基础环境说明
1、环境准备
1、启动4台服务器(在同一个网段内)。
2、重命名4台服务器,方便区分。
hostnamectl set-hostname swarm1
reboot
安装docker。参考文章:云原生(二)、Docker基础
2、DockerSwarm架构
在 Docker 中,Swarm 是一种容器编排工具,它允许用户在一个集群中管理多个 Docker 容器。Docker Swarm 允许您将多个 Docker 守护进程组织成一个虚拟的 Docker 引擎,这个引擎可以用来部署您的容器化应用程序。通过 Docker Swarm,您可以轻松地管理、扩展和调度容器,以便适应不同规模的工作负载。
Docker Swarm 提供了以下主要功能:
- 服务编排: 允许您定义和管理多个服务,并将它们部署到 Swarm 集群中的节点上。
- 高可用性: Docker Swarm 提供了高可用性的容器服务,如果某个节点出现故障,Swarm 将会重新分配容器到其他可用节点上,从而保证您的应用程序的可用性。
- 负载均衡: Swarm 提供内置的负载均衡功能,可以将流量分发到集群中运行的容器服务上。
- 自动扩展: Swarm 允许您根据工作负载的需求自动扩展容器服务,以应对流量的变化。
- 安全性: Docker Swarm 提供了各种安全特性,包括 TLS 加密、角色基础访问控制(RBAC)等,以保护您的集群和容器。
官网地址: https://docs.docker.com/engine/swarm/how-swarm-mode-works/nodes/
管理节点Manage与工作节点Worker。他们遵循高可用协议Raft,即保证大多数节点存活才能使用,在这里,就是需要2台及以上的Mange节点存活。
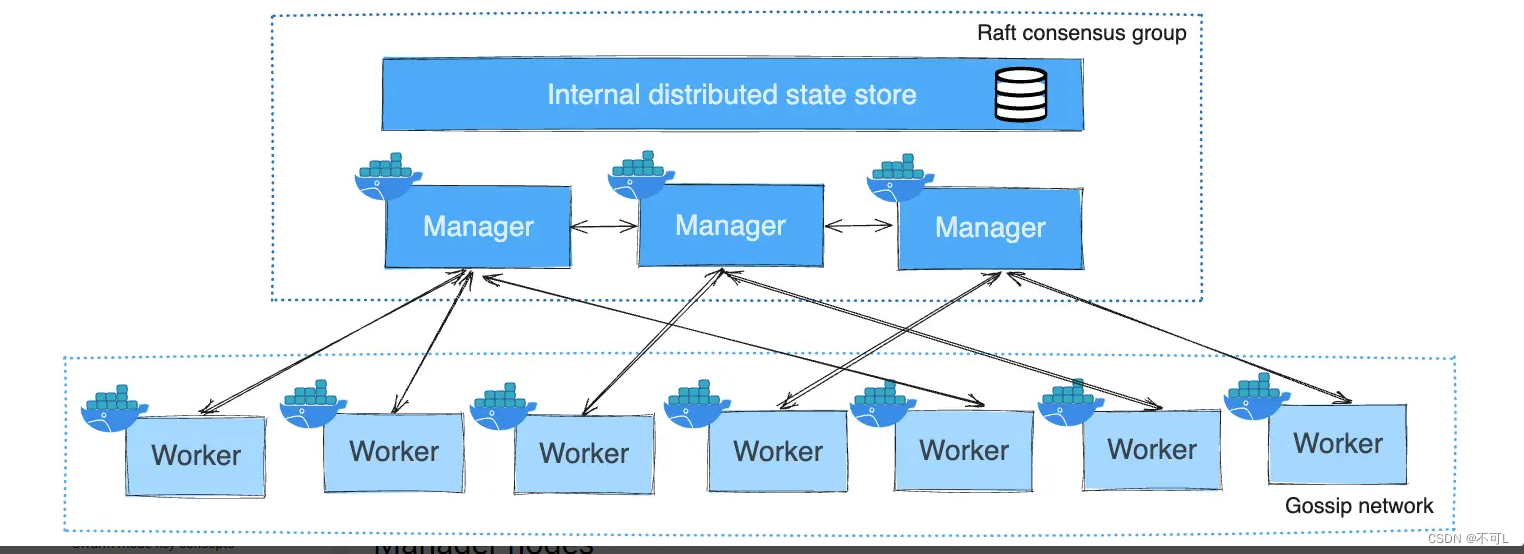
3、搭建集群环境
1、初始化第一个节点
使用命令docker swarm init --advertise-addr ip
[root@swarm1 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether fa:16:3e:0f:69:6a brd ff:ff:ff:ff:ff:ff
inet 192.168.2.3/20 brd 192.168.15.255 scope global dynamic noprefixroute eth0
valid_lft 315355602sec preferred_lft 315355602sec
inet6 fe80::f816:3eff:fe0f:696a/64 scope link
valid_lft forever preferred_lft forever
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:57:f2:17:06 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:57ff:fef2:1706/64 scope link
valid_lft forever preferred_lft forever
#暴露第一个节点
[root@swarm1 ~]# docker swarm init --advertise-addr 192.168.2.3
Swarm initialized: current node (hi3e42klj5okwv48u13e9phmd) is now a manager.
#添加工作节点的命令
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-0ac1f68fpc9c7laupcj53q7sgp650m5204ll4snj8npi8hl4x6-eqjzl0u227agfl3pe6mrk8r8m 192.168.2.3:2377
#添加管理节点的命令
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
2、将第二台服务器加入工作节点
在第二台服务器中,使用第一步中得到的token命令
[root@swarm2 ~]# docker swarm join --token SWMTKN-1-0ac1f68fpc9c7laupcj53q7sgp650m5204ll4snj8npi8hl4x6-eqjzl0u227agfl3pe6mrk8r8m 192.168.2.3:2377
This node joined a swarm as a worker.
