目录
Xpath的简介:
简介:
相关概念:
Xpath的使用:
安装:
用法:
第一步:准备html
第二步:将html构造出etree对象
第三步:使用etree对象的xpath()方法配合xpath表达式来完成对数据的提取
Xpath的简介:
简介:
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。但是XPath很快地被开发者采用来当作小型查询语言。
HTML属于XML的一个子集,所以可以用Xpath解析XML
相关概念:
<book>
<id>1</id>
<name>技术人才</name>
<price>5w</price>
<author>
<nick>程序猿</nick>
<nick>码农</nick>
</author>
</book>book,id,,name,price,author都被称为节点.Id,name,price,author被称为book的子节点book被称为id,name,price,author的父节点id,name,price,author被称为同胞节点
Xpath的使用:
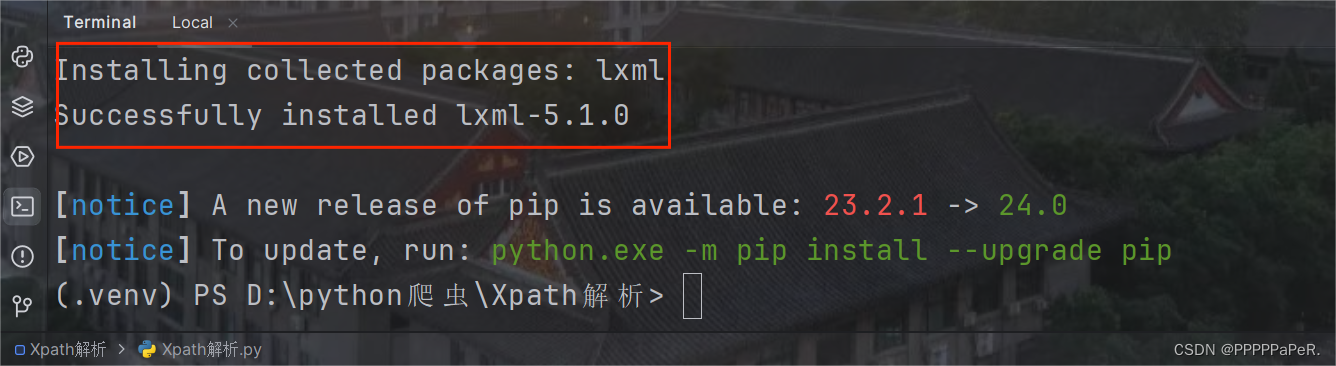
安装:
pip install lxml

用法:
第一步:准备html
html = """
<body>
<ul>
<li><a href="http://www.baidu.com">百度
</a></li>
<li><a href="http://www.google.com">谷歌
</a></li>
<li><a href="http://www.sogou.com">搜狗
</a></li>
</ul>
<ol>
<li><a href="qiche">汽车</a></li>
<li><a href="huoche">火车</a></li>
<li><a href="feiji">飞机</a></li>
</ol>
</body>
</html>
"""第二步:将html构造出etree对象
from lxml import etree
html = """
<body>
<ul>
<li><a href="http://www.baidu.com">百度
</a></li>
<li><a href="http://www.google.com">谷歌
</a></li>
<li><a href="http://www.sogou.com">搜狗
</a></li>
</ul>
<ol>
<li><a href="qiche">汽车</a></li>
<li><a href="huoche">火车</a></li>
<li><a href="feiji">飞机</a></li>
</ol>
</body>
</html>
"""
tree = etree.HTML(html)第三步:使用etree对象的xpath()方法配合xpath表达式来完成对数据的提取
from lxml import etree
html = """
<body>
<ul>
<li><a href="http://www.baidu.com">百度
</a></li>
<li><a href="http://www.google.com">谷歌
</a></li>
<li><a href="http://www.sogou.com">搜狗
</a></li>
</ul>
<ol>
<li><a href="qiche">汽车</a></li>
<li><a href="huoche">火车</a></li>
<li><a href="feiji">飞机</a></li>
</ol>
</body>
</html>
"""
tree = etree.HTML(html)
result = tree.xpath("/html/body/ul/li/a/@href")
print(result)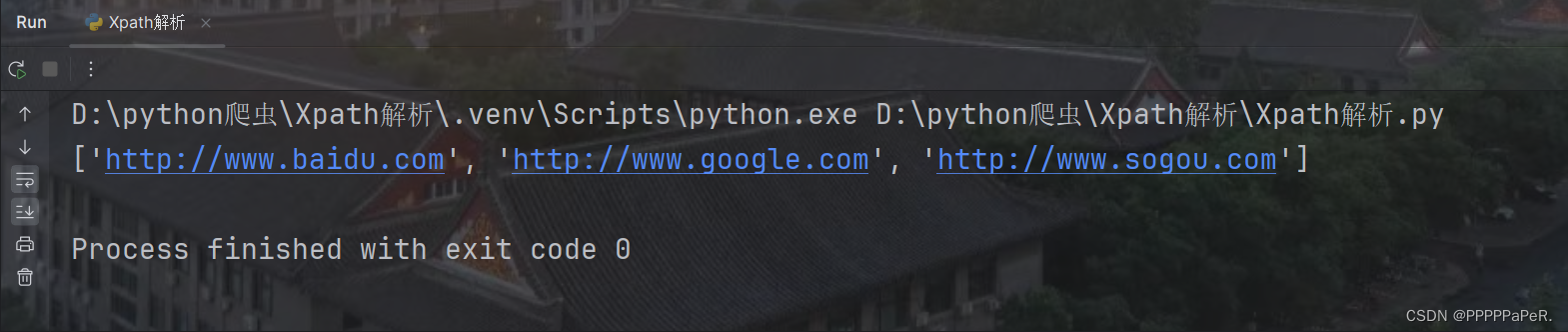



![每日一题 --- 977. 有序数组的平方[力扣][Go]](https://img-blog.csdnimg.cn/direct/cc73369402bb40f0ba52de6a070fb35a.png)