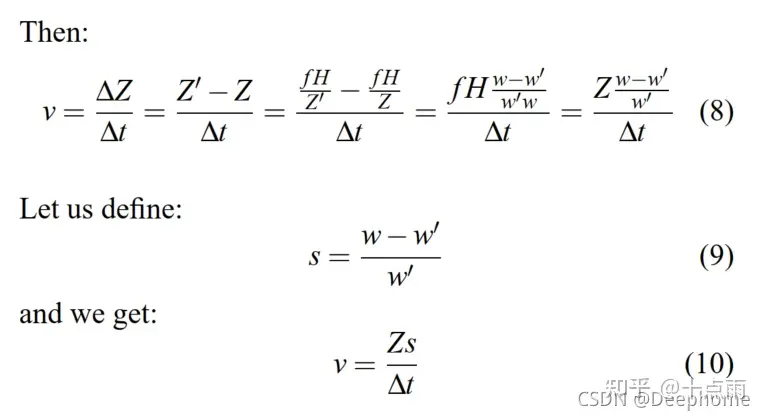好久不见,关于这篇文章,我也是想了很久,还是决定写一篇文章,有很多同学问过 mysql 相关的问题,其实关联查询如何优化,首先我们要知道关联查询的原理是什么?
左连接 left join
SELECT
字段列表
FROM
A表
LEFT JOIN
B表
ON 关联条件
WHERE 等其他子句
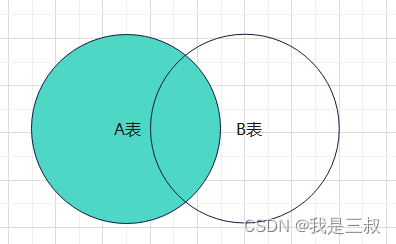
两表关联,以 left 左边的表为主表进行查询,除了返回满足连接条件的行以外,还返回左表中不满足条件的行。
如图所示:A 表是主表(驱动表),B 表是从表(被驱动表),颜色区域即所得结果集,结果集中返回匹配的行(交集),也返回 A 表中不匹配的行,不匹配字段用 NULL 表示。
右连接 right join
SELECT
字段列表
FROM
A表
RIGHT JOIN
B表
ON 关联条件
WHERE 等其他子句
两表关联,以 right 右边的表为主表进行查询,除了返回满足连接条件的行以外,还返回右表中不满足条件的行。
如图所示:B 表是主表(驱动表),A 表是从表(被驱动表),颜色区域即所得结果集,结果集中返回匹配的行(交集),也返回 B 表中不匹配的行,不匹配字段用 NULL 表示。(同 left join,只不过主表位置不同)
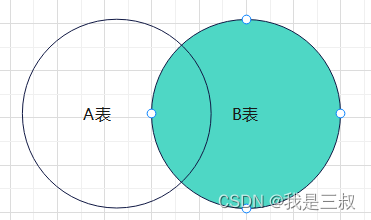
内连接 inner join
SELECT
字段列表
FROM
A表
INNER JOIN
B表
ON 关联条件
WHERE 等其他子句;
两表关联,返回符合 where 条件的结果集,即是 A 表 结果集,也是 B 表结果集,内联查询,没有左右主表之分,以哪张表为驱动表,取决于 MySQL service 层的优化器自己决定。
如图所示:

关联查询原理
前面讲解了连接查询的几种方式,现在谈谈 MySQL 底层是支持这几种连接查询的。
关联查询中涉及到多表的的查询,根据驱动类型分为驱动表和被驱动表,驱动表就是主表,被驱动表就是从表。
那么 MySQL 是如何进行join查询的呢?