3、将第三台服务器加入管理节点
在第一台服务器中,使用第一步中的添加管理节点命令
[root@swarm1 ~]# docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join --token SWMTKN-1-0ac1f68fpc9c7laupcj53q7sgp650m5204ll4snj8npi8hl4x6-cr4cg020fta2etrxqc72zs3el 192.168.2.3:2377
得到token命令后,在第三台服务器中使用该命令
[root@swarm3 ~]# docker swarm join --token SWMTKN-1-0ac1f68fpc9c7laupcj53q7sgp650m5204ll4snj8npi8hl4x6-cr4cg020fta2etrxqc72zs3el 192.168.2.3:2377
This node joined a swarm as a manager.
[root@swarm3 ~]#
4、第四台服务器加入管理节点
[root@swarm4 ~]# docker swarm join --token SWMTKN-1-0ac1f68fpc9c7laupcj53q7sgp650m5204ll4snj8npi8hl4x6-cr4cg020fta2etrxqc72zs3el 192.168.2.3:2377
This node joined a swarm as a manager.
5、检查集群部署结果
在管理者节点中使用命令
Leader即主节点,Reachable为子节点
[root@swarm4 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
hi3e42klj5okwv48u13e9phmd swarm1 Ready Active Leader 25.0.4
h9hjplib3dsql1k8v2x2qutax swarm2 Ready Active 25.0.4
seozhuxajbfkwu95d9ox14uej swarm3 Ready Active Reachable 25.0.4
8vxwp3m4sk24hhkethpd6axxs * swarm4 Ready Active Reachable 25.0.4
6、注意
如果加入集群时,当前服务器已经存在一个集群了,需要先离开当前集群,才能加入新的
docker swarm leave --force
4、Raft协议理解
Raft协议是一种共识算法,用于在分布式系统中实现一致性。它通过确保所有节点在某个时刻对系统状态达成一致,从而保证系统的可靠性和正确性。Raft协议由Diego Ongaro和John Ousterhout在2014年提出,并设计用于替代Paxos算法,以简化分布式系统的实现和理解。
在Raft协议中,系统中的节点被分为领导者(leader)、跟随者(follower)和候选人(candidate)。领导者负责接收客户端请求并复制状态到其他节点,而跟随者和候选人则遵从领导者的指示。如果领导者失效,系统中的其他节点可以通过选举新的领导者来维持一致性。
Raft协议通过简化算法和引入领导者的概念,使得其更易于理解和实现。这种可理解性使得Raft成为了分布式系统领域中备受青睐的共识算法之一,被广泛应用于诸如分布式数据库、分布式存储系统等领域。
我们上面的环境搭建中,采用的是3管理节点,1工作节点的方式。
如果是双主双从搭建,现在我们只有两个管理节点,如果一个节点挂了,另外一个节点也不能用,Raft一致性算法,是确保大多数节点存活才可以用,至少大于1台! 生产环境最少3 manager
实验
我们拥有3台管理节点,分别是swarm1、swarm3、swarm4,其中Leader节点是swarm1,1台工作节点swarm2.
在我们上面搭建好的集群中,使用命令systemctl stop docker让服务器中的docker停止工作。观察Raft的选举和工作状态
sudo systemctl stop docker #停止docker
sudo systemctl start docker #启动docker
测试1
- 停止swarm2,在其他管理节点执行docker node ls,集群仍然存活,工作节点swarm2状态为down
[root@swarm3 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
hi3e42klj5okwv48u13e9phmd swarm1 Ready Active Reachable 25.0.4
h9hjplib3dsql1k8v2x2qutax swarm2 Down Active 25.0.4
seozhuxajbfkwu95d9ox14uej * swarm3 Ready Active Reachable 25.0.4
8vxwp3m4sk24hhkethpd6axxs swarm4 Ready Active Leader 25.0.4
测试2
- 停止swarm3,在其他管理节点执行docker node ls,集群仍然存活
[root@swarm4 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
hi3e42klj5okwv48u13e9phmd swarm1 Ready Active Leader 25.0.4
h9hjplib3dsql1k8v2x2qutax swarm2 Ready Active 25.0.4
seozhuxajbfkwu95d9ox14uej swarm3 Down Active Unreachable 25.0.4
8vxwp3m4sk24hhkethpd6axxs * swarm4 Ready Active Reachable 25.0.4
- 再停止swarm4,在其他管理节点执行docker node ls,集群停止工作
[root@swarm4 ~]# docker node ls
Error response from daemon: rpc error: code = DeadlineExceeded desc = context deadline exceeded
测试3
一开始就直接停止Leader节点swarm1,在其他管理节点执行docker node ls,集群仍然存活。推举出了新的Leader
[root@swarm4 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
hi3e42klj5okwv48u13e9phmd swarm1 Ready Active Unreachable 25.0.4
h9hjplib3dsql1k8v2x2qutax swarm2 Ready Active 25.0.4
seozhuxajbfkwu95d9ox14uej swarm3 Down Active Leader 25.0.4
8vxwp3m4sk24hhkethpd6axxs * swarm4 Ready Active Reachable 25.0.4
测试4
- 停止swarm3,在其他管理节点执行docker node ls,集群仍然存活
[root@swarm4 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
hi3e42klj5okwv48u13e9phmd swarm1 Ready Active Leader 25.0.4
h9hjplib3dsql1k8v2x2qutax swarm2 Ready Active 25.0.4
seozhuxajbfkwu95d9ox14uej swarm3 Down Active Unreachable 25.0.4
8vxwp3m4sk24hhkethpd6axxs * swarm4 Ready Active Reachable 25.0.4
- 再停止swarm1,在其他管理节点执行docker node ls,集群停止工作。且由于Leader节点停止工作,集群无法再次重启。只能重新初始化集群设置。
[root@swarm3 ~]# docker node ls
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.
