1、如何跳过对某行数据的处理
第一行数据是字段名不需要处理,我们知道第一行偏移量是0(行记录的时候是从数组首地址开始,到了行标识符进行一次计数,这个计数就是行偏移量,从0开始),我们根据偏移量值进行判断,然后用中断方法把第一行数据跳过。
// 根据偏移量把第一行筛选出来:
if (0== key.get()){
return; // 中断方法:即不对符合条件的数据进行处理,也就是跳过这些数据不做处理
}2、接下来是对需求数据的Map处理
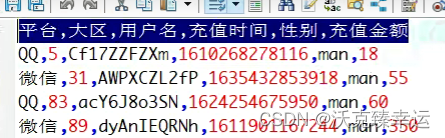
String[] line = value.toString().replaceAll("\"","").split(",");
//对可能数组越界的字符串数据过滤:用判断把长度不符合的数组剔除
if (11== line.length){
//对符合要求的数据开始写出:格式---K:省市年月日(拼接),V:温度
StringBuilder outKey = new StringBuilder();
outKey.append(line[1]).append(line[2])
.append(DateTimeFormatter.ofPattern("yyyyMMdd")
.format(LocalDateTime.parse(line[9], DateTimeFormatter.ofPattern("d/M/yyyy HH:mm:ss"))));
context.write(new Text(outKey.toString()),new IntWritable(Integer.parseInt(line[5])));
}3、接下来是reduce处理逻辑
根据业务需求写出数据
package com.yjxxt.Weather;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Reducer中四个泛型解释
* KEYIN: MapTask写出数据的key:地区年月日
* VALUEIN:MapTask写出数据的value 温度(N条,因为记录了每天不同时刻的温度)
* KEYOUT: Reducetask写出数据的key 地区年月日
* VALUEOUT: Reducetask写出数据的value 温度最值
*/
public class WeatherReducer extends Reducer <Text, IntWritable, Text, Text>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//这里的VALUEOUT是要最高温和最低温,所以reduce要把拉取过来的温度进行比较(从map-->reduce:数据是1:N模型)
int max=-100,min=100;
//用比较函数找到最值
for (IntWritable value:values
) {
max = Math.max(max, value.get());
min = Math.min(max, value.get());
}
//将最终结果写出去:VALUEOUT也写成文本形式
context.write(key,new Text("最高温度["+max+"]最低温度["+min+"]"));
}
}

![【算法每日一练]-图论(保姆级教程篇16 树的重心 树的直径)#树的直径 #会议 #医院设置](https://img-blog.csdnimg.cn/direct/dd26216a69da4870b7a448e1cf498036.png)