尽我所能,总结留给后面的师弟们!
1.目标
搭建一个完整的系统,包括图像数据集预处理,训练模型,分类器,优化器,以及结果数据处理。
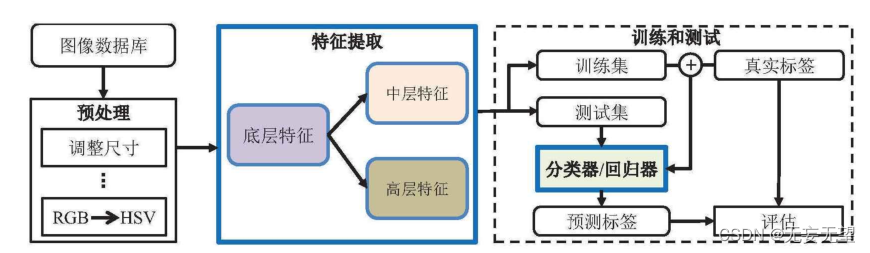
2.理论
3.实例(猫狗分类)
Gitee代码地址:https://gitee.com/li-bowen1805454123/slimming_pytorch_cat_Dog/tree/master
运行截图
目录结构
3.1代码讲解
Train.py
import os
import numpy as np
import torch
# from torch.utils.tensorboard import writer
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.optim import lr_scheduler
from model_AlexNet import AlexNet
from model_vgg16 import Vgg16
from model_leNet import LeNet
import data_read
from torch.utils.data import DataLoader
# from torch.utils.tensorboard import SummaryWriter
import os
import glob
import pandas as pd
import numpy as np
import torch
from yolo_pafpn_asff import YOLOPAFPN_ASFF
# from models.pan import PSENet
import keras as K
from keras import optimizers
#使用GPU 可选则
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 只使用GPU
# device = torch.device("cuda:0")
# 程序运行中可以通过 watch -n 0.1 -d nvidia-smi 命令来实时查看GPU占用情况,按Ctrl+c退出
# 通过 nvidia-smi 命令来查看某一时刻的GPU的占用情况
# watch -n 0.1 -d nvidia-smi
# 解决缓存问题
# 进入root用户 使用下面命令直接清除缓存
# echo 3 > /proc/sys/vm/drop_caches
# 查看内存使用情况,注意个人的电脑情况
# free -h
# 旧版 学习使用的加载数据:训练集、测试集
# # 训练集
# train_data = data_read.datasets("./data/train")
# # 测试集
# val_data = data_read.datasets("./data/val")
# 一组包含几张图像
batch_size = 10
# 项目常用加载数据集方式
# 训练集与测试集的路径
ROOT_TRAIN = './emotion_data/train'
ROOT_TEST = './emotion_data/val'
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomVerticalFlip(),
# 随机旋转,-45度到45度之间随机选
transforms.RandomRotation(45),
# 从中心开始裁剪
transforms.CenterCrop(224),
# 随机水平翻转 选择概率值为 p=0.5
transforms.RandomHorizontalFlip(p=0.5),
# 随机垂直翻转
transforms.RandomVerticalFlip(p=0.5),
# 参数:亮度、对比度、饱和度、色相
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),
# 转为3通道灰度图 R=G=B 概率设定0.025
transforms.RandomGrayscale(p=0.025),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
# 随机旋转,-45度到45度之间随机选
transforms.RandomRotation(45),
# 从中心开始裁剪
transforms.CenterCrop(224),
# 随机水平翻转 选择概率值为 p=0.5
transforms.RandomHorizontalFlip(p=0.5),
# 随机垂直翻转
transforms.RandomVerticalFlip(p=0.5),
# 参数:亮度、对比度、饱和度、色相
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),
# 转为3通道灰度图 R=G=B 概率设定0.025
transforms.RandomGrayscale(p=0.025),
transforms.ToTensor(),
# 将图像的像素值归一化到【-1, 1】之间
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
train_data = ImageFolder(ROOT_TRAIN, transform=train_transform)
