政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras实战演绎
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
概述
深度神经网络(Deep Neural Network,DNN)是一种机器学习模型,由多个神经网络层组成,每层都包含多个神经元节点。相比浅层神经网络,深度神经网络具有更多的隐藏层,能够处理更复杂的问题。
深度神经网络的核心思想是通过多层非线性变换来逐步提取输入数据的高级特征表示。每一层的神经元通过权重和偏置进行计算,并通过激活函数进行非线性映射。数据从输入层经过多个隐藏层传递,最终输出一个预测结果。
深度神经网络的训练通常使用反向传播算法。该算法通过计算预测结果与实际值之间的误差,并根据误差调整每一层中的权重和偏置,以提高模型的准确性。训练过程需要大量的数据和计算资源,但深度神经网络在图像识别、语音识别、自然语言处理等领域取得了很大的成功。
深度神经网络的发展得益于大数据和计算硬件的进步。随着深度学习领域的不断发展,出现了许多经典的深度神经网络模型,如卷积神经网络(Convolutional Neural Network,CNN)用于图像处理,循环神经网络(Recurrent Neural Network,RNN)用于序列数据处理,以及生成对抗网络(Generative Adversarial Network,GAN)用于生成新的数据等。
总之,深度神经网络是一种强大的机器学习模型,通过多层非线性变换和反向传播算法,能够学习到复杂的特征表示,广泛应用于各种领域的问题求解。
现在我们开始全面介绍深度神经网络,并通过它为网络添加隐藏层,揭示复杂关系。
引言
在这篇文章中,我们将看到如何构建能够学习深度神经网络著名的复杂关系的神经网络。
这里的关键思想是模块化,通过从简单的功能单元建立一个复杂的网络。
我们已经看到线性单元如何计算线性函数 - 现在我们将看到如何将这些单个单元组合和修改以模拟更复杂的关系。
层
神经网络通常将其神经元组织成层。当我们将具有共同输入集的线性单元集合在一起时,我们得到一个稠密层。
(一个由两个线性单元组成的密集层,接收两个输入和一个偏差。)
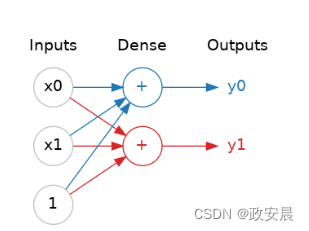
你可以将神经网络中的每一层看作是进行某种相对简单的转换。
通过一系列深层的层次,神经网络可以以越来越复杂的方式转变输入。在经过良好训练的神经网络中,每一层都是一个将我们逐渐接近解决方案的转换。
许多种层次
在 Keras 中,"layer" 是一种非常通用的概念。 一个 layer 本质上是一种数据转换方式。许多 layer,比如卷积层和循环层,通过使用神经元来转换数据,它们的主要区别在于它们所形成的连接模式。其他的 layer 则用于特征工程或者简单的算术运算。
激活函数
事实证明,两个没有任何中间层的密集层并不比单个密集层更好。密集层本身无法将我们从线条和平面的世界中移出。我们需要的是一些非线性的东西,我们需要的是激活函数。
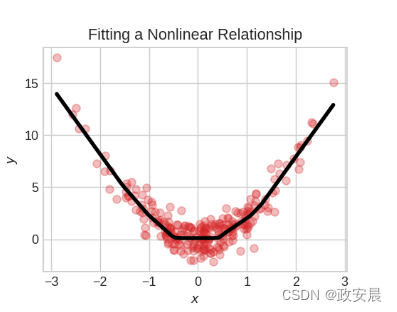
没有激活函数,神经网络只能学习线性关系。为了拟合曲线,我们需要使用激活函数。
激活函数就是我们对于每个层的输出(激活)应用的一种函数。最常见的是修正线性单元函数max(0,x)。

整流器函数的图表是一条线,其负部分被"整流"为零。将这个函数应用于神经元的输出将使数据产生弯曲,使我们远离简单的直线。
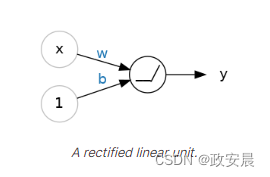
当我们将整流器连接到线性单元时,我们得到一个整流线性单元或ReLU(修正线性单元)。因此,将整流函数称为"ReLU函数"是很常见的。
应用ReLU激活到线性单元意味着输出变为max(0, w * x + b),我们可以将其在图表中绘制如下:
堆叠密集层
现在我们有了一些非线性性,让我们看看如何堆叠层来进行复杂的数据转换。
(一堆密集层构成了一个“全连接”的网络。)

输出层之前的层有时被称为隐藏层,因为我们从未直接看到它们的输出。
现在,请注意最后(输出)层是一个线性单元(意味着没有激活函数)。
这使得这个网络适用于回归任务,我们试图预测某个任意数值。其他任务(如分类)可能需要在输出上使用激活函数。
构建序列模型
我们一直在使用的Sequential模型将按顺序连接一个层的列表:第一层获得输入,最后一层产生输出。这创建了上图所示的模型:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
# the hidden ReLU layers
layers.Dense(units=4, activation='relu', input_shape=[2]),
layers.Dense(units=3, activation='relu'),
# the linear output layer
layers.Dense(units=1),
])请确保将所有的层一起作为一个列表传递,如[layer, layer, layer, ...],而不是作为单独的参数传递。要向层添加激活函数,只需在激活参数中给出其名称。
练习:一起创建一个深度神经网络
介绍
在这个练习中,我们将看到如何通过在Sequential模型中堆叠层来构建深度神经网络。通过在隐藏层后添加激活函数,我们使网络能够学习数据中更复杂(非线性)的关系。
您将构建一个具有多个隐藏层的神经网络,然后探索一些超出ReLU的激活函数。
代码如下:
import tensorflow as tf
# Setup plotting
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.deep_learning_intro.ex2 import *在具体的数据集中,您的任务是根据不同配方预测混凝土的抗压强度。
下面这段中已经有数据集存在。(我们使用的Kaggle来进行演绎)
输入形状
这个任务的目标是'CompressiveStrength'列。其余列是我们将用作输入的特征。这个数据集的输入形状应该是什么?
