,它会先将数据读入内存缓冲区中,然后再从缓冲区中逐个地读取数据。这样可以减少一些不必要的I/O操作,从而提高读取数据的效率。
优缺点
BufferedInputStream是Java中的一个输入流包装类,它提供了输入流缓冲区的功能,可以提高读取数据的效率。
优点:
- 提供了输入流的缓冲功能,减少了底层输入流的读取次数。这种减少I/O操作的方式可以显著提高读取数据的性能,特别是在处理大量数据时。
- 具有预读的功能,可以一次性读取多个字节到缓冲区中,从而减少了对底层输入流的访问次数。
- 可以通过设置合适的缓冲区大小来优化读取性能,尤其是在连续读取大型数据块时。
缺点:
- 需要额外的内存空间来存储缓冲区,可能会占用较大的内存。
- 当读取数据量较小时,缓冲区的额外开销可能会引起性能下降。
应用场景
- 读取大文件或数据流时,使用
BufferedInputStream可以提高读取性能。 - 在网络传输中,可以使用BufferedInputStream来缓冲输入流,减少网络I/O的次数,提高网络传输性能。
- 当需要连续读取大量数据块时,可以使用
BufferedInputStream来将其存储在缓冲区中,减少对底层输入流的访问次数。
源码分析
在BufferedInputStream的源码中,它维护了一个内部的字节数组缓冲区,默认缓冲区大小为8192字节(8KB)。当从BufferedInputStream中读取数据时,它会先检查缓冲区中是否还有可读取的数据,如果有,则直接从缓冲区中返回数据;如果没有,则从底层输入流中读取数据,并同时将读取的数据存入缓冲区中。在写入数据时也是类似的过程,先写入缓冲区,当缓冲区满或者需要刷新缓冲时,再将数据写入底层输出流。
BufferedInputStream的源码比较复杂,涉及缓冲区的管理、数据读写等操作,通过内部的缓冲区来实现数据的快速读取和写入。在具体使用时,我们只需要关注使用API即可,无需深入理解其具体实现细节。
由于BufferedInputStream主要的作用是在数据源和程序之间添加一个缓冲区,来提高IO操作的效率。读取数据时,BufferedInputStream先从缓冲区中读取,如果缓冲区中没有数据,则从数据源中读取一定量的数据放入缓冲区中,然后再从缓冲区中读取数据,这样就可以避免频繁地访问物理设备,提高了效率。
下面是BufferedInputStream的源码分析:
public class BufferedInputStream extends FilterInputStream {
protected volatile byte buf[];
//缓冲区大小
protected int count;
protected int pos;
protected int markpos = -1;
protected int marklimit;
protected boolean mSkipLF = false;
//默认缓冲区大小
static int defaultBufferSize = 8192;
//跳过缓冲区数据并重新读取数据
private void fill() throws IOException {
//pos记录缓存区的位置
pos = 0;
count = 0;
int n = in.read(buf, pos, buf.length);
if (n > 0) {//如果成功从输入流中读取数据
count = n;
}
}
//构造方法传入InputStream流对象
public BufferedInputStream(InputStream in) {
this(in, defaultBufferSize);
}
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
//读取单个字节
public synchronized int read() throws IOException {
//如果当前数据已经读取完了,从输入流读取数据并缓存
if (pos >= count) fill();
//如果读完了还为空则返回-1
return (pos < count) ? (buf[pos++] & 0xff) : -1;
}
//读取多个字节
private int read1(byte[] b, int off, int len) throws IOException {
int avail = count - pos;
//如果缓存区正在被使用,则重新从流中读取数据到缓冲区中
if (avail <= 0) {
if (len >= buf.length && markpos < 0) {
return in.read(b, off, len);
}
fill();
avail = count - pos;
if (avail <= 0) return -1;
}
int cnt = (avail < len) ? avail : len;
System.arraycopy(buf, pos, b, off, cnt);
pos += cnt;
return cnt;
}
//读取多个字节,并返回读取的字节数
public synchronized int read(byte b[], int off, int len)
throws IOException {
//校验参数范围
