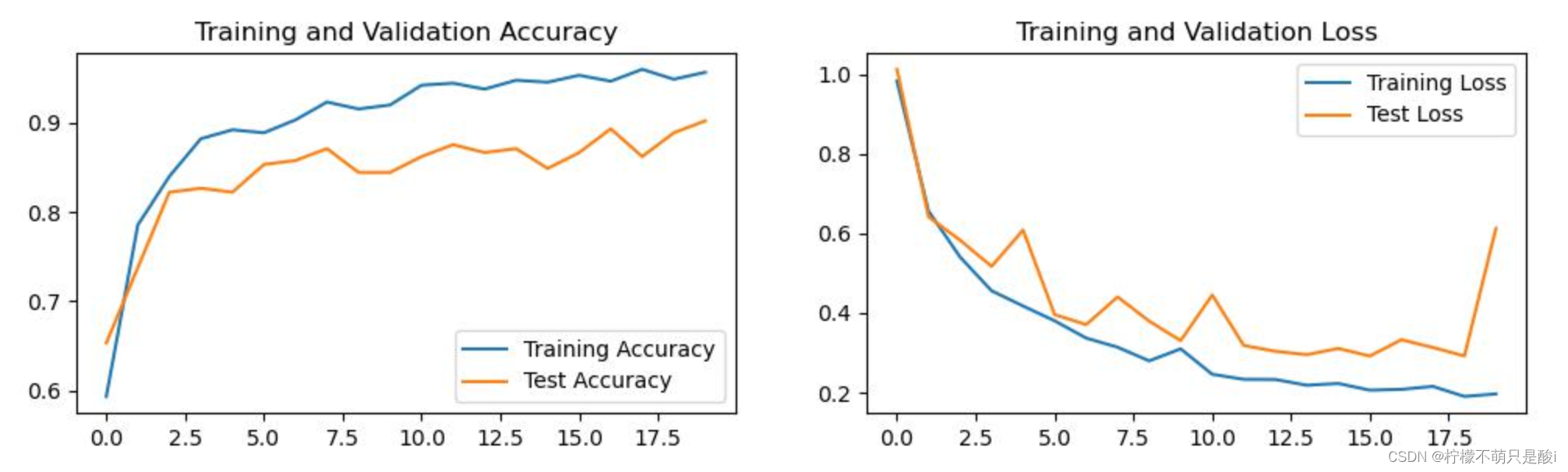
1.线程池的核心参数
线程池核心参数主要参考ThreadPoolExecutor这个类的7个参数的构造函数:
-
corePoolSize核心线程数目
-
maximumPoolSize最大线程数目=(核心线程+救急线程的最大数目)
-
keepAliveTime生存时间:救急线程的生存时间,生存时间内没有新任务,此线程资源会释放
-
unit时间单位:救急线程的生存时间单位,如秒、毫秒等
-
workQueue当没有空闲核心线程时,新来任务会加入到此队队列里,队列满会创建救急线程执行任务
-
threadFactory线程工厂:可以定制线程对象的创建,如设置线程名字、是否守护线程等
-
handler拒绝策略:当所有线程都在繁忙,workQueue也放满时,会触发拒绝策略

工作流程:
-
任务在提交的时候,首先判断核心线程数是否已满,如果没有满则直接添加到工作线程执行。
-
如果核心线程满了,则判断阻塞队列是否已满,如果没有满,当前任务存储阻塞队列。
-
如果阻塞队列也满了,则判断线程数是否小于最大线程数,如果满足条件,则使用临时线程执行任务。【如果核心或临时线程执行完成任务后会检查阻塞队列中是否有需要执行的线程,如果有,则使用非核心线程执行任务】
-
如果所有线程都忙着(核心线程+临时线程)则走拒绝策略。
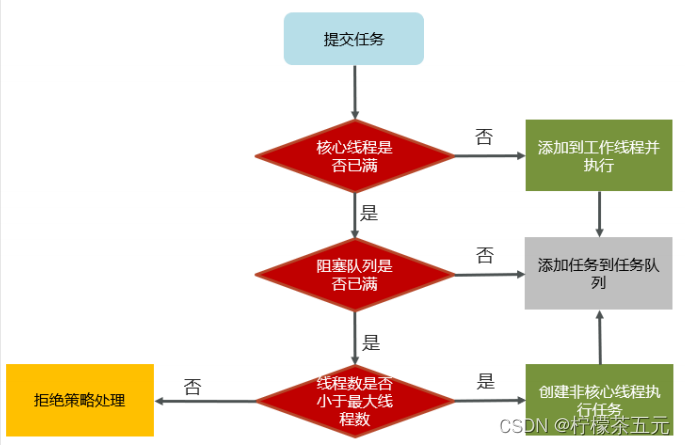
拒绝策略:
-
AbortPolicy:直接抛出异常,默认策略
-
CallerRunPolicy:用调用者所在的线程来执行任务
-
DiscardOldestPolicy:丢弃阻塞队列中靠前的任务,并执行当前任务
-
DiscardPolicy:直接丢弃任务
2.线程池常见的阻塞队列
常见的有4个,最多用的是ArrayBlockingQueue和LinkedBlockingQueue
-
ArrayBlockingQueue:基于数组结构的有界阻塞队列FIFO
-
LinkedBlockingQueue:基于链表结构的有界阻塞队列FIFO
-
DelayedWorkQueue:是一个优先级队列,可以保证每次出队的任务都是当前队列中执行时间最靠前的
-
SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作
ArrayBlockingQueue和LinkedBlockingQueue的区别:
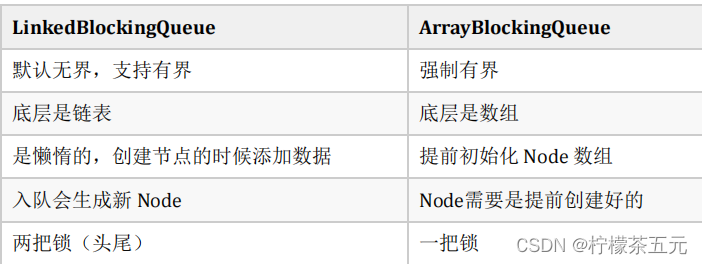
左边是LinkedBlockingQueue加锁的方式,右边是ArrayBlockingQueue加锁的方
式

