目标检测之Fast R-CNN论文精讲,Fast RCNN_哔哩哔哩_bilibili
一 引言
1.1 R-CNN和SPPNet缺点
😀R-CNN

Training is a multi-stage pipeline
多阶段检测器(两阶段和一阶段检测器) 1️⃣首先训练了一个cnn用来提取候选区域的特征,这个cnn训练好后再提取整个数据集上所有区域的特征;
2️⃣然后利用特征来额外训练一个svm网络来对候选区域进行分类。
如果是RCNN-BB算法,还会3️⃣额外训练一个框回归的模型来回归出候选框的精确位置。
Training is expensive in space and time
在训练svm和框回归模型的时候,需要把每一张图片上的每一个候选框的这个特征都提取出来,这些特征都被提取出来后才能训练后续的模型;
所以利用cnn提取到这个特征,需要先把它写到磁盘里供后续训练使用;
所以在训练过程中会耗费大量的空间来存特征、会耗费大量的时间来提取特征
Object detection is slow
对于一张测试图片RCNN也需要先产生2000个候选区域,每个候选区域都需要通过cnn的前向传播来提特征; 因此测试一张图片的速度也会特别慢,导致一张图的测试时间可能会达到47秒。
😅因为R-CNN需要使用一个cnn来前向传播,提取每一个候选区域的特征,没有用到共享计算;因此后续提出的SPP-net这个网络,就尝试通过共享计算来加速r cnn的训练和测试过程;
😲RCNN ---> SPP-Net
在SPP-Net可以只用把一整张图传进去给cnn,然后在cnn里只使用这一整张图进行一次前向传播,计算整张图的一个特征图,最后再把各个候选区域的特征给抠出来就可以了,也就是在整张图上共享计算;
否则在R-CNN里,还需要先产生2000个候选区域,每个候选区域都需要通过cnn的前向传播来提特征;
SPP-Net优化了R-CNN第三个缺点;
😆SPP-Net
它的核心其实就是引入了一个这个spp层,也叫空间金字塔池化(SPP和ASPP)层。 这个空间金字塔池化层的尺寸和步长是一个动态变化的过程 它会根据你输出特征图的尺寸来动态的改变尺化合的尺寸和步长;

在得到4x4大小、2x2大小和1x1大小的一个特征图之后,再把这些特征给拼接起来,形成了一个固定长度的一个特征,然后再把这个特征传给后续的全连接层形成最终的一个候选区域的图片特征;
1️⃣但SPP-Net仍是一个多阶段过程;
2️⃣But unlike R-CNN, the fine-tuning algorithm proposed in [11] cannot update the convolutional layers that precede the spatial pyramid pooling
SPP-Net的微调很难更新卷积层
1.2 Fast-RCNN优势

- 比RCNN和SPPNET具有更高的一个检测精度
- 它的训练过程是一个单阶段的过程
- 训练能更新所有的网络层,而不像sppnet不能更新卷积层
- 由于训练过程变成单阶段了,所以不需要额外的磁盘空间来缓存特征
二 Fast R-CNN模型结构和训练流程
模型结构

😺对于一整张输入图片,会先通过一个深度卷积神经网络来得到整张图片的图片特征; 😸根据候选区域在原图上的一个图片位置,使用ROI投影来获取到候选区域; 😹有了候选区域的特征图之后,再通过ROI池化层把尺寸不固定的候选区域特征图给转换成特定尺寸的一个特征图; 😻再接上两个全连接层来得到每一个区域的特征向量; 😼再额外接上两个并行的全连接层,其中一个利用soft max函数负责预测类别, 😽另一个直接预测和框坐标相关的一个框回归; 🙀这个预测类别的分支输出k加一个数据集的类别,另外加上一个背景类; 😿预测坐标的分支直接输出4*(k+x),也就是每个类别对应的坐标;
vs spp-net
😈是SPP-NET在最后一个卷积层后面跟上的是一个空间金字塔池化,但是Fast-RCNN在最后一个卷积层后面跟上的是一个ROI池化层;
👽SPP-NET它在提取到候选区域的特征之后,像RCNN一样额外训练支持向量机进行分类或回归; 但是Fast-RCNN在是后面直接接了两个并行的全连接层实现分类和回归;
2.1 ROI 池化层
The RoI pooling layer uses max pooling to convert the features inside any valid region of interest into a small feature map with a fixed spatial extent of H × W (e.g., 7 × 7), where H and W are layer hyper-parameters that are independent of any particular RoI.
它能将任意有效的候选区域内的这个特征给转化成一个小的特征图并且这个小的特征图具有特定的一个空间范围;
它本质上就是使用最大池化把不规则的一个特征图给转换成一个特定尺寸的输出;
只不过在这个空间金字塔池化层这里它是分别使用了三个不同的磁化来得到三个不同大小的一个输出;
但是在FAST-RCNN这里作者只用了一个池化来得到一个输出
The RoI layer is simply the special-case of the spatial pyramid pooling layer used in SPPnets [11] in which there is only one pyramid level
它仅仅是空间金字塔池化层的一种特殊情况,因为金字塔池化层是有三个输出,但是ROI层在这里它只有一个输出;
2.2 从预训练模型中初始化一个Fast-R-CNN
作者试验了三个预训练的imagenet网络,每个网络都具有五个最大池化层,并且具有5到13个卷积层;(这三个预训练模型的具体结构会在4.1小节给详细列出)
这里的预训练网络其实指的就是在imagenet上预训练好的一个图像分类模型, 预训练的分类模型一般都是这种结构: 🙈先传入一整张图片给一个深度卷积网络; 🙉这个深度卷积网络会得到这一整张图片的一个特征图,然后接上一个固定尺寸的最大池化层,来对这一个特征图做最大池化; 🙊再接上几个全连接层; 🙉最后再跟上一个全连接层和soft max函数来输出image net数据解上的1000个图像类别;