if (b == null) {
throw new NullPointerException();
} else if (off < 0 || len < 0 || len > b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int n = 0;
//连续读取
for (;;) {
int nread = read1(b, off + n, len - n);
if (nread <= 0) return (n == 0) ? nread : n;
n += nread;
//读够了就退出循环
if (n >= len) return n;
}
}
//跳过指定字节数
public synchronized long skip(long n) throws IOException {
if (n <= 0) {
return 0;
}
//现将缓存区的数据跳过
long avail = count - pos;
if (avail <= 0) {
//如果缓存区没有数据,则直接跳过n个字节
return in.skip(n);
}
long skipped = (avail < n) ? avail : n;
pos += skipped;
n -= skipped;
//如果还需要跳过的字节数超过了缓存区大小,则直接调用输入流的skip方法跳过
if (n > 0) {
skipped += in.skip(n);
}
return skipped;
}
//返回当前可读取的字节数
public synchronized int available() throws IOException {
int n = count - pos;
int avail = in.available();
return (n > (Integer.MAX_VALUE - avail)) ? Integer.MAX_VALUE : n + avail;
}
//标记当前位置
public synchronized void mark(int readlimit) {
marklimit = readlimit;
markpos = pos;
}
//重置到上一次标记的位置
public synchronized void reset() throws IOException {
if (markpos < 0) {
throw new IOException("Resetting to invalid mark");
}
pos = markpos;
}
//判断是否支持mark和reset方法
public boolean markSupported() {
return true;
}
//关闭流
public void close() throws IOException {
byte[] buffer;
synchronized (this) {
buffer = buf;
buf = null;
}
if (buffer != null) {
//调用输入流的close方法关闭流
in.close();
}
}
}
从源码中可以看出,BufferedInputStream主要是通过缓冲区来提高了读取效率,其读取过程与InputStream的读取过程基本一致,只不过在数据从输入流中读取后,会先将其缓存到一个缓冲区中,然后再从缓冲区中读取数据。同时,BufferedInputStream还提供了mark和reset方法,可以对数据流进行标记和重置,方便对流的操作。
使用BufferedInputStream类读取文件
在进行文件读取时,我们可以使用BufferedInputStream类来提高读取效率。下面是一个使用BufferedInputStream类读取文件的示例代码:
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("./template/hello.txt"))) {
byte[] buffer = new byte[1024];
int length;
while ((length = bis.read(buffer)) != -1) {
// do something with the data
}
} catch (IOException e) {
// handle exception
}
上面的代码中,我们首先创建了一个BufferedInputStream对象,并将其包装在一个try-with-resources语句中,这样可以自动关闭资源。然后我们创建一个字节数组作为缓冲区,读取文件时每次读取1024个字节,读取到文件末尾时返回-1。我们可以在while循环中对读取到的数据进行处理。
使用BufferedInputStream类读取文件时,每次读取的数据会先被读入缓冲区中,当缓冲区的数据被读取完后,再从文件中读取新的数据。这样可以减少I/O操作的次数,提高读取数据的效率。
使用BufferedInputStream类写入文件
在进行文件写入时,我们同样可以使用BufferedInputStream类来提高写入效率。下面是一个使用BufferedInputStream类写入文件的示例代码:
try (BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("./template/hello.txt"))) {
