“问渠那得清如许,为有源头活水来”,通过前沿领域知识的学习,从其他研究领域得到启发,对研究问题的本质有更清晰的认识和理解,是自我提高的不竭源泉。为此,我们特别精选论文阅读笔记,开辟“源头活水”专栏,帮助你广泛而深入的阅读科研文献,敬请关注
联邦学习、数据异质性、贝叶斯理论
L. Liu et al., "A Bayesian Federated Learning Framework With Online Laplace Approximation," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 1-16, Jan. 2024, doi: 10.1109/TPAMI.2023.3322743.关键词:联邦学习、数据异质性、贝叶斯理论
论文网址:
https://ieeexplore.ieee.org/document/10274722
联合学习(FL)允许多个客户端通过模型聚合和本地模型训练循环,协作学习一个全球共享的模型,而无需共享数据。大多数现有的联合学习方法都是在不同的客户端上分别训练本地模型,然后简单地平均参数,在服务器端获得一个集中模型。然而,这些方法普遍存在较大的聚合误差和严重的局部遗忘问题,在异构数据环境中尤为严重。为了解决这些问题,我们在本文中提出了一种新颖的 FL 框架,它使用在线拉普拉斯近似法来近似客户端和服务器端的后验。在服务器端,采用多变量高斯乘积机制来构建和最大化全局后验,从而大大减少了局部模型之间的巨大差异所引起的聚合误差。在客户端,设计了一种先验损失,使用服务器发送的全局后验概率参数来指导本地训练。结合来自其他客户端的此类学习约束,我们的方法就能减轻局部遗忘。最后,我们在多个基准测试中取得了最先进的结果,清楚地证明了所提方法的优势。
下图为整体系统架构图

数据集蒸馏综述
S. Lei and D. Tao, "A Comprehensive Survey of Dataset Distillation," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 17-32, Jan. 2024, doi: 10.1109/TPAMI.2023.3322540.论文网址:
https://ieeexplore.ieee.org/document/10273632
深度学习技术在过去十年中得到了前所未有的发展,已成为许多应用领域的首选。这一进步主要归功于系统性合作,快速增长的计算资源鼓励先进算法处理海量数据。然而,以有限的计算能力处理无限增长的数据逐渐成为一项挑战。为此,人们提出了多种方法来提高数据处理效率。数据集蒸馏作为一种数据集缩减方法,通过从大量数据中合成一个小的典型数据集来解决这一问题,引起了深度学习界的广泛关注。根据是否明确模仿目标数据的性能,现有的数据集提炼方法可分为元学习框架和数据匹配框架。虽然数据集蒸馏法在压缩数据集方面表现出了令人惊讶的性能,但仍然存在一些局限性,例如蒸馏高分辨率数据或具有复杂标签空间的数据。本文从蒸馏框架和算法、因式分解数据集蒸馏、性能比较和应用等多个方面全面介绍了数据集蒸馏。最后,我们讨论了数据集蒸馏所面临的挑战和有前景的方向,以进一步推动数据集蒸馏的未来研究。
下图为整体系统架构图

机器学习用于美学评估、现实主义绘画评价
Z. Zhang et al., "A Machine Learning Paradigm for Studying Pictorial Realism: How Accurate are Constable's Clouds?," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 33-42, Jan. 2024, doi: 10.1109/TPAMI.2023.3324743.关键词:机器学习用于美学评估、现实主义绘画评价
论文网址:
https://zh.wikipedia.org/wiki
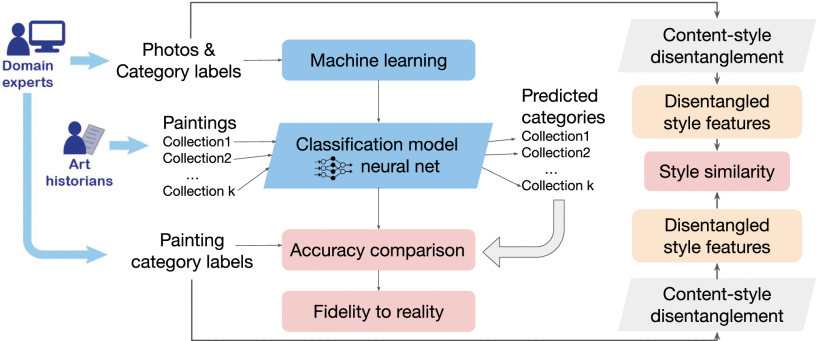
英国风景画家约翰·康斯特勃尔被认为是 19 世纪欧洲现实主义绘画运动的奠基人。尤其是康斯特勃绘制的天空,在他同时代的人看来非常准确,今天的许多观众也有同感。然而,即使对专业艺术史学家来说,评估康斯特布尔等现实主义绘画作品的准确性也是主观或直观的,因此很难肯定地说康斯特勃的天空与其同时代的作品有何不同。我们的目标是帮助人们更客观地理解康斯特勃的现实主义作品。我们提出了一种基于机器学习的新范式,用于以可解释的方式研究绘画的现实主义。我们的框架通过测量康斯特勃等以天空著称的艺术家所绘云彩与云彩照片之间的相似度来评估现实主义。云彩分类的实验结果表明,康斯特勃比他同时代的艺术家更接近他画中实际云彩的形式特征。这项研究是一种新颖的跨学科方法,它将计算机视觉和机器学习、气象学和艺术史结合在一起,是更广泛、更深入地分析绘画写实主义的跳板。
引注:英国风景画画家约翰·康斯特勃(John Constable,1776-1837),他的很多作品描绘的是家乡附近的戴德姆谷风景,此地因此得名“康斯特勃之乡”(Constable Country)

Two Cloud Study oil paintings by John Constable (1822). Left: Yale Center for British Art. Right: The Frick Collection.
