- 首先科普一下知识,我们知道ASCII码中有128的数字,符号,或大小写字母,这对于英文来说已经够用了,一个字母占用一个字节(一个字节8bit),
- 存储的过程是这样的,一个字母w,找到ASCII码===》十进制====》二进制====编码====》补成8位一个字节。好存储到磁盘。(最小存储单元为一字节)(补位要补0)
- 解码就是这个过程反过来
- GBK兼容ASCII,也可以存储汉字,用两个字节存储,(高字节第一位为1)过程是这样的==一个汉字-----》查询GBK对应的十进制------》转为二进制即可。
- 万国码大声的说出来===Unicode~~~~~呀吼
- Unicode字符集的UTF-8编码格式
- 一个英文站一个字节,二进制第一位是0,转成十进制是正数
- 一个中文占三个字节,二进制第一位是1,第一个字节转成十进制是负数。
- 如何不产生乱码呢,
- 不要用字节流读取文本文件
- 编码解码时使用同一个码表,同一个编码方法
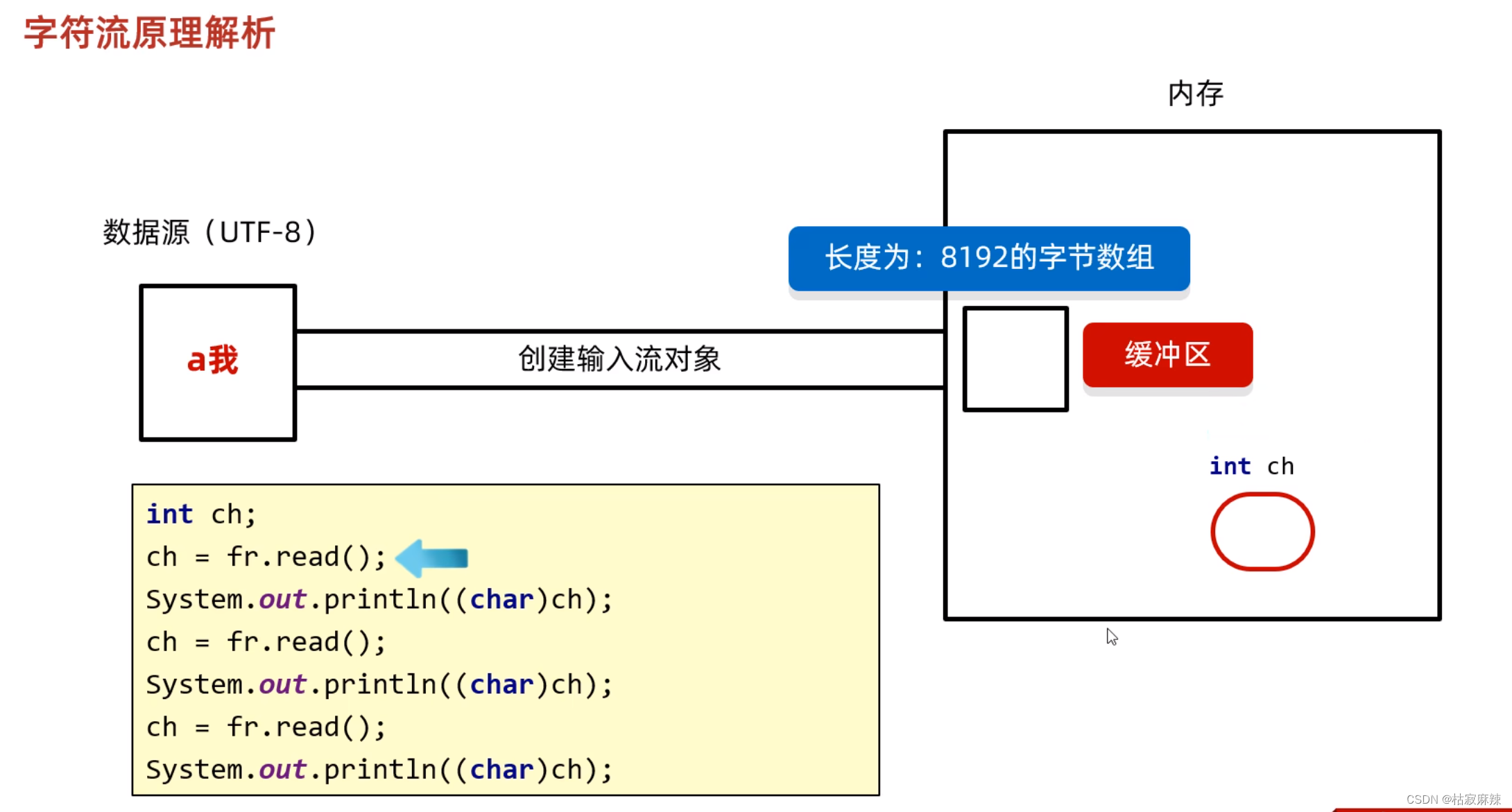
- 创建字符输入流对象:底层关联文件,并创建缓冲区(长度为8192的字节数组)
- 读取数据
- 判断缓冲区中是否有数据可以读取
- 缓冲区没有数据:就从文件中获取数据,装配到缓冲区中,每次尽可能装满缓冲区,如果文件中也没有数据了,返回-1
