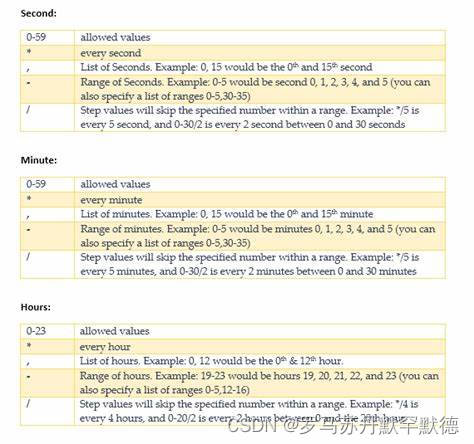
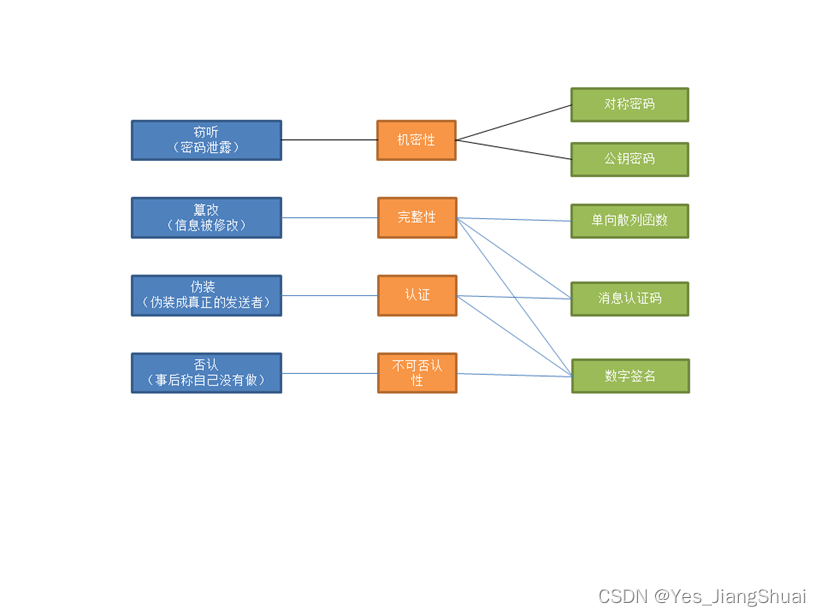
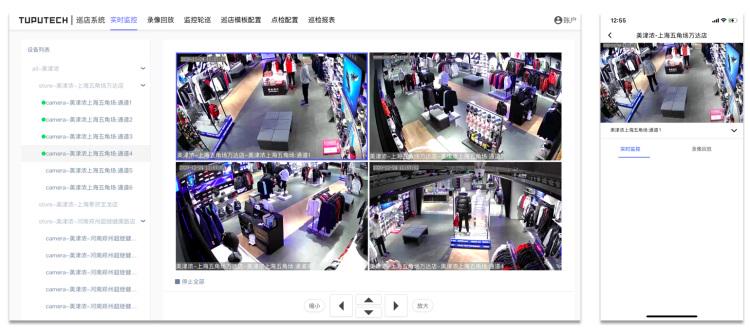
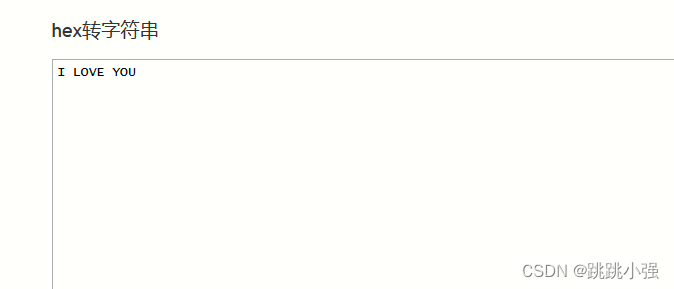An Image is Worth 16x16 Words Transformers for Image Recognition at Scale
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZSiMyRYv-1673337756810)(An Image is Worth 16x16 Words Transformers for Image Recognition at Scale.assets/image-20230110101507343.png)]](https://img-blog.csdnimg.cn/34a938791eea4da3870add631f88be73.png)
paper:2010.11929.pdf (arxiv.org)
code:google-research/vision_transformer (github.com)
期刊/会议:ICLR 2020
摘要
虽然Transformer体系结构已经成为自然语言处理任务的事实上的标准,但它在计算机视觉方面的应用仍然有限。在视觉上,注意力要么与卷积网络结合应用,要么用于替换卷积网络的某些组件,同时保持其整体结构。我们表明,这种对CNN的依赖是不必要的,直接应用于图像patch序列的纯转换器可以很好地执行图像分类任务。当在大量数据上进行预训练并传输到多个中型或小型图像识别基准(ImageNet, CIFAR-100, VTAB等)时,与最先进的卷积网络相比,Vision Transformer(ViT)获得了出色的结果,同时需要更少的计算资源进行训练。
1、简介
基于自我注意力的架构,特别是Transformer,已经成为自然语言处理(NLP)的首选模型。主要的方法是在大型文本语料库上进行预训练,然后在较小的特定于任务的数据集上进行微调。得益于Transformer的计算效率和可扩展性,训练具有超过100B个参数的空前规模的模型成为可能。随着模型和数据集的增长,性能仍然没有饱和的迹象。
然而,在计算机视觉中,卷积架构仍然占主导地位。受到NLP成功的启发,多个作品尝试将类似CNN的架构与self-attention相结合,甚至一些完全取代卷积。后一种模型虽然理论上是有效的,但由于使用了专门的注意力模式,还没有在现代硬件加速器上有效地扩展。因此,在大规模图像识别中,经典的ResNet架构仍然是最先进的。
受NLP中Transformer可扩展性成功的启发,我们尝试将标准Transformer直接应用于图像,并进行最少的修改。为此,我们将图像分割为多个patch,并将这些patch的线性嵌入序列作为Transformer的输入。在NLP应用程序中,图像patch的处理方式与标记(单词)相同。我们以监督的方式训练模型进行图像分类。
