前言
大家好,我是jiantaoyab,前面的文章给大家介绍了Linux的基础命令和权限,学会了命令行的模式使用Linux,今后要开始在Linux上写代码了,在这篇文章将介绍YUM、vim、gdb、git等常用的工具。
先来看看Linux如何安装软件
YUM
在Linux下,安装软件可以下载程序的源代码进行编译,得到可执行程序,但是这个过程是很复杂的,所以网上有人把软件编译好,做成软件包,放到服务器上,我们通过YUM/APT等下载下来就能用了。
这里我主要讲YUM。注意Centos,只能有一个YUM运行。
常用的选项
- -y, --assumeyes:自动回答 “yes”,跳过确认提示,用于无需人工干预地进行批量安装或更新。
- -q, --quiet:安静模式,只显示必要的输出信息,减少冗余和杂乱的信息。
- -d, --downloadonly:仅下载软件包而不进行安装,适用于在离线环境中安装软件包。
- –nogpgcheck:跳过 GPG 签名校验,允许安装未经授权或未签名的软件包。
YUM显示、搜索、查看
yum list # yum list显示所有已经安装和可以安装的程序包
yum info <package_name> #显示安装包rpm的详细信息
yum groupinfo <group_name> #显示程序组group信息
yum search #可以在所有软件包中搜索包含有指定关键字的软件包
yum deplist <package_name> # 仅仅 查看程序rpm依赖情况
yum provides */命令 # 查看命令是由哪个包提供的
比如我想查以pam开头的软件有哪些?

YUM安装、卸载、升级
#不加-y则会询问是否安装,想控制哪些包安装,则不要加-y,想自动安装不进行交互,则加-y
yum -y install <package_name>
yum clean all #命令可以清除缓存中老旧的头文件和软件包
yum remove #yum卸载
# 删除程序组group
yum groupremove <group_name>
#检查可更新的软件有哪些
yum check-update
#更新升级所有软件包
yum update
yum -y update #升级所有包同时,也升级软件和系统内核;
yum -y upgrade#只升级所有包,不升级软件和系统内核,软件和内核保持原样
#有时候需要将高版本的依赖降级到低版本,降级命令如下
yum downgrade <package_name> #降级,对于有依赖的,yum不会自动降级,需要手动降级依赖项
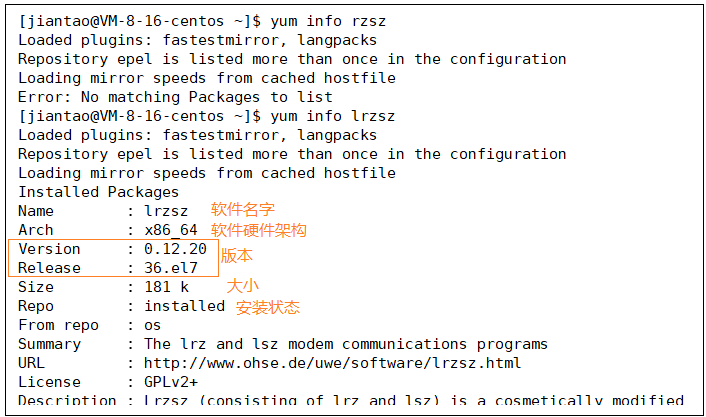
比如我想装个rzsz(这个工具用于 windows 机器和远端的 Linux 机器通过 XShell 传输文件)
先查看软件包,我这用2种方法都演示一下,第一个可以帮我们过滤很多包筛选出我们关注的包

软件包名称: 主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构.
“x86_64” 后缀表示64位系统的安装包, “i686” 后缀表示32位系统安装包. 选择包时要和系统匹配.
“el7” 表示操作系统发行版的版本. “el7” 表示的是 centos7/redhat7. “el6” 表示 centos6/redhat6.