val_data = ImageFolder(ROOT_TEST, transform=val_transform)
# ------------------------------------------------------------------
# 加载图像数据集
train_datas = DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True, num_workers=0, drop_last=False)
val_datas = DataLoader(dataset=val_data, batch_size=batch_size, shuffle=True, num_workers=0, drop_last=False)
# 导入网络 可选
# model = LeNet()
model = Vgg16()
# 使用GPU
model = model.to(device)
# 损失函数
loss_fn = torch.nn.CrossEntropyLoss()
# 使用GPU
loss_fn = loss_fn.to(device)
# 优化器
# 学习率
learning_rate = 0.001
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 学习率每隔10轮变为原来的0.5
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
# 训练轮次
epoch = 30
# writer = SummaryWriter("logs")
# 准确率 总数据
train_data_len = len(train_data)
val_data_len = len(val_data)
# 模型名字 根据准确率 删除
model_name_acc = ""
# 模型名字 根据轮次 删除
model_name_epoch = ""
# 准确率列表
acc_list = []
# 训练轮次
for i in range(epoch):
optimizer.zero_grad()
lr_scheduler.step()
# 训练开关
model.train(mode=True)
# 准确个数累计
train_acc = 0
# 累计loss
train_loss = 0
n = 1
for data in train_datas:
imgs, targets = data
# 使用GPU
imgs1 = imgs.to(device)
targets1 = targets.to(device)
# print("输入imgs","targets",imgs,targets)
# print("input.shapr:",imgs.shape)
# 数据给模型
outputs = model(imgs)
# print("输出outputs:",outputs)
# print("output.shape:",outputs.shape)
#YOLOPAFPN output.shape: torch.Size([2, 1792, 28, 28])
#AlexNet output.shape: torch.Size([2, 2])
#vgg16 output.shape: torch.Size([2, 2])
loss = loss_fn(outputs, targets1)
# print("loss:",loss)
# 优化损失 清零、反向传播、优化器启动
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("\r{}".format(loss.item()), end="")
# 显示
# 准确率
train_acc += (outputs.argmax(1) == targets1).sum().item()
# 累计loss
train_loss += loss.item()
print("\r训练次数:{},Loss:{}, acc:{}".format(n, loss.item(), train_acc / (n * batch_size)), end="")
n += 1
print()
print("Loss:{}, 准确率:{}".format(train_loss, train_acc / train_data_len))
# 绘图
# writer.add_scalar("train", train_loss, i)
# 测试开关
model.eval()
# 准确个数累计
val_acc = 0
# 累计loss
val_loss = 0
n = 1
with torch.no_grad():
for data in val_datas:
imgs, targets = data
# 使用GPU
imgs1 = imgs.to(device)
targets1 = targets.to(device)
# 数据给模型
outputs = model(imgs1)
loss = loss_fn(outputs, targets1)
# 准确率
val_acc += (outputs.argmax(1) == targets1).sum().item()
# 累计loss
val_loss += loss.item()
