M函数
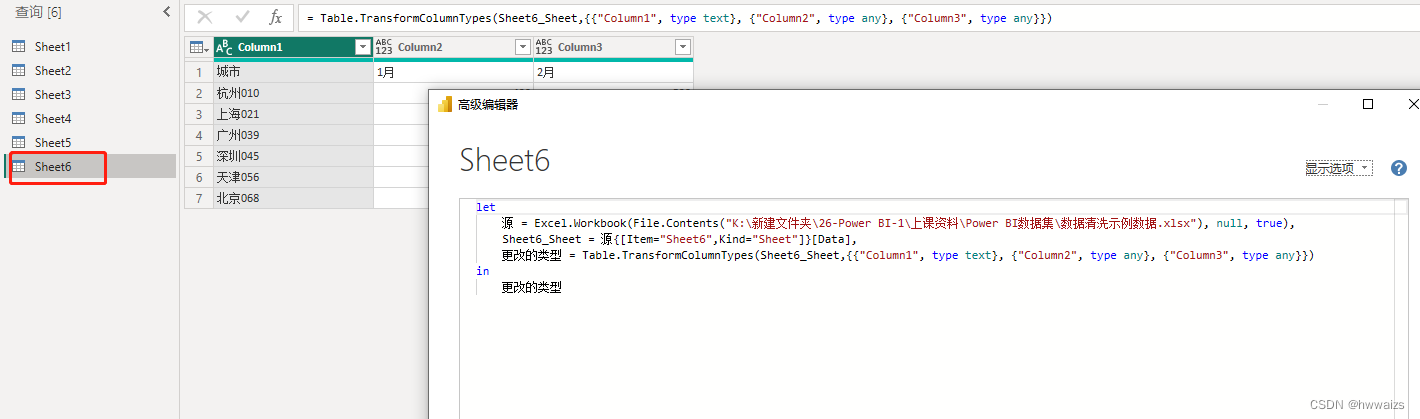
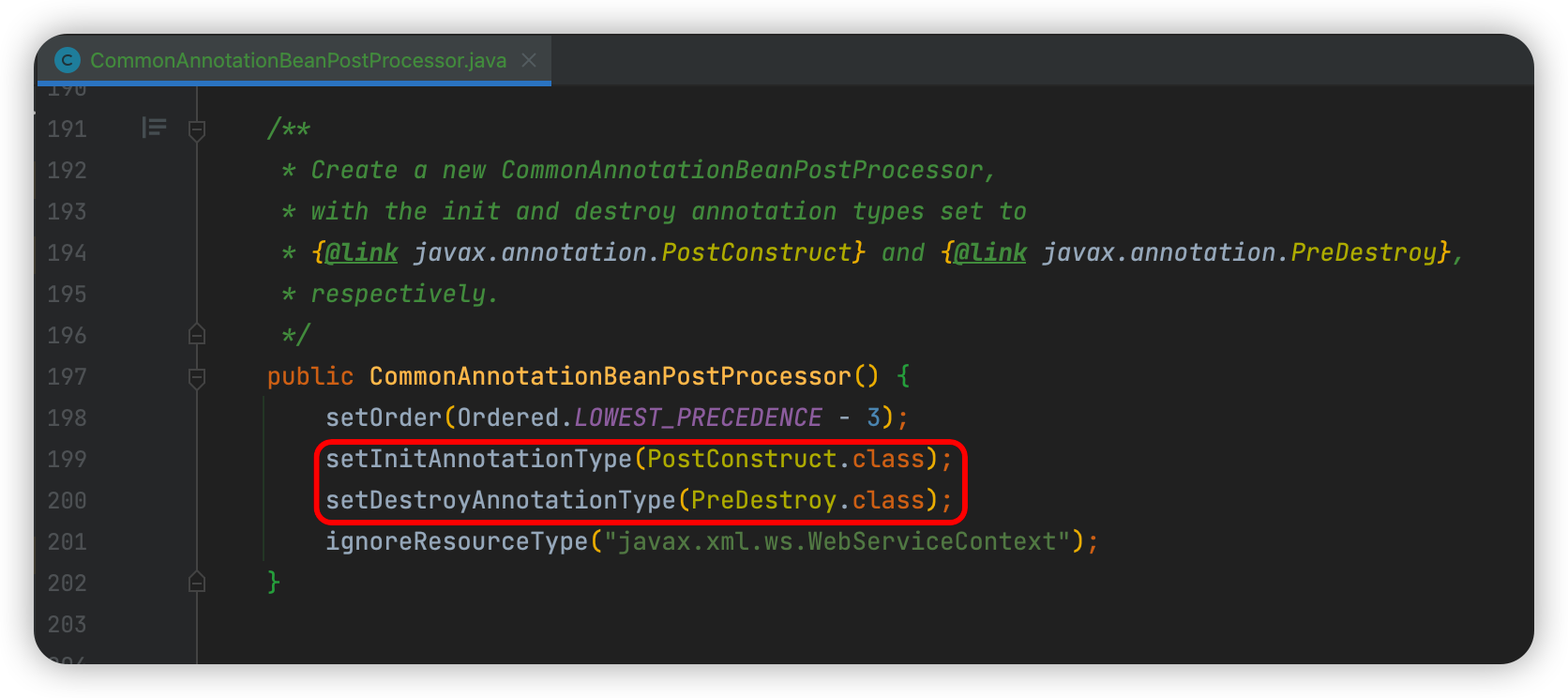
用鼠标操作的步骤背后的逻辑都是M函数,在编辑器里都会有体现出来,选中左侧的表名称,点击右键,选择高级编辑器,就会进入到高级编辑器界面,里面会显示每一步的操作步骤。
M函数基本规范
- M函数对大小写敏感,每一个字母必须按函数规范书写,第一个字母都是大写
- 表被称为Table,每行的内容是一个Record,每列的内容是一个List
- 行标用大括号{ },比如取第一行的内容:=表{0} //PQ的第一行从0开始
- 列标用中括号[ ],比如取自定义列的内容:=表[自定义]
- 取第一行自定义列的内容:=表{0}[自定义],使用的时候必须遵循规范。DataFrame对象的取值是先列后行。
常用的M函数:
点击主页–新建查询–新建源,点击空查询进入到查询语句界面,输入查询语句 =#shared ,回车后就会显示常见的M函数,单击某个函数,就会弹出示例,输入参数进行简单的调用。
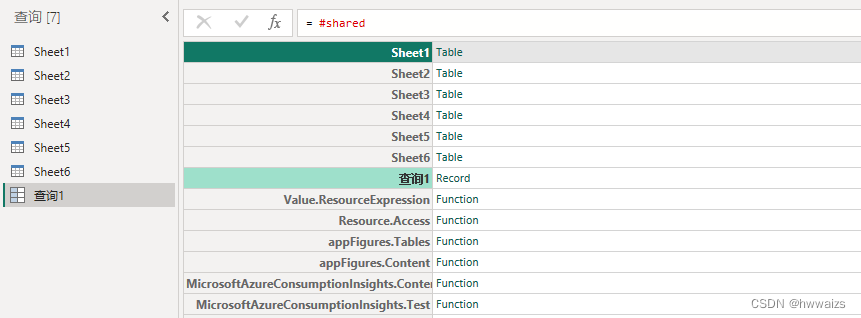
● 聚合函数
○ 求和:List.Sum()
○ 求最小值:List.Min()
○ 求最大值:List.Max()
○ 求平均值:List.Average()
● 文本函数
○ 取文本长度:Text.Length()
○ 取文本空格:Text.Trim()
○ 取前n个字符:Text.Start(文本,n)
○ 取后n个字符:Text.End(文本,n)
● 提取数据函数
○ 从Excel表中提取数据:Excel.Workbook()
○ 从Csv/Txt中提取数据:Csv.Document()
● 条件函数
○ if else then
数据建模
数据建模使用的语言为DAX函数。PowerBI 的数据建模是利用Excel的Power pivot插件,已经内嵌到PowerBI 的桌面版中,两者的功能基本相同,透视表只能从单个表中取出数据。若要把其他表中的数据也放进来就要用到VLOOKUP函数,把其他的表合并进来,再把字段放到透视表中,这些在Excel中都可以实现。如果设计的数据量比较大,数据维度很多的话,Excel就不能满足需求,而PowerBI可以从多个表格、多种来源的数据中根据不同的数据维度,不同的逻辑来整合、聚合数据。