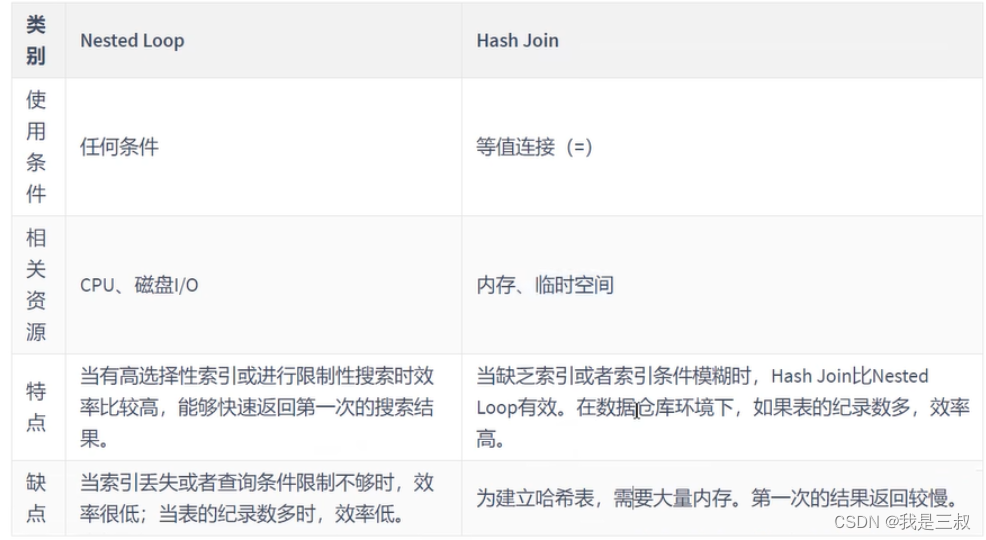
1.Simple Nested-Loop Join (简单嵌套循环连接)
是从驱动表 A 中取出一条数据,遍历表 B,将匹配到的数据放到result,以此类推, 如下图所示:
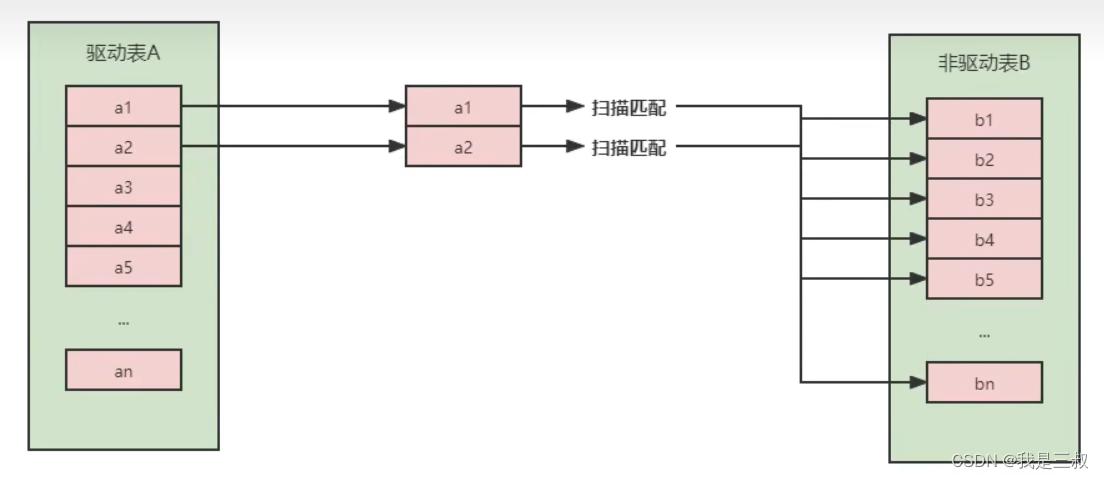
比如驱动表A有10条,被驱动表B有100条,那么扫描次数是A+A*B, 每一次扫描其实就是从硬盘中读取数据加载到内存中,也就是一次IO,而IO是最大的瓶颈,所以效率低下,开销如下表:
| 开销统计 | 简单嵌套循环连接 |
|---|---|
| 驱动表扫描次数 | 1 |
| 被驱动表扫描次数 | A |
| 读取记录数 | A+B*A |
| JOIN比较次数 | B*A |
| 回表读取记录次数 | 0 |
当然 MySQL 肯定不会这么粗暴的去进行表的连接,所以就出现了后面的两种对 Nested-Loop Join 优化算法。
2.Block Nested-Loop Join (块嵌套循环连接)
块嵌套循环连接是对上面一种算法的优化,简单嵌套是去驱动表中获取数据去匹配,和磁盘 IO 交互太多了,那么能否以一种批量的方式进行优化呢?mybatis 批量插入批量查询也是这个道理。而这种算法就是借鉴了这样的思想。
不再是逐条获取驱动表的数据,而是一块一块的获取,引入了 join buffer 缓冲区,将驱动表join相关的部分数据列、缓存到join buffer中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和join buffer中的所有驱动表记录进行匹配(内存中操作),将简单嵌套循环中的多次比较合并成一次,降低了被驱动表的访问频率。整体如下图所示:

需要注意的是:从驱动表中缓存的列不仅仅是关联的的列,select 后面的列也会缓存起来。因此,为了能让 join buffer 缓存更多的数据,我们的 SQL 尽量不要 select *, 而是 select 用到的字段。
开销如下表:
| 开销统计 | 块嵌套循环连接 |
|---|---|
| 驱动表扫描次数 | 1 |
| 被驱动表扫描次数 | A*used_column_size/join_buffer_size+1 |
| 读取记录数 | A+B*(A*used_column_size/join_buffer_size) |
| JOIN比较次数 | B*A |
| 回表读取记录次数 | 0 |
join buffer的大小是可以设置的,默认情况下 join_buffer_size=256k。