base 表示的是 “软件源” 的名称, 类似于 “小米应用商店”, “华为应用商店” 这样的概念
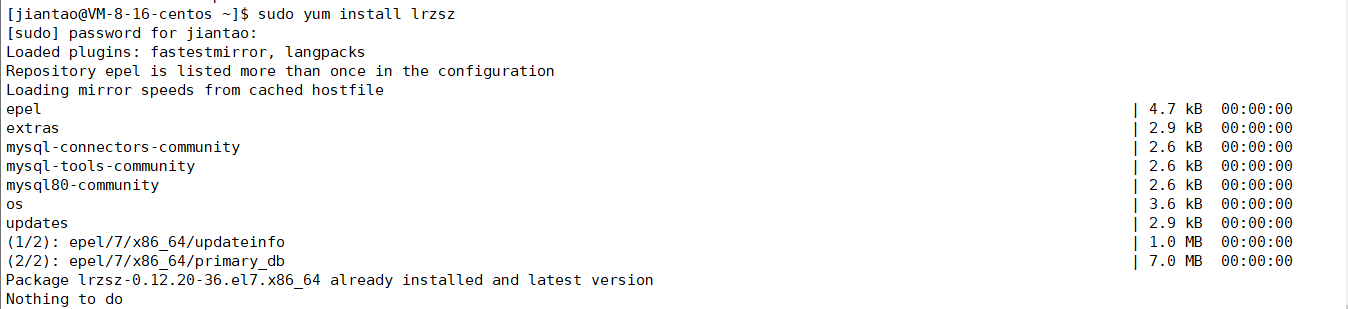
开始安装
sudo yum install lrzsz
YUM配置文件
YUM的一切信息都存储在yum.reops.d目录下的配置文件中,通常位于/etc/yum.reops.d目录下。

在这个目录下面有很多文件,都是.repo结尾的,repo文件是yum源(也就是软件仓库)的配置文件,通常一个repo文件定义了一个或者多个软件仓库的细节内容,例如我们将从哪里下载需要安装或者升级的软件包,repo文件中的设置内容将被yum读取和应用。
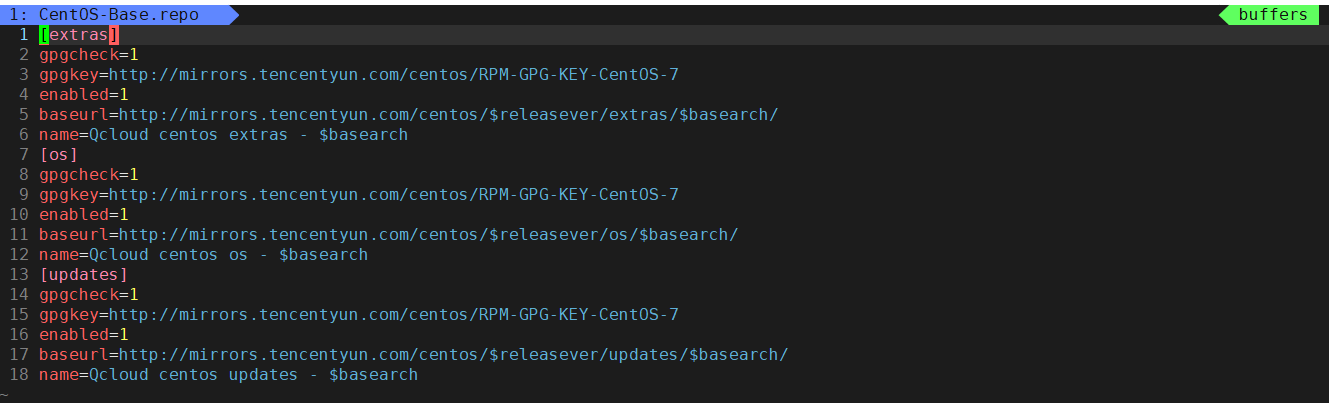

[extras]这个表示的是名称,[extras]是yum的ID,它必须唯一,本地有多个yum源的时候,这个[extras]必须是唯一的。
name:具体的yum源名字。
baseurl:是镜像服务器地址,只能写具体的确定地址。
mirrorlist:是镜像服务器的地址列表,里面有很多的服务器地址
gpgcheck=0:1是要验证,0为取消验证,使用公钥检验rpm包的正确性。
gpgcheck:是否检查软件包的GPG签名,值为1则对下载的rpm将进行gpg校验,校验密钥就是gpgkey,一般自己的yum源是不需要检测的。
gpgkey:指定GPG签名文件的URL。
YUM的主配置文件 /etc/yum.conf文件

cachedir=/var/cache/yum #yum下载的RPM包的缓存目录
keepcache=0 #缓存是否保存,1保存,0不保存。
debuglevel=2 #调试级别(0-10),默认为2
logfile=/var/log/yum.log #yum的日志文件所在的位置
Vim
Liunx绝大多数的文件是以ASCII纯文本的文件形式存在的,所以要学会用文本编辑软件修改设置、写程序文件等操作。
Vim常用的三种模式,是命令模式、插入模式和底行模式。
命令模式
先来介绍一下命令模式,因为用vim打开一个文件直接就进入了命令模式,在这个模式下可以通过键盘的[上下左右]按键或者 [H左J下K上L右]来操作光标的移动。