数据建模基础
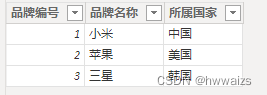
加载数据建模示例文件,产品明细表中显示的电子产品的专卖店销售的产品为手机、电脑、平板,每一类又来自三种不同的品牌。不同的产品不同的类别,共有9个产品。销售明细表记录的是产品每一天的销售数据,类别表中的产品类别、品牌表中的品牌名称分别跟产品明细表中的类别和品牌是相互对应的,产品明细表中的产品编号和销售明细表中的商品编号进行对应。
- 产品明细表
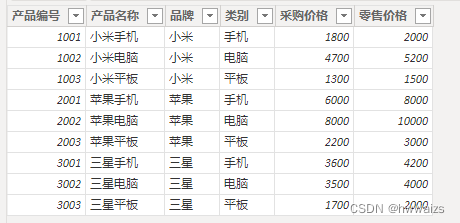
- 类别表
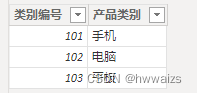
- 品牌表
- 销售明细表
可以在左侧的模型中建立关系,如果两个表的字段名称,字段内容都一样的话,会自动创建关系,如产品明细表和销售明细表的产品名称会自动创建关系,用线进行了连接。双击关系连接线,会弹出编辑关系的对话框,建立数据模型。
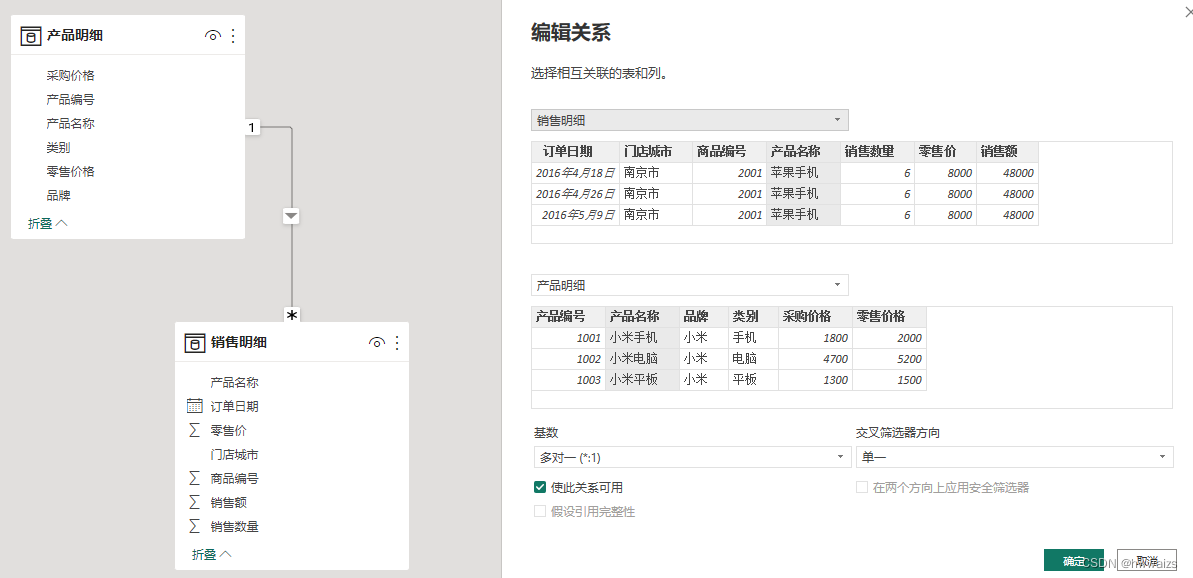
依次将类别表中的产品类别和产品明细表中的类别、品牌表中的品牌名称和产品明细表中的品牌依次建立联系。
基数:两个连接字段的对应关系,其实为两个表的字段建立关联。
学生表 (学生id 学生姓名)
课程表 (课程id 课程名)
成绩表 (学生id 课程id 分数)
班级表 (班级id 学生id)
● 多对一
一个班级包含了很多学生
● 一对多
很多学生都在一个班级
● 多对多
一门课对应多个学生选择 一个学生也可以有多个课程可以选,学生表和课程表之间的关系。
● 一对一
一门课程应该对应一个分数,成绩表和课程表之间的关系。
交叉筛选方向:表示数据筛选方向
● 单向:一个表只能对另一个表筛选,而不能反向
● 双向:两个表可以互相筛选
度量值
度量值用于一些最常见的数据分析。 简单汇总(如总和、平均值、最小值、最大值和计数)可以通过“字段”选项进行设置。 度量值的计算结果也始终随着你与的报表的交互而改变,以便进行快速和动态的临时数据浏览。度量值不是一列,与增加列很相似,是放在虚拟内存中的值,值会随着筛选的数据进行更改 。
