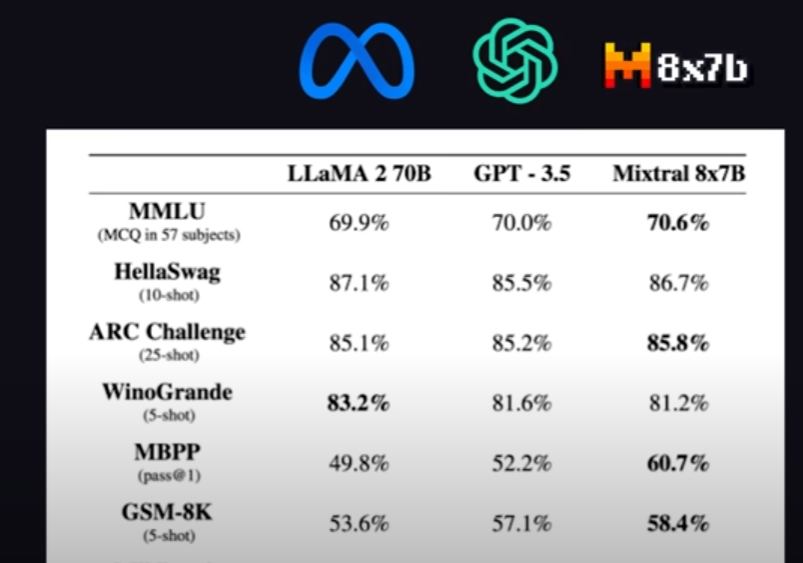
Diffusion Models专栏文章汇总:入门与实战
前言:OpenAI的视频生成模型Sora一经发布就广受全世界的瞩目,上海人工智能实验室最近推出了一个基于Diffusion Transformer的结构的模型Latte,堪称最接近Sora原理的视频生成模型。这篇博客就详细解读Latte,并从中窥探Sora的神秘面纱。
目录
贡献概述
方法详解
backbone
是否预训练模型开始训练?
patch embedding方法:uniform frame patch embedding和compression frame patch embedding
Timestep-class 信息注入方式
Temporal positional embedding
论文和代码
个人感悟

贡献概述
论文提出了一种基于Transformer的视频扩散模型结构Latte。Latte首先从输入视频中提取时空标记,然后采用一系列Transformer块对潜在空间中的视频分布进行建模。为了对从视频中提取的大量标记进行建模,从分解输入视频的空间和时间维度的角度引入了四个有效的变体。作者详细比较了四种有效变体之间的利弊。
方法详解
backbone
latte采用视频transformer作为骨干。Latte 使用预训练的变分自动编码器将输入视频编码到潜在空间中的特征中,其中tokens是从编码特征中提取的。然后应用一系列 Transformer 块来编码这些tokens。
最主要的backbone,作者探索了如下图所示的四种方法:

1. 变体1:这个变体的Transformer骨干由两种不同类型的Transformer块组成:空间Transformer块和时间Transformer块。空间Transformer块专注于捕捉具有相同时间索引的token之间的空间信息,而时间Transformer块则采用“交错融合”的方式在时间维度上捕捉信息。
2. 变体2:与变体1中的“交错融合”设计不同,变体2采用了“后期融合”方法来结合时空信息。这个变体同样包含与变体1相同数量的Transformer块,输入形状与变体1相似,但在融合时空信息的方式上有所不同。
3. 变体3:专注于分解Transformer块中的多头注意力(multi-head attention)。这个变体首先在空间维度上计算自注意力,然后是时间维度,从而使得每个Transformer块都能捕捉到时空信息。
结论:变体 1 随着迭代次数的增加表现最好;变体4由于计算效率较高,尽管性能稍逊,但在资源受限的情况下可能是一个不错的选择。详见下表:

是否预训练模型开始训练?
大多数的视频生成模型都是从图片生成模型当中初始化开始学习的。
作者研究了两种学习策略:使用预训练模型(ImageNet预训练)和图像-视频联合训练(image-video joint training)。使用预训练模型可以利用ImageNet上学习到的图像生成知识,而图像-视频联合训练则通过在每个视频样本后附加随机选择的视频帧来提高模型的多样性和性能。
使用在ImageNet上预训练的模型作为初始权重可以帮助视频生成模型更快地学习,但随着训练的进行,模型可能会遇到适应特定视频数据集分布的挑战。这可能导致性能在达到一定水平后趋于稳定,不再显著提高。
patch embedding方法:uniform frame patch embedding和compression frame patch embedding

作者探索了两种视频片段嵌入方法:均匀帧补丁嵌入(uniform frame patch embedding)和压缩帧补丁嵌入(compression frame patch embedding)。
- 均匀帧补丁嵌入是将每个视频帧单独嵌入到token中,类似于ViT(Vision Transformer)的方法。
- 压缩帧补丁嵌入考虑捕获时间信息,然后将 ViT patch 嵌入方法从 2D 扩展到 3D,随后沿着时间维度提取,通过按一定步长提取时间序列中的“管状”结构,然后映射到token。
结论:均匀帧补丁嵌入在某些情况下表现更好,因为它可能更好地保留了视频的时空信息。使用压缩帧补丁嵌入方法会导致时空信号的丢失,这使得Transformer主干很难学习视频的分布。
Timestep-class 信息注入方式
-
S-AdaLN架构:S-AdaLN(Scalable Adaptive Layer Normalization)架构是一种特殊的自适应层归一化方法。它通过线性回归计算两个参数γc(缩放因子)和βc(偏移量),然后将这些参数应用到Transformer块的隐藏嵌入上。这样做的目的是为了适应性地编码时间步长或类别信息,从而使模型能够更好地理解和处理这些信息。
-
Vanilla Transformer块:在图(a)和(b)中使用的是标准的Transformer块(通常称为vanilla transformer blocks),这些块包含多层感知机(MLP)和多头注意力(MHA)。多层感知机是一种简单的神经网络结构,用于非线性变换和特征学习;而多头注意力机制则允许模型在不同的表示子空间中并行地学习输入之间的关系。
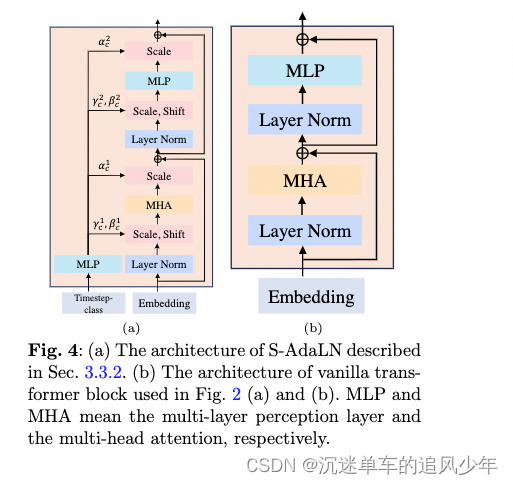
结论:S-AdaLN方法更有效。
Temporal positional embedding
为了让模型能够理解时间信号,作者探索了两种时间位置嵌入方法。绝对位置编码使用不同频率的正弦和余弦函数来为每个时间步长生成唯一的位置编码。相对位置编码则使用旋转位置编码(RoPE),这是一种更高级的位置编码方法,能够捕捉连续帧之间的相对时间关系,从而提供更丰富的时间动态信息。
结论:绝对位置编码在某些情况下能提供稍微更好的结果。
论文和代码

Latte: Latent Diffusion Transformer for Video Generation
个人感悟
1、说实话从DiT发布很久很久了,图像领域用的比较早,视频领域的DiT探索比较晚,相信Sora带来的这股热浪能够很快将DiT带火的。
2、看论文的排版,应该是投了eccv 2024。实验是真的扎实,给ailab长脸了。
3、最近有open sora的工作,结合latte更有启发性,之后会专门出博客进行讲解。
4、目前latte这个工作只是处于学术阶段,只能小数据集上验证有效性,如果不是sora爆火,可能也不会得到这么多的关注。