光标操作
| shitf + ^ | 光标定位到行首 |
|---|---|
| shitf + $ | 光标定位到h行尾 |
| gg | 移动到文件第一行 |
| G | 移动到文件最后一行 |
| nG / n + shift + g | 移动到文件第n行 |
| w/b | 以单词为单位前后光标移动 |
文本操作
| /world | ?world | 向光标之下/上找一个名为word的单词 |
|---|---|
| yy | 复制当前行 nyy 复制当前行和之后的n行 |
| p | 在下一行粘贴 P 在本行开始粘贴 np粘贴n行 |
| u | 撤销操作 |
| dd | 删除当前光标所在的行 dd p 剪切功能 |
| x | 向后删除一个字符相当于[del] |
| X | 向前删除一个字符相当于[Backspace] |
| shitf + ~ | 快速切换大小写 |
| r | 替换光标所在的字符 |
| shift + r | 进入替换模式,可以一次替换多个内容 |
| ctrl + r | 撤销刚刚的撤销 |
底行模式
在命令模式下,输入[:/ ?] 三个任何一个都能进入到低行模式。
:vs 文件名可以同时看多个文件,按ctrl + w 切换光标所在的文件

| :set no / nonu | 调出行号/取消行号 |
|---|---|
| :q | 退出vim |
| :w | 将数据写入硬盘文件中 |
| ! | 强制操作 |
| !man 函数名 | 可以不用退出vim直接查看man手册 |
插入模式
当在命令模式下按[i o a r]任意一个字符就能进入插入模式,当左下角出现[INSERT]说明进入到插入模式了,注意低行模式是不能直接切换到插入模式的。进入插入模式下就能编辑代码了。
批量化注释
- Ctrl + v 进入块选择模式,然后移动光标选中你要注释的行,再按大写的 I 进入行首插入模式输入注释符号如 // 或 #
- Ctrl + v 进入块选择模式,选中你要删除的行首的注释符号,注意 // 要选中两个,选好之后按 d 即可删除注释
Vim配置
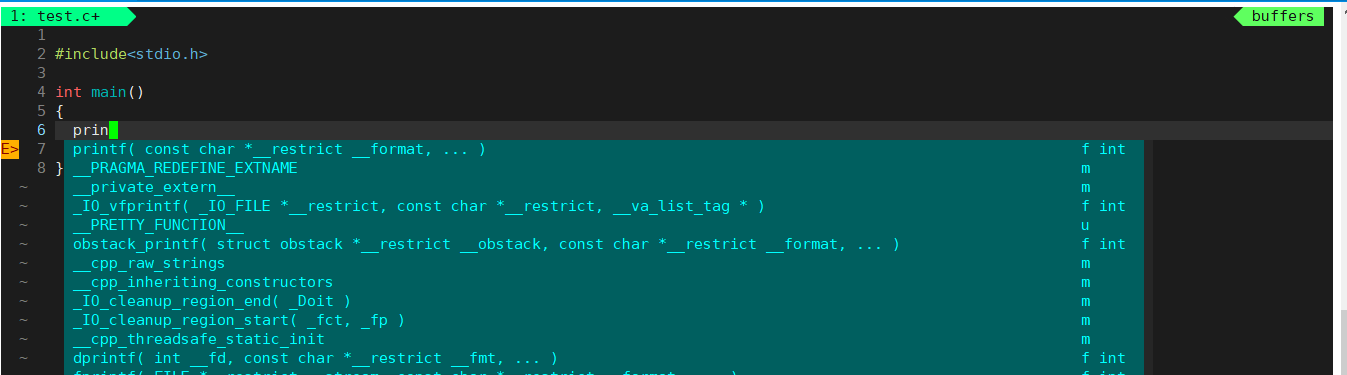
可以看到我的vim不仅看起来舒服还有语法提示,这都是经过配置的。
