Mora: Enabling Generalist Video Generation via A Multi-Agent Framework
PDF: https://arxiv.org/html/2403.13248v1
1 概述
为弥补Sora不开源的缺陷,本文提出多代理框架Mora,整合先进视觉AI代理,复制Sora的全能视频生成能力。Mora能利用多视觉代理,成功模仿Sora在各种任务中的视频生成能力。
主要贡献包括:
- 介绍了Mora,一个用于增强多智能体协作的元编程框架,具有结构化且灵活的智能体系统和直观的配置界面,有助于推动通用视频生成任务的发展。
- 研究表明,通过自动化协作多个智能体(如文本到图像、图像到视频等),可以显著提升视频生成质量。
- Mora在多个视频相关任务中表现卓越,超越现有开源模型,展现了其作为通用视频生成框架的巨大潜力,预示着视频内容创建和利用的重大进步。
2 Mora: A Multi-Agent Framework for Video Generation
代理的设定使得复杂工作可以分解为更具体的任务,不同能力的代理在解决视频生成任务时相互协作。Mora 框架包括五个基本角色:提示选择和生成、文本到图像生成、图像到图像生成、图像到视频生成以及视频到视频代理。
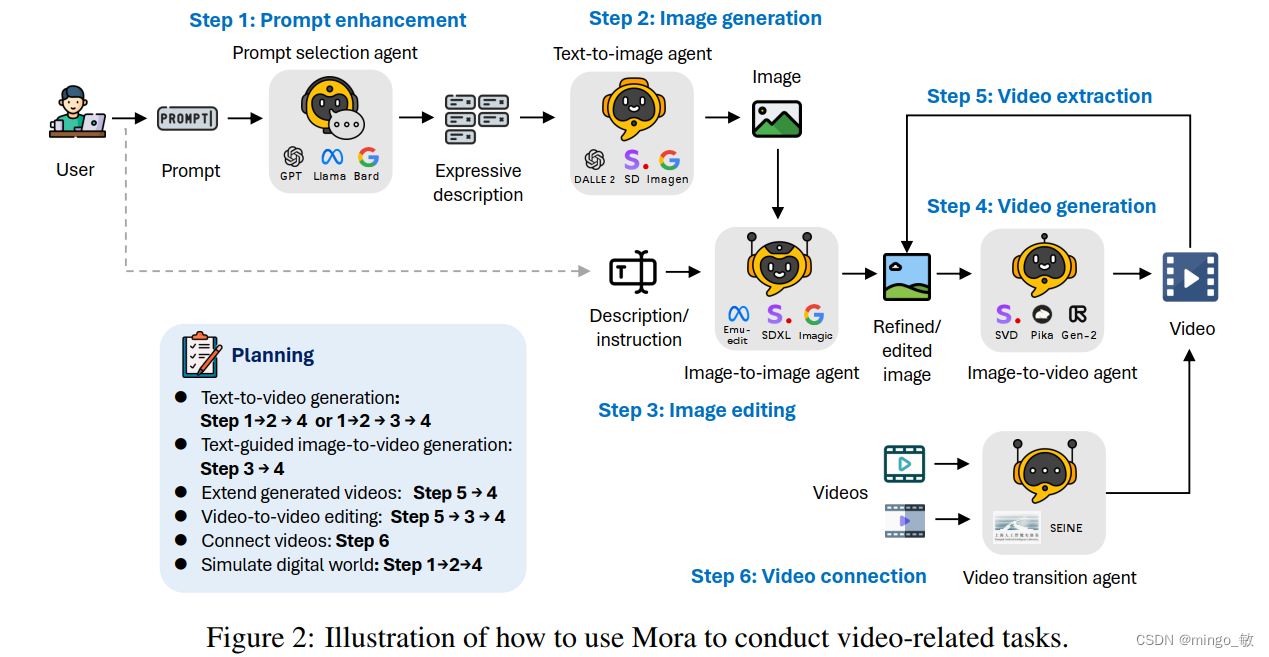
2-1 提示选择与生成代理
在开始图像生成前,代理利用大型语言模型处理优化文本提示,以提升图像的相关性和质量。
目前,GPT-4是市面上最先进的生成模型。通过利用GPT-4的能力,我们能够生成并精心选择高质量的提示。这些提示详细且信息丰富,为文本到图像的生成过程提供了全面的指导。
GPT-4 Technical Report
2-2 文本到图像生成代理
该代理将丰富的文本描述转化为高质量的初始图像,准确呈现复杂文本输入的可视化效果。
Stable Diffusion XL通过增强UNet架构和引入双文本编码器系统,提升了文本解读能力,并引入无需外部监督的条件方案,增强了生成图像的灵活性。其细化模型通过噪声消除技术,提升了图像的视觉质量,同时保持高效生成速度。
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
2-3 图像到图像生成代理
代理根据文本指令修改源图像,实现细节调整或整体变换,无缝融合新元素和调整视觉风格。
