本文主要聊InnoDB内存结构, 先来看下官网Mysql 8.0 InnoDB架构图
MySQL :: MySQL 8.0 Reference Manual :: 17.4 InnoDB Architecture

如上图所示,InnoDB内存主要包含Buffer Pool, Change Buffer, Log Buffer, Adaptive Hash Index
Buffer Pool
其实 buffer pool 就是内存中的一块缓冲池,用来缓存表和索引的数据。默认80%的物理内存分配给缓冲池。
我们都知道 mysql 的数据最终是存储在磁盘上的,但是如果读存数据都直接跟磁盘打交道的话,这速度就有点慢了。所以 innodb 自己维护了一个 buffer pool,在读取数据的时候,会把数据加载到缓冲池中,这样下次再获取就不需要从磁盘读了,直接访问内存中的 buffer pool 即可。包括修改也是一样,直接修改内存中的数据,然后到一定时机才会将这些脏数据刷到磁盘上。
其实缓冲池维护的是页数据,也就是说,即使你只想从磁盘中获取一条数据,但是 innodb 也会加载一页的数据到缓冲池中,一页默认是 16k。
Buffer Pool 管理
Buffer Pool 中的页有三种状态:
-
空闲页:通过空闲页链表(Free List)管理。
-
正常页:通过LRU链表(LRU List)管理。
-
脏页:通过LRU链表和脏页链表(Flush List)管理。(缓冲池中被修改过的页,与磁盘上的数据页不一致)
Free链表
初始化完的buffer pool时所有的页都是空闲页,所有空闲的缓冲页对应的控制块信息作为一个节点放到Free链表中。

要注意Free链表是一个个控制块,而控制块的信息中有缓存页的地址信息。
在有了free链表之后,当需要加载磁盘中的页到buffer pool中时,就去free链表中取一个空闲页所对应的控制块信息,根据控制块信息中的表空间号、页号找到buffer pool里对应的缓冲页,再将数据加载到该缓冲页中,随后删掉free链表该控制块信息对应的节点。
Flush链表
修改了buffer pool中缓冲页的数据,那么该页和磁盘就不一致了,这样的页就称为【脏页】,它不是立马刷入到磁盘中,而是由后台线程将脏页写入到磁盘。
Flush链表就是为了能知道哪些是脏页而设计的,它跟Free链表结构图相似,区别在于控制块指向的是脏页地址。
LRU链表
对于频繁访问的数据和很少访问的数据我们对与它的期望是不一样的,很少访问的数据希望在某个时机淘汰掉,避免占用buffer pool的空间,因为缓冲空间大小是有限的。
MySQL设计了根据LRU算法设计了LRU链表来维护和淘汰缓冲页。
LRU 算法简单来说,如果用链表来实现,将最近命中(加载)的数据页移在头部,未使用的向后偏移,直至移除链表。这样的淘汰算法就叫做 LRU 算法,但是简单的LRU算法会带来两个问题:预读失效、Buffer Pool污染
预读: 当数据页从磁盘加载到 Buffer Pool 中时,会把相邻的数据页也提前加载到 Buffer Pool 中,这样做的好处就是减少未来可能的磁盘IO。
改进LRU 算法
Buffer Pool的LRU算法中InnoDB 将LRU链表按照5:3的比例分成了young区域和old区域。链表头部的5/8是young区(被高频访问数据),链表尾部的3/8区域是old区域(低频访问数据),箭头朝下的是未被访问的数据,朝上的是被访问的数据。

这样做的目的是,在预读的时候或访问不存在的缓冲页时,先加入到 old 区域的头部,等 1s后(大部分场景扫描数据之后同一个请求会马上访问这部分数据,之后可能就不访问了),如果该页面再次被访问才会被移动到新生代。
Buffer Pool刷盘
(1)有一个后台线程,会认为数据库空闲时;
(2)数据库缓冲池不够用时;(执行sql时刚好碰到缓冲池不够用导致的刷盘时, sql执行得等缓存池刷盘完成)
(3)数据库正常关闭时;
(4)redo log写满时(下文详解);
Change Buffer
在MySQL5.5之前,叫插入缓冲(insert buffer),只针对insert做了优化;现在对delete和update也有效,叫做写缓冲(change buffer)。
它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(buffer changes),等未来数据被读取时,再将数据合并(merge)恢复到缓冲池中的技术。写缓冲的目的是降低写操作的磁盘IO,提升数据库性能。
写入流程