总结
1、先保证有两个管理节点,挂掉其中一台。nodels 命名不可用
2、如果有work节点离开了,状态会更新为down,不可用了
3、可以没有Work节点,全是管理节点
4、leader挂了,就全部都挂掉了
Raft保证:至少要保证有两个及两个以上的管理者节点,集群才可以使用,否则直接挂掉
所有管理者节点挂掉的话。需要全部移除集群,重新初始化才可以再次使用了
5、swarm实战
示例1
Nginx集群部署。
#在任意manage节点执行命令
[root@swarm1 ~]# docker service create -p 8888:80 --name myNginx nginx
sxa1g4p45k268e6do9td0y2ie
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
[root@swarm1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
sxa1g4p45k26 myNginx replicated 1/1 nginx:latest *:8888->80/tcp
# 成功后我们会发现,4台服务器的ip:8888都能成功访问nginx的初始页面。
# 通过docker service启动服务,在任何服务器都可以访问到该服务,不需要在启动容器的节点中访问。
查看我们刚刚部署的nginx的具体信息
[root@swarm1 ~]# docker service inspect --pretty myNginx
ID: sxa1g4p45k268e6do9td0y2ie
Name: myNginx
#副本数量
Service Mode: Replicated
Replicas: 1
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: nginx:latest@sha256:1a53eb723d17523512bd25c27299046cfa034cce309f4ed330c943a304513f59
Init: false
Resources:
Endpoint Mode: vip
Ports:
PublishedPort = 8888
Protocol = tcp
TargetPort = 80
PublishMode = ingress
动态扩缩容
- 创建时启动多个副本
docker service create --replicas 3 --name myNginx1 nginx
- 动态更新
docker service update --replicas 3 myNginx
[root@swarm1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
sxa1g4p45k26 myNginx replicated 1/1 nginx:latest *:8888->80/tcp
vsk8icrao3bk myNginx1 replicated 3/3 nginx:latest
[root@swarm1 ~]# docker service update --replicas 3 myNginx
myNginx
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged
[root@swarm1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
sxa1g4p45k26 myNginx replicated 3/3 nginx:latest *:8888->80/tcp
vsk8icrao3bk myNginx1 replicated 3/3 nginx:latest
- 扩缩容
docker service scale myNginx1 =6
- 回滚
docker service rollback myNginx
[root@swarm1 ~]# docker service rollback myNginx
myNginx
rollback: manually requested rollback
overall progress: rolling back update: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
[root@swarm1 ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
sxa1g4p45k26 myNginx replicated 1/1 nginx:latest *:8888->80/tcp