下图为整体系统架构图
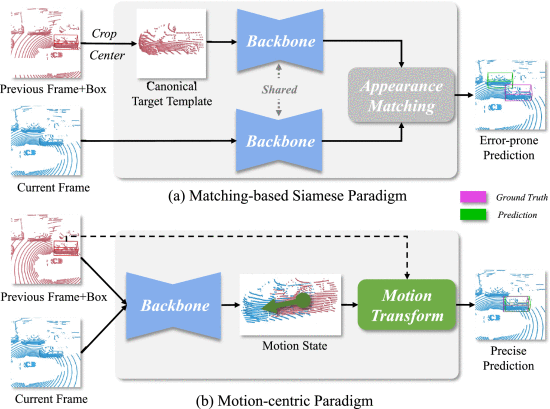
自动驾驶、3D物体跟踪、激光雷达点云、运动为中心范式
C. Zheng et al., "An Effective Motion-Centric Paradigm for 3D Single Object Tracking in Point Clouds," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 43-60, Jan. 2024, doi: 10.1109/TPAMI.2023.3324372.关键词:自动驾驶、3D物体跟踪、激光雷达点云、运动为中心范式
激光雷达点云中的三维单个物体跟踪(LiDAR SOT)在自动驾驶中起着至关重要的作用。目前的方法都遵循基于外观匹配的连体模式。然而,LiDAR 点云通常没有纹理且不完整,这阻碍了有效的外观匹配。此外,以往的方法也极大地忽略了目标之间的关键运动线索。在这项工作中,除了三维连体跟踪之外,我们还引入了以运动为中心的范式,从一个全新的角度来处理激光雷达 SOT。根据这一范式,我们提出了一种无匹配的两阶段跟踪器M2-Track。在第一阶段,M2-Track 通过运动变换在连续帧内定位目标。然后,在第2 阶段,它将通过定位辅助形状补全来完善目标框。由于我们的方法以运动为中心,因此在训练标签有限的情况下也能显示出令人印象深刻的通用性,并为端到端循环训练提供了良好的可区分性。这启发我们探索半监督式激光雷达 SOT,将基于伪标签的运动增强和自监督损失项结合起来。在全监督设置下,大量实验证实,在以57FPS速度运行的三个大型数据集上,"追踪 "的精度明显优于之前的技术水平(在 KITTI、NuScenes 和 Waymo Open Dataset 上的精度分别提高了3%、11%和22%)。在半监督设置下,我们的方法在使用不到一半的 KITTI 标签时,表现与完全监督方法相当,甚至超过了完全监督方法。进一步的分析验证了每个组件的有效性,并显示了以运动为中心的范式在自动标记和无监督领域适应方面的巨大潜力。
下图为整体系统架构图
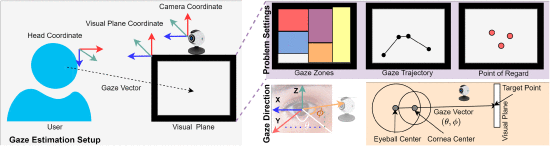
基于深度学习的视线估计和分析综述
S. Ghosh, A. Dhall, M. Hayat, J. Knibbe and Q. Ji, "Automatic Gaze Analysis: A Survey of Deep Learning Based Approaches," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 61-84, Jan. 2024, doi: 10.1109/TPAMI.2023.3321337.论文地址:
https://ieeexplore.ieee.org/document/10319064
视线估计和分析是计算机视觉和人机交互领域的一个重要研究课题。即使在过去 10 年中取得了显著进展,但由于眼睛外观、眼头相互作用、遮挡、图像质量和光照条件的独特性,自动视线分析仍然具有挑战性。有几个问题尚未解决,包括在没有事先了解的情况下,在无约束环境中解释注视方向的重要线索是什么,以及如何实时编码这些线索。我们回顾了一系列视线分析任务和应用的进展,以阐明这些基本问题,确定视线分析的有效方法,并提供可能的未来方向。我们分析了最近的视线估计和分割方法,特别是在无监督和弱监督领域,并根据其优势和报告的评估指标进行了分析。我们的分析表明,开发稳健、通用的视线分析方法仍需应对现实世界的挑战,如无约束设置和少监督学习。最后,我们讨论了设计真实世界视线分析系统的未来研究方向,该系统可推广到计算机视觉、增强现实(AR)、虚拟现实(VR)和人机交互(HCI)等其他领域。