注意,比如我的用户是jiantao配置了vim在自己的配置文件中,只会影响我自己,vim的配置文件在.vimrc中。自己配置vim 可以使用vim .vimrc进行配置。
如果是Centos7下,大家可以用下面操作一键配置
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh
更详细的Vim使用大家可以看Vim入门到精通
Linux编译器
在vim中写好c/c++代码之后,需要将程序预处理(进行宏替换)、编译(生成汇编)、汇编(生成机器可识别代码)、连接(生成可执行文件或库文件)生成不带后缀的可执行文件加上路径才能运行程序。
我们来拆分这个过程
预处理
预处理功能主要包括宏定义,文件包含,条件编译,去注释等,预处理指令是以#号开头的代码行。
gcc –E test.c –o test.i
选项“-E”,该选项的作用是让 gcc 在预处理结束后停止编译过程

编译(生成汇编)
在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
gcc -S test.i -o test.s
#“-S”只进行编译而不进行汇编,生成汇编代码

汇编(生成机器可识别代码)
汇编阶段是把编译阶段生成的“.s”文件转成目标文件,.o是可重定向目标文件
gcc -c test.s -o test.o
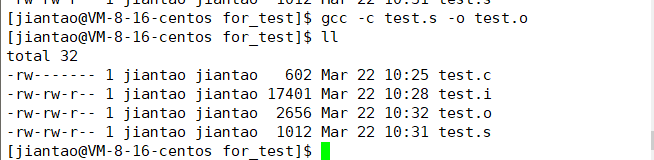
连接(生成可执行文件或库文件)
gcc test.o -o test
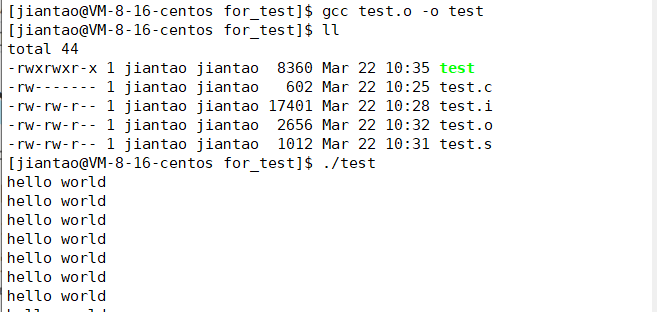
我们的C程序中,并没有定义“printf”的函数实现,且在预编译中包含的“stdio.h”中也只有该函数的声明,而没有定义函数的实现,那么在哪里实“printf”函数的呢?
系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径“/usr/lib”下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数“printf”了,而这也就是链接的作用
函数库一般分为静态库和动态库两种。