vsk8icrao3bk myNginx1 replicated 3/3 nginx:latest
#线上灰度发布的原理
[root@swarm1 ~]# docker service update --image nginx:1.18.0-alpine --update-parallelism 1 --update-delay 10s myNginx1
myNginx1
overall progress: 1 out of 3 tasks
1/3: running [==================================================>]
2/3: preparing [=================================> ]
3/3:
#一台一台机器逐次启动,直到所有容器更新完成
#docker service update --help 查看帮助
示例2
- 创建一个集群网络
docker network create -d overlay tomcat-net
- 创建service
docker service create --name tomcat --network tomcat-net -p 8080:8080 --replicas 3 tomcat
- 扩缩容
docker service scale tomcat=6
- 删除服务
docker service rm id
#服务一旦移除,所有容器都会被移除
示例3
- 创建网络
docker network create -d overlay demo
- 创建mysql服务
rootanode111 ~]# docker service create --name mysql --env MYSQL_ROOT_PASSWORD=root --env MYSQL_DATABASE=wordpress --network demo --mount type=volume,source=mysql-data,destination=/var/lib/mysql mysql:5.7.24
- 创建wordpress服务
[root@node111 ~]# docker service create --name wordpress -p 80:80 --env WORDPRESS_DB_USER=root --env WORDPRESS_DB_PASSWORD=root --env WORDPRESS_DB_HOST=mysql:3306 --env WORDPRESS_DB_NAME=wordpress --network demo wordpress
成功后,4台服务器的ip:80都能访问到我们的wordpress。
我们也可以对刚刚运行的2个服务进行动态扩缩容
[root@swarm1 ~]# docker service scale mysql=4
mysql scaled to 4
overall progress: 4 out of 4 tasks
1/4: running [==================================================>]
2/4: running [==================================================>]
3/4: running [==================================================>]
4/4: running [==================================================>]
[root@swarm1 ~]# docker service scale wordpress=4
wordpress scaled to 4
overall progress: 4 out of 4 tasks
1/4: running [==================================================>]
2/4: running [==================================================>]
3/4: running [==================================================>]
4/4: running [==================================================>]
服务模式
服务模式一共有两种:Ingress和Host,如果不指则默认的是Ingress;
