前言
合理使用日志对于Java应用程序的开发、部署和维护都至关重要。通过采用良好的日志记录实践,可以更好地监控应用程序的运行状况、排查问题并优化性能
日志系统与日志框架
日志系统
直接负责打印输出日志,提供完整的日志输出能力:
JUL
java.util.logging.*,java自带的日志系统简称JUL。目前除了Java自身代码很少被生态系统类库使用。
简介
Java Logging API是Java标准库中内置的日志框架。它提供了基本的日志记录功能,但被认为相对简单和有限。它包括以下主要组件:
Logger对象: 用于记录日志消息。
LogRecord对象: 表示一条日志记录。
Handler对象: 负责处理和发送日志记录到不同的目的地,如文件、控制台等。
Level对象: 定义日志记录的级别(SEVERE、WARNING、INFO、CONFIG、FINE、FINER、FINEST)。
Filter对象: 用于过滤日志记录。
Log4j
https://logging.apache.org/,目前已经发展到2.x版本(2.x版本有超越logback的趋势),早期的1.x版本非常成功。开创日志系统模型(Logger\Appender\Level等概念)并被各种日志框架采用,且一直沿用至今
log4j可直接使用,也可配合日志框架一起使用
简介
Log4j是Apache软件基金会的一个开源日志框架,曾经是Java应用程序中最流行的日志解决方案。它提供了比Java Logging API更丰富的功能,包括:
支持多种日志输出目标,如文件、数据库、控制台、远程套接字等。
支持日志文件滚动和压缩。
支持日志级别的继承和过滤。
支持日志格式化和参数化日志消息。
支持日志上下文(MDC和NDC)。
Logback
http://logback.qos.ch/,Log4j作者的另一个作品,(比Log4j1.x新,Log4j2.x旧)吸取多年经验教训重新设计的一套日志系统,使用更方便、功能更强、性能更好。
logback不能单独使用,需配置日志框架SLF4J一起使用
Logback是Log4j的继任者,由同一个作者开发。它构建在相同的核心代码之上,但修复了Log4j的一些缺陷,并提供了更好的性能和更多功能。Logback完全实现了SLF4J(Simple Logging Facade for Java)API,因此可以无缝地集成到使用SLF4J的应用程序中
日志框架
为了克服各种日志系统标准混乱,诞生了日志框架,日志框架不提供日志输出的功能,它定义标准,提供标准接口API,日志框架+日志系统=输出日志。
写代码过程中使用日志框架的好处:编码的时候调用日志框架API,部署的时候可根据不同的环境在多种日志系统中随意切换。
- JCL
https://commons.apache.org/proper/commons-logging/,前几年最流行的日志框架,由Apache社区维护,大量的老牌知名框架版本都在使用,比如Spring(甚至新版本依然在使用)。
Apache Commons Logging是Apache软件基金会的日志抽象层,类似于SLF4J。它提供了一个通用的日志接口,可以绑定到不同的日志实现,如Log4j、java.util.logging等。
- SLF4J