静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为“.a”
动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为“.so”,如前面所述的 libc.so.6 就是动态库。
通过file 可执行文件可以看到,gcc 在编译时默认使用动态库。
如果想要生成静态库gcc/g++的时候加上 -static,如果报错
sudo yum install glibc-static。

在Linux下一遍用g++/gcc来编译c++/c语言写的代码。
常用的选项
| -E | 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面 |
|---|---|
| -S | 编译到汇编语言不进行汇编和链接 |
| -c | 编译到目标代码 |
| -o | 文件输出到文件(给文件起个新名字) |
| static | 生成的文件采用静态链接 |
| -g | 生成调试信息。GNU 调试器可利用该信息 |
| -O0-O3 | 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高 |
| -w | 不生成任何警告信息 |
| -Wall | 生成所有警告信息 |
Linux调试器
程序的发布方式有两种,debug模式和release模式。
Linux gcc/g++出来的二进制程序,默认是release模式要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项。
启动gdb调试
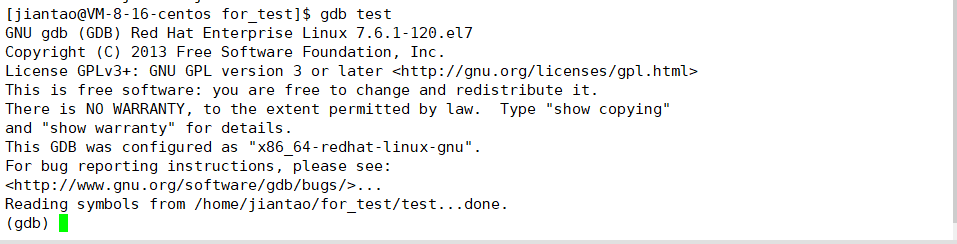
调试过程
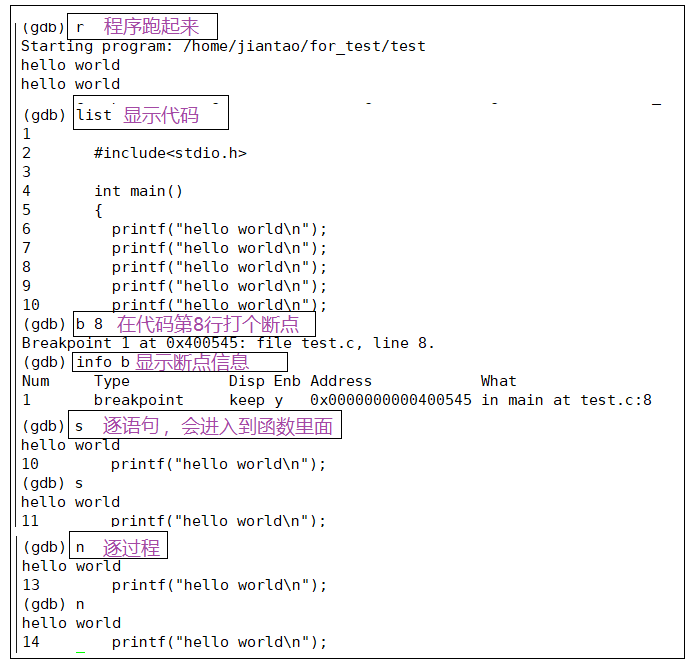
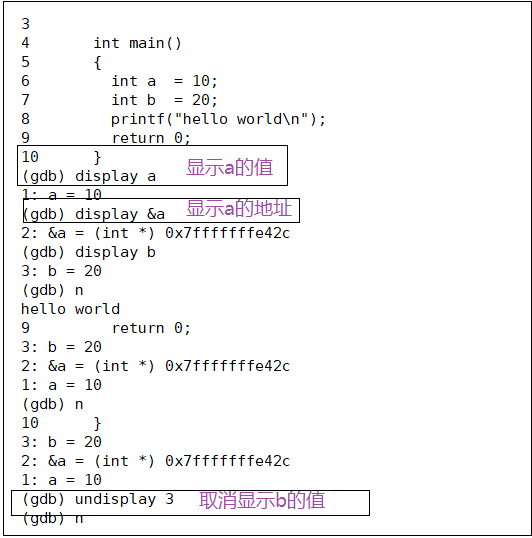
常用选项
| run | 跑起来 |
|---|---|
| list | 显示写的代码 |
| b (break) + 行号 | 打断点 |
| d + 断点的行号 | 可以删除断点 |
| disable/enable b | 禁用断点(断点还在)/启用断点 |