byte[] data = "Hello, jym! ".getBytes();
bos.write(data);
} catch (IOException e) {
// handle exception
}
上面的代码中,我们首先创建了一个BufferedOutputStream对象,并将其包装在一个try-with-resources语句中,这样可以自动关闭资源。然后我们将要写入的数据转换成字节数组,并通过BufferedOutputStream对象将数据写入到文件中。
使用BufferedInputStream类写入文件时,每次写入的数据会先被写入到缓冲区中,当缓冲区的数据写满后,再将缓冲区中的数据一次性写入到文件中。这样可以减少I/O操作的次数,提高写入数据的效率。
测试用例
代码演示
为了验证BufferedInputStream类的优化效果,我们可以编写一个测试用例。下面是一个使用BufferedInputStream类读取文件的测试用例:
package com.example.javase.io.bufferedInputStream;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
/**
* @author bug菌
* @version 1.0
* @date 2023/10/13 17:51
*/
public class BufferedInputStreamTest {
public static void main(String[] args) {
long start = System.currentTimeMillis();
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("./template/hello.txt"))) {
byte[] buffer = new byte[1024];
int length;
while ((length = bis.read(buffer)) != -1) {
String content = new String(buffer, 0, length);
System.out.println("读取内容为:" + content);
}
} catch (IOException e) {
// handle exception
}
long end = System.currentTimeMillis();
System.out.println("Time used: " + (end - start) + "ms");
}
}
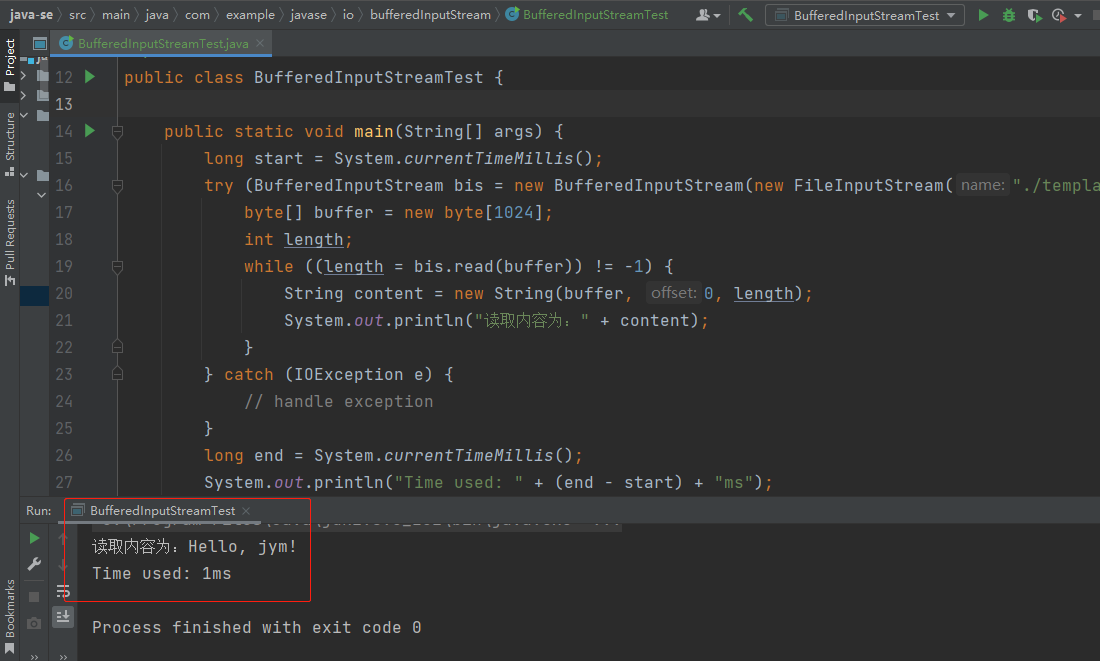
上面的代码中,我们首先记录了开始时间,然后使用BufferedInputStream类读取文件,并在while循环中对读取到的数据进行处理。最后,在读取数据时,将字节数组转换为字符串,并使用 System.out.println() 方法打印出来;并记录了结束时间,并输出总共使用的时间。
我们可以在不使用BufferedInputStream类的情况下编写一个相同的测试用例,然后比较两个测试用例的运行时间,从而验证BufferedInputStream类的优化效果。
测试代码解析
这段代码演示了如何使用BufferedInputStream读取文件内容。
-
首先导入需要的类,包括
BufferedInputStream、FileInputStream、IOException等; -
在main函数中,首先记录程序开始的时间;
-
使用
try-with-resources语句创建一个BufferedInputStream对象,它包装了一个FileInputStream对象,用于读取指定路径下的hello.txt文件; -
创建一个byte数组作为缓冲区,长度为1024;
-
使用while循环读取文件内容,每次读取的数据被存储在缓冲区中,长度由read()方法返回;
-
将从缓冲区中读取的字节转换为字符串,输出到控制台;
-
catch IOException异常,处理异常; -
记录程序结束的时间;
-
输出程序执行时间。
需要注意的是,使用BufferedInputStream可以提高读取文件的效率,但在读取大文件时,可能会导致内存溢出,需要注意调整缓冲区的大小。
测试结果
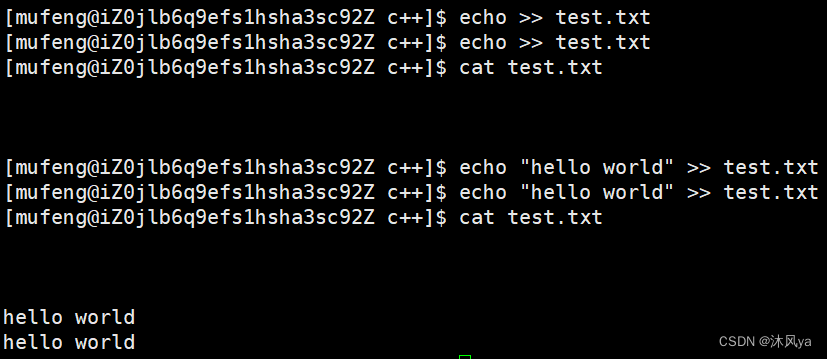
如下是运行测试用例所得截图,仅供参考:
小结
通过本文的介绍,我们了解了如何使用Java中的BufferedInputStream类来提高I/O操作的效率。我们可以使用BufferedInputStream类来读取文件和写入文件,达到减少I/O操作次数、提高效率的目的。同时我们还编写了一个测试用例来验证BufferedInputStream类的优化效果。
总结
BufferedInputStream类是Java中的一个输入流缓冲器,它可以提高I/O操作的效率。我们可以使用BufferedInputStream类来读取文件和写入文件,达到减少I/O操作次数、提高效率的目的。通过编写测试用例,我们验证了BufferedInputStream类的优化效果。在进行文件操作时,我们可以尽可能使用BufferedInputStream类来提高效率。