这里的这个初始化,它指的其实就是把一个预训练的一个图像分类网络 给变成Fast-RCNN网络的一个过程; 也就是从上面这个模型变成下面这个模型的过程:
🤖三个变换阶段
First, the last max pooling layer is replaced by a RoI pooling layer that is configured by setting H and W to be compatible with the net’s first fully connected layer (e.g., H = W = 7 for VGG16).
第一步先把最后的一个最大池化层给替换成ROI池化层
Second, the network’s last fully connected layer and softmax (which were trained for 1000-way ImageNet classification) are replaced with the two sibling layers described earlier (a fully connected layer and softmax over K + 1 categories and category-specific bounding-box regressors).
第二步是把最后的一个全连接层和soft max层给替换成了两个并行的全连接层;
其中一个分支用来预测k加一个类别;
另一个分支用来预测边界框回归;
Third, the network is modified to take two data inputs: a list of images and a list of RoIs in those images.
第三步是把网络给修改成了两个数据输入;
除了输入图片外还需要输入图片中的一系列候选区域坐标,以便于你在最终的这个特征图中根据这个候选区域的坐标把这个候选区域的特征给抠出来
2.3 在检测任务上进行微调
微调模型它其实就是使用反向传播来训练整个网络的一个权重
🤔为什么Fast-RCNN有很好的训练权重能力,SPP-NET却不能?
答:这涉及到训练过程中样本的一个采样方法;
在模型训练时,需要一批一批的图片喂给这个卷积神经网络,一次会传入多张图片。在反向传播更新权重的时候,是需要利用你正向传播得到的中间每一层的值去更新权重的;
🐵SPPNet The root cause is that back-propagation through the SPP layer is highly inefficient when each training sample (i.e. RoI) comes from a different image, which is exactly how R-CNN and SPPnet networks are trained. The inefficiencystems from the fact that each RoI may have a very large receptive field, often spanning the entire input image. Since the forward pass must process the entire receptive field, the training inputs are large (often the entire image).
在训练时,因为一批样本它是通过随机采样得到的,比如需要128个候选区,这128个区域它可能是来自不同的图片,也就是说你需要传入128张这种类似的原图进去; 然后在128个特征图中各自抠出各自所需要的这个后面区域; 在前向传播和反馈传播的过程中,会占用大量的显存,降低模型的训练效率;
🐶FAST-RCNN In Fast RCNN training, stochastic gradient descent (SGD) minibatches are sampled hierarchically, first by sampling N images and then by sampling R/N RoIs from each image. Critically, RoIs from the same image share computation and memory in the forward and backward passes. Making N small decreases mini-batch computation. For example, when using N = 2 and R = 128, the proposed training scheme is roughly 64× faster than sampling one RoI from 128 different images (i.e., the R-CNN and SPPnet strategy).
在FAST-RCNN的训练过程中,随机梯度下降Stochastic Gradient Descent(SGD)的这个mini-batch它是通过一种按层抽样的方法;
以N等于二,R等于128为例: 🙋会首先采样两张图片; 🙋♂️然后在每张图片上各自采样64个候选区域;
👍这样做的好处就是每次在前向传播的时候,只能传两张图片进去就可以了; 因为每张图片的64个区域都是在一张图上去得到的,所以说你只需要两张原图传进去,然后在两张原图的特征图上各自扣出64个候选区域就可以了;
而不是像SPP-Net一样需要去传入128个原图,大大提升了训练效率
🥳训练时的多任务损失函数
Multi-task loss

