Linux进阶
Vim——Linux自带的文本编辑器
功能强大

命令模式
- 使用
vim <file>进入后的默认模式 - 可以上下左右移动光标
- 方向键/hjkl
- 快速到所在行的开头
^/末尾$ - 向下移动30行
30j(上左右同) - 上下翻页
Ctrl+f向上,Ctrl+b向下翻页 - 快速回到文件第一行的第一个字符
gg - 快速回到文件底部第一个字符
G
- 可以剪切字符/整行、也可以复制粘贴
- 剪切
x,连续剪切10个字符10x - 剪切所在行
dd,剪切所在行及向下共10行10dd - 粘贴到所在行的下面
p/上面P粘贴 - 复制光标所在行
yy,复制所在行及下面10行10yy
- 剪切
- 撤销
u - 重做上一个动作
Ctrl+r
编辑模式
输入i后进入编辑模式
按Esc退出编辑模式
末行模式
在命令模式下输入:
按Esc退出该模式
- 在该模式下可以设置、查询、替换、保存并退出
- 保存退出
- 保存并退出
wq - 直接退出
q - 不保存修改,强制退出
q!
- 保存并退出
- 查询
- 输入
/<KEYWORD>进行查询 - 按
n向下查找,按N向上查找
- 输入
- 替换
:%s///g全局替换:s///g替换光标所在行:s///只替换光标所在行的第一次出现
set系列命令
:set nu显示行号;:set nonu取消显示行号:set list显示不可见字符(分辨制表符表格等):set nowrap单行显示:set ff-unix将文件格式转换为unix格式fffile format文件格式
- 不同平台关于回车键的设置不同:Windows:
\r\n; Mac:\r; Linux:\n. 解决方法之一:vim中的:set ff-unix。解决方法之二:dos2unix(unix2mac…)
异常情况处理
-
E325:ATTENTIONswp文件:使用vim编辑的时候未保存产生的缓存的文件
第一种情况为其他程序正在修改。
第二种情况为保存修改之前和服务器断开连接。
可以
-r(recovery)恢复,恢复保存后删除缓存文件[swp]。 -
vim的帮助文档:
vimtutor zh_CN
文本处理的三驾马车
grep
一种强大的文本搜索工具,可以匹配正则表达式
-
格式:grep [options] ‘pattern’ file
-
常见参数
-
-w精准查找某个关键词word -
-c统计匹配成功的行的数量 -
-v反向选择,输出没有匹配的行 -
-n显示匹配成功的行的所在行号 -
-r从目录中查找pattern,显示所在行在目录中的所有文件中查找(不会查找压缩文件)
-
-e指定多个匹配模式cat file | grep -w -e 'exon' -e 'UTR' #-e和pattern成对出现 -
-f从指定文件中读取要匹配的pattern使用vim把多个个关键词写入file2中,一行一个
-
-i忽略大小写
-
-
正则表达式
-
^行首 -
$行尾 -
.换行符之外的任意单个字符 -
?匹配前一字符出现了0次/1次的情况(扩展正则表达式,需要使用\?或在参数位置使用-E开启优先正则表达式模式来匹配? ) -
+匹配前一字符出现了1次/多次的情况(扩展正则) -
*匹配前一字符出现了0次/多次的情况 -
[]匹配任意一个字符[AT]匹配A/T
-
[^]排除字符[^aB] -
|或
-
sed
流编辑器,一般对文本进行增删改查
针对行进行的动作
-
用法:sed [-options] ‘script’ file(s)