当在中等大小数据集(如ImageNet)上训练时,没有很强的正则化,这些模型产生的精度比同等大小的ResNets低几个百分点。这个看起来令人沮丧的结果可能在意料之中:Transformer相对于CNN来说,缺少一些inductive biases ,例如翻译等值方差和局域性,因此不能很好地泛化时,训练的数据量不足。
然而,如果模型在更大的数据集(14M-300M图像)上训练,情况就会发生变化。我们发现大规模训练优于inductive biases。我们的Vision Transformer(ViT)在足够规模的预训练和迁移到数据点更少的任务时获得了出色的结果。当在公共ImageNet-21k数据集或内部JFT-300M数据集上进行预训练时,ViT在多个图像识别基准测试中接近或超过了最先进的水平。其中,最佳模型在ImageNet上的准确率为88.55%,在ImageNet- real上的准确率为90.72%,在CIFAR-100上的准确率为94.55%,在VTAB套件的19个任务上的准确率为77.63%。
2、相关工作
Transformer由Vaswani等人(2017)提出用于机器翻译,并已成为许多NLP任务中的最先进方法。基于transformer的大型模型通常在大型语料库上进行预训练,然后针对手头的任务进行微调:BERT使用去噪自监督的预训练任务,而GPT工作线使用语言建模作为其预训练任务。
对图像进行自我关注的理想应用会要求每个像素都关注其他像素。由于像素数量的成本是二次的,所以这并不能扩展到实际的输入大小。因此,为了将Transformer应用于图像处理,过去已经尝试了几种近似方法。Parmar等人仅在每个查询像素的局部邻域中应用self-attention,而不是全局应用。这种局部多头点积自注意块可以完全取代卷积。在另一项工作中,Sparse Transformer采用可放缩的全局自注意近似,以便适用于图像。扩大注意力的另一种方法是将其应用于不同大小的块中,在极端情况下,仅沿单个轴。许多这些专门的注意力架构在计算机视觉任务上展示了有前景的结果,但是需要复杂的工程才能在硬件加速器上有效地实现。
与我们最相关的是Cordonnier等人的模型,该模型从输入图像中提取大小为2 × 2的patch,并在顶部应用完全的自我注意。这个模型与ViT非常相似,但我们的工作进一步证明了大规模的预训练使vanilla transformer与最先进的CNN对比(甚至更好)。此外,Cordonnier等人使用了2 × 2像素的小patch尺寸,这使得模型只适用于小分辨率的图像,而我们也可以处理中等分辨率的图像。
也有很多人对将卷积神经网络(CNN)与self-attention的形式相结合感兴趣,例如通过增强图像分类的特征图或通过使用self-attention进一步处理CNN的输出,例如用于目标检测,视频处理,图像分类,无监督目标发现,或统一的文本视觉任务。
另一个近期相关的模型是图像GPT (iGPT),它在降低图像分辨率和色彩空间后,将transformer应用于图像像素。该模型以无监督的方式作为生成模型进行训练,然后可以对产生的表示进行微调或线性探测以获得分类性能,在ImageNet上达到72%的最大精度。