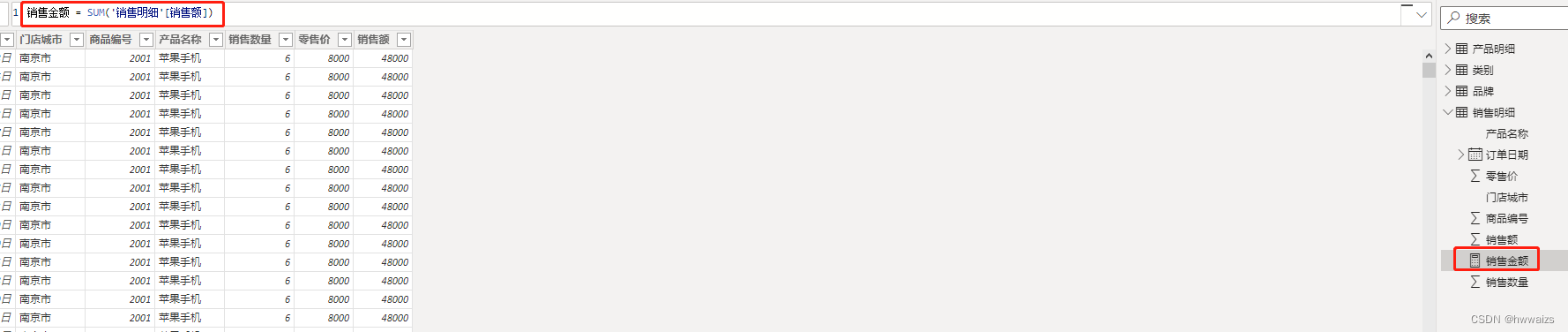
根据建立的数据模型来做数据分析,统计各个品牌的销售额。销售额无法通过单一的一张表得到,在销售明细表中点右键,选择增加度量值,名称为销售金额,内容为 =SUM(‘销售明细’[销售额]),在右侧的字段里,会出现销售金额的字段名,图表跟正常的字段名不一样。
这时销售金额在表中看不到数据,可以切换到报表界面,可视化生成视觉对象中选择卡片图,把字段中的销售金额添加到可视化对象中的字段中,显示销售金额的值。

销售金额为销售列累计求和的值,不算是单独的一列,对原数据没有影响,只是一个度量值,是虚拟汇总的结果,一直在内存当中可以快速和动态的进行修改的临时数据,如果不保存的话,软件关闭,度量值就会消失。有时候要求人均的消费金额,平均金额等,但是又不想去新增加一列数据,就可以以新建度量值的方式进行简单的数据汇总,便于我们在画布中看到汇总的数据信息。
在报表界面新增切片器,把品牌表中的品牌名称放到切片器的字段里,不进行选择的时候,显示为总的销售金额,选中某一个框就显示某一个品牌的销售金额。
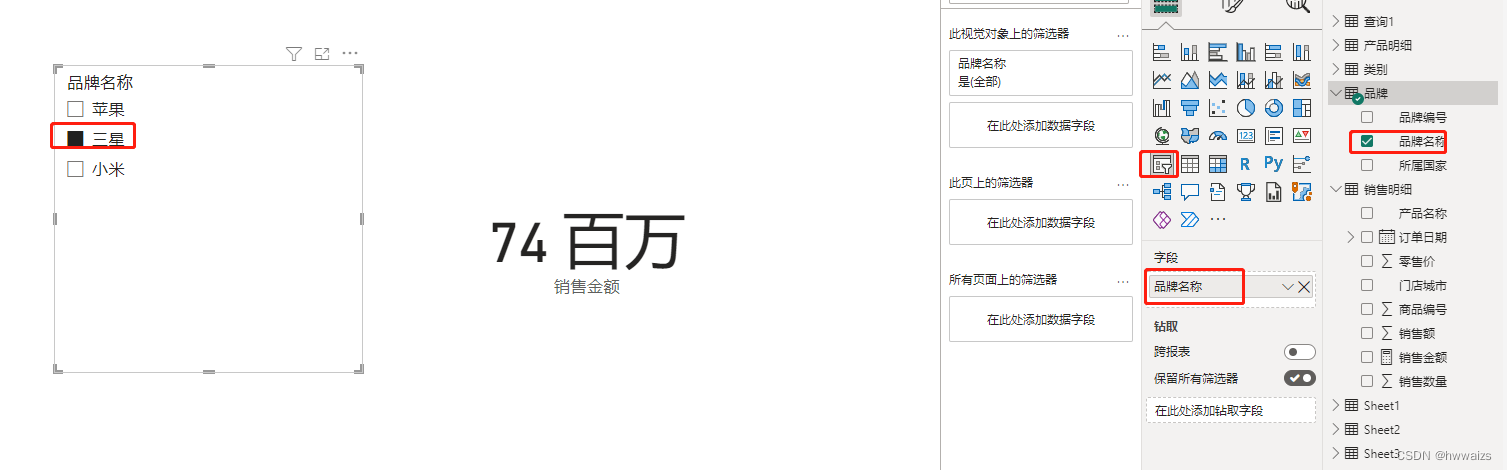
度量值会跟随报表的交互而改变得到的结果。
度量值是通过大量的公式来建立的虚拟字段的数据值,不会影响到原数据,也不会改变数据建模。把它放到报表上进行交互的时候就会体现它巨大的功能,也可以跟随切片器进行变化,度量值可以根据DAX函数来创建的,也被称为移动的公式。
销售总金额,日期数据里有层级结构的,可以在日期数据中选择年,月份的数据,这里的月份指的是每一年1月份的销售总额,可以新建一个切片器进行筛选。
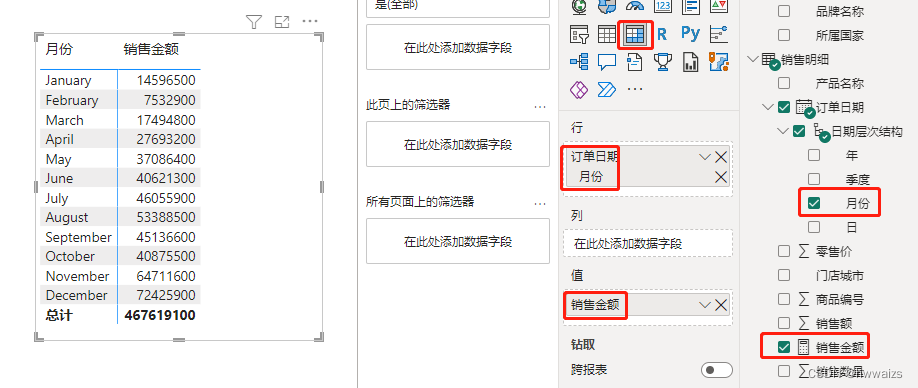
也可以选择日期层次结构进行依次展开,分别显示获取的数据。
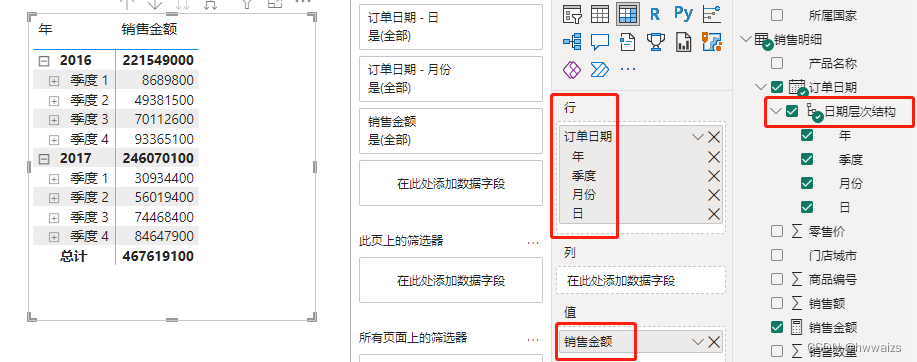
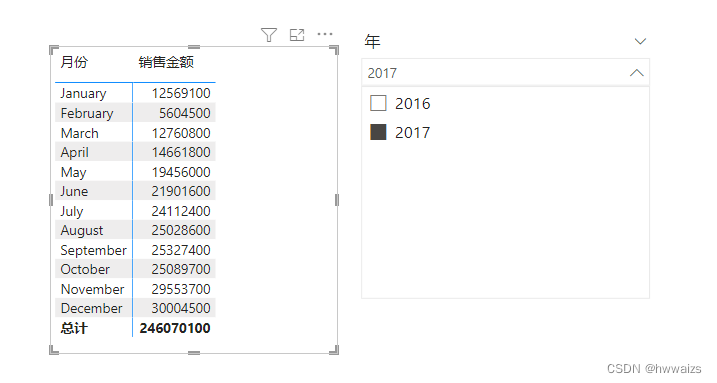
增加门店城市和日期表,建立关系如下图所示:
新建度量值是在表中建立的,后期建立的度量值比较多的话,需要一个表一个表的展开,不容易查找,可以新建一张表,所有的度量值都放到这张表里,便于管理。