-
LinkedBlockingQueue读和写各有一把锁,性能相对较好
-
ArrayBlockingQueue只有一把锁,读和写公用,性能相对于
-
LinkedBlockingQueue差一些
3.如何确定核心线程数
设置核心线程数之前,需要熟悉一些执行线程池任务的类型:
-
IO密集型任务:文件读写、DB读写、网络请求
推荐:核心线程数大小设置为2N+1(N为CPU数)
-
CPU密集型任务:计算型代码、Bitmap转换、Gson转换等
推荐:核心线程数大小设置为N+1
① 高并发、任务执行时间短 -->( CPU核数+1 ),减少线程上下文的切换
② 并发不高、任务执行时间长
IO密集型的任务 --> (CPU核数 * 2 + 1)
计算密集型任务 --> ( CPU核数+1 )③ 并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整
体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,增加服务器
是第二步,至于线程池的设置,设置参考(2)
4.线程池的种类
-
创建使用固定线程数的线程池
-
单线程化的线程池
-
可缓存线程池
-
提供了“延迟”和“周期执行”功能的ThreadPoolExecutor
1.创建使用固定线程数的线程池

-
核心线程数与最大线程数一样,没有救急线程
-
阻塞队列是LinkedBlockingQueue,最大容量为Integer.MAX_VALUE
-
场景:适用于任务量已知,相对耗时的任务
2.单线程化的线程池,它只会用唯一的工作线程来执行任 务,保证所有任务按
照指定顺序(FIFO)执行

-
核心线程数和最大线程数都是1
-
阻塞队列是LinkedBlockingQueue,最大容量为Integer.MAX_VALUE
-
适用场景:适用于按照顺序执行的任务
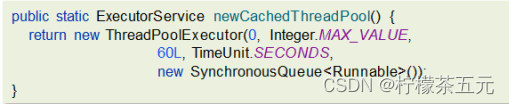
3.可缓存线程池
-
核心线程数为0
-
最大线程数是Integer.MAX_VALUE
-
阻塞队列为SynchronousQueue:不存储元素的阻塞队列,每个插入操作都必须等待一个移出操作。
-
适用场景:适合任务数比较密集,但每个任务执行时间较短的情况
4.提供了“延迟”和“周期执行”功能的ThreadPoolExecutor
适用场景:有定时和延迟执行的任务

5.为什么不建议用Executors创建线程池

6.CountDownLatch
CountDownLatch(闭锁/倒计时锁)用来进行线程同步协作,等待所有线程完成倒计时(一个或者多个线程,等待其他多个线程完成某件事情之后才能执行)
-
其中构造参数用来初始化等待计数值
-
await() 用来等待计数归零
-
countDown() 用来让计数减一

7.控制某个方法允许并发访问线程的数量
Semaphore [ˈsɛməˌfɔr] 信号量,是JUC包下的一个工具类,我们可以通过其限制
执行的线程数量,达到限流的效果当一个线程执行时先通过其方法进行获取许可操作,获取到许可的线程继续执行业务逻辑,当线程执行完成后进行释放许可操作,未获取达到许可的线程进行等待或者直接结束。
Semaphore两个重要的方法
lsemaphore.acquire(): 请求一个信号量,这时候的信号量个数-1(一旦没有可使用的信号量,也即信号量个数变为负数时,再次请求的时候就会阻塞,直到其他线程释放了信号量)
lsemaphore.release():释放一个信号量,此时信号量个数+1
8.谈谈对ThreadLocal的理解
ThreadLocal是多线程中对于解决线程安全的一个操作类,它会为每个线程都分配一个独立的线程副本从而解决了变量并发访问冲突的问题。ThreadLocal 同时实现了线程内的资源共享。
ThreadLocal基本使用:
-
set(value) 设置值
-
get() 获取值
-
remove() 清除值
实现原理:
ThreadLocal本质来说就是一个线程内部存储类,从而让多个线程只操作自己内部的值,从而实现线程数据隔离。在ThreadLocal中有一个内部类叫做ThreadLocalMap,类似于HashMap。ThreadLocalMap中有一个属性table数组,这个是真正存储数据的位置。
ThreadLocal内存泄漏:
Java对象中的四种引用类型:强引用、软引用、弱引用、虚引用
-
强引用:最为普通的引用方式,表示一个对象处于有用且必须的状态,如果一个对象具有强引用,则GC并不会回收它。即便堆中内存不足了,宁可出现OOM,也不会对其进行回收

-
弱引用:表示一个对象处于可能有用且非必须的状态。在GC线程扫描内存区域时,一旦发现弱引用,就会回收到弱引用相关联的对象。对于弱引用的回收,无关内存区域是否足够,一旦发现则会被回收

每一个Thread维护一个ThreadLocalMap,在ThreadLocalMap中的Entry对象继承了WeakReference。其中key为使用弱引用的ThreadLocal实例,value为线程变量的副本