- 缓冲区有数据:就从缓冲区读取。
- 空参的read方法:一次读取一个字节,遇到中文一次读取多个字节,把字节解码并转成十进制返回。
- 有参的read方法:把读取字节,解码,强转三步合并了,强转之后的字符放到数组中。
- 一个问题:write()方法是不是当文件中有数据时会清除数据,那么当我们做了一个read方法后,紧接着执行write方法,那么我在执行read方法时会是什么样子的?
- 答案是:第一次read方法后会把文件中的数据读取到缓冲区中,当write进行清空操作只会清空本地文件中的数据,不会清除缓冲区的数据,这个时候再进行read会去缓冲区中拿第一次缓冲的数据。
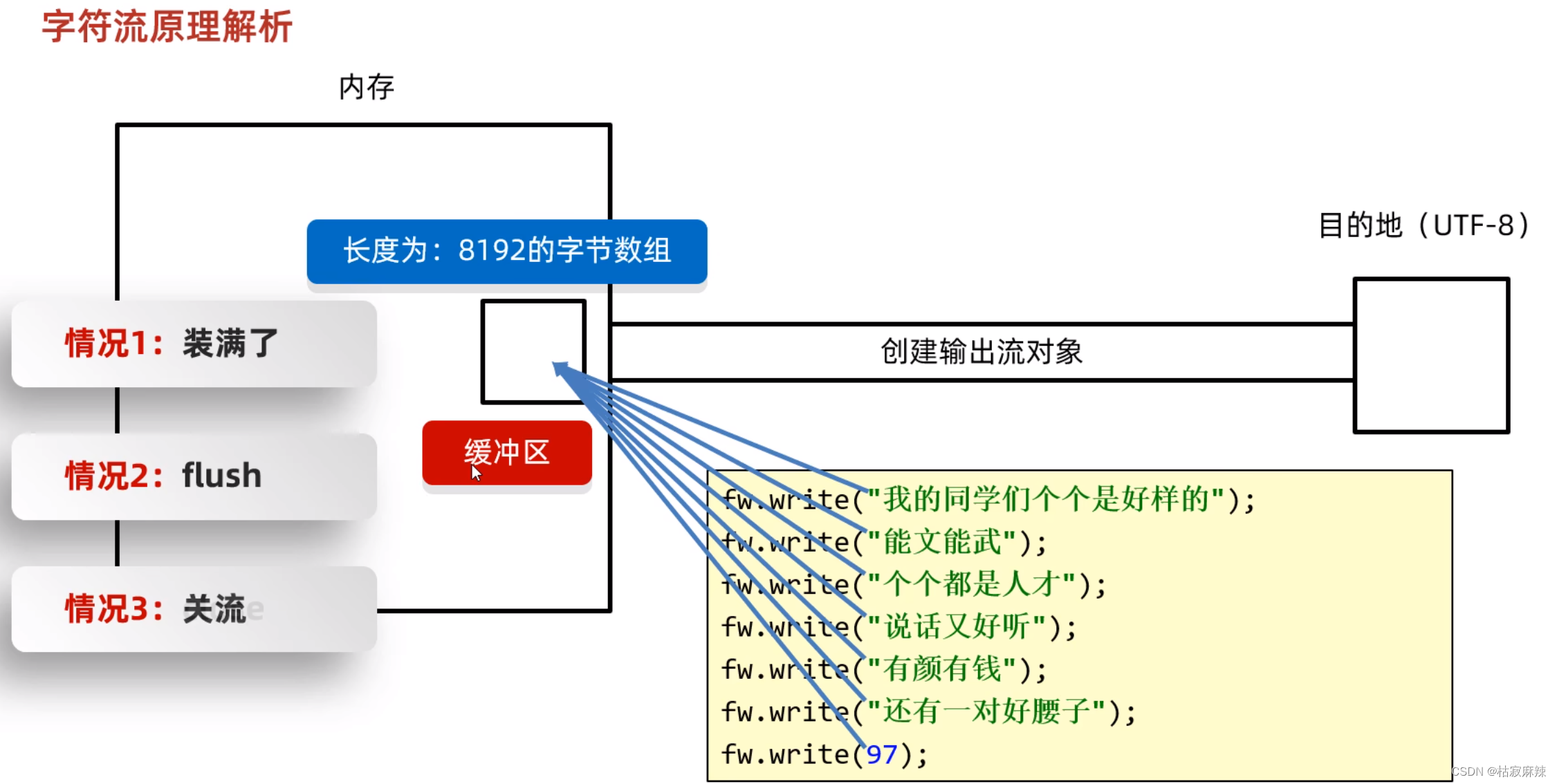
- 这是三种往文件中写入的方式。
- flush刷新:刷新之后,还可以继续往文件中写入数据
- close关流:断开通道,无法再往文件中写出数据
乱码问题,字符流原理
news2026/4/4 16:20:38
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1539826.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