在主页选项卡下,计算选项组中,新建表选项,新建一张表,表名为度量值,在度量值表处点右键,新建度量值,输入 销售总额 = SUM(‘销售明细’[销售额]) ,输入回车;依次创建本年和上一年的销售额,本年累计销售额 = TOTALYTD([销售总额],‘日期表’[日期]);上年累计销售额 = TOTALYTD([销售总额],SAMEPERIODLASTYEAR(‘日期表’[日期]))。TOTALYTD指的是从年初到本月的金额,实现的是累加,SAMEPERIODLASTYEAR返回的是上一年同期的日期表,
新建度量值 累计同比增长率 = DIVIDE([本年累计销售额],[上年累计销售额])-1
把上述新建的度量值放到矩阵里,就可以得到累计的销售同比增长率,增加年度、门店城市、品牌名称切片器可以更加精准的分析。
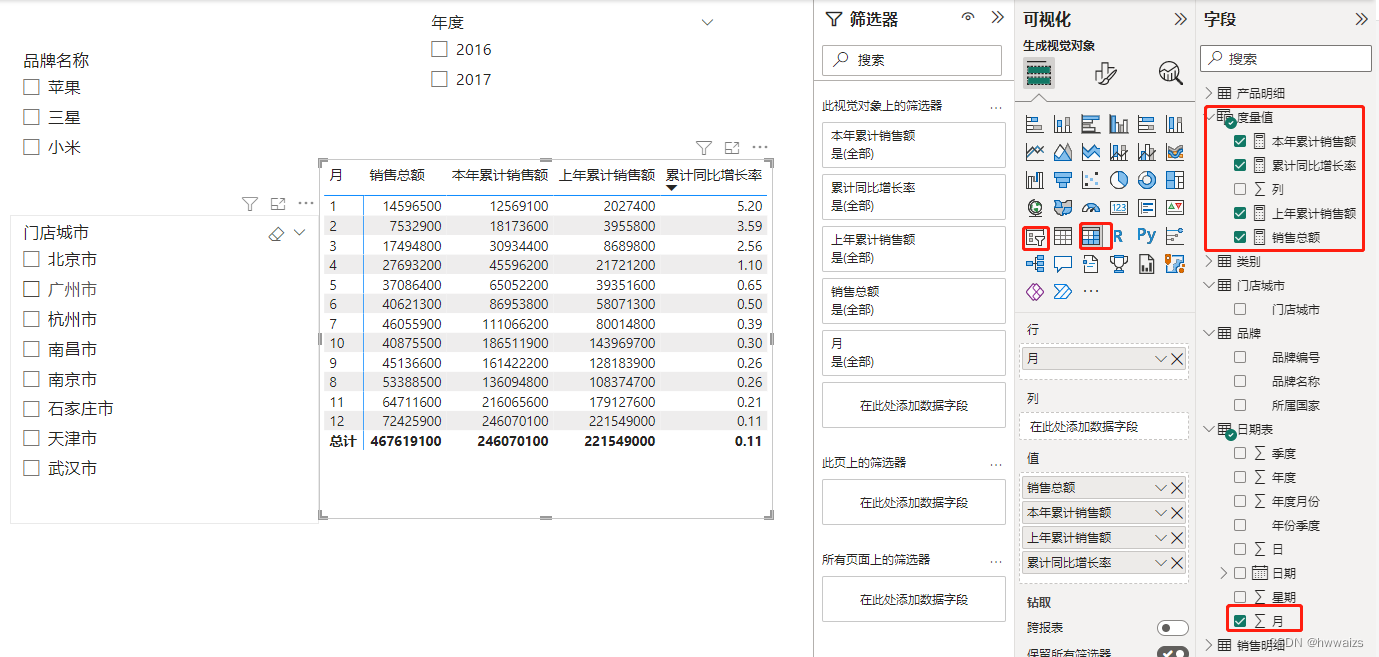
通过创建的4个度量值来实现了多种维度数据的比较,利用上下文的内容进行筛选,上下文指的是度量值所处的环境。北京2017年截止5月的苹果手机累计销售额,上下文数据指的是北京市、苹果品牌、手机、年度为2017、月份为5月份这五个维度。上下文环境不同,所展示的数据也不一样。度量值不会浪费内存,只有被拖拽到图表上才会执行运算,度量值可以循环使用。
DAX
DAX指的是数据分析表达式,从数据分析的层次上认识公式。数据分析从茫茫的数据中提取有用的信息,执行一定的运算并得出结论的过程。DAX的主要功能也是查询和运算,负责筛选出来有用的数据集合,再利用聚合函数执行的计算。度量值的计算依赖于上下文,上下文又分为外部上下文(可以看的见的筛选条件,标签、切片器等)和内部上下文(创建度量值的公式),查询、筛选函数可以扩大、限制、重置等。度量值是PowerBI建模的灵魂,DAX是度量值使用的灵魂。数据建模重要的是度量值,度量值重要的是DAX公式。它的使用范围可以在Power BI 的数据建模,除了创建度量值,也可以新建列。
在日期表中增加列,选择表工具选项卡下计算选项组中的 新建列,输入 月份 = FORMAT(‘日期表’[日期],“MM”),这里引用的表用单引号,引用的列用方括号,引用字符串用双引号,两个M表示两位数。

但是不建议在此处增加列,可以在转换数据,Power Query界面增加列。
DAX 参数的基本格式
● 表名用单引号’ ',如 ‘日期表’