执行两条Insert语句,其中左侧的要更新的数据页 Page1 不在Buffer Pool,而右侧需要更新的数据页Page2在Buffer Pool缓存中。
- 数据页Page1: 不在Buffer Pool中的话, 将修改写入Change Buffer,最终写入表空间
- 数据页Page2: 在缓存中,直接更新, 最终写入数据文件
两次内存:一次是修改Buffer Pool的数据页、另一次是Change buffer中记录这个写入操作。
三次磁盘: 一次redo log(合并批量), 一次change buffer落盘, 一次脏页落盘. 三次落盘都是等到落盘条件之后触发。
Merge流程
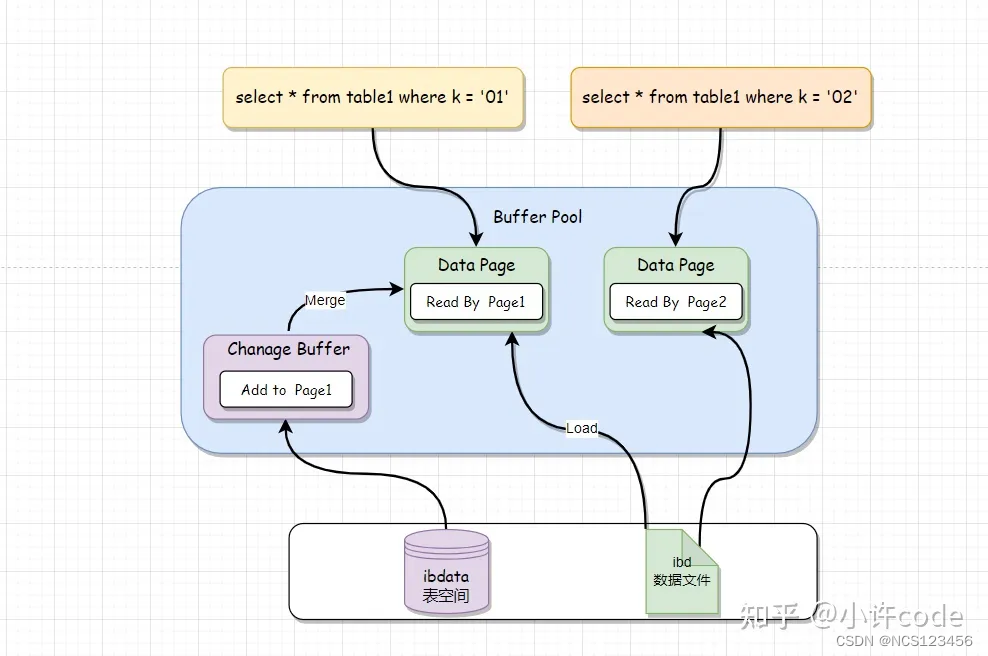
读Page2的时候很好理解,直接从Buffer Pool 中返回,
但是读Page1时,需把Page1从磁盘读入内存,然后将Change Buffer里面的操作日志,Merge生成一个正确版本并返回结果。
适用场景: 数据库大部分是非唯一索引, 并且写多读少。
Log Buffer
Log Buffer是给 redo log 做缓冲用的。redo log 我们都知道是重做日志,用来保证崩溃恢复数据的正确性,innodb 写数据时是先写日志,再写磁盘数据,即 WAL (Write-Ahead Logging),把数据的随机写入转换成日志的顺序写。
即使是顺序写 log ,每次都调用 write 或者 fsync 也是有开销的,毕竟也是系统调用,涉及上下文切换。于是乎,搞了个 Log Buffer(默认16M) 来缓存 redo log 的写入。
刷盘配置
innodb 其实给了个配置,即 innodb_flush_log_at_trx_commit 来控制 redo log 写盘时机。
-
当值为 0,提交事务不会刷盘到 redo log,需要等每隔一秒的后台线程,将 log buffer 写到操作系统的 cache,并调用 fsync落盘,性能最好,但是可能会丢 1s 数据。
-
当值为 1,提交事务会将 log buffer 写到操作系统的 cache,并调用 fsync 落盘,保证数据正确,性能最差,这也是默认配置。
-
当值为 2,提交事务会将 log buffer 写到操作系统的 cache,但不调用 fsync,而是等每隔 1s 调用 fsync 落盘,性能折中,如果数据库挂了没事,如果服务器宕机了,会丢 1s 数据。
redo log
每个 InnoDB 存储引擎至少有 1 个重做日志文件组( redo log group),每个文件组下至少有 2 个重做日志文件(redo log file),默认的话是一个 redo log group,其中包含 2 个 redo log file:ib_logfile0 和 ib_logfile1 。在日志组中每个 redo log file 的大小一致,并以循环写入的方式运行。
如下图举例:
一组 4 个文件,每个文件的大小是 1GB,那么总共就有 4GB 的 redo log file 空间。write pos 是当前 redo log 记录的位置,随着不断地写入磁盘,write pos 也不断地往后移,写到 file 3 末尾后就回到 file 0 开头。CheckPoint 是当前要擦除的位置(将 Checkpoint 之后的页刷新回磁盘),write pos 和 CheckPoint 之间的就是 redo log file 上还空着的部分,可以用来记录新的操作。如果 write pos 追上 CheckPoint,就表示 redo log file 满了,这时候不能再执行新的更新,得停下来先把buffer pool中脏页都flush到磁盘,把 CheckPoint 推进一下。