二进制王国(蓝桥杯备赛)【sort/cmp的灵活应用】
二进制王国
题目链接
https://www.lanqiao.cn/problems/17035/learning/?contest_id177
题目描述 思路
这里就要灵活理解字典序排列,虽然string内置可以直接比较字符串字典序,但是在拼接时比较特殊,比如 11的字典序小于110,但…

鸿蒙Harmony应用开发—ArkTS(@Extend装饰器:定义扩展组件样式)
在前文的示例中,可以使用Styles用于样式的扩展,在Styles的基础上,我们提供了Extend,用于扩展原生组件样式。 说明: 从API version 9开始,该装饰器支持在ArkTS卡片中使用。 装饰器使用说明
语法
Extend(UI…

4 种策略让 MySQL 和 Redis 数据保持一致
先阐明一下 MySQL 和 Redis 的关系:MySQL 是数据库,用来持久化数据,一定程度上保证数据的可靠性;Redis 是用来当缓存,用来提升数据访问的性能。 关于如何保证 MySQL 和 Redis 中的数据一致(即缓存一致性问题…
jmeter超高并发报错解决方法
1、比如jmeter设置并发量为5000,运行后报错socket closed。原因是客户端与服务端做了三次握手之后,后面不需要握手了,但是jmeter没有这个功能,5000个并发每次发接口请求都是独立的,jmeter端口处理不了这么大量的请求&a…
【SpringBoot框架篇】37.使用gRPC实现远程服务调用
文章目录 RPC简介gPRC简介protobuf1.文件编写规范2.字段类型3.定义服务(Services) 在Spring Boot中使用grpc1.父工程pom配置2.grpc-api模块2.1.pom配置2.2.proto文件编写2.3.把proto文件编译成class文件 3.grpc-server模块3.1.pom文件和application.yaml3.2.实现grpc-api模块的…
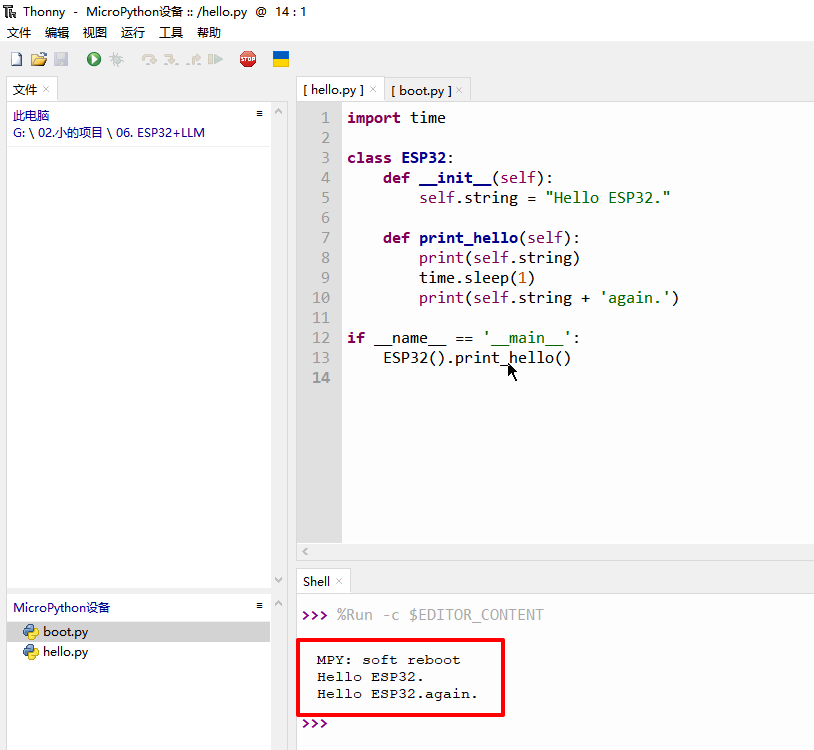
01. 如何配置ESP32环境?如何开发ESP32?
0. 前言 此文章收录于《ESP32学习笔记》专栏,此专栏会结合实际项目记录作者学习ESP32的过程,争取每篇文章能够将细节讲明白,会应用。 1. 安装IDE:Thonny 后续项目中我们都是使用pythont语言,而thonny工具能很好的支撑E…