我们的工作搜集了越来越多的论文,这些论文探索了比标准ImageNet数据集更大规模的图像识别。使用额外的数据源可以在标准基准上实现最先进的结果。此外,Sun等人研究了CNN性能如何随数据集大小缩放,Kolesnikov等人,Djolonga等人从ImageNet-21k和JFT-300M等大规模数据集对CNN迁移学习进行了实证探索。我们也关注后面两个数据集,但训练transformer,而不是之前工作中使用的基于ResNet的模型。
3、方法
在模型设计中,我们尽可能地遵循原始的transformer。这种有意设计的简单设置的一个优点是,可伸缩的NLP Transformer体系结构及其高效的实现几乎可以开箱即用。
3.1 Vision Transformer(ViT)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D2j6w2rt-1673337756812)(An Image is Worth 16x16 Words Transformers for Image Recognition at Scale.assets/image-20230110115318606.png)]](https://img-blog.csdnimg.cn/bc6d88ff54284c33b5375e3ab9d78d26.png)
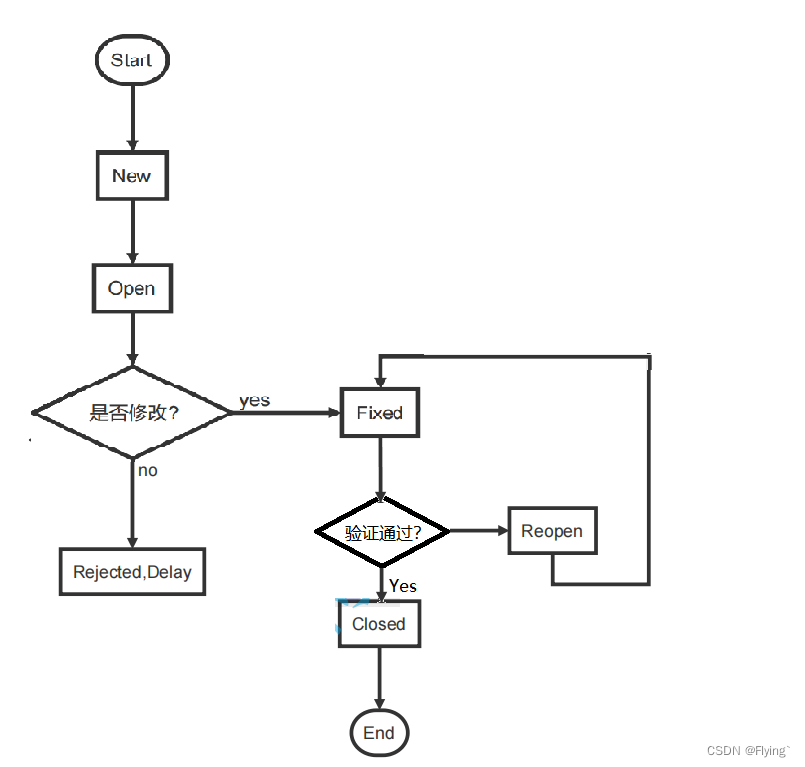
图1描述了模型的概述。标准Transformer接收token嵌入的1D序列作为输入。为了处理2D图像,我们将图像 x ∈ R H × W × C x \in \R^{H×W ×C} x∈RH×W×C重塑为一个平面2D patch序列 x p ∈ R N × ( P 2 ⋅ C ) x_p \in \R^{N×(P^2·C)} xp∈RN×(P2⋅C),其中 ( H , W ) (H, W) (H,W)为原始图像的分辨率, C C C为通道数, ( P , P ) (P, P) (P,P)为每个图像patch的分辨率, N = H W / P 2 N = HW/P^2 N=HW/P2为得到的patch数量,这也作为transformer的有效输入序列长度。Transformer在它的所有层中使用恒定的潜在向量大小 D D D,所以我们用一个可训练的线性投影(Eq. 1)将patch扁平化并映射到D维。我们将这个投影的输出称为patch嵌入。
与BERT的[class] token类似,我们在嵌入的补丁序列( z 0 0 = X c l a s s z_0^0 = X_{class} z00=Xclass)前添加一个可学习嵌入,其在Transformer编码器( z L 0 z^0_L zL0)输出处的状态作为图像表示 y y y (Eq. 4)。在预训练和微调期间,分类头附加到 z L 0 z^0_L zL0。分类头在预训练时由一个隐含层的MLP实现,在微调时由一个线性层实现。
位置嵌入被添加到patch嵌入中以保留位置信息。我们使用标准的可学习的1D位置嵌入,因为我们没有观察到使用更先进的2D感知位置嵌入有显著的性能提升(附录D.4)。得到的嵌入向量序列作为编码器的输入。
Transformer由多头自注意(MSA,见附录A)和MLP块交替层(Eq. 2,3)组成。在每个块之前应用Layernorm (LN),在每个块之后应用残差连接。
MLP层包含两层带有GELU的非线性层。
z
0
=
[
x
c
l
a
s
s
;
x
p
1
E
;
x
p
2
E
;
.