- Ingress模式(overlay网络)下,到达Swarm任可节点的8080端口的流量,都会映射到任何服务副本的J部80端口,就算该节点上没有tomcat服务副本也会映射;
- Host模式下,仅在运行有容器副本的机器上开放端口访问,使用Host模式的命令如下:
docker service create --name tomcat
--network tomcat-net
--publish published=8080,target=8080,modehost
--replicas 2
tomcat:7.0.96-jdk8-openjdk
docker service ps tomcat
6、swarm相关概念
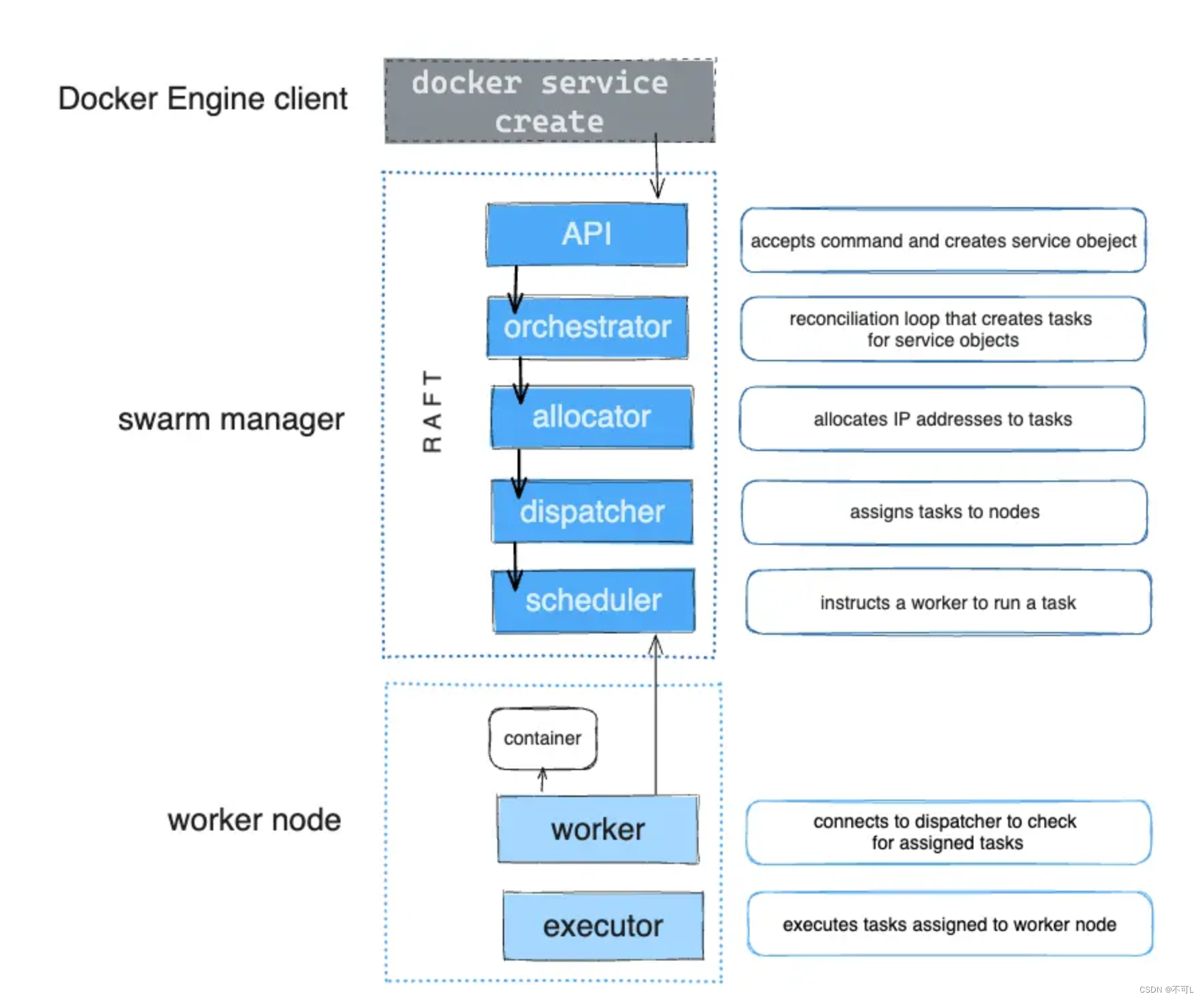
- 1.Docker Engine集成集群管理
使用Docker Engine Cll 创建一个Docker Engine的swarm模式,在集群中部署应用程序服务。链接数以万计的docker节点。 - 2.去中心化设计
Swarm角色分为Manager和Worker节点,Manager节点故障不影响应用使用,raft协议原则。 - 3.扩容缩容
可以声明每个服务运行的容器数量,通过添加或删除容器数自动调整期望的状态。 - 4.期望状态协调
Swarm Manager节点不断监视集群状态,并调整当前状态与期望状态之间的差异。例如,设置一个服务运行10个副本容器,如果两个副本的服务器节点崩溃,Manager将创建两个新的副本替代崩溃的副本。并将新的副本分配到可用的worker节点。 - 5.多主机网络
可以为服务指定overlay网络。当初始化或更新应用程序时,Swarm manager会自动为overlay网络上的容器分配IP地址。 - 6.服务发现
Swarm manager节点为集群中的每个服务分配唯一的DNS记录和负载均衡VIP。可以通过Swarm内置的DNS服务器查询集群中每个运行的容器。 - 7.负载均衡
实现服务副本负载均衡,提供入口访问。也可以将服务入口暴露给外部负载均衡器再次负载均衡。 - 8.安全传输
Swarm中的每个节点使用TLS相互验证和加密,确保安全的其他节点通信。 - 9.滚动更新
升级时,逐步将应用服务更新到节点,如果出现问题,可以将任务回滚到先前版本
工作模式
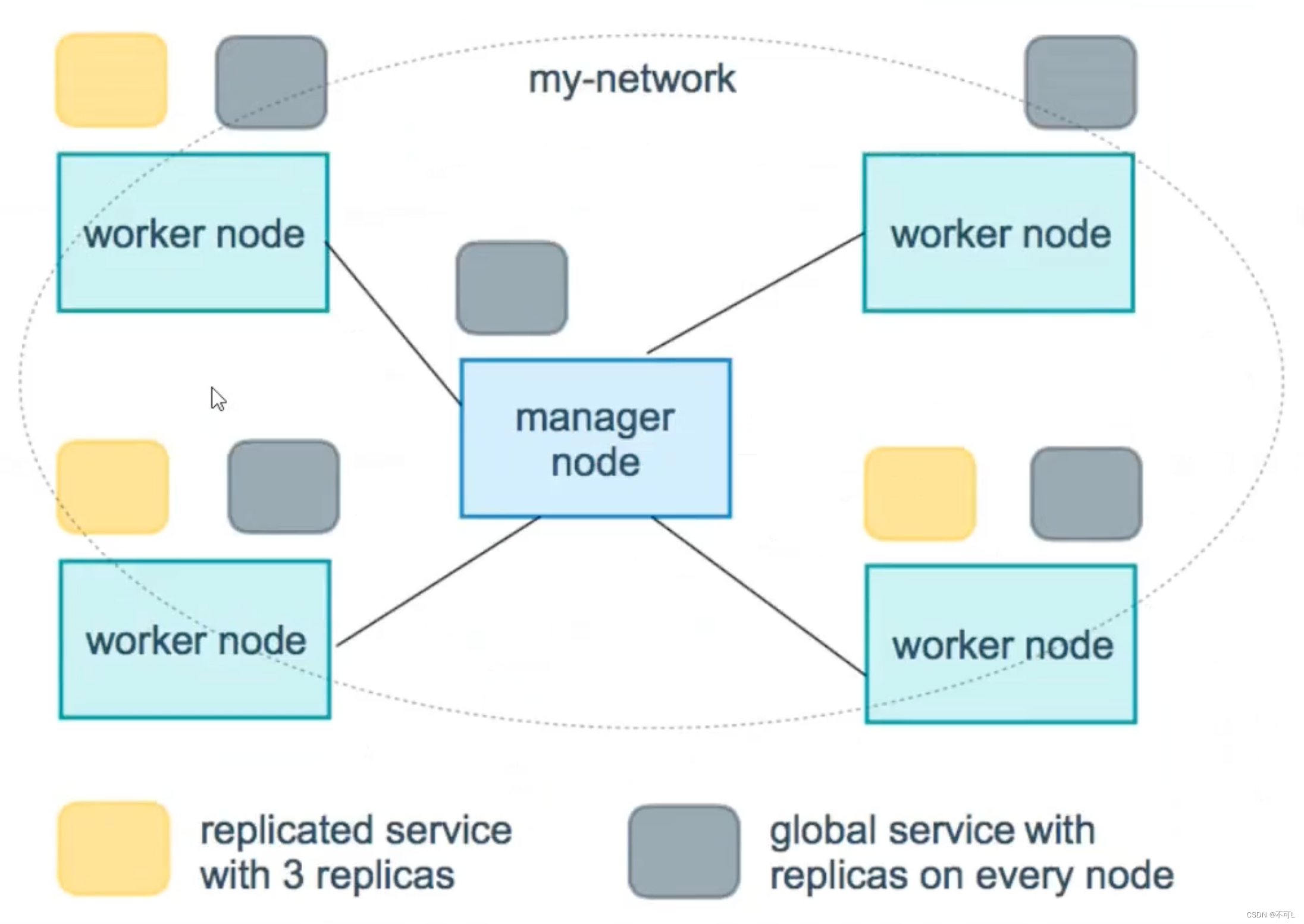
服务副本与全局服务
在docker swarm中部署的service,有2种类型。
- replicated(副本)
- global(全局)启动一个服务,会在所有节点上,自动拉起一个容器
下面的图显示了一个有3个副本的service(黄色)和一个global的service(灰色)在这里插入图片描述
--mode string Service mode ("replicated", "global", "replicated-job", "global-job") (default "replicated")
补充Label的说明
#我们讨论了 service 部署的两种模式:global mode 和 replicated mode。无论采用 global mode 还是 replicated mode,副本运行在哪些节点都是由 Swarm 决定的,作为用户我们有没有可能精细控制 service 的运行位置呢?
答:能,使用 1abe1
逻辑分两步:
1、为每个 node 定义 label.
2、设置 service 运行在指定 label的 node 上.
docker node update --label-add env=test 节点1
docker node update --label-add env=prod swarm-worker2
#指定在哪台服务器中拉起这个服务。很少使用
docker service create \
--constraint node.labels jenv-=test \
--replicas 3\
--name my_web
--publish 8080:80 \
httpd
#更新 service,将其迁移到生产环境:
docker service update --constraint-rm node.labels.env==test my_web
docker service update --constraint-add node.labels.env==prod my_weh
7、网络概念说明
https://docs.docker.com/engine/swarm/ingress/
在 Swarm Seryice 中有三个重要的网络概念!