crash-safe
上面change buffer提到二级索引更新操作,如果 buffer pool中没有更新数据,不会从磁盘拉取数据,而是直接把变更记录在change buffer。假如数据库挂了,更改不是丢了吗?
mysql通过redo log 和 binlog来防止机器宕机之后数据丢失问题。
场景一:redo log 没有commit,binlog没有fsync,数据丢失。
场景二:redo log 没有commit,binlog已经fsync,重启之后会对比binlog中的trx_id和redo log中的trx_id, 进行commit redo log。
场景三:redo log 已经commit,binlog已经fsync,从redo log恢复数据。
Adaptive Hash Index
在MySQL运行的过程中,如果InnoDB发现,有很多寻路很长(比如B+树层数太多、回表次数多等情况)的SQL,并且有很多SQL会命中相同的页面(Page)的话,InnoDB会在自己的内存缓冲区(Buffer Pool)里,开辟一块区域,建立自适应哈希索引(Adaptive Hash Index,AHI),以加速查询。
MySQL 5.5 版本开始提供AHI特性,并在后续版本持续改进。在最新的8.0.33版本中依然将该特性默认开启。

首先,我们来看一下上图中两个InnoDB内部的B树结构,左边的primary key主键索引,右边是secondary key二级索引。当我们需要找到主键值为5的记录时,就需要从主键索引B数的根节点开始,一直搜索到叶子,找到最下面的左边第二页,然后定位到记录(5…)。而当我们想要查找二级索引键值为35的那条记录的时候,就会先搜索左边的二级索引B树,然后定位到(35,5)这条二级索引记录,再通过对应的主键5到左边的主键索引中找到(5…)这条完整的数据记录。
而如下图所示,AHI通过建立主键5到数据所在数据页的hash索引,可以直接定位到记录(5…)所在的数据页,也就是左边数第二个数据页。如此,在查找记录的时候就省略了从根节点到叶子节点的搜索过程。

如下图所示,AHI的主要数据结构是多个哈希表,可以看做它是B+树索引的hash索引

优势场景:读多写少,并且是叶节点定位占比多的场景 。
Doublewrite Buffer
Doublewrite Buffer,翻译成中文:双写缓冲区,缩写:DWB。Doublewrite 是保障 InnoDB 存储引擎操作数据页的可靠性。
我们都知道 innodb 默认一页是 16K,而操作系统 Linux 内存页是 4K,那么一个 innodb 页对应 4 个系统页。所以 innodb 的一页数据要刷盘等于需要写四个系统页。
如下图所示:Buffer Pool中的Page1 对应,系统页中的Page1,Page2,Page3,Page4,在写Page4的时候出现了断电了,则会出现:重启后,MySQL内Page 1的页,物理上对应磁盘上的Page 1、Page 2、Page 3三个页,数据完整性被破坏。(Redo Log无法修复这类“页数据损坏”的异常,修复的前提是“页数据正确”并且Redo日志正常)