join_buffer_size 的最大值在32位操作系统可以申请4G,而在64位操作系统下可以申请大于4G的 Join Buffer 空间(64位Windows除外,其大值会被截断为4GB并发出警告)。
3.Index Nested-Loop Join (索引嵌套循环连接)
索引嵌套循环连接(Index Nested-Loop Join)就是效率最高的,前提条件是被驱动表的关联字段建立了索引。通过驱动表匹配条件直接与被驱动表的索引进行匹配,避免和内存表的每条记录去进行比较,这样极大的减少了对内存表的匹配次数。如下图所示:

因为索引查询的成本基本一样,为了降低开销,驱动表是小表更加合适。所以我们常说把小表当作主表是有原因的。
开销如下表:
| 开销统计 | 索引嵌套循环连接 |
|---|---|
| 驱动表扫描次数 | 1 |
| 被驱动表扫描次数 | 0 |
| 读取记录数 | A+B(match) |
| JOIN比较次数 | A*Index(Height) |
| 回表读取记录次数 | B(match)(if possible) |
如果被驱动表加索引,效率是非常高的,但如果索引不是主键索引,所以还得进行一次回表查询。相比,被驱动表的索引是主键索引,效率会更高。
块嵌套循环连接:对于被连接的数据子集较小的情况下,它是个较好的选择。
Hash Join: 是做大数据集连接时的常用方式,优化器使用两个表中较小(相对较小)的表利用 Join Key 在内存中建立散列值,然后扫描较大的表并探测散列值,找出与 Hash 表匹配的行。它能够很好的工作于没有索引的大表和并行查询的环境中,并提供最好的性能。Hash Join 只能应用于等值连接,这是由 Hash 的特点决定的。
总结:优化建议
前面讲了原理,从原理出发,讲一下优化的建议
- 被驱动表的连接字段建立索引,因为建立索引的查询方式是效率最高的。
- left join 或者 right join 这种外连接的情况,要保证小表(小结果集)作为驱动表,大表(大结果集)作为被驱动表,这样性能更好。
- 在查询字段的话,要避免写出 select * ,而是根据业务需要,需要查询出来的 select 出来就行,因为这些字段也会加入到 join buffer 中,减少额外的内存消耗。
- 能够直接多表关联的尽量直接关联,不用子查询,因为子查询的效率更加低。
- 在 sql 的查询计划的 extra 中,尽量避免出现 Using join buffer,有这个表示使用了块嵌套循环连接算法,尽量通过索引去解决。
- 尽量避免超过 3 张表以上的关联查询。