● 字段用中括号[ ],如[日期]
● 度量值也是用中括号[ ]
● 引用字段始终要包含表名,用以和度量值(前没有表名称)区分开
聚合函数
这几个函数的使用跟Excel中一样。
● SUM
● AVERAGE
● MIN
● MAX
这几个函数可以循环访问表的每一行,并执行计算,迭代函数
● SUMX
● AVERAGEX
● MINX
● MAXX
● RANGX
其他聚合函数
● COUNT: 计数
● COUNTROWS: 计算行数
● DISTINCTCOUNT: 计算不重复值的个数
时间函数
● PREVIOUSYEAR/Q/M/D:上一年/季/月/日
● NEXTYEAR/Q/M/D:下一年/季/月/日
● TOTALYTD/QTD/MTD:年/季/月初至今
● SAMEPERIODLASTYEAR:上年同期
● PARALLELPERIOD:上一期
● DATESINPERIOD:指定期间的日期
筛选函数
● FILTER:筛选
● ALL:所有值,可以清除筛选
● ALLEXCEPT:保留指定列
● VALUES:返回不重复值
常用的DAX函数
CALCULATE函数
语法:
CALCULATE(<expression>,<filter1>,<filter2>…)
■ 第一个参数是计算表达式,可以执行各种聚合运算
■ 从第二个参数开始,是一系列筛选条件,可以为空;如果多个筛选条件,用逗号分隔
■ 所有晒选条件的交集形成最终的筛选数据集合
■ 根据筛选出的数据集合执行第一个参数的聚合运算并返回运算结果
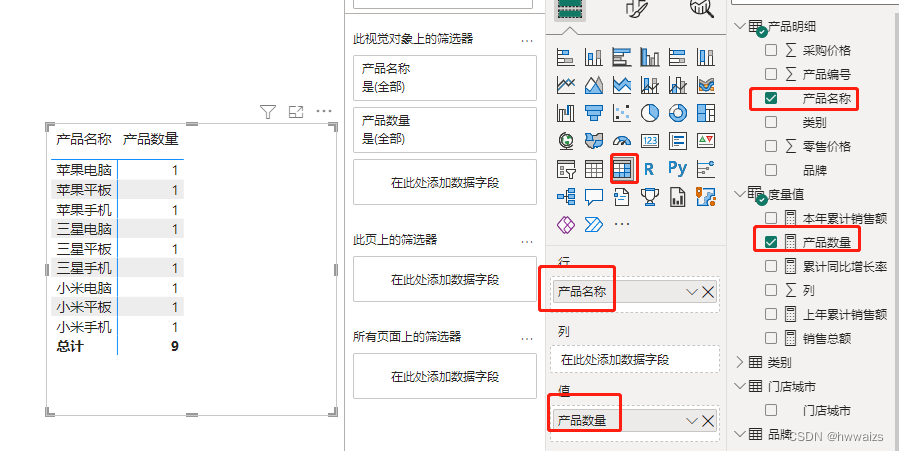
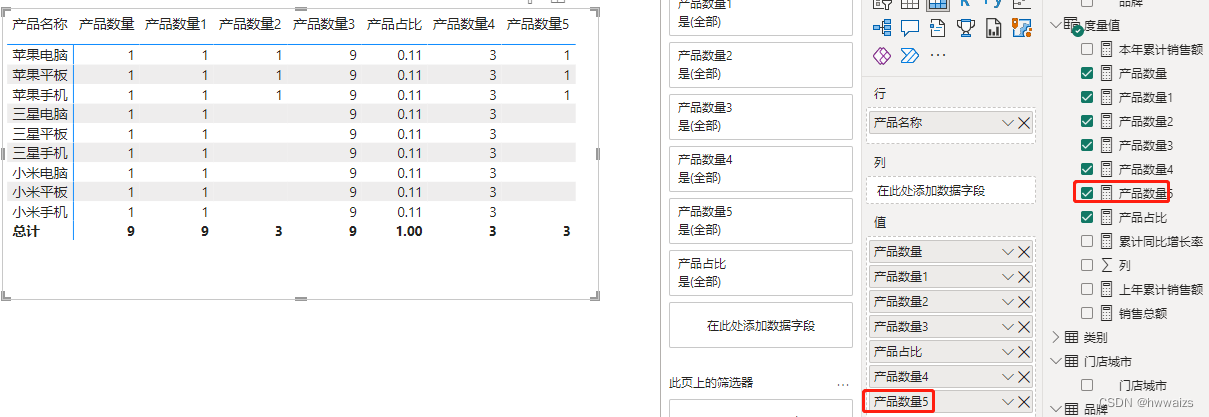
求每一种产品的数量。
新建度量值,产品数量 = COUNTROWS(‘产品明细’) 。
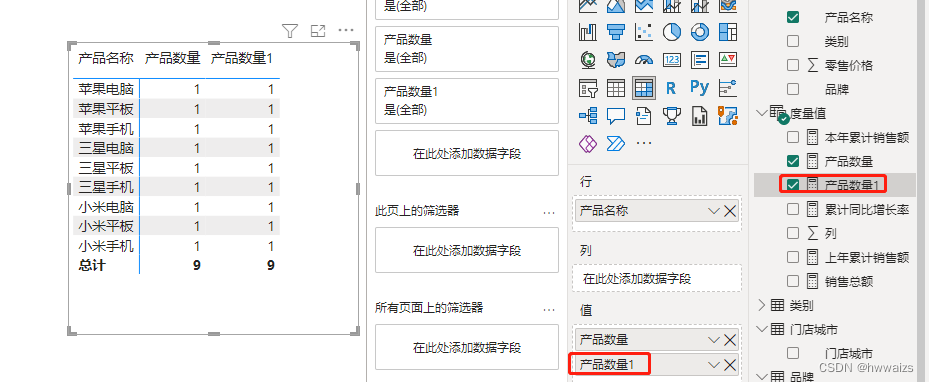
使用CALCULATE函数创建度量值,产品数量1 = CALCULATE([产品数量])。在这里 [产品数量] 等效于 COUNTROWS(‘产品明细’)
求苹果的品牌有几种。
新建度量值, 产品数量2 = CALCULATE([产品数量],‘产品明细’[品牌]=“苹果”),只筛选品牌为苹果的产品,限制了外部的上下文,只计算筛选内容数据的计算。