https://www.slf4j.org/,Log4j作者推出,这几年最流行的日志框架,特别是配合Logback使用。
当然也可以配合log4j使用
SLF4J不是一个真正的日志实现,而是一个抽象层,为各种日志框架(如Log4j、Logback、java.util.logging等)提供了一个统一的API接口。这使得应用程序可以在不同的日志框架之间进行切换,而无需修改日志语句。
目前在Java生态趋势主要是使用:SLF4J+Logback组合。
如何正确组合使用日志系统和日志框架
日志系统之间互斥
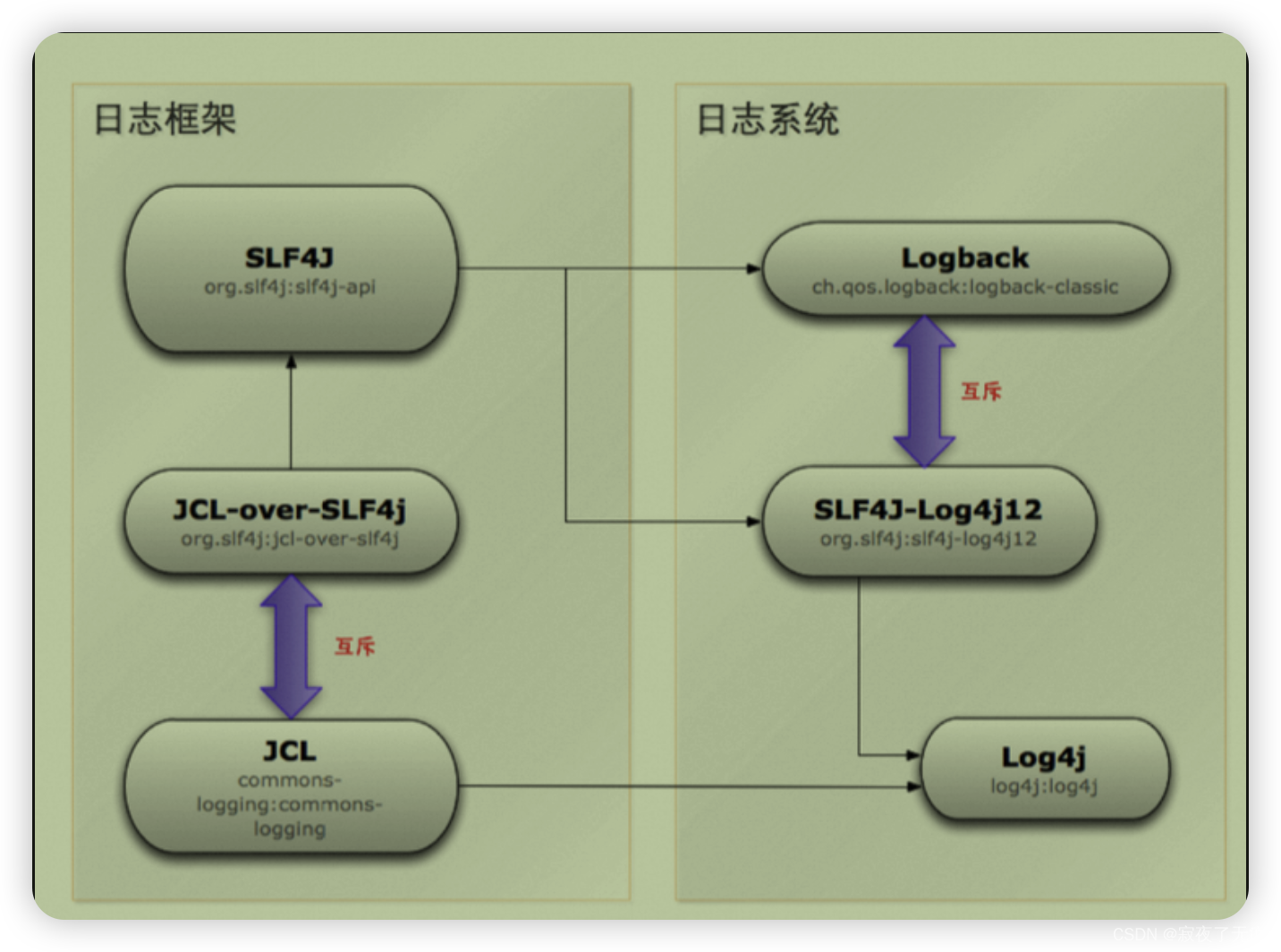
- 日志框架:JCL和JCL-over-SLF4J桥接包直接互斥
- 日志系统:logback和slf4j-log4j12互斥,不能共存
我们大概可枚举出如下几种组合:

slf4j+logback组合
下面列出一个正确的slf4j+logback依赖,这个环节很重要,很多应用因为依赖搞不清楚经常出现日志丢失问题:
<properties>
<slf4j.version>${xxxx}</slf4j.version>
<logback.version>${yyyyy}</logback.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>999-not-exist</version>
</dependency>
<dependency>
<groupId>com.alibaba.external</groupId>
<artifactId>jakarta.commons.logging</artifactId>
<version>999-not-exist</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>999-not-exist</version>
</dependency>
<dependency>
<groupId>com.alibaba.external</groupId>
<artifactId>org.slf4j.slf4j-log4j12</artifactId>
<version>999-not-exist</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>999-not-exist</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>999-not-exist</version>
</dependency>
<dependency>
<groupId>com.alibaba.external</groupId>
<artifactId>org.slf4j.slf4j-simple</artifactId>