引注:本文作者之一为纪强(Qiang Ji)教授,IEEE Fellow, 在华盛顿大学获得电气工程博士学位。他是伦斯勒理工学院(RPI)电气、计算机和系统工程系教授。他曾担任美国国家科学基金会的项目主任,负责管理国家科学基金会的计算机视觉和机器学习项目。他还曾在伊利诺伊大学香槟分校、卡内基梅隆大学和内华达大学里诺分校担任教学和研究职务。他的研究兴趣是计算机视觉、概率机器学习及其应用。他发表过 300 多篇论文,获得过多个奖项,担任过多个国际期刊的编辑,组织过多次国际会议/研讨会。他还是 IAPR Fellow。
下图为整体系统架构图

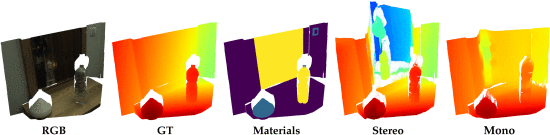
基于图像的深度估算、非朗伯体、高光和透明表面深度估计
P. Z. Ramirez et al., "Booster: A Benchmark for Depth From Images of Specular and Transparent Surfaces," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 85-102, Jan. 2024, doi: 10.1109/TPAMI.2023.3323858.关键词:基于图像的深度估算、非朗伯体、高光和透明表面深度估计
论文地址:
https://ieeexplore.ieee.org/document/10278453
从图像中估算深度在域内精度和通用性方面都取得了卓越的成果。然而,我们发现该领域仍存在两大挑战:处理非朗伯体材料和有效处理高分辨率图像。为此,我们提出了一个新颖的数据集,其中包括高分辨率下精确而密集的真实标注标签,以及包含多个镜面和透明表面的场景。我们的采集流程采用了新颖的深度时空立体框架,能够以亚像素精度轻松准确地进行标注。数据集由在 85 个不同场景中采集的 606 个样本组成,每个样本都包括一对高分辨率(12 Mpx)和一对非平衡立体(左:12 Mpx,右:1.1 Mpx),这是安装了不同分辨率传感器的现代移动设备的典型特征。此外,我们还提供了人工标注的材料分割掩码和 15 K 个未标注样本。数据集由一个训练集和两个测试集组成,后者专门用于评估立体和单目深度估算网络。我们的实验凸显了该领域的挑战和未来研究方向。

下图为整体系统架构图

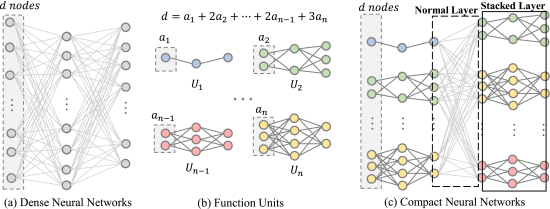
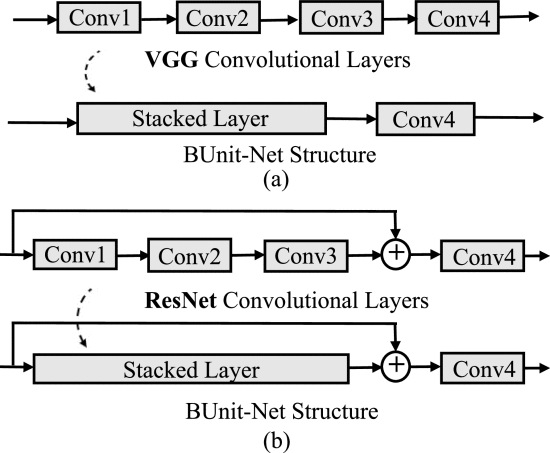
深度神经网络压缩、模型剪枝、结构化剪枝
W. Lan, Y. -M. Cheung, J. Jiang, Z. Hu and M. Li, "Compact Neural Network via Stacking Hybrid Units," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 103-116, Jan. 2024, doi: 10.1109/TPAMI.2023.3323496.关键词:深度神经网络压缩、模型剪枝、结构化剪枝
论文地址:
https://ieeexplore.ieee.org/document/10275036