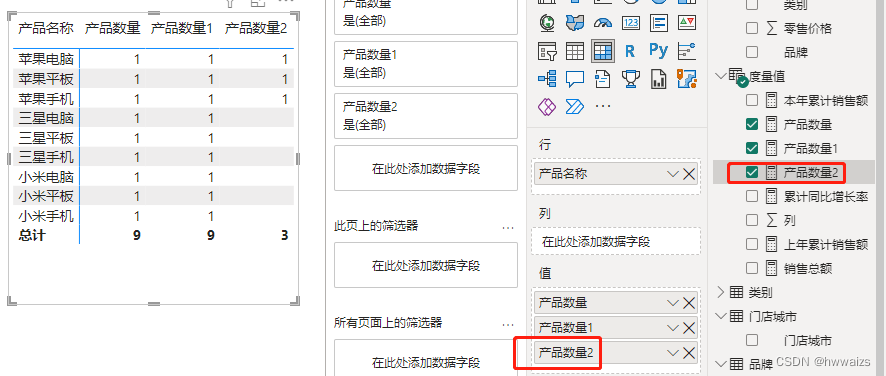
新建度量值,产品数量3 = CALCULATE([产品数量],ALL(‘产品明细’)),筛选条件选择的是ALL函数,清除产品明细表中所有的筛选,显示的9为所有产品的数量,增加切片器,不会影响统计结果的变化。
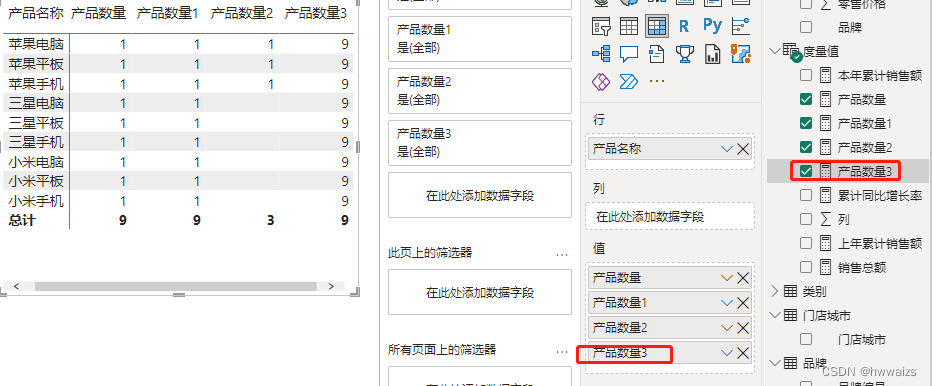
计算每种数量占总产品数量的比重。
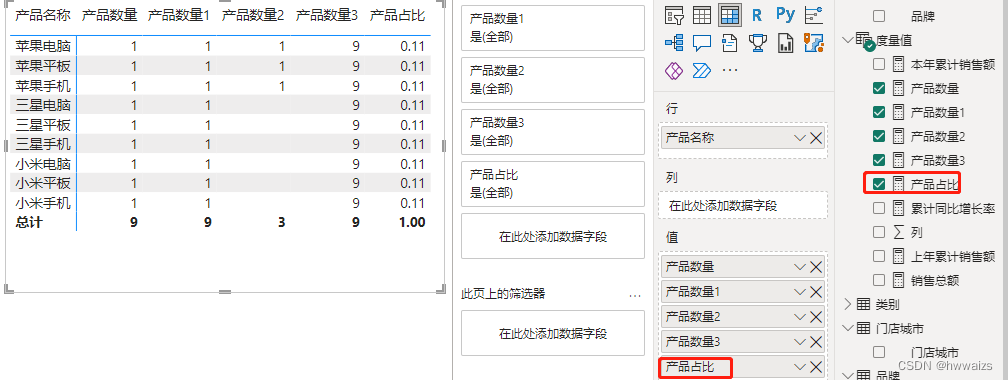
新建度量值,产品占比 = [产品数量]/[产品数量3],产品数量3 不会受外部数量的影响,好比除的是固定的值 一样。
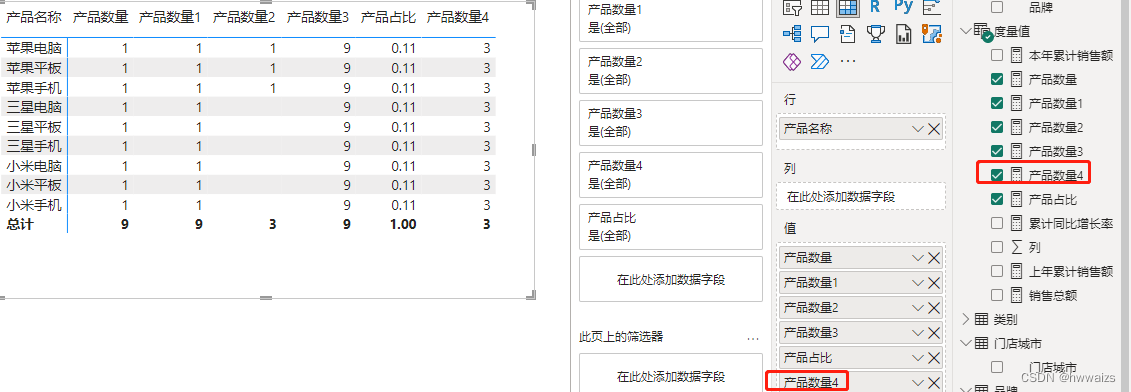
新建度量值,产品数量4 = CALCULATE([产品数量],ALL(‘产品明细’[产品名称]),‘产品明细’[类别]=“手机”)。先用ALL清除了外部的上下文筛选的影响因素,增加筛选条件查询类别为手机的产品数量,从所有产品中统计了类别为手机的产品的数量,每行的结果返回都是3。
FILTER函数
主要是用于筛选,语法
FILTER(<table>,<filter>)
■ 第一个参数<table>是要筛选的表
■ 第二个参数<filter>是筛选条件
■ 返回的是一张表,不能单独使用,需要与其他函数结合使用
比较简单的筛选就没必要用FILTER函数。
新建度量值,产品数量5 = CALCULATE([产品数量],FILTER(ALL(‘产品明细’[品牌]),‘产品明细’[品牌]=“苹果”)),筛选的结果和产品数量2一样。
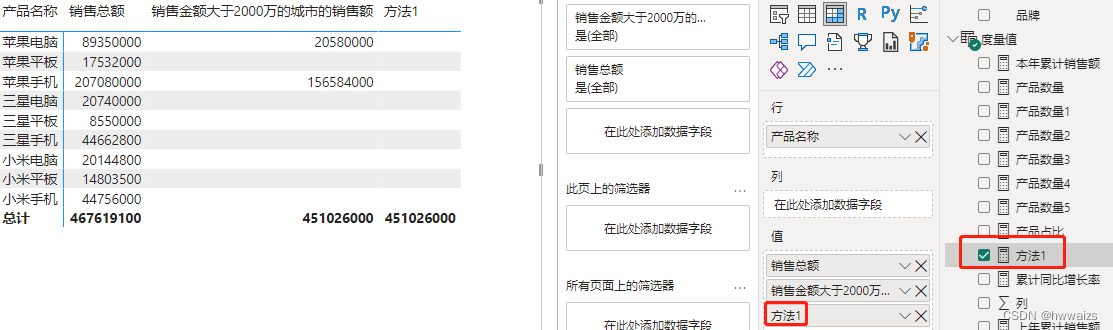
找出销售额超过2000万的城市的销售金额。新建度量值,销售金额大于2000万的城市的销售额 = CALCULATE([销售总额],FILTER(ALL(‘门店城市’),[销售总额]>20000000))。

HASONEVALUE
HASONEVALUE(<columnName>),返回值为True或者False
- 参数只有一个,为列名;
- 作用:判断外部上下文中是否为该列中的唯一值,做切片器交互时十分有用。
