2024年了,你需要网络资源不能还自己再慢慢找吧?
跟着博主一块学习如何利用爬虫获取资源,从茫茫大海中寻找那个她到再妹子群中找妹子,闭着眼睛都可以找到合适的那种。文章有完整示例代码,拿过来就可以用,欢迎实践尝试。
| - | ||||
| ▽ | ˃̣̣̣̣ | ˂ | ▽ | |
| ˗ˏˋ | ˎ˗ |
1.案例简介
本次案例主要针对网络图片下载,使用网络爬虫技术抓取百度图片,能够根据指定的关键字搜索相关主题的图片,然后把图片下载到本地指定的文件夹中。本次讲解内容主题是python,大家实践可以换成自己喜欢的主题。
2.设计思路
目标:通过百度图片引擎入口,抓取指定主题的图片,然后把抓取的图片保存到本地文件夹中。
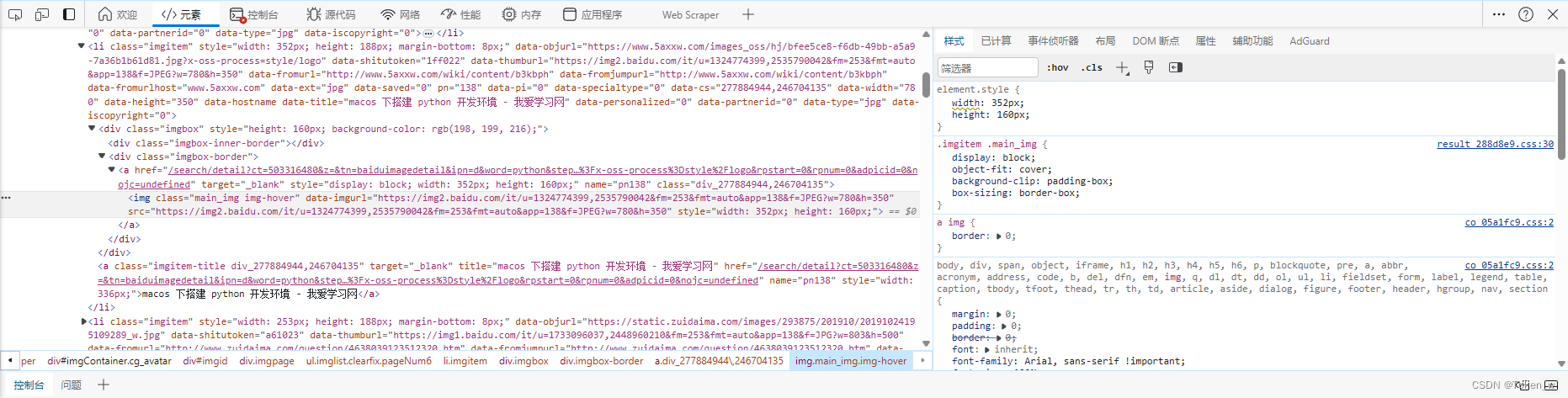
设计爬虫,首先需要把握抓取对象(URL)的规律。分析网页源代码和网页结构,配合F12键查看网页源代码。这一步是抓取成功的关键。
接着,借助HTTP第三方库,获取HTML源代码;使用正则表达式、XPath表达式等技术,解析其结构,根据一定的逻辑分解其中的图片URL。
最后,把网上URL图片保存到本地,完成本例操作。
3.关键技术
把网上图片下载到本地。可以使用request.urlretrieveO函数;也可以使用Python的文件操作函数write()写入文件。
爬取指定网页中的图片。首先用urllib库来模拟浏览器访问网站的页的源代码(htinl标签)。其中,源代码以字符串的形式返回;然后用正则表达式re库在字符串(网页源代码)中匹配表示图片链接的子字符串,返 回一个列表;最后循环列表,根据图片链接将图片保存到本地。
也可以使用BeautifulSoup抓取图片。BeautifulSoup是一个Python处理HTML/XML的函数库,是Python内置的网页分析工具,用来快速地转换被抓取的网页。它产生一个转换后DOM树,尽可能和原文档内容的含义一致,这种措施通常能够满足用户搜集数据的需求。BeautifulSoup提供了一些简单的方法以及类Python语法来查找、定位、修改一棵转换后DOM树。BeautifulSoup自动将送进来的文档转换为Unicode编码,而且在输出的时候转换为UTF-8。
使用requests请求URL和读取网页源代码。requests库和urllib库的作用相似且使用方法基木一致,都是根据HTTP协议操作各种消息和页而,但使用requests库比使用urllib库更简单些。
4.设计过程
第1步,先研究百度图片的入口规律。
进入百度图片(https://image.baidu.com/ ),输入某个关键字(如python),然后单击“百度一下”按钮搜索,可见如下网址:
https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=python&oq=python&rsp=-1

其中,word=python查询字符串表示搜索的主题。所看见的页面是瀑布流版木,当向下滑动的时候可以不停刷新,这是一种动态的网页。需要按F12键,通过Network下的XHR分析网页的结构。

