目录
1.原理
2.安装
3.运行
编辑
4.数据集
编辑
4.代码
4.1 model
init编辑
forward:
总结:
关于loss和因果语言模型:
编辑
交叉熵:编辑
记录一下transformers库训练gpt的过程。
transformers/examples/pytorch/language-modeling at main · huggingface/transformers (github.com)
1.原理
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的生成式预训练模型。下面是GPT的基本原理: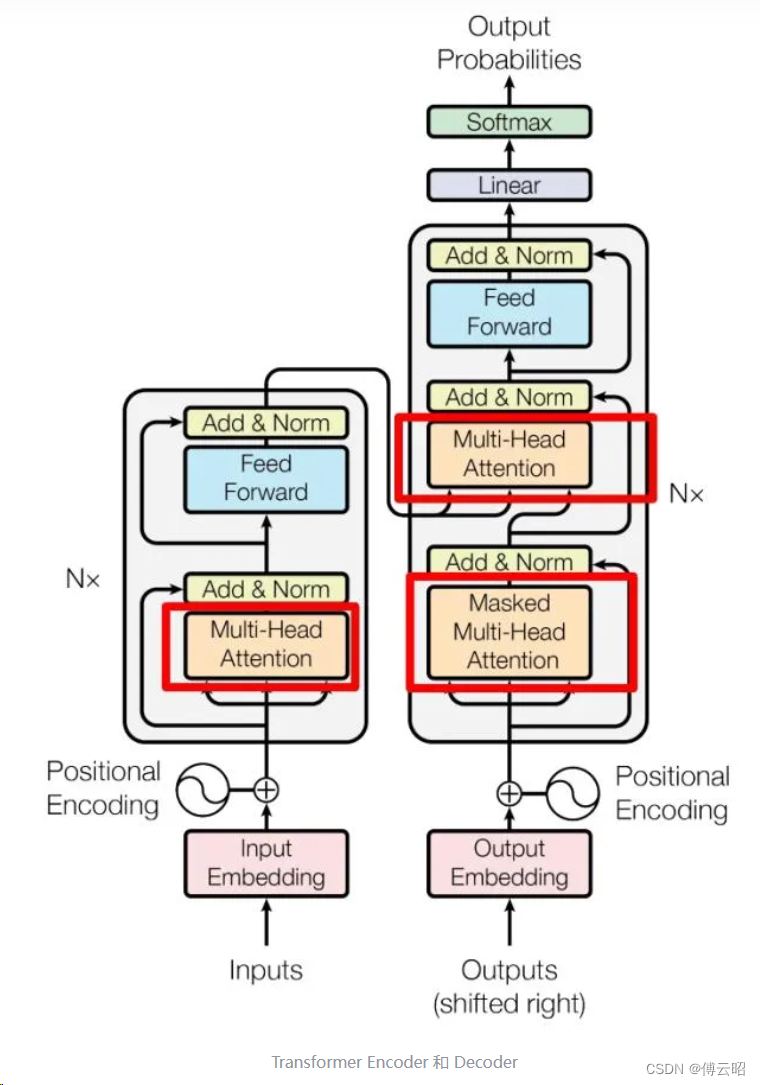
-
Transformer架构:GPT基于Transformer架构,它是一种使用自注意力机制(self-attention)的神经网络模型。Transformer通过在输入序列中的各个位置之间建立相互作用,从而对序列进行并行处理。这种架构在处理长序列和捕捉全局依赖关系方面表现出色。
-
预训练:GPT使用无监督的预训练方式进行训练,这意味着它在大规模的文本数据上进行训练,而无需标注的人工标签。在预训练阶段,GPT模型通过自我监督任务来学习语言的基本特征。常见的预训练任务是语言模型,即根据上下文预测下一个词。
-
多层堆叠:GPT由多个Transformer编码器decoder组成,这些编码器堆叠在一起形成一个深层模型。每个编码器由多个相同结构的自注意力层和前馈神经网络层组成。堆叠多个编码器可以帮助模型学习更复杂的语言特征和抽象表示。
-
自注意力机制:自注意力机制是Transformer的核心组件之一。它允许模型在处理输入序列时对不同位置之间的关系进行建模。通过计算每个位置与其他所有位置之间的相对重要性,自注意力机制能够为每个位置生成一个上下文感知的表示。