针对上面出现的情况,如何解决这类“页数据损坏”的问题呢?很容易想到的方法是,能有一个“副本”,对原来的页进行还原,这个存储“副本”的地方,就是Doublewrite Buffer。
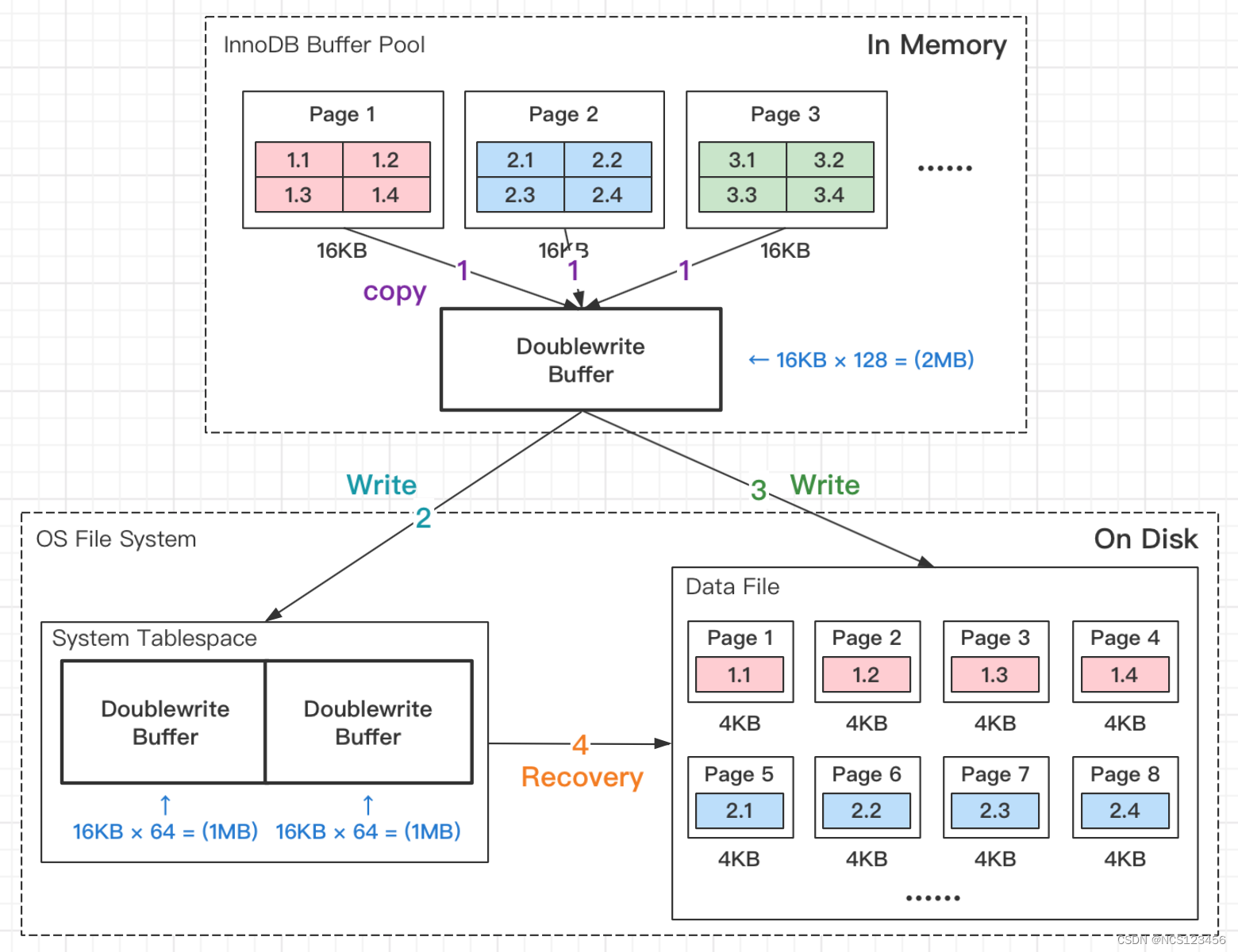
如上图所示,当有页数据要刷盘时:
第1步:页数据先memcopy到DWB的内存里;
第2步:DWB的内存里的数据页,会先刷到DWB的磁盘上;
第3步:DWB的内存里的数据页,再刷到数据磁盘存储.ibd文件上;
第4步:如果出现如上断电场景,从DWB FILE中恢复数据盘;
备注:DWB内存结构由128个页(Page)构成,所以容量只有:16KB × 128 = 2MB。
![【源头活水】顶刊解读!IEEE T-PAMI (CCF-A,IF 23.6)2024年46卷第一期 [1]](https://img-blog.csdnimg.cn/img_convert/94ec459434c1ec54559a5b4cbe122d09.png)