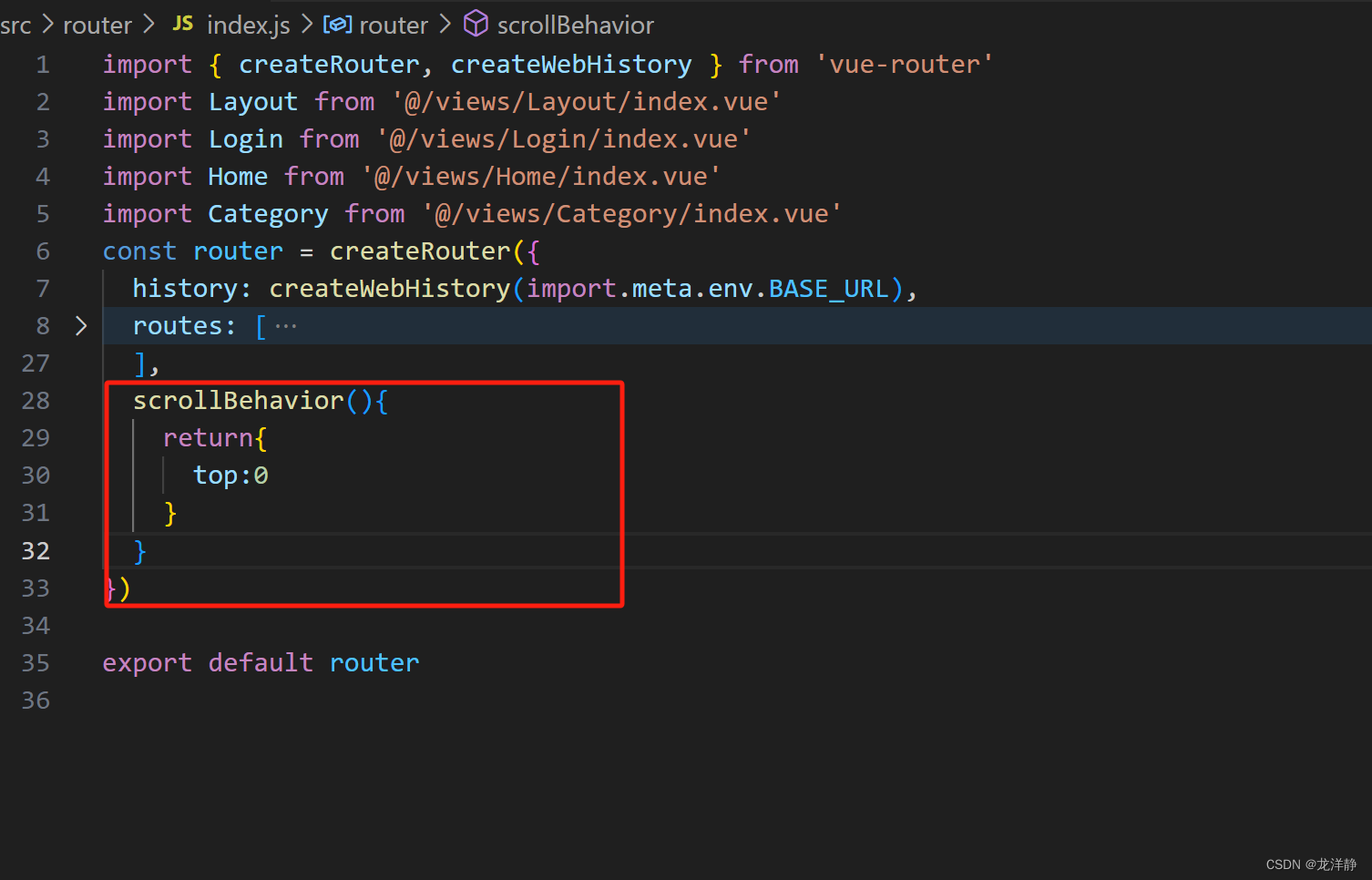
Vue3:用重定向方式,解决No match found for location with path “/“问题
一、情景说明
在初学Vue3的项目中,我们配置了路由后,页面会告警 如下图: 具体含义就是,没有配置"/"路径对应的路由组件
二、解决
关键配置:redirect
const router createRouter({history:createWebHis…
P1246 编码题解
题目
编码工作常被运用于密文或压缩传输。这里我们用一种最简单的编码方式进行编码:把一些有规律的单词编成数字。
字母表中共有26个字母a,b,c,⋯,z,这些特殊的单词长度不超过6且字母按升序排列。把所有这样的单词放在一起,按字典顺序排列&…