<version>999-not-exist</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>999-not-exist</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-ext</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jul-to-slf4j</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>${logback.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-ext</artifactId>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jul-to-slf4j</artifactId>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>log4j-over-slf4j</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
</dependency>
</dependencies>
-
先将依赖全部写在节点中,这样可影响间接依赖,如果只当初的使用dependencies节点,只会应用直接依赖
-
使用999-not-exist这样的版本:欺骗maven,直接依赖一个空包占位,这样Maven就不会再去依赖相同坐标的真实依赖,间接起到排包的作用
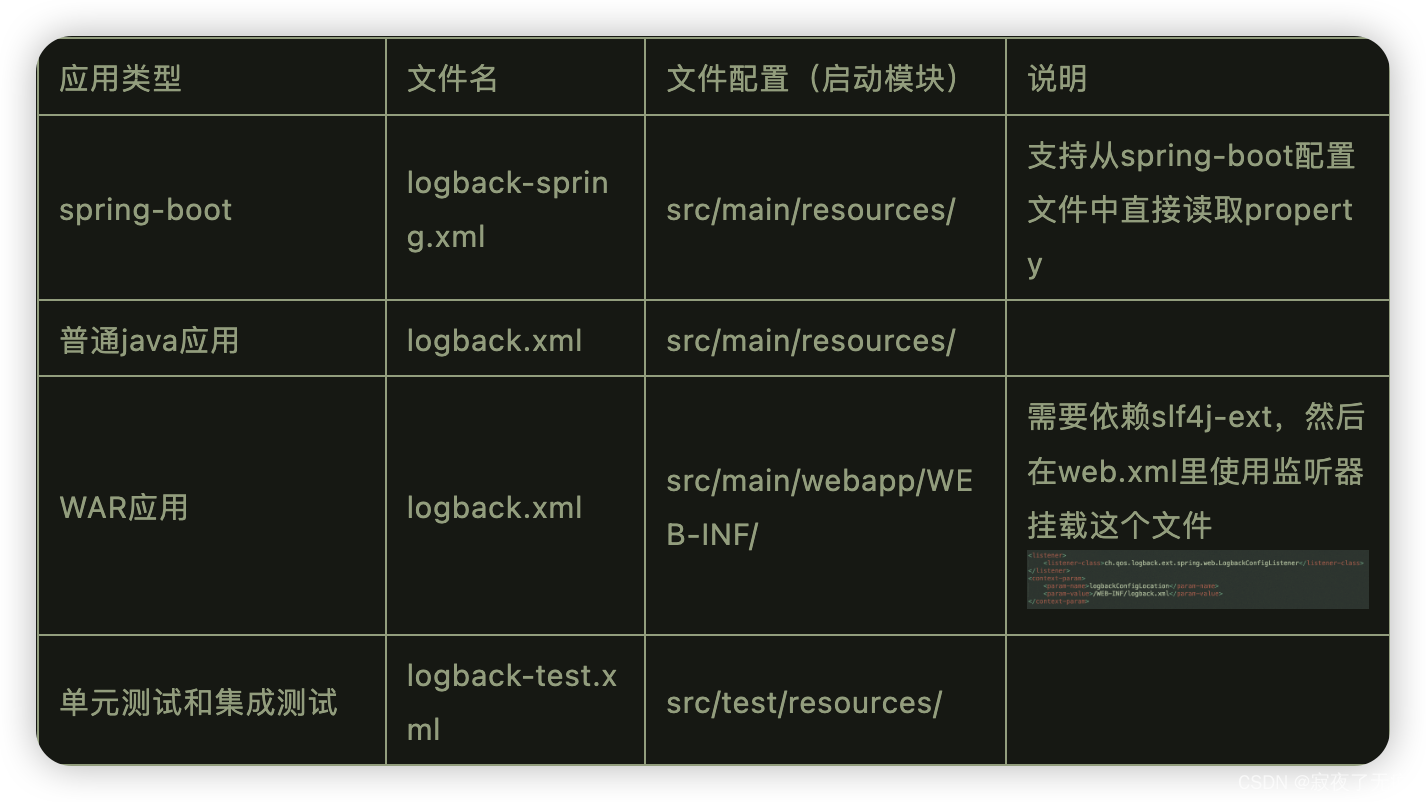
logback配置
文件名和位置
配置样例
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="APP_NAME" value="demo1" />
<property name="LOG_PATH" value="${user.home}/${APP_NAME}/logs" />
<property name="LOG_FILE" value="${LOG_PATH}/application.log" />
<property name="LOG.PATTERN" value="%d %-5level %X{EAGLEEYE_TRACE_ID} %logger{5}[%L] - %msg%n"/>
<property name="LOG.CHARSET" value="UTF-8"/>
<appender name="APPLICATION"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<encoder>
<pattern>${LOG.PATTERN}</pattern>
<charset>${LOG.CHARSET}</charset>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxHistory>7</maxHistory>
<maxFileSize>50MB</maxFileSize>
<totalSizeCap>20GB</totalSizeCap>
</rollingPolicy>
</appender>
<logger name="org.springframework" additivity="false">
<level value="error"/>
<appender-ref ref="APPLICATION"/>