.
.
,
x
p
N
E
]
+
E
p
o
s
z_0=[x_{class};x_p^1E;x_p^2E;...,x_p^NE]+E_{pos}
z0=[xclass;xp1E;xp2E;...,xpNE]+Epos
z l ′ = M S A ( L N ( z l − 1 ) ) + z l − 1 z'_l=MSA(LN(z_{l-1}))+z_{l-1} zl′=MSA(LN(zl−1))+zl−1
z l = M L P ( L N ( z l ′ ) ) + z ′ l z_l=MLP(LN(z'_l))+z'l zl=MLP(LN(zl′))+z′l
y = L N ( z L 0 ) y=LN(z_L^0) y=LN(zL0)
Inductive bias。我们注意到Vision Transformer比CNN具有更少的图像特定的Inductive bias。在CNN中,局部性、二维邻域结构和平移等效方差贯穿整个模型的每一层。在ViT中,只有MLP层是局部的、平移等变的,而自我注意层是全局的。二维邻域结构的使用非常谨慎:在模型开始时,通过将图像切割成块,并在微调时调整不同分辨率图像的位置嵌入(如下所述)。除此之外,初始化时的位置嵌入不包含patch的二维位置信息,并且必须从头学习patch之间的所有空间关系。
混合架构。作为原始图像patch的替代方案,输入序列可以从CNN的特征图中形成。在这个混合模型中,patch嵌入投影 E E E (Eq. 1)应用于从CNN特征图中提取的斑块。作为一种特殊情况,patch的空间大小可以为1x1,这意味着输入序列是通过简单地将特征图的空间维度扁平化并投影到Transformer维度来获得的。如上所述,增加了分类输入嵌入和位置嵌入。
3.2 微调和高分辨率
通常,我们在大型数据集上预训练ViT,并对(较小的)下游任务进行微调。为此,我们去掉预训练的预测头,并附加一个零初始化的 D × K D × K D×K前馈层,其中 K K K是下游类的数量。与训练前相比,以更高的分辨率进行微调通常是有益的。当输入高分辨率的图像时,我们保持patch大小相同,这导致更大的有效序列长度。ViT可以处理任意长度的序列(直到内存限制),然而,预先训练的位置嵌入可能不再有意义。因此,我们根据预训练的位置嵌入在原始图像中的位置执行2D插值。请注意,分辨率调整和patch抽取是关于图像2D结构的inductive bias手动注入Vision Transformer的唯一点。
4、实验
我们评估了ResNet、Vision Transformer(ViT)和混合的表示学习能力。为了理解每个模型的数据需求,我们在不同大小的数据集上进行预训练,并评估许多基准任务。在考虑预训练模型的计算成本时,ViT表现非常好,以较低的预训练成本在大多数识别基准上达到了最先进的水平。最后,我们使用自我监督进行了一个小实验,并表明自我监督的ViT为未来带来了希望。
4.1 设置
数据集:为了探索模型的可扩展性,我们使用了ILSVRC-2012 ImageNet数据集(包含1k类和1.3M张图像),它的超集ImageNet-21k包含21k类和14M张图像, JFT 包含18k类和303M高分辨率图像。根据Kolesnikov等人的研究,我们对下游任务的测试集进行了减少重复的预训练数据集。我们将在这些数据集上训练的模型迁移到几个基准任务:原始验证标签和清理后的ReaL标签上的ImageNet, CIFAR-10/100, Oxford-IIIT Pets 和Oxford Flowers-102 。对于这些数据集,预处理遵循Kolesnikov等人。
我们还使用19个任务的VTAB分类套件进行评估。VTAB评估不同任务的低数据传输,每个任务使用1000个训练示例。任务分为三组:自然任务(Natural),如上所述,宠物,CIFAR等。专业的任务(Specialized)——医疗和卫星图像,以及结构化的任务(Structured)——需要几何理解的任务,比如定位。
模型变体:我们基于BERT使用的ViT配置,如表1所示。“Base”和“Large”模型直接采用BERT,我们添加了更大的“Huge”模型。在接下来的内容中,我们使用简单的符号来表示模型大小和输入补丁大小:例如,ViT-L/16表示输入patch大小为16 × 16的“Large”变体。请注意,Transformer的序列长度与patch大小的平方成反比,因此具有较小patch大小的模型在计算上更昂贵。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KCbTlthA-1673337756814)(An Image is Worth 16x16 Words Transformers for Image Recognition at Scale.assets/image-20230110130633675.png)]](https://img-blog.csdnimg.cn/8bcc50adde0f46649a8b0fe148ecb5c6.png#pic_center)