【docker系列】深入理解 Docker 容器管理与清理
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…
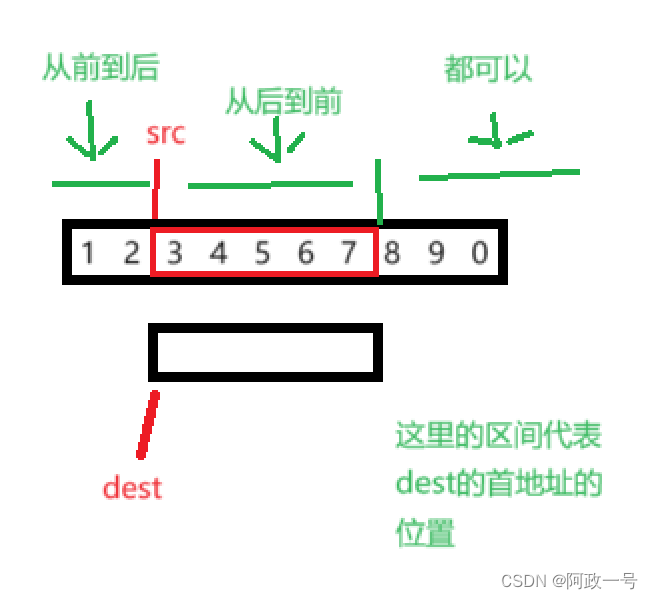
C语言内存函数(1)【memcpy函数的使用与模拟实现】【memmove函数的使用和模拟实现】
关于内存函数有四个函数需要我们学习。分别是memcpy,memmove,memset和memcmp。都在头文件string.h里面。
一.memcpy函数的使用
一提到这个函数,我们可能会联想到strcpy函数,但strcpy函数是针对字符串的拷贝。但是我们在写代码的…