print("\r测试次数:{},Loss:{}, acc:{}".format(n, loss.item(), val_acc / (n * batch_size)), end="")
n += 1
print()
# 测试集 loss
acc = val_acc / (n * batch_size)
print("测试集 Loss:{}, 准确率:{}".format(val_loss, acc))
# 绘图
writer.add_scalar("val", val_loss, i)
# 第1轮保存模型
model_name = "vgg16_{}_{:.2f}.pth".format(i, acc)
# 保存模型 只保存权重参数,没有保存网络架构
# 轮次保存
torch.save(model.state_dict(), model_name)
print("第{}轮模型已保存".format(i + 1))
# 放入
acc_list.append(val_loss)
# loss 最小保存
if val_loss == np.min(acc_list):
acc_max = "vgg16_{}_{:.2f}_acc_max.pth".format(i, acc)
torch.save(model.state_dict(), acc_max)
# 删除上一个准确率
if model_name_acc != "":
os.remove(model_name_acc)
# 将模型名字给外面
model_name_acc = acc_max
# 删除上一个轮次保存的模型,来保护缓存
if i >= 1:
os.remove(model_name_epoch)
# 将保存的模型名字给外面
model_name_epoch = model_name
writer.close()
数据处理
简单来说,首先通过transforms.Compose()来处理图像数据集,之后通过ImageFolder来加载数据集,最后使用DataLoader()来加载预处理后的图像数据集
(1)train_datas = DataLoader()
train_datas = DataLoader是一个用于加载训练数据的函数,它是PyTorch框架中的一个工具类。下面是对train_datas参数的介绍:
1. dataset:表示要加载的训练数据集,通常是一个自定义的Dataset对象,用于提供训练样本。
2. batch_size:表示每个batch中包含的样本数量。在训练过程中,通常会将数据划分为多个batch进行训练,这个参数指定了每个batch的大小。
3. shuffle:表示是否在每个epoch开始时对数据进行洗牌(随机打乱顺序)。设置为True可以增加训练的随机性,有助于提高模型的泛化能力。
4. num_workers:表示用于数据加载的子进程数量。设置为0表示在主进程中加载数据,设置为大于0的值可以加速数据加载过程,但需要注意系统资源的限制。
5. drop_last:表示当样本数量不能被batch_size整除时,是否丢弃最后一个不完整的batch。设置为True可以丢弃不完整的batch,设置为False则保留不完整的batch。
(2) train_data = ImageFolder(ROOT_TRAIN, transform=train_transform)
train_data = ImageFolder是一个用于加载图像数据集的类,它是torchvision库中的一个函数。它接受两个参数:ROOT_TRAIN和transform。
1. ROOT_TRAIN是指训练数据集的根目录,即包含所有训练图像的文件夹的路径。在这个文件夹中,每个类别的图像应该被放置在一个单独的子文件夹中。例如,如果你有一个猫狗分类任务,那么你可以在ROOT_TRAIN文件夹下创建两个子文件夹,一个用于存放猫的图像,另一个用于存放狗的图像。
2. transform是一个用于对图像进行预处理的可选参数。它可以用来对图像进行缩放、裁剪、旋转等操作,以及将图像转换为张量等。你可以根据需要选择合适的预处理操作。
通过调用ImageFolder函数并传入上述参数,train_data对象将被创建,它可以用于加载和访问训练数据集中的图像。
(3) train_transform = transforms.Compose()
train_transform是一个用于数据增强的图像变换操作的合。它包含了多个常用的图像处理操作,用于增加训练数据的多样性和鲁棒性。下面是train_transform中包含的一些操作:
1. transforms.Resize((224, 224)):将图像大小调整为224x224像素。
2. transforms.RandomVerticalFlip():以0.5的概率对图像进行垂直翻转。
3. transforms.RandomRotation(45):以-45度到45度之间的随机角度对图像进行旋转。
4. transforms.CenterCrop(224):从图像中心裁剪出224x224大小的区域。
5. transforms.RandomHorizontalFlip(p=0.5):以0.5的概率对图像进行水平翻转。
6. transforms.RandomVerticalFlip(p=0.5):以0.5的概率对图像进行垂直翻转。
7. transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1):对图像进行亮度、对比度、饱和度和色相的随机调整。
8. transforms.RandomGrayscale(p=0.025):以0.025的概率将图像转换为3通道灰度图像。
9. transforms.ToTensor():将图像转换为张量。
10. transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]):对图像进行标准化处理,将像素值归一化到[-1, 1]的范围。这些图像变换操作可以应用于训练数据,在每个训练样本上进行随机变换,增加数据的多样性,提高模型的泛化能力。
训练设置
(1)model = Vgg16()
model = Vgg16()是创建了一个Vgg16模型的实例,并将其赋值给了变量model。Vgg16是一个经典的卷积神经网络模型,用于图像分类任务。
(2)model = model.to(device)
model = model.to(device)是将模型移动到指定的设备上,其中device是指定的设备,可以是CPU或者GPU。这样做是为了利用GPU的并行计算能力来加速模型的训练或推理过程。
优化器设置
(1)loss_fn = torch.nn.CrossEntropyLoss()
loss_fn = torch.nn.CrossEntropyLoss()是一个用于计算交叉熵损失的函数。交叉熵损失通常用于多分类任务中,它将模型的输出与真实标签进行比较,计算出模型预测的概率分布与真实标签之间的差异。
在上述代码中,loss_fn被定义为CrossEntropyLoss()的一个实例。通过调用该实例的forward()方法,可以计算出模型的输出与真实标签之间的损失值。
(2)loss_fn = loss_fn.to(device)
使用GPU进行计算时,需要将loss_fn移动到GPU上,可以通过调用to(device)方法实现。
(3)learning_rate = 0.001
接下来是优化器的定义。优化器用于更新模型的参数,使得模型能够更好地拟合训练数据。在代码中,使用了随机梯度下降(SGD)作为优化器,学习率为0.001
(4)optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
通过调用torch.optim.SGD()函数,并传入模型的参数和学习率,可以创建一个SGD优化器的实例。
(5)lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
lr_scheduler用于调整学习率。在代码中,使用了StepLR调度器,每隔10个epoch将学习率变为原来的0.5。通过调用torch.optim.lr_scheduler.StepLR()函数,并传入优化器和调整学习率的参数,可以创建一个StepLR调度器的实例。
训练设置
(1)epoch = 30
epoch = 30是指在训练神经网络时,将训练数据集中的所有样本都通过网络训练一次的次数。在每个epoch中,模型会根据训练数据进行前向传播、计算损失、反向传播和参数更新等操作。
(2)train_data_len = len(train_data) ;val_data_len = len(val_data)
train_data_len = len(train_data)是用来获取训练数据集train_data的长度的,即train_data中样本的数量。val_data_len = len(val_data)是用来获取验证数据集val_data的长度的,即val_data中样本的数量。
(3)model_name_acc = "";model_name_epoch = "";acc_list = []
分别定义了根据准确率的模型名称,根据训练次数的模型名称以及准确率列表
训练脚本
-
for i in range(epoch):是一个循环,用于指定训练的轮数。 -
optimizer.zero_grad()用于将模型参数的梯度置零,以便进行下一次反向传播。 -
lr_scheduler.step()用于更新学习率,根据设定的学习率调整策略进行更新。 -
model.train(mode=True)将模型设置为训练模式,以便启用训练相关的功能,如Dropout。 -
train_acc = 0初始化准确个数累计变量。 -
train_loss = 0初始化累计损失变量。 -
n = 1初始化计数器变量。 -
for data in train_datas:是一个数据迭代循环,用于遍历训练数据集。 -
imgs, targets = data将数据拆分为图像和目标。 -
imgs1 = imgs.to(device)将图像数据移动到指定的设备(如GPU)上进行加速计算。 -
targets1 = targets.to(device)将目标数据移动到指定的设备上。 -
outputs = model(imgs)将图像数据输入模型,得到模型的输出。 -
loss = loss_fn(outputs, targets1)计算模型输出与目标之间的损失。 -
optimizer.zero_grad()将优化器的梯度置零,以便进行下一次反向传播。 -
loss.backward()反向传播计算梯度。 -
optimizer.step()根据计算得到的梯度更新模型参数。