</logger>
<logger name="com.ibatis" additivity="false">
<level value="error"/>
<appender-ref ref="APPLICATION"/>
</logger>
<logger name="org.mybatis" additivity="false">
<level value="error"/>
<appender-ref ref="APPLICATION"/>
</logger>
<logger name="java.sql" additivity="false">
<level value="error"/>
<appender-ref ref="APPLICATION"/>
</logger>
<logger name="sqlMonitor" additivity="false">
<level value="error"/>
<appender-ref ref="APPLICATION"/>
</logger>
<logger name="com.taobao" additivity="false">
<level value="error"/>
<appender-ref ref="APPLICATION"/>
</logger>
<logger name="com.alibaba" additivity="false">
<level value="error"/>
<appender-ref ref="APPLICATION"/>
</logger>
<logger name="com.alibaba.example.demo" additivity="false">
<level value="info"/>
<appender-ref ref="APPLICATION"/>
</logger>
<root level="error">
<appender-ref ref="APPLICATION" />
</root>
</configuration>
- 使用SizeAndTimeBasedRollingPolicy使日志可以根据大小和日期进行滚动
- 日志编码请使用UTF-8
- 请正确使用日志级别,不要统统输出error
日志级别根据不同环境可配
- 如果是Pandora-boot或spring-boot可以直接在配置里使用property读取application.properties,application.properties在不同环境下使用-Dspring.profiles.active进行切换
- 普通应用和WAR应用:请使用autoconfig-maven-plugin插件
一些实用的日志技巧
1. 动态修改日志级别
场景:应用在运行中,默认日志配置的打印级别是error,但是我现在想针对某个包或者某个类输出下info日志。
使用Arthas:https://arthas.aliyun.com/doc/logger.html,该工具提供了动态修改日志的能力。
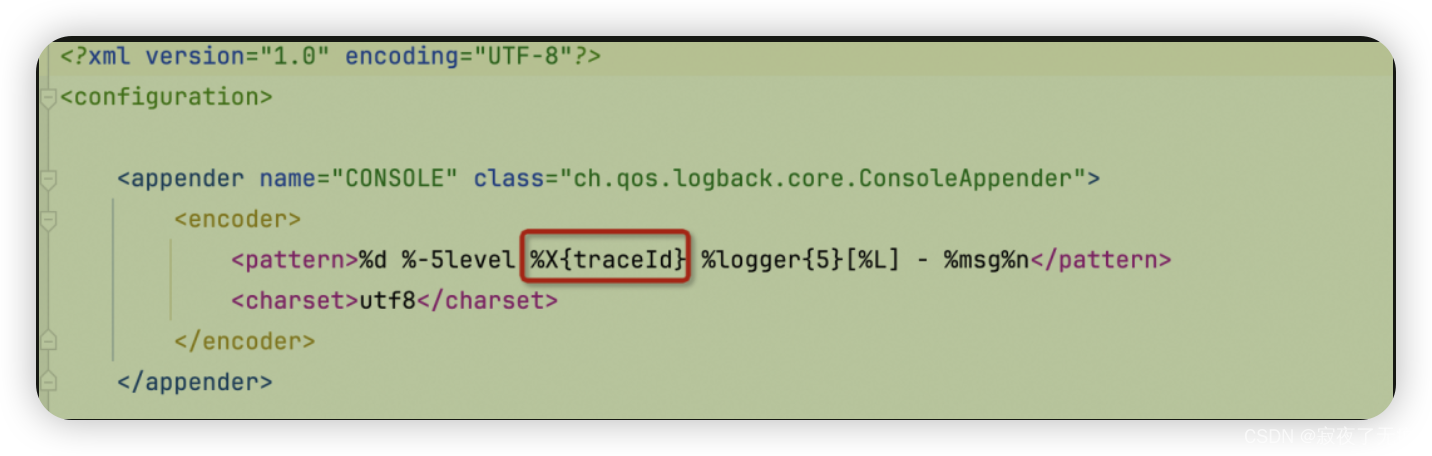
2. 追加业务信息到日志中,并格式化输出:追加MDC信息,方便排查问题