对于基线CNN,我们使用ResNet,但将批规范化层(BN)替换为组规范化(GN),并使用标准化卷积。这些修改改进了传输,我们将修改后的模型称为“ResNet (BiT)”。对于混合模型,我们将中间特征图以一个“像素”的patch大小输入ViT。为了实验不同的序列长度,我们要么(i)取常规ResNet50的阶段4的输出,要么(ii)删除阶段4,在阶段3中放置相同数量的层(保持层总数),并取这个扩展的阶段3的输出。选项(ii)的结果是4倍长的序列长度,和更昂贵的ViT模型。
训练和微调。我们使用Adam训练所有模型,包括ResNets, β 1 = 0.9 , β 2 = 0.999 β_1 = 0.9, β_2 = 0.999 β1=0.9,β2=0.999,batch_size为4096,并应用0.1的高权重衰减,我们发现这对所有模型的迁移都有用(附录D.1显示,与常规做法相比,Adam在我们的设置中对ResNets的效果略好于SGD)。我们使用线性学习速率预热warmup和衰减decay,详见附录B.1。为了进行微调,我们使用动量SGD,批量大小512,所有模型,见附录B.1.1。对于表2中的ImageNet结果,我们在更高分辨率下进行了微调:ViT-L/16为512,ViT-H/14为518,并且还使用Polyak和Juditsky以0.9999的因子平均。
评估指标。我们报告下游数据集的结果,无论是通过少样本或微调精度。微调精度捕获每个模型在各自数据集上进行微调后的性能。通过解决正则化最小二乘回归问题,将训练图像子集的(冻结)表示映射到 { − 1 , 1 } K \{−1,1\}^K {−1,1}K个目标向量,可以获得少样本精度。这个公式使我们能够以封闭的形式得到精确的解。虽然我们主要关注微调性能,但有时我们使用线性少样本精度进行快速动态评估,因为微调成本太高。
4.2 对比SOTA
首先比较我们最大的模型-ViT-H/14和ViT-L/16 与文献中最先进的CNN。第一个比较点是大迁移(BiT),它使用大型ResNets执行监督迁移学习。第二个是Noisy Student,这是一个使用ImageNet和JFT-300M上的半监督学习训练的大型高效网络,删除了标签。目前,Noisy Student是ImageNet和BiT-L在其他数据集报道的SOTA。所有模型都在TPU v3硬件上进行训练,我们报告了用于每个模型预训练的TPU v3-core-days,即用于训练的TPU v3核数量(每个芯片2个)乘以训练时间(以天为单位)。
表2显示了结果。在JFT-300M上预训练的较小的ViT-L/16模型在所有任务上都优于BiT-L(在相同数据集上预训练),同时训练所需的计算资源大大减少。更大的模型ViT-H/14进一步提高了性能,特别是在更具有挑战性的数据集上——ImageNet、CIFAR-100和VTAB套件。有趣的是,与现有的技术相比,该模型的预训练所需的计算量仍然大大减少。然而,我们注意到,预训练效率可能不仅受到架构选择的影响,还受到其他参数的影响,如训练计划、优化器、权重衰减等。我们在第4.4节中提供了不同架构的性能与计算的对照研究。最后,在公共ImageNet-21K数据集上预训练的ViT-L/16模型在大多数数据集上也表现良好,同时预训练占用的资源更少:它可以在大约30天内使用8核的标准云TPU v3进行训练。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x4sGHT5c-1673337756814)(An Image is Worth 16x16 Words Transformers for Image Recognition at Scale.assets/image-20230110151730779.png)]](https://img-blog.csdnimg.cn/53cebbd4a4b74f16a6592a110b36a0fd.png)