训练结果输出
(1)print("\r{}".format(loss.item()), end="")
这段代码是一个训练过程中的打印输出部分。首先,
print("\r{}".format(loss.item()), end="")使用\r实现了输出的覆盖,每次打印时会将光标移动到行首,然后输出loss.item()的值。
(2)train_acc += (outputs.argmax(1) == targets1).sum().item() # 累计;
train_loss += loss.item()
在这段代码中,outputs是模型的输出结果,targets1是训练数据的标签。首先,outputs.argmax(1)会返回outputs中每个样本预测结果的最大值所在的索引,然后与targets1进行比较,得到一个布尔类型的张量。接着,使用.sum().item()将布尔类型的张量求和,并将结果转换为Python标量,最后累加到train_acc上。
同样地,train_loss += loss.item() 是用于计算训练损失的代码。其中,loss是模型的损失函数计算得到的损失值,通过.loss.item()将损失值转换为Python标量,并累加到train_loss上。
(3)print("\r训练次数:{},Loss:{}, acc:{}".format(n, loss.item(), train_acc / (n * batch_size)), end="") n += 1
这段代码是一个简单的打印语句,用于在训练过程中输出训练次数、损失值和准确率。其中,
n表示训练次数,loss.item()表示损失值,train_acc表示准确率。通过使用format()函数将这些变量的值插入到字符串中,并使用\r实现每次打印都在同一行显示。最后,end=""表示打印结束后不换行。
(4)print("Loss:{}, 准确率:{}".format(train_loss, train_acc / train_data_len))
这段代码是用来打印训练过程中的损失值和准确率的。其中,train_loss表示训练的损失值,train_acc表示训练的准确率,train_data_len表示训练数据的长度。
在print函数中,使用了字符串的format方法来格式化输出。{}是占位符,分别对应后面format方法中的train_loss和train_acc / train_data_len。format方法会将这些值填充到对应的位置上,然后打印出来。
这段代码的作用是在训练过程中实时输出损失值和准确率,方便开发者进行调试和监控训练情况。
测试设置
(1)model.eval()
model.eval()是PyTorch中的一个方法,用于将模型设置为评估模式。在评估模式下,模型的行为会有所不同,主要包括以下几个方面:
不会进行梯度计算:在评估模式下,模型不会计算梯度,这样可以减少内存的使用,并且加快推理速度。
Batch Normalization和Dropout的行为不同:在训练模式下,Batch Normalization和Dropout会根据输入数据的统计信息进行归一化和随机失活操作,而在评估模式下,它们会使用固定的统计信息,通常是在训练集上计算得到的。
不会进行参数更新:在评估模式下,模型的参数不会被更新,这样可以保持模型的状态不变,以便进行后续的推理或测试。
对于给定的代码片段,model.eval()的作用是将模型设置为评估模式,然后在验证集上进行推理。在推理过程中,模型会根据输入数据计算输出,并计算损失和准确率。
(2)val_acc = 0;val_loss = 0; n = 1
val_acc表示准确个数的累计,初始值为0;val_loss表示损失的累计,初始值为0;n表示样本数量,初始值为1。
测试脚本
(1)with torch.no_grad()
with torch.no_grad()是一个上下文管理器,用于在代码块中禁用梯度计算。在深度学习中,梯度计算是为了更新模型的参数,但在验证或测试阶段,我们通常不需要计算梯度,只需要使用模型进行推断。因此,使用with torch.no_grad()可以提高代码的执行效率。在给定的代码中,
with torch.no_grad()用于禁用梯度计算,以提高验证数据集上的推断速度。具体来说,代码遍历验证数据集val_datas,将数据和目标转移到GPU上(如果可用),然后将数据传递给模型进行推断。推断结果与目标进行比较以计算准确率,并累积损失值。
(2)
-
imgs1 = imgs.to(device);targets1 = targets.to(device):将数据和标签加载到GPU上(如果可用):将imgs和targets分别赋值给imgs1和targets1,并将它们转移到设备(GPU)上。
-
outputs = model(imgs1):将数据输入模型:将imgs1输入模型,得到模型的输出。
-
loss = loss_fn(outputs, targets1):计算损失:使用损失函数(loss_fn)计算模型输出与真实标签之间的损失。
-
val_acc += (outputs.argmax(1) == targets1).sum().item() :计算准确率:将模型输出的预测结果与真实标签进行比较,统计预测正确的数量,并累加到val_acc变量中。
-