-
Overlay networks 管理 Swarm 中 Docker守护进程间的通信。你可以将服务附加到一个或多个己存在的网络上,使得服务与服overlay务之间能够通信。
-
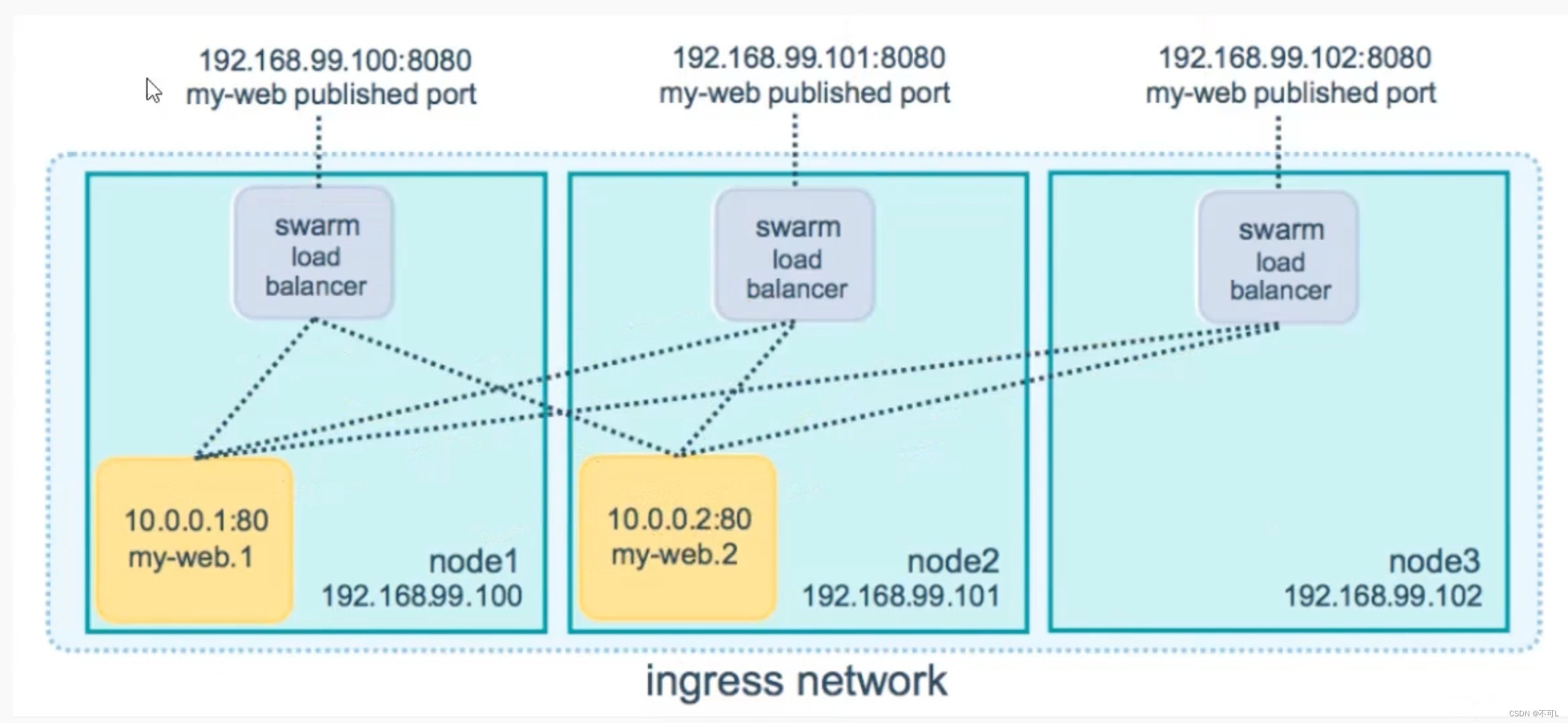
ingress network是一个特殊的网络,用于服务节点间的负载均衡:启动多个服务,访问的时候随机分配到一个服务器中。当任何 Swarm 节点在发布的端口上接收到请求时,它将该请overlayX求交给一个名为 IPVS 的模块。IPVS 跟踪参与该服务的所有IP地址,选择其中的一个,并通过ingress 网络将请求路由到它。
初始化或加入 Swarm 集群时会自动创建 ingress 网络,大多数情况下,用户不需要自定义配置。但是 docker 17.05 和更高版本允许你自定义。
-
docker_gwbridge是一种桥接网络,将 overlay 网络(包括 ingress网络)连接到一个单独的Docker 守护进程的物理网络。默认情况下,服务正在运行的每个容器都连接到本地 docker 守护进程主机的 docker_gwbridge 网络。
docker_gwbridge网络在初始化或加入 Swarm 时自动创建。大多数情况下,用户不需要自定义配置,但是 Docker 允许自定义。
说明
-
docker_gwbridge和ingress是swarm自动(别建的,当用户执行了docker swarm init/connect之后
-
docker_gwbridge是bridge类型的负责本机container和主机直接的连接
间的路由。 -
ingress负责service在多个主机container之
-
custom-network是用户自己创建的overla网络,通常我们都需要创建自己的network并把service挂在上面ingress网络。
vip(虚拟ip模式)
8、DokcerStack
单机:docker run 、docker compose
集群:docker service DockerStack
我们了解了Docker compose,它是用来进行一个完整的应用程序相互依赖的多个容器的编排的,但是缺点是不能在分布式多机器上使用;我们也介绍了Docker swarm,它构建了docker集群,并且可以通过docker service在不同集群节点上运行容器服务,但是缺点是不能同时编排多个服务。
单机模式下,我们可以使用 Docker Compose 来编排多个服务,而 Docker Swarm 只能实现对单个服务 的简单部署。通过 Docker Stack,我们只需对已有的 docker-cmpose.yml 配置文件稍加改造就可以完成 Docker 身群环境下的多服务编排。
但是在实际的生产开发中,我们一个完整的应用需要的服务往往不止一个,通过docker service 命令来部署的话会很麻烦,所以这里要讲一下Docker Stack,它用于向swarm集群部署完整的应用程序堆栈,可以在分布式多机器上同时编排多个有依赖关系的服务。
Stack能够在单个声明文件中定义复杂的多服务应用。还提供了简单的方式来部署应用并管理其完整的生命周期:初始化部署 ->健康检查 ->扩容->更新->回滚,以及其他功能!可以简单地理解iStack是集群下的Compose。
# 单机
docker compose up -d -c wordpress-compose.yaml
#集群
docker stack deploy wordpress-compose.yaml
实战
https://gitee.com/landylee007/voting-app?_from=gitee_search
这是一个开源的投票app,包含以下服务
- 5个应用服务:vote、redisworker、db、result
- 工具服务:vi、sua、lizer
首先创建一个docker-compose.yml文件,使用docker compose v3语法
docker stack deploy --compose-file docker-stack.yml vote
docker stack rm vote