作为一种有效的神经网络压缩工具,剪枝技术已被广泛用于减少深度神经网络(NN)中的大量参数。然而,非结构化剪枝在处理稀疏和不规则权重方面存在局限性。相比之下,结构化剪枝有助于消除这一缺点,但它需要复杂的标准来确定哪些组件需要剪枝。因此,本文提出了一种称为 BUnit-Net 的新方法,它通过堆叠设计好的基本单元直接构建紧凑型 NN,而不再需要额外的判断标准。给定各种架构的基本单元后,将它们系统地组合和堆叠,从而构建出紧凑型 NN,由于单元之间的独立性,这些 NN 所涉及的权重参数较少。这样,BUnit-Net 就能达到与非结构化剪枝相同的压缩效果,而权重张量仍能保持规则和密集。我们在不同的基准数据集上与最先进的剪枝方法进行了比较,并在各种流行的骨干网中制定了 BUnit-Net。此外,我们还提出了两个新指标来评估压缩性能的权衡。实验结果表明,BUnit-Net 在节省约 80% FLOPs 和 73% 参数的同时,还能达到相当的分类准确率。也就是说,堆叠基本单元为网络压缩提供了一种新的有前途的方法。
下图为整体系统架构图
元学习、实例模糊性、多嵌入空间分解、多义嵌入的跨上下文比较
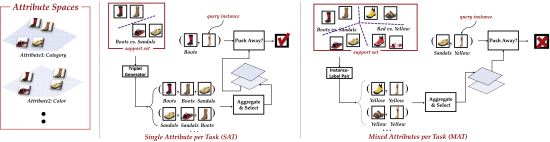
H. -J. Ye, D. -W. Zhou, L. Hong, Z. Li, X. -S. Wei and D. -C. Zhan, "Contextualizing Meta-Learning via Learning to Decompose," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 117-133, Jan. 2024, doi: 10.1109/TPAMI.2023.3317425.关键词:元学习、实例模糊性、多嵌入空间分解、多义嵌入的跨上下文比较
元学习已成为一种基于支持集构建目标模型的高效方法。例如,元学习嵌入通过将实例拉近其同类邻居,从而为特定任务构建目标近邻分类器。然而,单个实例可以由各种潜在属性注释,使得支持集内部或跨支持集的视觉相似实例具有不同的标签和与其他实例的不同关系。因此,从支持集推断目标模型的统一元学习策略无法捕捉到实例方面的模糊相似性。为此,我们提出了 "学习分解网络"(Learning to Decompose Network,简称 LeadNet),利用支持集中具有一个或混合潜在属性的实例的上下文,将元学习的 "支持到目标 "策略情境化。具体来说,实例之间的比较关系是根据多个嵌入空间进行分解的。通过结合多义嵌入的跨上下文比较变化,LeadNet 学会自动选择与正确属性相关的策略。我们证明了 LeadNet 在各种应用中的优越性,包括探索混乱数据的多个视图、分布外识别和少样本图像分类。
下图为整体系统架构图
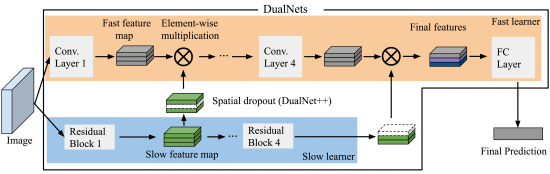
持续学习、互补学习系统理论(CLS)、慢速和快速学习系统
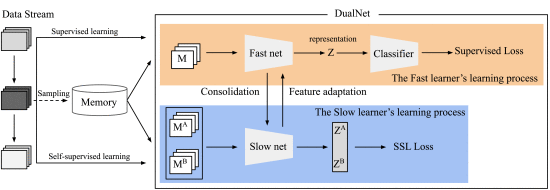
Q. Pham, C. Liu and S. C. H. Hoi, "Continual Learning, Fast and Slow," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 134-149, Jan. 2024, doi: 10.1109/TPAMI.2023.3324203.关键词:持续学习、互补学习系统理论(CLS)、慢速和快速学习系统
论文网址:
https://ieeexplore.ieee.org/document/10285461