val_loss += loss.item():累计损失:将当前数据的损失值累加到val_loss变量中。
这段代码的目的是评估模型在验证数据集上的性能,通过计算平均损失和准确率来衡量模型的表现。
测试结果输出
(1) print("\r测试次数:{},Loss:{}, acc:{}".format(n, loss.item(), val_acc / (n * batch_size)), end="") n += 1
这段代码是一个简单的打印语句,用于在训练过程中输出训练次数、损失和准确率的信息。其中,
n表示训练次数,loss.item()表示损失值,val_acc / (n * batch_size)表示准确率。通过使用format()函数将这些变量的值插入到字符串中,并使用\r实现每次打印都在同一行显示。最后,end=""表示打印结束后不换行。
(2) loss acc = val_acc / (n * batch_size)
print("测试集 Loss:{}, 准确率:{}".format(val_loss, acc))
这段代码是用来计算测试集的损失和准确率的。其中,
loss表示损失值,acc表示准确率。val_acc表示验证集的准确率,n表示验证集的样本数量,batch_size表示每个批次的样本数量。根据代码中的计算公式,
loss的值等于val_acc除以(n * batch_size)。这个公式是将验证集的准确率除以验证集的总样本数和每个批次的样本数量的乘积。打印语句
print("测试集 Loss:{}, 准确率:{}".format(val_loss, acc))用来输出测试集的损失和准确率。其中,val_loss表示测试集的损失值,acc表示测试集的准确率。
模型保存
(1)model_name = "vgg16_{}_{:.2f}.pth".format(i, acc)
model_name = “vgg16_{}_{:.2f}.pth”.format(i, acc) 是一个字符串格式化的操作,用于生成一个模型的名称。其中,{} 是占位符,i 和 acc 是要填充到占位符中的值。
具体来说,这个模型名称的格式是 “vgg16_i_acc.pth”,其中 i 是一个整数,表示模型的序号,acc 是一个浮点数,表示模型的准确率。通过使用 format() 方法,可以将 i 和 acc 的值填充到占位符中,生成最终的模型名称。
例如,如果 i 的值为 1,acc 的值为 0.85,那么生成的模型名称就是 “vgg16_1_0.85.pth”。
(2)torch.save(model.state_dict(), model_name)
print("第{}轮模型已保存".format(i + 1))
torch.save(model.state_dict(), model_name)是一个用于保存PyTorch模型参数的函数。它将模型的状态字典保存到指定的文件中,以便在以后加载和使用模型时可以重新加载这些参数。这个函数接受两个参数:第一个参数是模型的状态字典,即包含了模型所有参数的字典;第二个参数是保存的文件名。
print("第{}轮模型已保存".format(i + 1))是一个打印语句,用于在控制台输出一条消息,表示第i+1轮的模型已经成功保存。
(3)acc_list.append(val_loss)
if val_loss == np.min(acc_list):
acc_max = "vgg16_{}_{:.2f}_acc_max.pth".format(i, acc)
torch.save(model.state_dict(), acc_max)
if model_name_acc != "":
os.remove(model_name_acc)
model_name_acc = acc_max
这段代码是一个模型训练过程中的一部分,主要是用来保存在验证集上表现最好的模型参数。具体来说,代码中的`acc_list`是一个用来保存每次验证集上的损失值的列表,`val_loss`是当前的验证集损失值。代码首先将当前的验证集损失值添加到`acc_list`中,然后判断当前的验证集损失值是否是`acc_list`中的最小值,如果是最小值,则将模型的参数保存到文件中。
具体的操作步骤如下:
1. 将当前的验证集损失值`val_loss`添加到`acc_list`中。
2. 判断当前的验证集损失值是否等于`acc_list`中的最小值。
3. 如果当前的验证集损失值是最小值,则根据当前的迭代次数`i`和准确率`acc`生成一个模型文件名`acc_max`。
4. 使用`torch.save()`函数将模型的参数保存到文件中。
5. 如果之前已经保存过模型参数文件`model_name_acc`,则删除该文件。
6. 将当前的模型文件名`acc_max`赋值给变量`model_name_acc`。
(4)if i >= 1:
os.remove(model_name_epoch)
model_name_epoch = model_name
这段代码是一个条件语句,如果变量i的值大于等于1,则执行以下两行代码:
1. 使用os模块的remove函数删除文件model_name_epoch。
2. 将变量model_name_epoch的值更新为变量model_name的值。这段代码的作用是删除指定的文件,并将变量model_name_epoch更新为变量model_name的值。
VGG.py
from torch import nn