Fast-RCNN是有两个并行的输出层;
第一个输出用来产生k加一个类别; 其中p0 表示某个候选区域是背景类的概率; p1到pk表示属于k数据集类别的概率;
第二个分支输出是一个框回归的一个偏移量; 它预测出来的tx和ty表示框的中心点归一化后的偏移量; tw和th表示跟边界框的宽和高相关的一个值;
p和t都是每个候选区域的预测值;
求损失函数的时,除了要有预测值之外,还需要有一个提前标注好的一个目标值,也就是ground truth;
这里把标注好的候选区域类别给用u符号表示; 把边界框回归的目标值给定义成v这个符号;
😘类别损失公式:

λ [u≥1 ] 一般等于1。 它表示只有当目标类别是≥1的时候,值才等于一; 表示需要求这个回归损失,如果u等于零,就表示这是一个背景类,这个值也就是零,所以最后回归损失就是零,因为背景类它是没有预测框的,也就不需要去求后边这个回归损失。
😲**类别损失函数:

😊**框回归损失函数:


🤡vs RCNN smoothL2
![]()
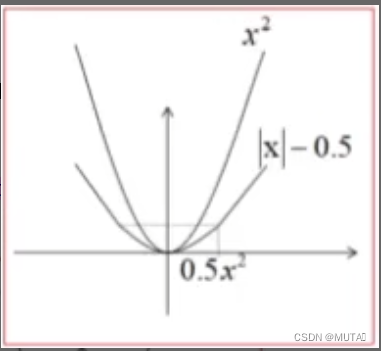
假如使用L2损失,这条曲线是可以向两端无限延伸,如果预测出来的这个预测值和目标值偏差过大的话,即x过大,导致smooth值一直无限的往上延伸;
在图像上,斜率其实就是梯度,当无线往上延伸的时候,这个梯度就会趋向于无穷大,最终会产生梯度爆炸现象,没法训练;
所以这个smooth L1损失它在x≥1时,等于|x|-0.5,它的梯度恒等于1,相当于是给梯度设置了一个上限,不会再像L2损失一样产生梯度爆炸;
当x绝对值小于一的时候,多乘了一个0.5系数,是为了让这个分段函数在 x=1的这个点两端的一个梯度值连续;
👻Mini-Batch采样策略
Mini-batch sampling
在微调期间,每个随机梯度下降的mini batch都先随机去采样了两张图片; 然后在每个图片上在采样64个候选区域; 这样就构成了一个128个候选区域的一个mini batch;
在这128个候选区域里有25%,也就是32个候选区域是正样本; 剩下的96个候选区域是负样本;
正样本的采样方法跟 RCNN一样,以IoU≥0.5来作为正样本; 在剩下的候选区域里,IoU在0.1~0.5之间的候选区域作为负样本; 对于阈值低于0.1的样本,都采用难例挖掘 hard negative mining的这种方法来挑选难样本进行训练;
在训练期间,每张图片都随机的以0.5的概率去做水平翻转;
🤢RoI池化层的反向传播公式
Back-propagation through RoI pooling layers 这里假设只使用一张图,也就是mini batch的N=1来进行推导; N=1就表示在一张图上取出了128个候选区域,通过ROI池化层,而不像之前一样使用两张,一张取出64个候选区域。
这里假设只使用一张图,也就是mini batch的N=1来进行推导; N=1就表示在一张图上取出了128个候选区域,通过ROI池化层,而不像之前一样使用两张,一张取出64个候选区域。
举例:

在这张图上一共取出来了128个候选区域的一个特征图,这个特征图是其中第二个候选区域的特征图; 假设它是一个7x7大小的一个特征图,假如使用了一个3x3步长为二的一个最大池化; 对这个特征图进行操作,通过池化处理以后会得到一个3x3的输出特征图;
这里的这个xi指的就是输入特征图上的每一个位置的一个元素值;
这里的y r j表示的就是输出输出特征图上的每一个位置的一个元素值,也就是第二个特征图上的这个输出;
y rj的这个值是通过在池化和的范围内挑选出最大的那一个值,然后得到的这个位置的值; ![[Fast R-CNN.pdf#page=3&rect=466,90,530,100&color=note] 这里的Xi*, 小括号指的就是这个石化和覆盖区域内的最大值; 所以这个值和这个值是相等的. 反向传播公式:
反向传播公式:
👾训练过程的超参数
SGD hyper-parameters.
The fully connected layers used for softmax classification and bounding-box regression are initialized from zero-mean Gaussian distributions with standard deviations 0.01 and 0.001, respectively. Biases are initialized to 0. All layers use a per-layer learning rate of 1 for weights and 2 for biases and a global learning rate of 0.001. When training on VOC07 or VOC12 trainval we run SGD for 30k mini-batch iterations, and then lower the learning rate to 0.0001 and train for another 10k iterations. When we train on larger datasets, we run SGD for more iterations, as described later. A momentum of 0.9 and parameter decay of 0.0005 (on weights and biases) are used.
全连接层初始化的时候,使用了一个零为均值,然后0.01或者0.01为标准差的高斯分布来初始化,偏差项被初始化为零;
设置了一个学习率以及这个权重衰减的一个值;
2.4 目标的尺度不变性
尺度不变性指的就是有两个相同的目标,一个目标比较大,一个目标比较小,如果这两个目标都能够被模型识别出来,就说明这个模型具有比较好的尺度不变性。
作者设计了两种方法:
1️⃣brute-force approach
可以把它理解成单尺度训练。
在单尺度训练过程中,每一张图片都被处理成了一个预定义好的图片尺寸来进行训练或者进行预测;
他的目的是让网络来直接学会尺度不变形
2️⃣multi-scale approach
多尺度方法。
在训练期间,每一张图片都先被随机采样成一个特定的尺度,而不是像第一种一样采用一个预定义的固定尺度;
这种多尺度的训练方法也是一种数据增强的方式
👋这两种方法在第五章有实验结果做对比。
三 Fast-RCNN测试流程
一旦fast cn的网络被微调好后就可以进行目标检测,整个网络只需要接收两个输入,分别是一张图片和这个图片中的一系列目标候选区域,就能够预测出候选区域的类别和精确坐标。
3.1 奇异值分解方法加速检测
For whole-image classification, the time spent computing the fully connected layers is small compared to the conv layers. On the contrary, for detection the number of RoIs to process is large and nearly half of the forward pass time is spent computing the fully connected layers (see Fig. 2).
对于图像分类任务来说,花费在全连接层上的时间比花费在卷积层上的时间要小;
相反的对于检测任务来说,由于ROI的数量非常的大,因此几乎一半前馈传播时间都被花费在了计算全连接层上;
这是因为在测试一张图片的时候只需要通过一次前馈传播把这一整张图的一个特征图给提取出来就可以;
但是在后面进行全连接层运算的时候,需要把这一张图上所有的候选区域抠出来后的候选区域特征图都通过后面的全连接层去进行运算;
所以全连接层会占据大量的一个测试时间
👏大的全连接层的一个加速方法就是通过截断奇异值分解 Truncated SVD方法
🧙♂️奇异值分解SVD: ![]()

🎅截断奇异值分解 Truncated SVD: 中间的这个对角矩阵有一个性质,就越靠近左上角的这个值越重要,越靠近右下角的这个值越不重要,既然右下角的这个值不重要,就可以直接把这些值给去掉。
🤸相当于只保留左上角一部分变成一个t乘t的矩阵; 🤸♂️相应的前面这个矩阵就把最后这几列给去掉变成u乘t的一个矩阵 🤸♀️后面这个矩阵就把最后的这几这几行给去掉就变成一个t乘v的一个矩阵 相当于对原始的这么一个u乘v的矩阵做了一个压缩

在全连接层中,它本质上就是让参数矩阵w和一个输入特征x去进行相乘;
把单个全连接层w给替换成两个全连接层;
这两个全连接层中的第一个是使用了一个权重矩阵![]() ;
;
第二个使用这个![]() 来作为权重矩阵;
来作为权重矩阵;