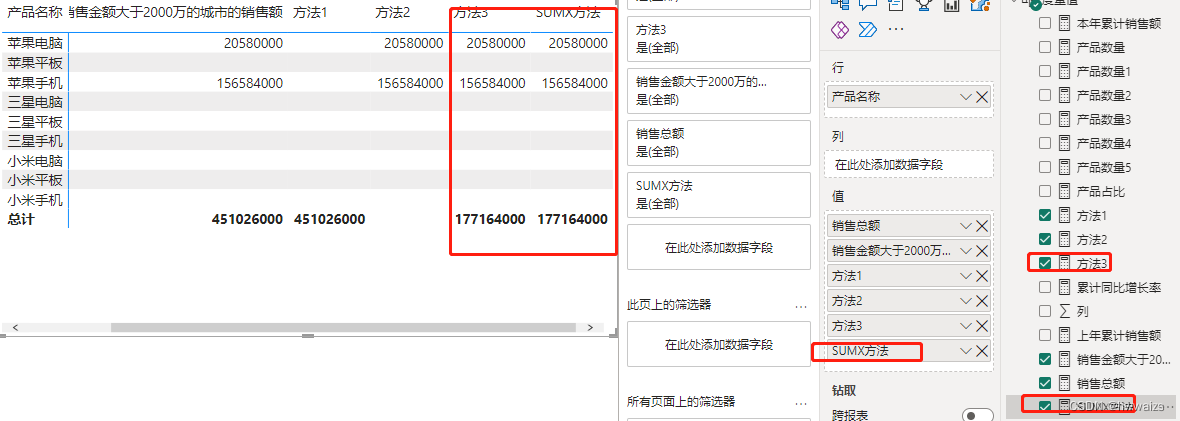
不显示明细项的值。新建度量值,方法1 = IF(HASONEVALUE(‘产品明细’[产品名称]),BLANK(),[销售金额大于2000万的城市的销售额]),实现的效果不显示当前的细分项,只显示最后的总结果值。
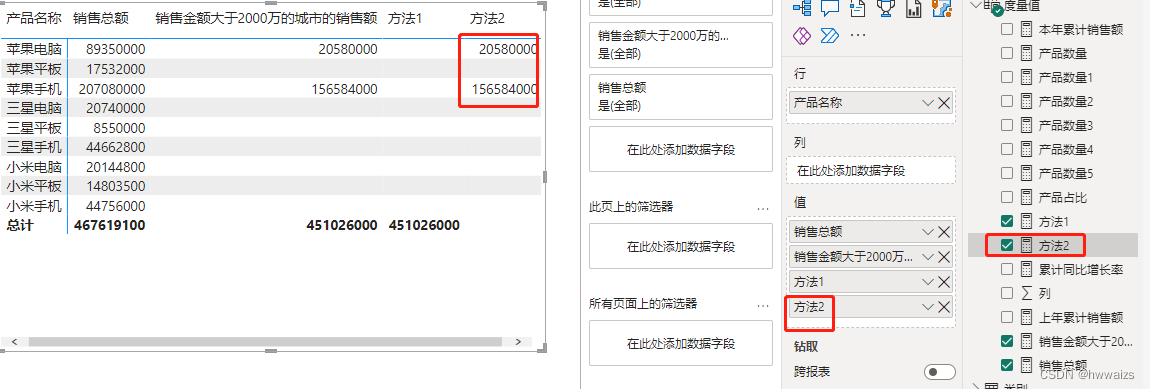
不显示总计值,只显示明细项的内容。方法2 = IF(HASONEVALUE(‘产品明细’[产品名称]),[销售金额大于2000万的城市的销售额],BLANK()),实现的效果是只显示当前的明细项,不显示总计的结果。
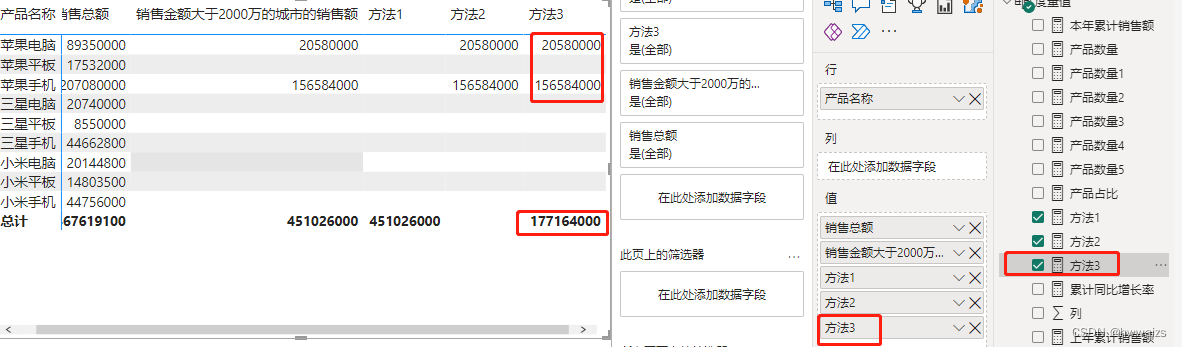
SUMX 函数
SUMX(<table>,<expression>),总计项为各明细项之和。该函数为迭代函数,可以对表进行逐行的运算。
- 第一个参数为被运算的表 table
- 第二个参数是对表中的每一行计算的表达式
新建度量值,方法3 = SUMX(‘产品明细’,[销售金额大于2000万的城市的销售额]),实现的功能是总计项为各个明细项目的和。
SUMX函数可以代替CALCULATE函数,来实现方法3的效果。新建度量值,SUMX方法 = SUMX(‘产品明细’,SUMX(FILTER(ALL(‘销售明细’[门店城市]),[销售总额]>20000000),[销售总额])),实现的效果和方法3类似,没有用到之前“”“大于2000万的城市的销售额”的度量值,但是对内存的消耗比较大。在实际分析中遇到相似的情况可以根据具体的逻辑关系和展现出来的需求来选择不同的方式来进行处理。
EARLIER函数
之前使用Power BI 进行数据分析的时候都是对整列字段进行的操作,并没有做更细分的分析,如果要分析数据的每一行,提取每一行的数据,在Excel中是比较容易实现的,Excel是对单元格的操作,也可以借助EARLIER函数来实现。
EARLIER(<column>,<number>)
- 第一个参数是列名称
- 第二个参数一般可以省略
- EARLIER函数提取本行对应的该列的值,实际上就是提取本行和参数列交叉的单元格
该函数是指定上下文重要的工具。
