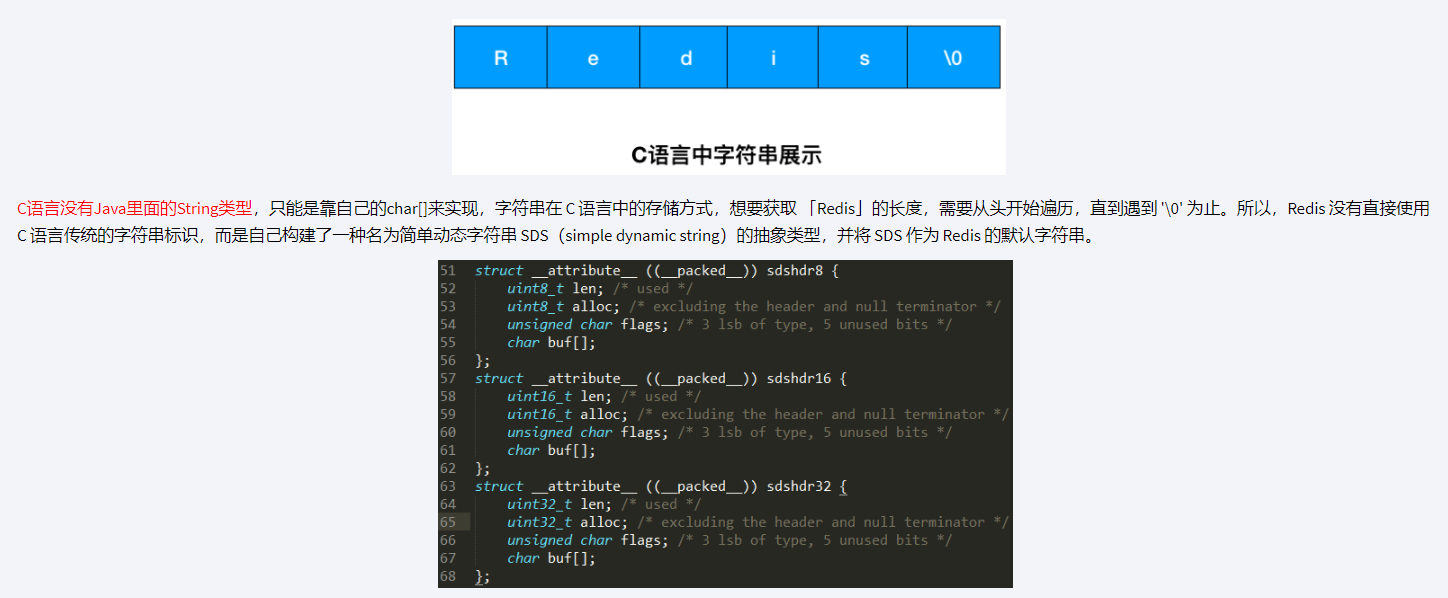
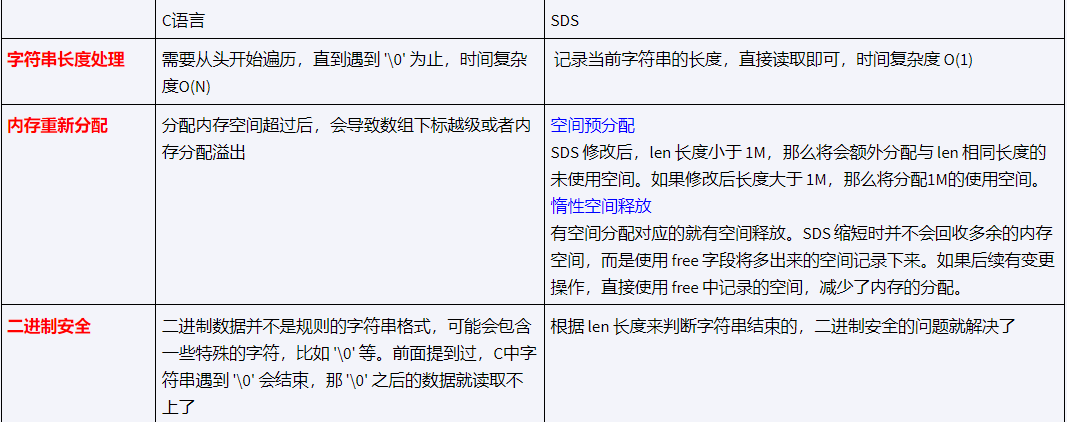
Redis 选择重新设计其 String 类型的底层数据结构,采用 SDS(Simple Dynamic String)而不是直接使用 C 语言标准库提供的原生字符串(char*)的原因主要包括以下几点:
-
O(1) 时间复杂度获取长度:
- 在 C 语言中,获取一个以空字符
\0结尾的字符串长度需要遍历整个字符串直到找到结束符,时间复杂度为 O(N)。 - SDS 在结构体头部显式记录了字符串的长度
len,因此可以直接通过读取这个字段得知字符串长度,无需遍历,时间复杂度降为 O(1)。
- 在 C 语言中,获取一个以空字符
-
空间预分配与惰性释放:
- SDS 在执行修改字符串操作时,会对内存进行预分配策略,预留一定的未使用空间
free,这样当后续有连续的追加操作时,避免了频繁的内存重分配。 - 同时,当字符串缩短时,SDS 不会立即回收内存,而是保持已分配内存,仅减少
len的值,这样可以更快地执行字符串缩短操作,并在未来可能的扩展操作中重复利用这部分空间。
- SDS 在执行修改字符串操作时,会对内存进行预分配策略,预留一定的未使用空间
-
二进制安全:
- C 语言的字符串必须以空字符结束,不支持包含内部
\0字符的二进制数据。 - SDS 支持任意二进制数据存储,因为它不是基于空字符来判断字符串的结束,而是根据长度字段来确定字符串内容。
- C 语言的字符串必须以空字符结束,不支持包含内部
-
防止缓冲区溢出:
- 直接操作 C 字符串容易出现缓冲区溢出的问题,尤其是在拼接和修改字符串时,如果没有正确处理可能会导致安全问题。
- SDS 在执行修改操作时会检查现有空间是否足够,如果不够则会自动进行扩展,确保不会发生溢出。
综上所述,SDS 设计旨在提高 Redis 的性能、安全性及对不同场景的适应能力,尤其对于高并发环境下频繁进行字符串操作的服务端数据库系统来说,这些优化显得尤为重要。