# YOUR CODE HERE
input_shape = ____
# Check your answer
q_1.check()
# Lines below will give you a hint or solution code
#q_1.hint()
#q_1.solution()定义一个具有隐藏层的模型
现在创建一个模型,其中包含三个隐藏层,每个隐藏层都有512个单元,使用ReLU激活函数。确保包括一个输出层,并且没有激活函数,并且将输入形状作为参数传递给第一层。
参考代码如下:
from tensorflow import keras
from tensorflow.keras import layers
# YOUR CODE HERE
model = ____
# Check your answer
q_2.check()
# Lines below will give you a hint or solution code
#q_2.hint()
#q_2.solution()我写了一个示例:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(input_shape,)))
model.add(Dense(512, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(1, activation=None))
激活层
让我们来探索一些激活函数。
将激活函数附加到稠密层的常见方式是将其作为定义的一部分,并使用激活参数。然而有时候你可能希望在稠密层和其激活函数之间加入其他层。(我们将在第5课中使用批归一化的例子来看一个例子。)在这种情况下,我们可以使用自己的激活层来定义激活函数,如下所示:
layers.Dense(units=8),
layers.Activation('relu')这与普通的方式完全相等:layers.Dense(units=8, activation='relu')。重写以下模型,使每个激活函数都在自己的激活层中。
### YOUR CODE HERE: rewrite this to use activation layers
model = keras.Sequential([
layers.Dense(32, activation='relu', input_shape=[8]),
layers.Dense(32, activation='relu'),
layers.Dense(1),
])
# Check your answer
q_3.check()
# Lines below will give you a hint or solution code
#q_3.hint()
#q_3.solution()可选:ReLU的替代方案
ReLU(Rectified Linear Unit)是一种常用的激活函数,它在神经网络中被广泛使用。然而,除了ReLU之外,还有一些替代方案可以用作激活函数,具体如下:
Sigmoid函数:Sigmoid函数将输入值映射到一个介于0和1之间的连续输出。它在早期的神经网络中广泛使用,但在深度神经网络中的性能较差。
Tanh函数:Tanh函数是双曲正切函数,它将输入值映射到一个介于-1和1之间的连续输出。与Sigmoid函数类似,Tanh函数在早期的神经网络中使用较多,但在深度神经网络中也存在梯度消失问题。
Leaky ReLU:Leaky ReLU是对ReLU的改进,它在负数输入时引入了一个小的斜率,以避免ReLU的神经元死亡问题。Leaky ReLU的数学表达式为f(x) = max(ax, x),其中a是一个很小的常数。
Parametric ReLU (PReLU):PReLU是对Leaky ReLU的进一步改进,它不是使用固定的斜率,而是将负数区域的斜率作为一个可学习的参数来确定。这使得神经网络可以更好地适应不同的数据集。
Exponential Linear Units (ELUs):ELU是一种具有负数区域的激活函数,类似于Leaky ReLU和PReLU,但它具有更平滑的曲线。ELU可以缓解梯度消失问题,并且在某些任务中比ReLU表现更好。
总而言之,虽然ReLU是最常用的激活函数之一,但在某些情况下,上述的替代方案可能会更适合特定的神经网络架构和任务。
“relu”激活函数的变体有很多,包括“elu”,“selu”和“swish”等,你可以在Keras中使用它们。在特定任务中,有时一个激活函数比另一个表现更好,因此在开发模型时可以考虑尝试不同的激活函数。ReLU激活函数在大多数问题上表现良好,因此是一个很好的起点。
让我们来看看其中几个图形。将激活函数从 'relu' 更改为上面提到的其他一种。然后运行单元格以查看图形。(查阅文档以获取更多想法。)
# YOUR CODE HERE: Change 'relu' to 'elu', 'selu', 'swish'... or something else
activation_layer = layers.Activation('relu')
x = tf.linspace(-3.0, 3.0, 100)
y = activation_layer(x) # once created, a layer is callable just like a function
plt.figure(dpi=100)
plt.plot(x, y)
plt.xlim(-3, 3)
plt.xlabel("Input")
plt.ylabel("Output")
plt.show()后面的文章中咱们将会学习到如何训练一个神经网络。