| s (step) | 逐语句 |
| n | 逐过程 |
| display | 常显示变量 &可以查看地址 |
| undisplay +行号 | 取消显示变量 |
| finish | 直接跑完函数 |
| until +n | 跳转到第n行 |
| info b | 查看断点信息 |
| delete b | 删除所有断点 |
| delete breakpoints n | 删除序号为n的断点 |
| info locals | 查看当前栈帧局部变量的值 |
| quit | 退出gdb |
Makefile
Make原理
执行make的时候,make会在当前路径下去找Makefile,Makefile记录了源代码如何编译的详细信息。如果找到,它会找文件中的第一个目标文件(target),并把这个文件作为最终的目标文件。
如果文件不存在,或是所依赖的后面的文件的文件修改时间要比这个文件新,那么,他就会执行后面所定义的命令来生成文件。make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那make就不工作了。
我们来看看Makefile怎么编写,在后面的代码中我将都会写Makefile。
//目标:依赖文件
file:file.c
gcc file.c -o file -std=c99 //必须以Tab开头
//后面我们一般这么写 gcc -o $@ $^
.PHONY:clean
clean:
rm -rf file
make扫描makefile文件的时候,默认只会生成一个目标依赖关系,一般是第一个,所以直接make就能编译文件,而清理文件要加上make clean;
.PHONY 修饰的是一个伪目标的概念,就是总是能被执行,你会发现无论make clean多少次都是可以的,但是make只会生成一次,除非有修改。
一次形成2个可执行程序
.PHONY:all
all:myexe myexec
myexe:myexe.c
gcc -o $@ $^
myexec:myexec.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -rf myexec myexe
进度条
说了那么多,我们来编写一个进度条程序。