-
解码和生成:在预训练阶段,GPT模型学习了输入序列的表示。在生成时,可以使用该表示来生成与输入相关的文本。通过将已生成的词作为输入传递给模型,可以逐步生成连续的文本序列。

能大致讲一下ChatGPT的原理吗? - 知乎 (zhihu.com)
总之,GPT通过使用Transformer架构和自注意力机制,通过大规模无监督的预训练学习语言的基本特征,并能够生成与输入相关的文本序列。这使得GPT在许多自然语言处理任务中表现出色,如文本生成、机器翻译、问题回答等。
2.安装
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
cd examples/pytorch/language-modeling
pip install -r requirements.txt3.运行
transformers/examples/pytorch/language-modeling at main · huggingface/transformers (github.com)

python run_clm.py \
--model_name_or_path openai-community/gpt2 \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--output_dir /tmp/test-clm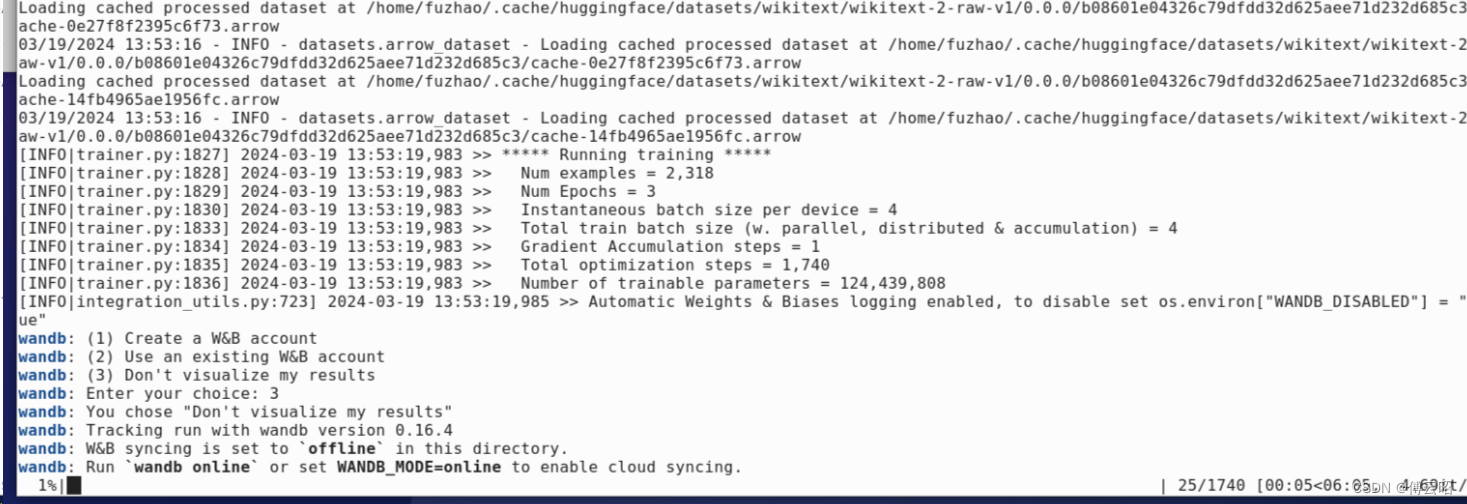
训练开始。
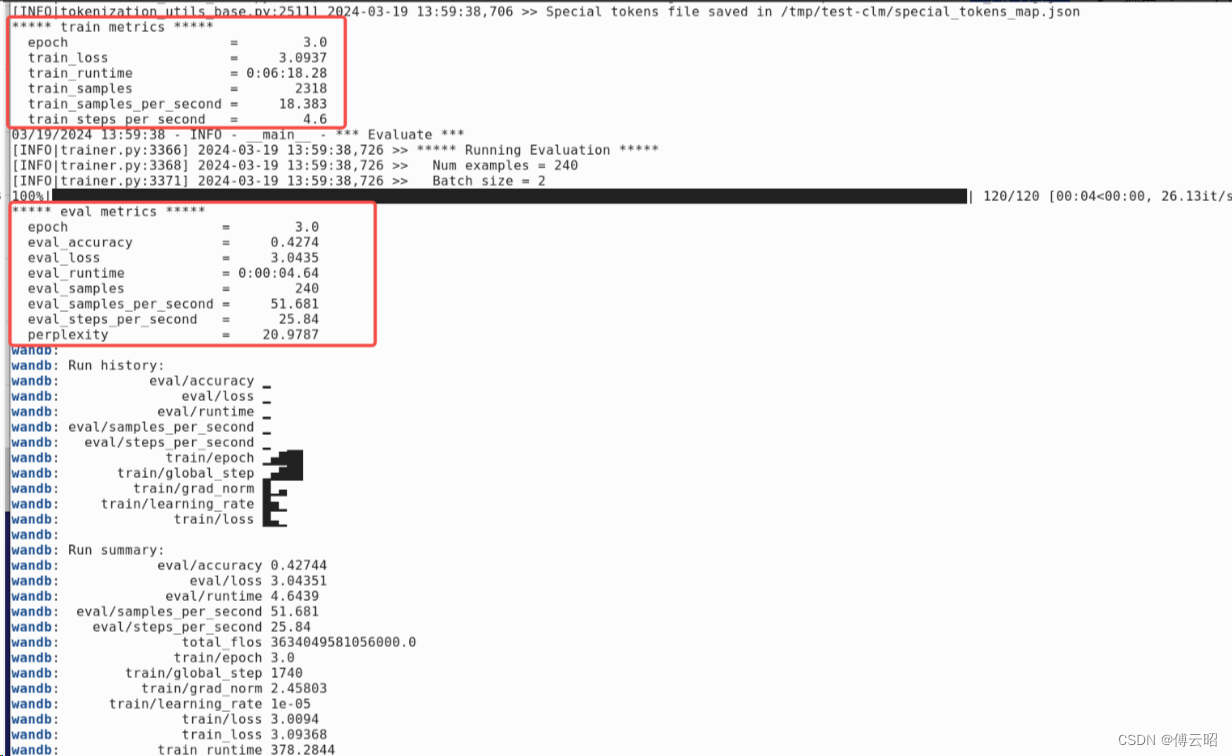
训练结束。
4.数据集
数据集使用的是wikitext