第2步,找到源代码规律之后,就可以动手编写Python代码了。
5.示例结果

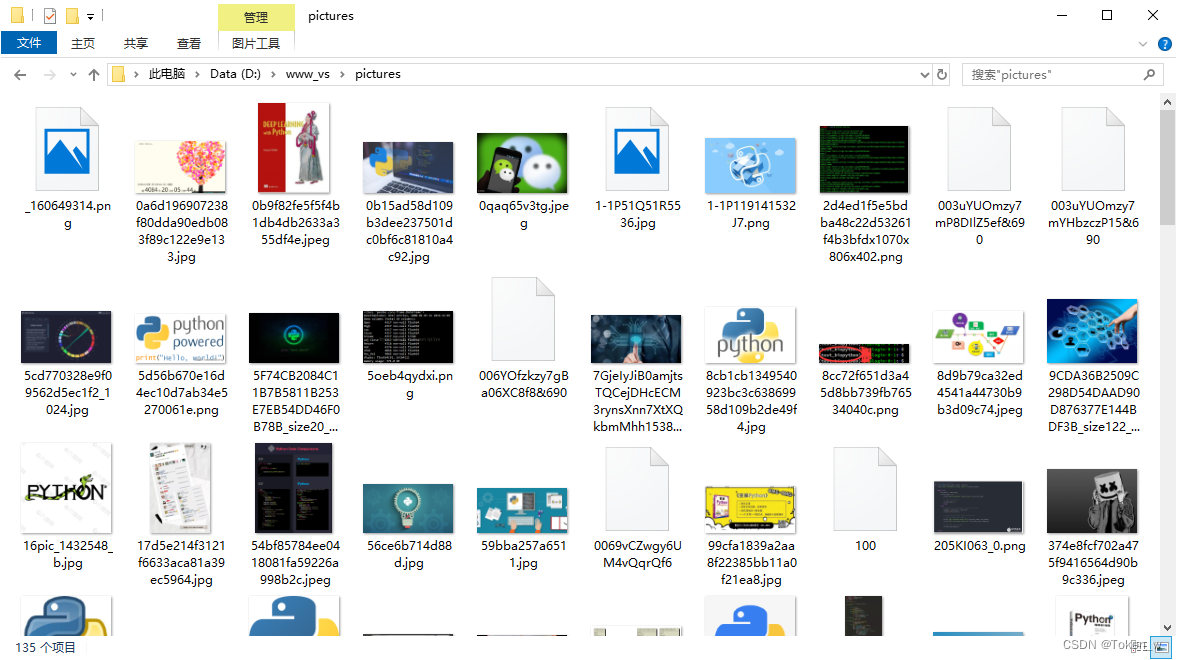
6.示例源码
# test1.py 运行程序之前,需要现在当前目录下创建pictures文件夹。
# 导入库
import requests
import os.path
import re
# 设置默认配置
MaxSearchPage = 20 # 收索页数
CurrentPage = 0 # 当前正在搜索的页数
DefaultPath = "pictures" # 默认储存位置
NeedSave = 0 # 是否需要储存
# 图片链接正则和下一页的链接正则
def imageFiler(content): # 通过正则获取当前页面的图片地址数组
return re.findall('"objURL":"(.*?)"',content,re.S)
def nextSource(content): # 通过正则获取下一页的网址
next = re.findall('<div id="page">.*<a href="(.*?)" class="n">',content,re.S)[0]
print("---------" + "http://image.baidu.com" + next)
return next
# 爬虫主体
def spidler(source):
content = requests.get(source).text # 通过链接获取内容
imageArr = imageFiler(content) # 获取图片数组
global CurrentPage
print("当前页: " + str(CurrentPage) )
for imageUrl in imageArr:
print(imageUrl)
global NeedSave
if NeedSave: # 如果需要保存图片则下载图片,否则不下载图片
global DefaultPath
try:
# 下载图片并设置超时时间,如果图片地址错误就不继续等待了
picture = requests.get(imageUrl,timeout=10)
except:
print("下载错误! errorUrl:" + imageUrl)
continue
# 创建图片保存的路径
# imageUrl = imageUrl.replace('/','').replace(':','').replace('?','')
imageUrl1 = os.path.basename(imageUrl)
basepath = os.getcwd()
print( imageUrl1 )
pictureSavePath = basepath + "/" + DefaultPath + imageUrl1
pictureSavePath = pictureSavePath.split("?")[0]
print(pictureSavePath)
fp = open(pictureSavePath,'wb') # 以写入二进制的方式打开文件
fp.write(picture.content)
fp.close()
global MaxSearchPage
if CurrentPage <= MaxSearchPage: # 继续下一页爬取
if nextSource(content):
CurrentPage += 1
# 爬取完毕后通过下一页地址继续爬取
spidler("http://image.baidu.com" + nextSource(content))
#爬虫的开启方法
def beginSearch(page=1,save=0,savePath="pictures/"):
# (page:爬取页数,save:是否储存,savePath:默认储存路径)
global MaxSearchPage,NeedSave,DefaultPath
MaxSearchPage = page
NeedSave = save # 是否保存,值0不保存,1保存
DefaultPath = savePath # 图片保存的位置
key = input("请输入关键词: ")
StartSource = "http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=" + str(key) + "&ct=201326592&v=flip" # 分析链接可以得到,替换其`word`值后面的数据来搜索关键词
spidler(StartSource)
#调用开启的方法就可以通过关键词搜索图片了
beginSearch(page=5,save=1) # page=5是下载前5页,save=1保存图片