图2将VTAB任务分解为各自的组,并与该基准测试上之前的SOTA方法进行了比较:BiT, VIVI在ImageNet和Youtube上联合训练的ResNet,以及S4L在ImageNet上的监督加半监督学习。ViT-H/14在自然和结构化任务上优于BiT-R152x4和其他方法。在Specialized上,前两个模型的性能是相似的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6tRIxvnz-1673337756815)(An Image is Worth 16x16 Words Transformers for Image Recognition at Scale.assets/image-20230110152045537.png)]](https://img-blog.csdnimg.cn/30a1779a152944cfb500dfc79dc98714.png)
4.3 预训练数据要求
视觉转换器在大型JFT-300M数据集上进行预训练时表现良好。与ResNets相比,视觉的inductive bias更少,数据集大小有多重要?我们进行了两个系列实验。
首先,我们在不断增加的数据集上预训练ViT模型:ImageNet, ImageNet-21k和JFT-300M。为了提高较小数据集上的性能,我们优化了三个基本正则化参数——权重衰减、dropout和标签平滑。图3显示了对ImageNet进行微调后的结果(其他数据集的结果如表5所示)。当在最小的数据集ImageNet上进行预训练时,ViT-Large模型与ViT-Base模型相比表现不佳,尽管(适度)正则化。通过ImageNet-21K预训练,它们的表现相似。只有JFT-300M,我们才能看到更大型号的全部好处。图3也展现了不同大小的BiT模型所跨越的区域的效果。在ImageNet上,BiT CNN优于ViT,但在更大的数据集上,ViT超过。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OQCAlfwR-1673337756816)(An Image is Worth 16x16 Words Transformers for Image Recognition at Scale.assets/image-20230110152812984.png)]](https://img-blog.csdnimg.cn/0447acd5304b472ea4cbec8356d9eb6d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nF8wCgEV-1673337756817)(An Image is Worth 16x16 Words Transformers for Image Recognition at Scale.assets/image-20230110152824847.png)]](https://img-blog.csdnimg.cn/aab2b54f22ce40529486716911045438.png)
其次,我们在9M、30M和90M的随机子集以及完整的JFT-300M数据集上训练我们的模型。我们不对较小的子集执行额外的正则化,并对所有设置使用相同的超参数。这样,我们评估模型的内在属性,而不是正则化的影响。然而,我们确实使用了早停(early stopping),并报告了在训练期间获得的最佳验证准确性。为了节省计算量,我们报告了少量的线性精度,而不是完整的微调精度。图4包含结果。在较小的数据集上,ViT比ResNets的计算成本更高。例如,ViT-B/32比ResNet50略快;它在9M子集上表现得更差,但在90M+子集上表现得更好。ResNet152x2和ViT_L/16也是如此。这个结果强化了这样一种直觉,即卷积inductive bias对于较小的数据集是有用的,但对于较大的数据集,直接从数据中学习相关模式是足够的,甚至是有益的。
总的来说,ImageNet上的少样本结果(图4)以及VTAB上的低数据结果(表2)似乎很有希望实现非常低的数据迁移。进一步分析ViT的少样本特性是未来工作的一个令人振奋的方向。
4.4 scaling study
通过评估来自JFT-300M的传输性能,我们对不同模型进行了控制scaling study。在这种情况下,数据大小不会限制模型的性能,我们评估每个模型的性能与预训练成本。模型集包括:7个ResNets, R50x1, R50x2, R101x1, R152x1, R152x2,预训练7个epoch,加上R152x2和R200x3预训练14个epoch;6个ViT模型,ViT-B/32, B/16, L/32, L/16,预训练7个epoch,加上L/16和H/14预训练14epoch;5个混合模型,R50+ViT-B/32, B/16, L/32, L/16预训练7个epoch,加上R50+ViT-L/16预训练14个epoch(对于混合,模型名称后面的数字不是表示patch大小,而是表示ResNet骨干中的总下采样比)。