导入订单表,点击主页,查询选项组中转换数据,进入Power Query界面,选择添加列选项卡下常规选项组中的索引列,选择从1开始的,更改名称为序号。选择主页,关闭并应用。
求两个订单的时间间隔,从下一个订单的日期减去当前订单的日期,为了计算方便,新建列提取出来下一个订单日期,下一个订单日期 = SUMX(FILTER(‘订单表’,‘订单表’[序号]=EARLIER(‘订单表’[序号])+1),‘订单表’[订单日期]),查询的是订单表,查询的内容是订单表的序号,用EARLIER函数获取当前行的序号。再新建一列,把这两列用于相减得到的相隔天数,间隔 = IF([下一个订单日期]=BLANK(),BLANK(),[下一个订单日期]-[订单日期]),然后把间隔列的数据类型改为整数,就得到了两个订单之间的间隔日期。最后一行有空值,没有下一个日期,为了避免出现不合理的数值,用IF 进行了判断。
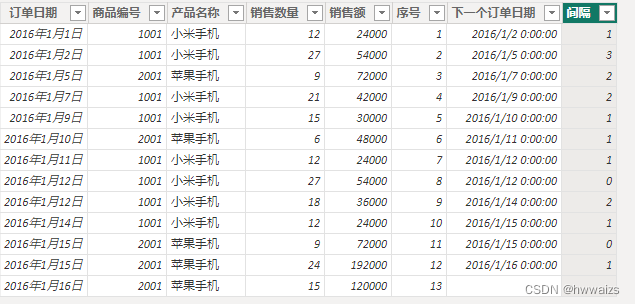
求每个订单日期的累计销售金额。第二天的累计金额为第二天加上第一天的金额。新建列,累计销售额 = SUMX(FILTER(‘订单表’,‘订单表’[序号]<= EARLIER(‘订单表’[序号])),‘订单表’[销售额]),用EARLIER函数求当前行的序号,再把小于等于当前行的所有行进行累加。
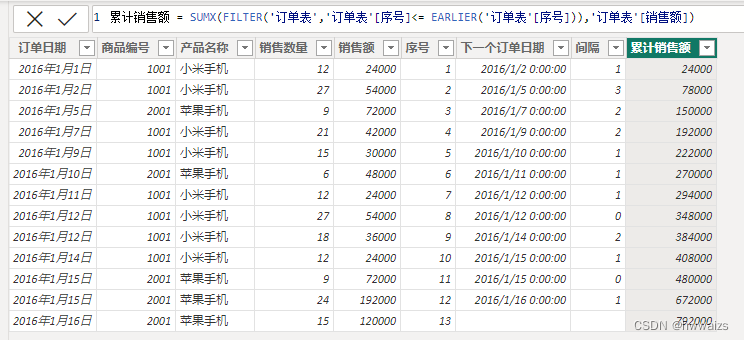
求截止目前订单每种产品的销量。新建列,产品累计销量 = SUMX(FILTER(‘订单表’,‘订单表’[序号]<= EARLIER(‘订单表’[序号]) && ‘订单表’[产品名称]=EARLIER(‘订单表’[产品名称])),‘订单表’[销售数量]),不仅可以用EARLIER函数筛选小于当前行的序号,还可以利用它求得当前行的产品名称,同时符合两个条件的销量进行累加,得到最终的结果。先获取本行的记录,然后再做各种聚合运算,本行的记录可以称为行的上下文,EARLIER正是获取上下文的函数之一。
![sqlserver连接时报错 [IM002] [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序](https://img-blog.csdnimg.cn/b7531b45aed64f3db1bc0ba11f1ac354.png)