# 项目中的docker-stack.yml文件,需要稍作修改,添加数据库初始用户信息
# environment:
# POSTGRES_USER: "postgres"
# POSTGRES_PASSWORD: "postgres"
# POSTGRES_HOST_AUTH_METHOD: "trust"
# 报错yaml: line 18: found character that cannot start any token ,解决:注意yml文件中不识别tab制表符
version: "3"
services:
redis:
image: redis:alpine
networks:
- frontend
deploy:
replicas: 1
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
db:
image: postgres:9.4
environment:
POSTGRES_USER: "postgres"
POSTGRES_PASSWORD: "postgres"
POSTGRES_HOST_AUTH_METHOD: "trust"
volumes:
- db-data:/var/lib/postgresql/data
networks:
- backend
deploy:
placement:
constraints: [node.role == manager]
vote:
image: dockersamples/examplevotingapp_vote:before
ports:
- 5000:80
networks:
- frontend
depends_on:
- redis
deploy:
replicas: 2
update_config:
parallelism: 2
restart_policy:
condition: on-failure
result:
image: dockersamples/examplevotingapp_result:before
ports:
- 5001:80
networks:
- backend
depends_on:
- db
deploy:
replicas: 1
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
worker:
image: dockersamples/examplevotingapp_worker
networks:
- frontend
- backend
depends_on:
- db
- redis
deploy:
mode: replicated
replicas: 1
labels: [APP=VOTING]
restart_policy:
condition: on-failure
delay: 10s
max_attempts: 3
window: 120s
placement:
constraints: [node.role == manager]
visualizer:
image: dockersamples/visualizer:stable
ports:
- "8080:8080"
stop_grace_period: 1m30s
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
deploy:
placement:
constraints: [node.role == manager]
networks:
frontend:
backend:
volumes:
db-data:
详细的部署流程
这里我们使用集群部署
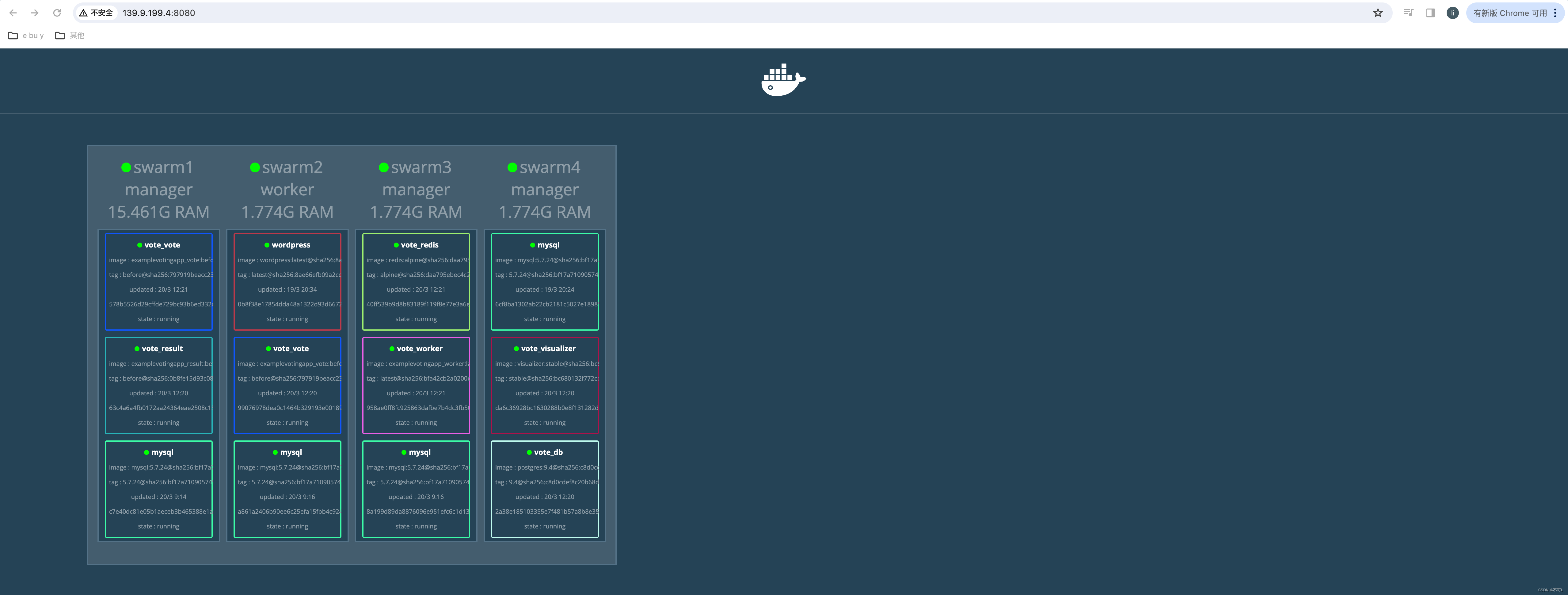
docker stack deploy --compose-file docker-stack.yml vote
部署成功后,通过ip访问
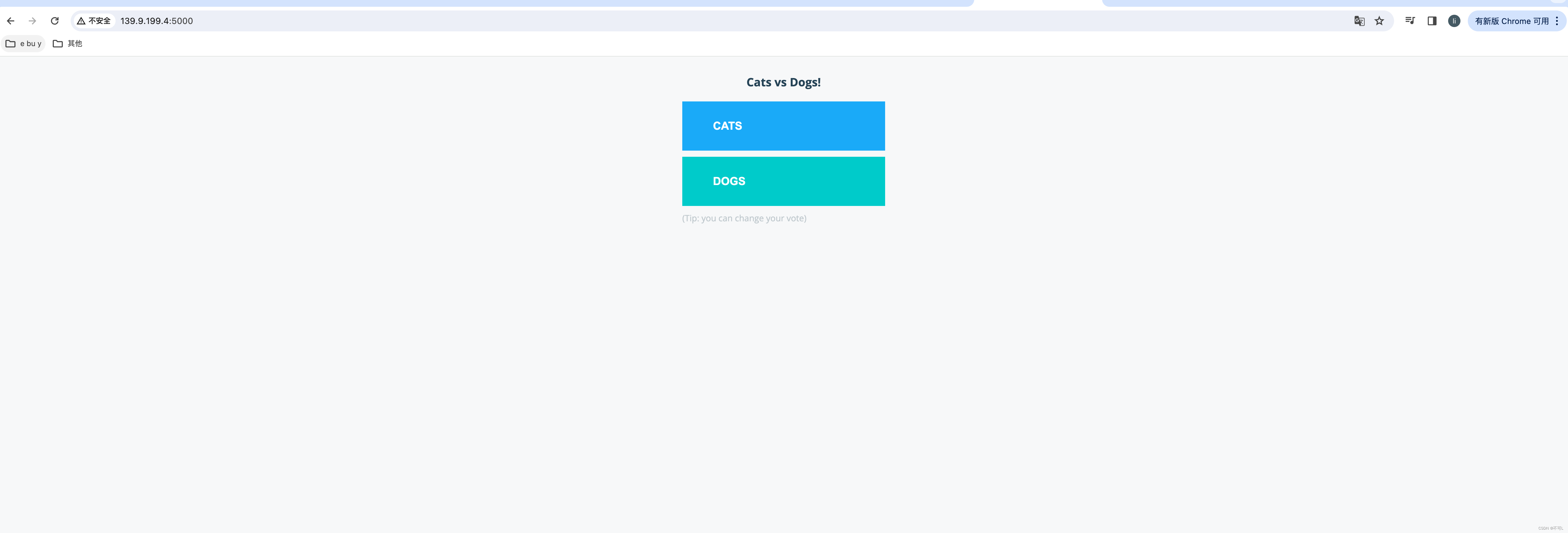
Docker Stack和 Compose区别
- Docker stack会忽略了“构建”指令,无法使用stack命令构建新镜像,它是需要镜像是预先已经构建好的。所以docker-compose更适合于开发场景;
- 它使用Docker API规范来操作容器。所以需要安装Docker-compose,以便与Docker-起DockerCompose是一个Python项目,在内部在您的计算机上使用;