图5包含了迁移性能与总训练前计算的对比(关于计算成本的详细信息,请参阅附录D.5)。各模型的详细结果见附录中的表6。可以观察到一些模式。首先,ViT在性能/计算权衡方面超过ResNet。ViT使用大约2 - 4倍的计算量来获得相同的性能(平均超过5个数据集)。其次,在较小的计算预算下,混合模型的性能略优于ViT,但对于较大的模型,这种差异就消失了。这个结果有点令人惊讶,因为人们可能期望卷积局部特征处理可以辅助任何规模的ViT。第三,ViT在尝试的范围内似乎没有饱和,这激励了未来的扩大努力。
4.5 深入研究ViT
为了开始理解Vision Transformer如何处理图像数据,我们先分析它的内部表示。视觉转换器的第一层将扁平化的补丁线性投影到低维空间(Eq. 1)。图7(左)显示了学习嵌入滤波器的顶部主成分。这些组件类似于每个patch中精细结构的低维表示的合理基函数。

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xYFkSiGk-1673337756818)(An Image is Worth 16x16 Words Transformers for Image Recognition at Scale.assets/image-20230110154837293.png)]](https://img-blog.csdnimg.cn/948df6e29d6943df98b367a79c262d0e.png)
投影完成后,将学习到的位置嵌入添加到patch表示中。图7(中)显示,模型学会了在位置嵌入的相似性中对图像内的距离进行编码,即越近的patch往往具有越相似的位置嵌入。进一步,出现了行-列结构;同一行/列中的patch具有相似的嵌入。最后,对于较大的网格,正弦结构有时是明显的(附录D)。位置嵌入学习表示2D图像拓扑解释了为什么手工制作的2D感知嵌入变量没有产生改进(附录D.4)。
self-attention使ViT能够在整个图像中集成信息,即使是在最低层。我们调查网络在多大程度上利用了这种能力。具体来说,我们根据注意力权重计算图像空间中信息被整合的平均距离(图7,右)。这个“注意距离”类似于CNN中的感受野(receptive field)大小。我们发现一些头部已经在最低层中处理了大部分图像,这表明模型确实使用了全局集成信息的能力。其他注意头在低层的注意距离始终较小。这种高度本地化的注意力在混合模型中不太明显,在Transformer之前应用ResNet(图7,右),这表明它可能与CNN中的早期卷积层具有类似的功能。注意距离随网络深度的增加而增加。从全局来看,我们发现该模型关注与分类语义相关的图像区域(图6)。
4.6 自监督
Transformer在NLP任务中表现出色。然而,它们的成功不仅来自于出色的可扩展性,还来自于大规模的自我监督预训练。我们还对用于自监督的mask patch prediction进行了初步探索,模拟了BERT中使用的掩码语言建模(masked language modeling)任务。通过自监督的预训练,我们较小的ViT-B/16模型在ImageNet上的准确率达到了79.9%,比从头开始的训练显著提高了2%,但仍落后于监督的预训练4%。附录B.1.2载有进一步的细节。我们留下对比前训练的探索到未来的工作。
5、总结
我们探索了Transformer在图像识别中的直接应用。与之前在计算机视觉中使用self-attention的工作不同,除了初始的patch抽取步骤外,我们没有在架构中引入特定于图像的inductive bias。相反,我们将图像转化为一系列patch,并通过NLP中使用的标准Transformer编码器对其进行处理。这种简单但可扩展的策略在与大型数据集上的预训练相结合时效果非常好。因此,Vision Transformer在许多图像分类数据集上达到或超过了最先进的水平,同时预训练成本相对较低。
尽管这些初步成果令人鼓舞,但仍存在许多挑战。一种是将ViT应用于其他计算机视觉任务,如检测和分割。我们的结果,加上Carion等人的结果,表明了这种方法的前景。另一个挑战是继续探索自监督的预训练方法。我们的初步实验表明,自监督预训练有所改善,但自监督预训练与大规模监督预训练之间仍有较大差距。最后,ViT的进一步扩展可能会提高性能。