Docker学习笔记 - 基本概念
一. 什么是“容器”(container)和“镜像”(Image)
所谓“容器”可以理解为一个模拟操作系统的虚拟层,大部分是基于Linux的,应用程序及其配置信息,依赖库可以打包成一个Image独立运行在这个虚拟…

双指针算法:三数之和
文章目录 一、[题目链接:三数之和](https://leetcode.cn/problems/3sum/submissions/515727749/)二、思路讲解三、代码演示 先赞后看,养成习惯!!!^ _ ^<3 ❤️ ❤️ ❤️ 码字不易,大家的支持就是我坚持…

【LeetCode】升级打怪之路 Day 28:回溯算法 — 括号生成 删除无效的括号
今日题目: 22. 括号生成301. 删除无效的括号 参考文章: 回溯算法:括号生成回溯算法:删除无效的括号 这是两道使用回溯算法来解决与括号相关的问题,具备一定的难度,需要学习理解。
通过第一道题“括号生成”…

第十届蓝桥杯大赛个人赛省赛(软件类)真题- CC++ 研究生组-字串数字
3725573269
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main(){map<char, int> mp;string s "LANQIAO";long long ans 0, power 1;//7位数的26进制可能会超过int范围for(int i 1; i < 26; i){mp.…

Visual Studio 2013 - 高亮设置突出显示的引用
Visual Studio 2013 - 高亮设置突出显示的引用 1. 高亮设置 突出显示的引用References 1. 高亮设置 突出显示的引用
工具 -> 选项… -> 环境 -> 字体和颜色 References
[1] Yongqiang Cheng, https://yongqiang.blog.csdn.net/
前端项目,个人笔记(五)【图片懒加载 + 路由配置 + 面包屑 + 路由行为修改】
目录
1、图片懒加载
步骤一:自定义全局指令
步骤二:代码中使用
编辑步骤三:效果查看
步骤四:代码优化
2、封装组件案例-传对象
3、路由配置——tab标签
4、根据tab标签添加面包屑
4.1、实现
4.2、bug:需要…
使用 ReclaiMe Pro 查找并恢复网络中的 SSH 服务器数据
天津鸿萌科贸发展有限公司是 ReclaiMe Pro 数据恢复软件的授权代理商。ReclaiMe Pro 数据恢复软件专注于恢复几乎所有文件系统及各种类型和复杂程度的 RAID 阵列。
在本文中,我们介绍 ReclaiMe Pro 对于采用 SSH 连接方式的网络服务器中数据的恢复方法。
ReclaiMe…

接口测试前需要了解的网路基础知识
在面试时,不管是面试功能测试、自动化测试、测试开发以及性能测试,都会问到计算机网络基础相关知识。今天主要介绍一些高频的网络基础面试题目,如果觉得有帮助,欢迎点赞、转发、收藏三连击。
Cookie和Session的区别? …

数据结构系列-算法的时间复杂度算法效率
🌈个人主页:会编程的果子君
💫个人格言:“成为自己未来的主人~” 算法效率
如何衡量一个算法的好坏
如何衡量一个算法的好坏,比如对于以下斐波那契数列:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h&…

阿里云优惠券在哪里领取?
随着云计算技术的快速发展,越来越多的企业和个人开始选择使用云服务来满足他们的数据存储、计算、网络等需求。阿里云作为国内领先的云计算服务提供商,一直以其稳定、高效、安全的服务赢得了广大用户的信赖。而在购买阿里云产品时,使用优惠券…