根据神经科学中的互补学习系统(CLS)理论(McClelland 等人,1995 年),人类通过两个互补系统进行有效的持续学习:一个是以海马体为中心的快速学习系统,用于快速学习具体的个体经验;另一个是位于新皮层的慢速学习系统,用于逐步获取有关环境的结构化知识。受这一理论的启发,我们提出了双网络(DualNets),这是一个通用的持续学习框架,由一个快速学习系统和一个慢速学习系统组成,前者用于监督学习从特定任务中分离出来的模式表征,后者则通过自我监督学习(SSL)学习与任务无关的一般表征。DualNets 可以将这两种表征类型无缝整合到一个整体框架中,从而促进深度神经网络更好地持续学习。通过广泛的实验,我们展示了 DualNets 在各种持续学习协议上的良好效果,从标准的离线、任务感知设置到具有挑战性的在线、无任务场景。值得注意的是,在 CTrL(Veniat 等人,2020 年)基准上,DualNets 可以实现与现有最先进的动态架构策略(Ostapenko 等人,2021 年)相媲美的性能。此外,我们还进行了全面的消融研究,以验证 DualNets 的功效、鲁棒性和可扩展性。
引注:互补学习理论(Complementary Learning Systems,CLS)认为,有效的学习需要两个互补的系统:第一个系统位于新皮层,用于逐渐学习有关环境的结构化知识;另一个系统位于海马体,用于个体经验细节的快速学习。总的来说,CLS理论提供了刻画大脑学习过程的框架。CLS理论起源于David Mar等人的早期想法,提供了海马体和新皮层计算功能和特征的综合,不仅能解释丰富的经验知识,还用理性的视角推理智能主体所面临的挑战。CLS理论的中心原则就是,新皮层包含了一个结构化的知识表征,该知识表征是以新皮层中神经元相互连接的方式储存的。这个原则起源于对多层神经网络的观察,即:训练时,多层神经网络通过调整神经元的连接权重来最小化网络输出的误差,进而学会如何提取结构(特征)。
下图为整体系统架构图
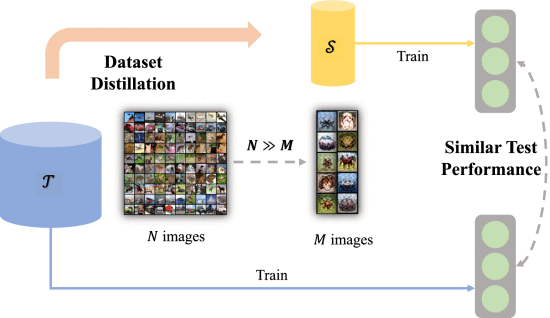
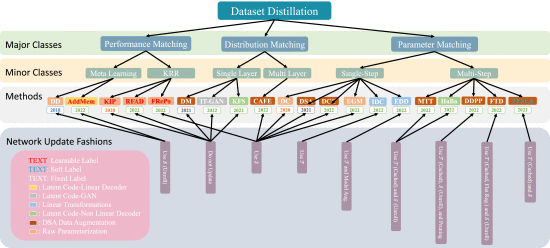
数据集蒸馏综述
R. Yu, S. Liu and X. Wang, "Dataset Distillation: A Comprehensive Review," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 1, pp. 150-170, Jan. 2024, doi: 10.1109/TPAMI.2023.3323376.数据集蒸馏综述(另外一篇)
深度学习最近取得的成功在很大程度上归功于用于训练深度神经网络的海量数据。尽管取得了前所未有的成功,但不幸的是,海量数据大大增加了存储和传输的负担,并进一步导致模型训练过程的繁琐。此外,依赖原始数据进行训练本身也会产生隐私和版权方面的问题。为了解决这些问题,人们提出了数据集蒸馏(Dataset distillation,DD),也称为数据集浓缩(Dataset condensation,DC),并在最近引起了研究界的广泛关注。给定一个原始数据集,DD 的目的是得到一个包含合成样本的更小的数据集,在此基础上训练出的模型性能可与在原始数据集上训练出的模型相媲美。在本文中,我们将全面回顾和总结 DD 及其应用的最新进展。我们首先正式介绍了这项任务,并提出了所有现有 DD 方法所遵循的总体算法框架。接下来,我们对该领域的现有方法进行了系统分类,并讨论了它们之间的理论联系。我们还通过广泛的实证研究介绍了 DD 目前面临的挑战,并展望了未来工作的可能方向。
下图为整体系统架构图
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
收藏,分享、在看,给个三连击呗!