import torch.nn.functional as F
import torch
import math
"""
复现vgg19,增加一层实现2分类
"""
class VGG19(nn.Module):
def __init__(self, cfg=None):
super(VGG19, self).__init__()
if cfg is None:
# 使用Max是证明里面可以随意定义,但在剪枝内要与之对应改动
cfg = [64, 'Max', 64, 128, 'Max',
128, 256, 256, 256, 'Max',
256, 512, 512, 512, 'Max',
512, 512, 512, 512, 'Max']
self.vgg19 = self.make_vgg19(cfg)
self.f1 = nn.AdaptiveAvgPool2d(output_size=(7, 7))
# 由于剪枝模型后,nn.Conv2d(in_channels=???) 或者叫 输入通道数,也就是配置文件cfg会产生变化
# 全连接层的输入是由上一层的输出决定的,这里不能定死,要写成一个变量
# 全连接层根据 nn.AdaptiveAvgPool2d(output_size=(7, 7)) 与 cfg的最后一层,如果最后一层是池化,那就用倒数第二层
# 全连接层根据 图像走到当前层的宽、高 * 特征图个数 也就是cfg最后的数
self.f2 = nn.Linear(in_features=cfg[-2]*7*7, out_features=4096, bias=True)
self.Relu = nn.ReLU(inplace=True)
self.f3 = nn.Linear(in_features=4096, out_features=4096, bias=True)
self.f4 = nn.Linear(in_features=4096, out_features=1000, bias=True)
self.f5 = nn.Linear(in_features=1000, out_features=2, bias=True)
# self.f6 = nn.Sigmoid()
# 权重初始化
# self._initialize_weights()
def make_vgg19(self, cfg):
"""
函数概述:构造vgg19的网络模型,前半部分
诞生原因:利用自定义的cfg来快速构造重复性较多的层(少写点代码)
通用具体实现思路:观察网络重复节点,进行打包,按序添加列表中再串联。
"""
# 传递给下一层输入的节点数
input_n = 3 # 初始的输入是3
# 总网络层数
features_sum = []
for v in cfg:
if v == 'Max':
features_sum += [nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)]
else:
conv = nn.Conv2d(input_n, v, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
features_sum += [conv, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
input_n = v
return nn.Sequential(*features_sum)
def forward(self, x):
x = self.vgg19(x)
x = self.f1(x)
x = nn.Flatten()(x)
x = self.f2(x)
x = self.Relu(x)
x = F.dropout(x, p=0.5)
x = self.f3(x)
x = F.dropout(x, p=0.5)
x = self.f4(x)
x = self.Relu(x)
x = self.f5(x)
return x
# 权重初始化
def _initialize_weights(self):
"""
Xavier权重初始化
权重初始化公式:上一个节点数 = n,当前权重初始值 = 1/根号n
"""
for m in self.modules():
# 判断对象是不是一个实例,惯用方法
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(0.5)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
if __name__ == '__main__':
net = VGG19()
# 验证网络 须知输入图像,设定全1矩阵测试
input = torch.ones((1, 3, 224, 224))
output = net(input)
print(output.shape)




![[学习笔记]CNN代码实战](https://img-blog.csdnimg.cn/direct/8d543bbfadc84252bba75c5a6268660c.png#pic_center)
![[Netty实践] 请求响应同步实现](https://img-blog.csdnimg.cn/direct/defbeb37fd1c44f386acdc36ae86d915.png)