这是日志系统的一个扩容能力,可以把一些额外的信息输出到日志里,只需要在MDC上下文中写入kv,https://logback.qos.ch/manual/mdc.html
例如:
public static void main(String[] args) {
//代码里使用MDC.put写入key为traceId的值
//在logback.xml里就可以使用%X{traceId}进行输出
MDC.put("traceId", UUID.randomUUID().toString().replace("-", ""));
}
日志配置中使用:
3. 配置定时日志磁盘占用清理
一定要配置合理的日志清理策略,避免磁盘被打爆,可借助日志框架自身能力,或借助可用的日志清理系统(如果有)
在logback.xml配置中,可通过配置带有清理作用的rollingPolicy来完成日志定时清理和滚动,例如:SizeAndTimeBasedRollingPolicy
<rollingPolicy class="ch.gos. logback.core. rolling. SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxHistory>7</maxHistory>
<maxFileSize>50MB</maxFileSize>
<totalSizeCap>20GB</totalSizeCap>
</rollingPolicy>
这段配置的含义是:最多保留7天,单个文件最大50MB,该日志(包括滚动的)最大只能保存20GB。
4. 不要封装一个日志Util,而应该直接使用日志框架进行输出
反例:LogUtil.log(“通过封装的日志工具打印日志”);
正例:log.info(“直接使用日志框架的api进行日志输出”);
理由:在日志输出的时候,日志系统会打印日志产生的原始位置:比如哪个包的哪个类,以及第几行(如果配置了[%L]),如果你使用LogUtil等自己封装的工具,所有的日志输出打印的位置都是LogUtil的,这样不便于做日志问题定位
5. 高效使用日志输出 前提是日志框架 日志系统配置正常
集成lombok 通过使用 注解来进行日志输出
@Slf4j
public class TestLog {
public void test(){
log.info("日志输出......");
}
}
日志问题排查思路
目前没有现成的工具帮你一键做好这个事情,下面给出一个排查思路
-
先明确该系统到底使用的是什么日志框架+日志系统组合,这个很重要,必须搞清是何种组合才可有针对性的处理后续步骤
-
如果是slf4j+logback组合,则可根据上述列出的maven依赖进行排包处理,优先保证依赖的包没有错误,90%的情况下都是包依赖混乱导致的日志丢失
-
排查自己的logback配置文件是否放在正确的路径下、文件名是否正确,配置文件位置不对也会导致日志输出的不对甚至丢失
-
检查logback配置文件内部每个logger及其level配置是否正确,避免自己期望打印info,却配置了error
原文 :https://mp.weixin.qq.com/s/Qdi5kDq6vLqcRsFD5_vnnw
the end !!!
good day !!!