-
常见参数[-options]
-n禁止显示所有输入内容,只显示经过sed处理的行(常用)-e直接在命令模式上进行sed的动作编辑,接要执行的一个或多个命令-f执行含有sed动作的文件-rsed的动作支持扩展正则-i直接修改读取的文件内容,会直接修改源文件
-
动作
script:[address]command-
address
2:第2行
2,4:第2-4行
2,$:第2行到最后一行
2~3:从第2行开始,每隔3行处理一次(2、5、8)
2,+4:从第2行开始,到第2+4行
/pattern/:匹配上pattern的行
!:表示否定,取反,例如2!表示动作在除了第二行以外的行
-
command:增改删查
a(append) 在指定行后增加一行,内容为a后面接的字符串i(insert) 在指定行的前增加一行,内容为i后面接的字符串d(delete) 删除某一行或某几行c(change) 改变指定行的内容s更改或替换字符串,使用格式s/pattern/new/[flags],意为把pattern替换成new,flags表示替换第几个,1/2/gy转换,实现字符一对一转换,格式y/abc/ABC意为abc一对一替换成ABC,符号也支持p(print) 把匹配或修改过的行打印出来,通常与-n参数合用
-
awk
也成为gawk,编程语言,可对文本和数据进行处理
-
常见参数:
-F(fields)设置字段分隔符 -
用法:awk [options] ‘{script}’ file
##基础结构 '{script}' ##匹配结构 '/pattern/{script}' ##扩展结构 'BEGIN{script} {script} END{script}' -
awk使用预定义的字段分隔符划分每个数据字段,分配给一个变量。-
$0代表整个文本行 -
$1代表文本行的第一个数据字段(列)。。。
-
$NF代表文本行的最后一个数据字段(列)
-
-
默认分隔符是任意空白字符(空格/制表符),也可以使用参数
-F自定义分隔符 -
内置变量:
FS定义输入字段分隔符RS定义输入记录分隔符OFS定义输出字段分隔符ORS定义输出记录分隔符NF数据文件中的字段总数,简单理解为列数NR已处理的输入记录数,可以简单理解为行数
cat Data/example.gtf | awk 'BEGIN{OFS= ":"} {print $3,$4,$5}' | head -5 cat Data/example.gtf | awk 'BEGIN{FS="\t";OFS=";"} {print NR, $9}'|head -5 -
awk条件和循环语句-
if条件判断awk '{if(条件) {yes} else {no}}' #例子 awk'{if($3=="gene") print $0}' ##类似R逻辑值去子集
-
-
awk数学运算
-
cut的默认分隔符是分隔符,awk的列之间是根据写法不同改变。
Linux常见符号及其含义
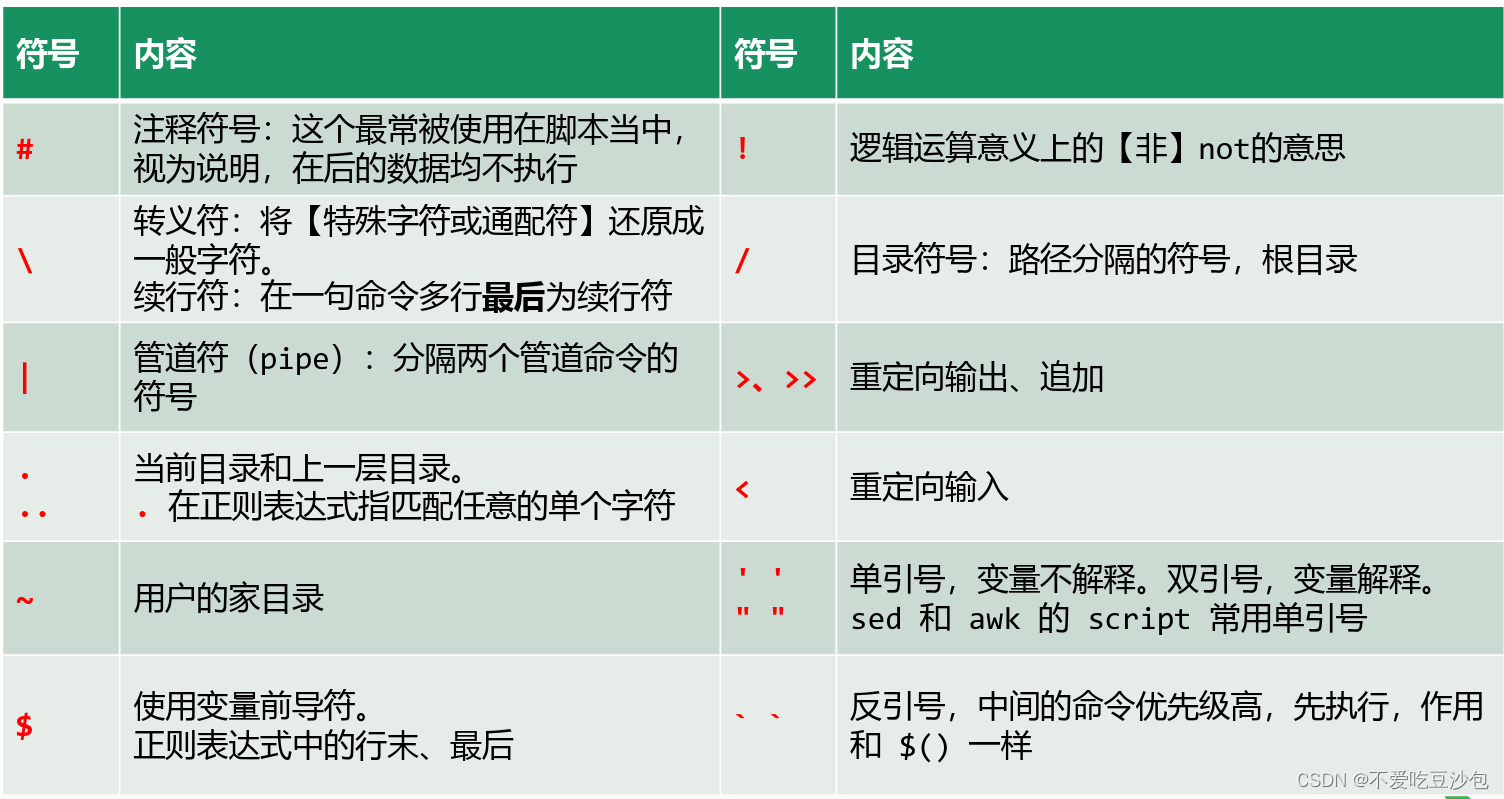
引用自生信技能树课程~
今天内容比较多一些,还需要时间消化,还是先记下来以后慢慢理解~




![服务器中了.[hpssupfast@mailfence.com].Elbie勒索病毒,数据还能恢复吗?](https://img-blog.csdnimg.cn/direct/afd2ec524ef24d0a9294e773734f93cf.png)