#include<stdio.h>
#include<unistd.h>
#include<string.h>
int main()
{
char buffer[100];
memset(buffer, '\0', sizeof(buffer));//初始化
const char* lable="\\|/-";
int i=0;
while(i<=100)
{
//-100s 预留100个空间 -向左对齐
buffer[i++]='#';
printf("[%-100s][%d%%][%c]\r",buffer, i, lable[i%4]);
fflush(stdout);//刷新到显示器上
sleep(1);
}
printf("\n");
return 0;
}
效果

Git
在Window下,我们经常运用Git,同样的Linux下也可以。

这里教大家用git在linux下传东西到gitee
大家先创建一个仓库,在克隆/下载复制https
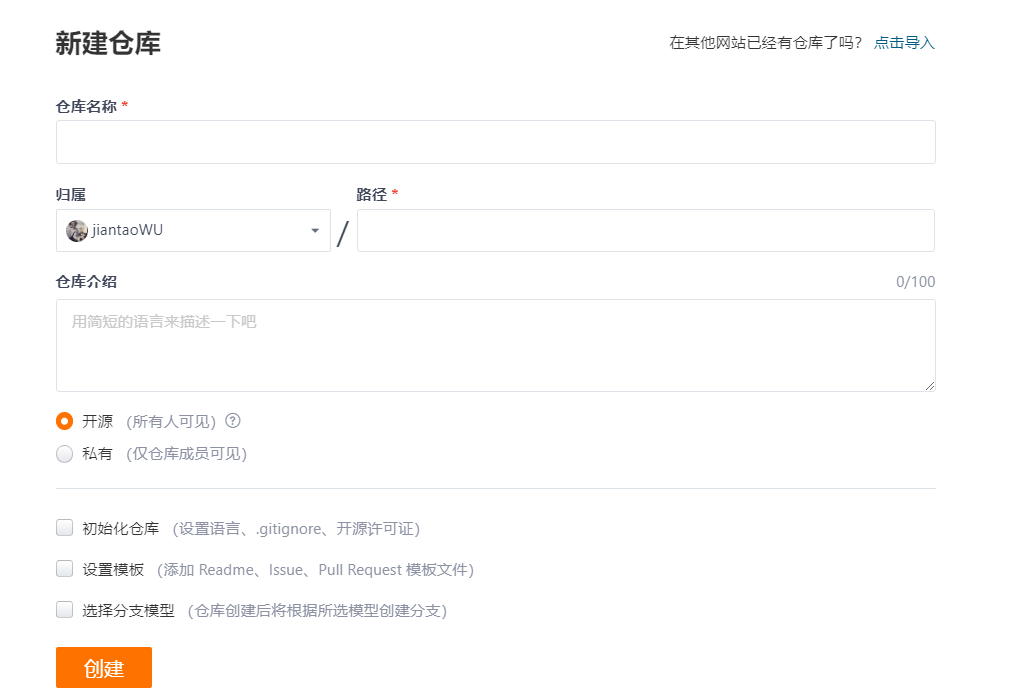
在Linux输入git clone 复制的https,这个时候,在当前的路径下就会多出一个文件夹,这个文件夹就是远端仓库。
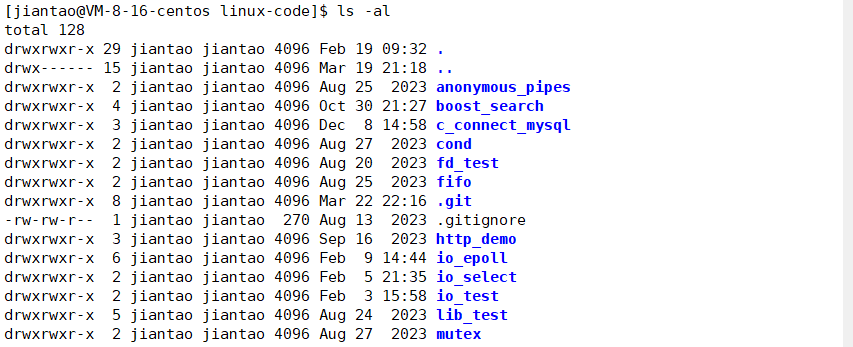
在.gitignore出现的后缀文件都不会上传到远端
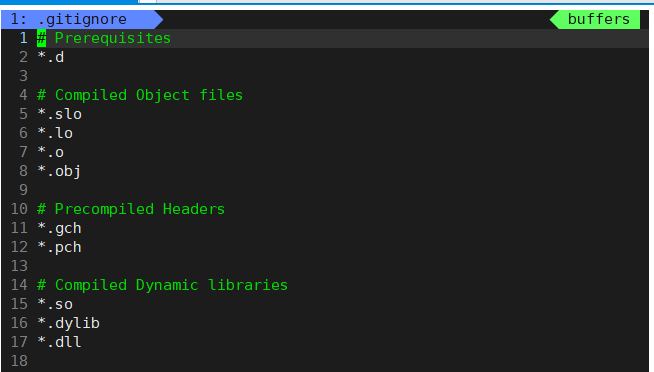
git status 查看状态
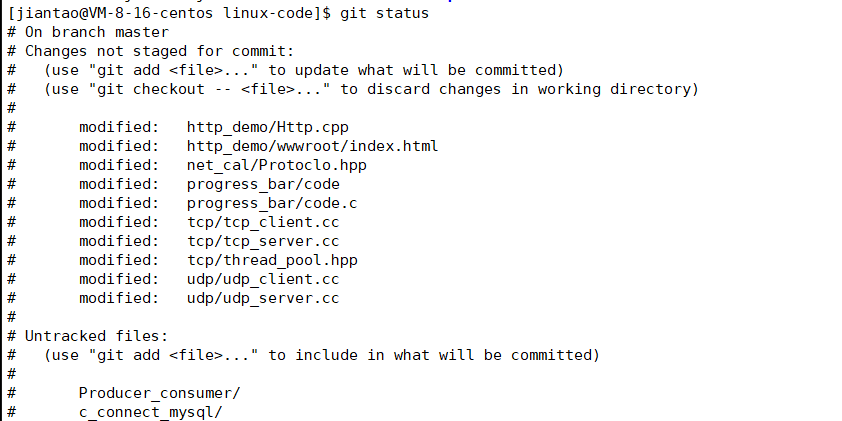
先告诉git 你是谁
git config --global user.email "you@example.com"
git config --global user.name "Your Name"
上传文件步骤
git add
git commit -m ""
git push
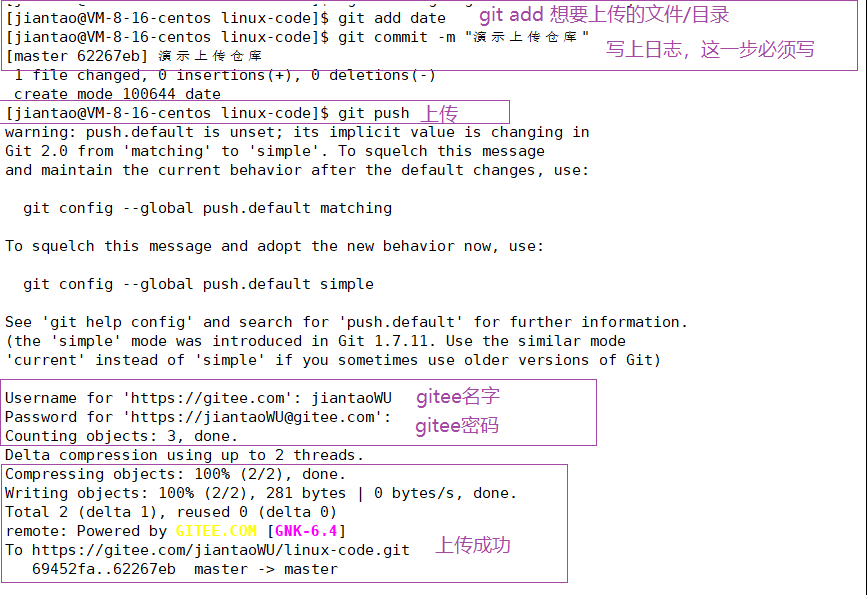
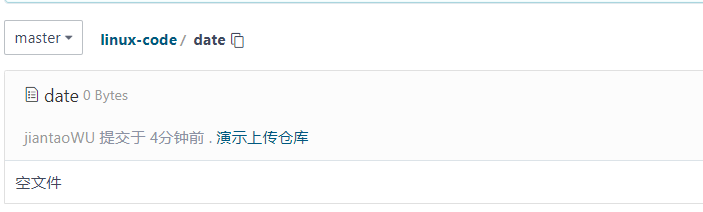
上传成功后,就能在gitee上看到上传的文件
更详细的git教程大家可以看git中文教程