- Docker Stack功能包含在Docker引擎中。你不需要安装额外的包来使用它,docker stacks 只是swarm mode的一部分。
- Dockerstack不支持基于第2版写的docker-compose.yml,也就是version版本至少为3。然而Docker Compose对版本为2和3的文件仍然可以处理
- docker stack把docker compose的所有工作老做完了,因此docker stack将占主导地位。同时,对于大多数用户来说,切换到使用dockerstack既不困难,也不需要太多的开销。如果是Docker新手,或正在选择用于新项目的技术,请使用docker stack.
9、DockerSecret&Config
Docker Secret 是 Docker 容器中存储敏感数据的一种机制。它们用于安全地存储和传输诸如密码、API 密钥、TLS 证书等敏感信息,以供容器应用程序使用。Docker Secret 是 Docker Swarm 和 Docker Compose 中的功能,用于将敏感数据传递给容器,并确保这些数据在容器中的使用是安全可靠的。
Docker Secret 的工作原理是将敏感数据存储在一个受 Docker 本地安全机制保护的地方,并将其传递给容器。在 Swarm 中,Secret 以加密的方式存储在 Swarm 中的 Raft 日志中,并且只有具有适当权限的服务才能访问它们。在 Compose 中,Secret 存储在本地的 Docker 配置目录中,也是以加密的方式存储。
使用 Docker Secret,可以更安全地管理敏感信息,避免将其硬编码到容器镜像中,从而提高了容器化应用程序的安全性和可移植性。
用法
要使用 Docker Secret,您可以按照以下步骤:
- 创建 Docker Secret:首先,您需要创建一个 Docker Secret。您可以使用
docker secret create命令来创建一个新的 Secret。例如:
echo "my_secret_data" | docker secret create my_secret_data -
上述命令将创建一个名为 my_secret_data 的 Secret,并将其值设置为 “my_secret_data”。
- 将 Secret 添加到服务中:一旦您创建了 Secret,您可以将其添加到 Docker 服务中。在 Docker Swarm 中,您可以使用
--secret标志将 Secret 添加到服务中。例如:
docker service create --name myservice --secret my_secret_data my_image
在 Docker Compose 中,您可以在 docker-compose.yml 文件中使用 secrets 关键字指定 Secret。例如:
version: '3.8'
services:
myservice:
image: my_image
secrets:
- my_secret_data
-
在容器中使用 Secret:一旦将 Secret 添加到服务中,您可以在容器中使用它。容器可以通过文件或环境变量访问 Secret 的值。
- 通过文件:在容器内,Secret 会被挂载到文件系统上的某个位置。例如,在 Linux 上,默认路径为
/run/secrets/<secret_name>。您可以在容器中读取此文件来获取 Secret 的值。 - 通过环境变量:Docker 还会将 Secret 的值以环境变量的形式传递给容器。环境变量的名称将是 Secret 的名称。例如,如果 Secret 名称为
my_secret_data,则环境变量名称将为MY_SECRET_DATA。
- 通过文件:在容器内,Secret 会被挂载到文件系统上的某个位置。例如,在 Linux 上,默认路径为
总结
到这里dokcer的集群通信的逻辑就完结了,但是Docker Swarm仍旧只是匆匆过客,最终还是需要回到Kuberness上!







![[C语言]结构体、位段、枚举常量、联合体](https://img-blog.csdnimg.cn/direct/ec489746976941eaa13d8328ca31860d.png)