左边的这个全连接层用右边两个更小的全连接层近似替换了;
替换前左边的这个参数是u乘w的参数; 右边压缩后的参数其实是u乘t加上一个v乘t;
右边这个压缩的力度越大,右边的这个参数是越小的;参数越少;模型的运行速度就会越快
所以说通过这种截断的奇异值分解法,可以提高全连接层的一个推理速度
四 主要结论
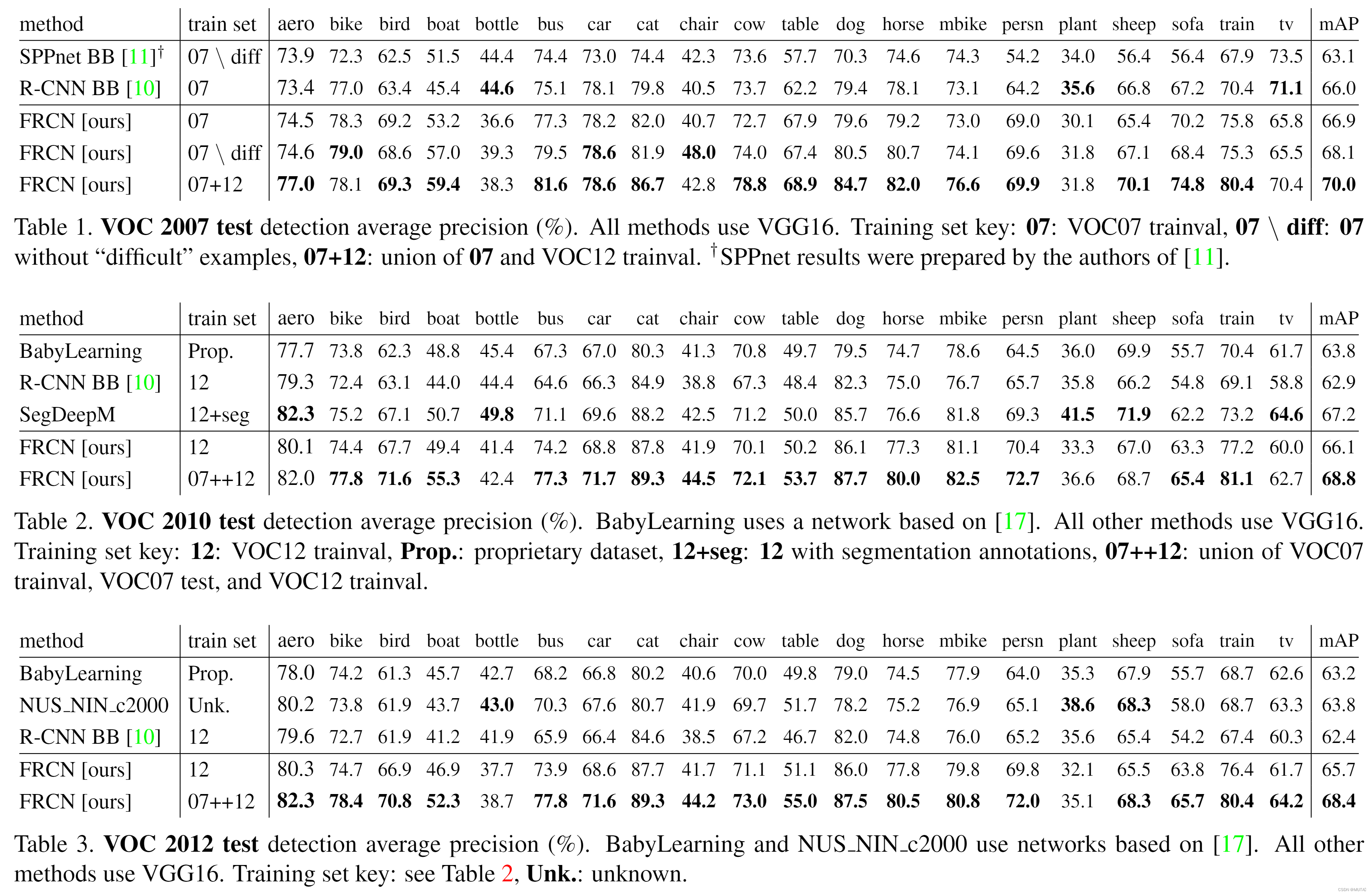
 😇fast-rcnn在三个数据集上都取得了一个最优的一个平均精度 😎与RCNN和SPPNET相比,Fast-RCNN具有更快的训练速度和测试速度 😲在VGG-16上微调卷积层能够提高模型的平均精度
😇fast-rcnn在三个数据集上都取得了一个最优的一个平均精度 😎与RCNN和SPPNET相比,Fast-RCNN具有更快的训练速度和测试速度 😲在VGG-16上微调卷积层能够提高模型的平均精度
4.1 实验配置
作者使用了三个预训练的ImageNet模型:
🤗第一个模型是RCNN的CaffeNet模型 它本质上是使用了一个AlexNet这个模型,作者额外给它起了一个名字 也就是model-s(其中这个s就表示small的意思)
😌第二个模型是使用了 VGG CNN M 1024 这个模型 这个模型它和model s具有相同的一个模型深度,但是它更宽一些,所以也所以就给这个模型起名为model m() m就是medium的意思)
🤣最后一个网络模型就是非常深的这个 VGG16模型,由于第三个模型是最大的一个,所以就给它起名为model L (L就表示large的意思)
所有的实验都使用单尺度训练和单尺度预测,也就是说模型在训练和预测时输入的图片尺寸都被固定成了600大小;