InstructPix2Pix融合了GPT-3和Stable Diffusion两个预训练模型的优势。GPT-3负责从文本描述中生成编辑指令和标题,Stable Diffusion则将文本输入转化为视觉输出。框架首先微调GPT-3以提出合理编辑建议,然后利用Stable Diffusion生成编辑前后的图像对。最终,InstructPix2Pix利用文本指令和输入图像直接进行编辑,通过无分类器指导提高效率和保真度。
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
2-4 图像到视频生成代理
此代理将初始图像转换为生动的视频序列,确保内容连贯且视觉一致,展现模型对场景进展的预见能力。
采用先进的Stable Video Diffusion模型来生成视频,它结合LDMs的优势,可处理视频的时间复杂性。模型经过三阶段训练:从文本到图像学习视觉表示,视频预训练学习时间动态,高质量视频微调提高生成效果。
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
2-5 视频连接代理
利用视频到视频代理,基于用户提供的两个视频创建无缝过渡,保留各段风格,实现流畅的视频转换。
使用SEINE连接视频,它基于预训练的扩散T2V模型,能生成基于文本描述的过渡效果,实现流畅的视频连接。
SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction
3 Experiments
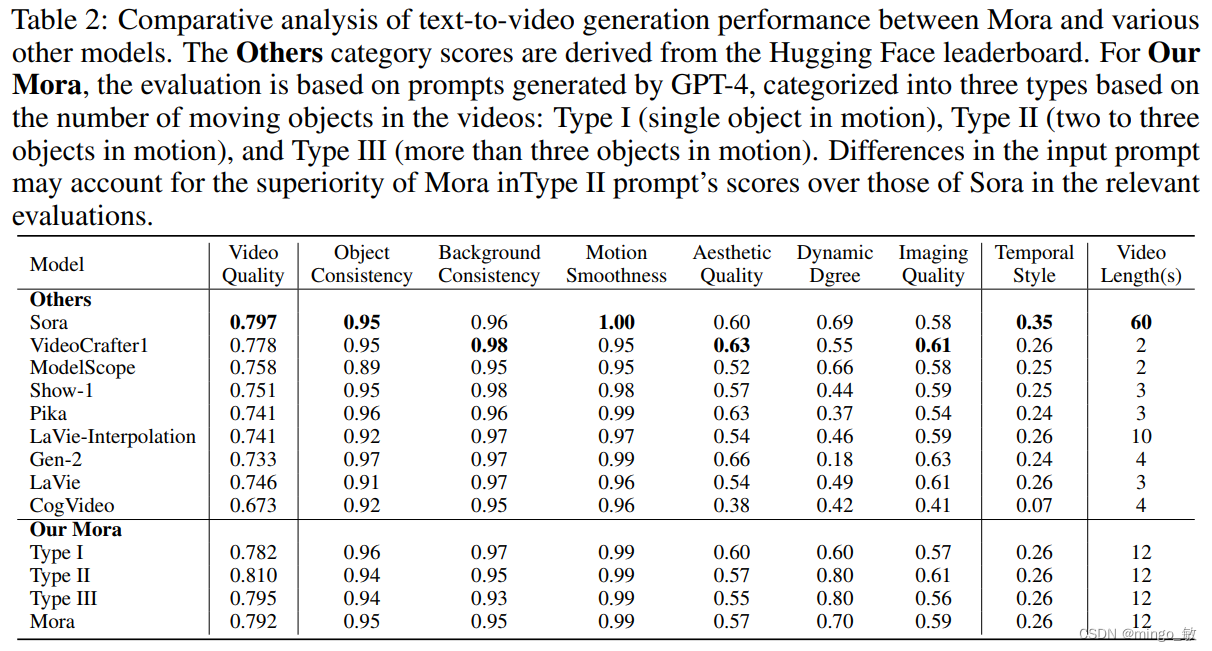
3-1 Text-to-video generation

3-2 Text-conditional image-to-video generation
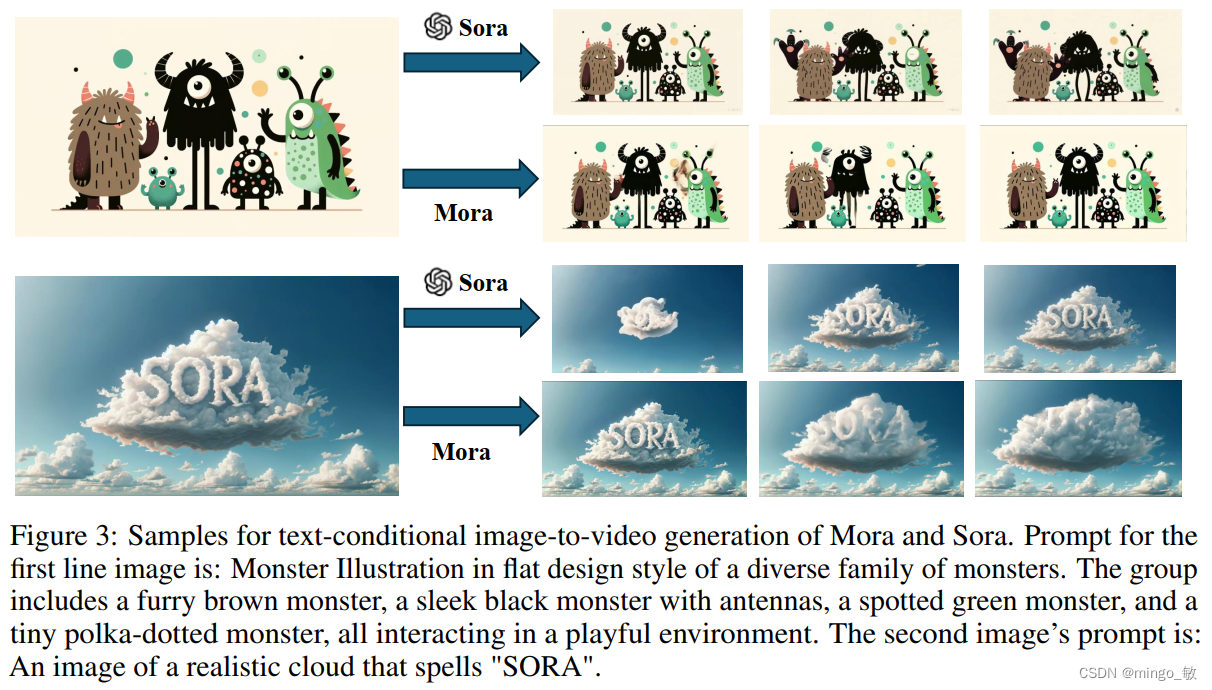
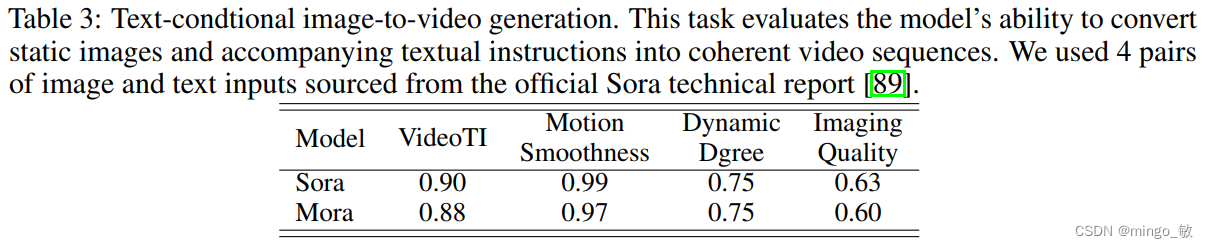
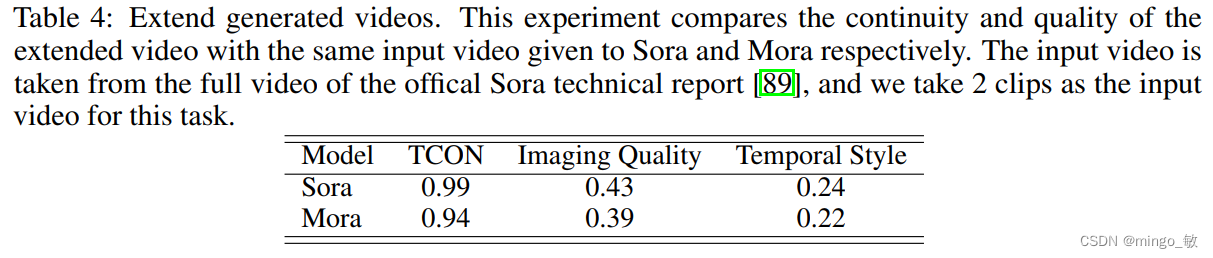
3-3 Extend generated videos

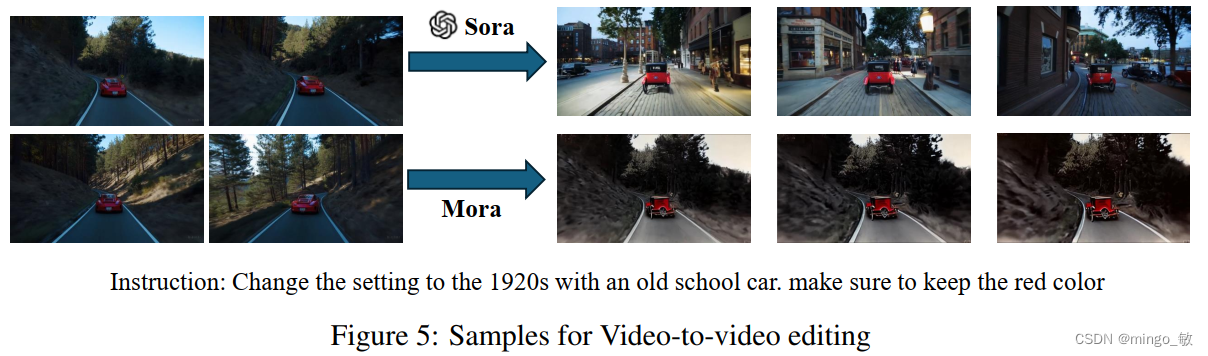
3-4 Video-to-video editing

3-5 Connect Videos


3-6 Simulate digital worlds





![【源头活水】顶刊解读!IEEE T-PAMI (CCF-A,IF 23.6)2024年46卷第一期 [1]](https://img-blog.csdnimg.cn/img_convert/94ec459434c1ec54559a5b4cbe122d09.png)