https://security.feishu.cn/link/safety?target=https%3A%2F%2Fblog.csdn.net%2Fqq_42589613%2Farticle%2Fdetails%2F130357215&scene=ccm&logParams=%7B"location"%3A"ccm_docs"%7D&lang=zh-CN
 上面是默认的下载地址
上面是默认的下载地址
数据集就是这样,全部是.json和.arrow文件
读取看一下:
# https://huggingface.co/docs/datasets/v2.18.0/en/loading#arrow
from datasets import Dataset
path = r'C:\Users\PaXini_035\.cache\huggingface\datasets\wikitext\wikitext-2-raw-v1\0.0.0\b08601e04326c79dfdd32d625aee71d232d685c3\wikitext-test.arrow'
dataset = Dataset.from_file(path)
print(1)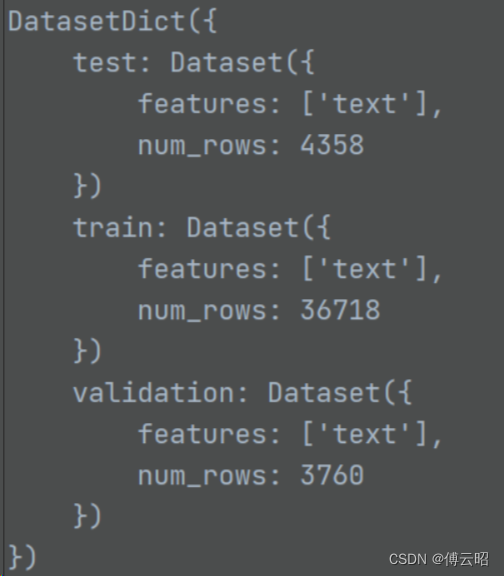
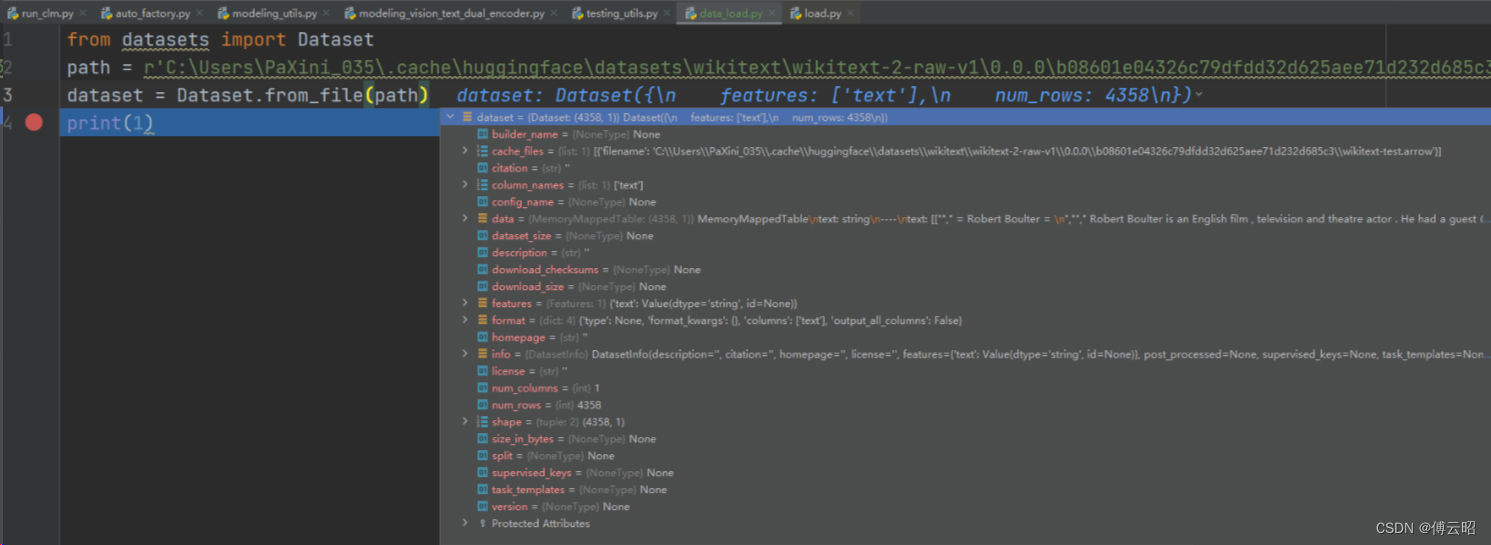

就是文本。
4.代码
4.1 model
init






forward:
class GPT2LMHeadModel(GPT2PreTrainedModel):
_tied_weights_keys = ["lm_head.weight"]
def __init__(self, config):
super().__init__(config)
self.transformer = GPT2Model(config)
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
# Model parallel
self.model_parallel = False
self.device_map = None
# Initialize weights and apply final processing
self.post_init()
def forward( self,) -> Union[Tuple, CausalLMOutputWithCrossAttentions]:
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
transformer_outputs = self.transformer(
input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
lm_logits = self.lm_head(hidden_states)
loss = None
return CausalLMOutputWithCrossAttentions(
loss=loss,
logits=lm_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
cross_attentions=transformer_outputs.cross_attentions,
)GPT2LMHeadModel = self.transformer + CausalLMOutputWithCrossAttentions
self.transformer = GPT2Model(config)
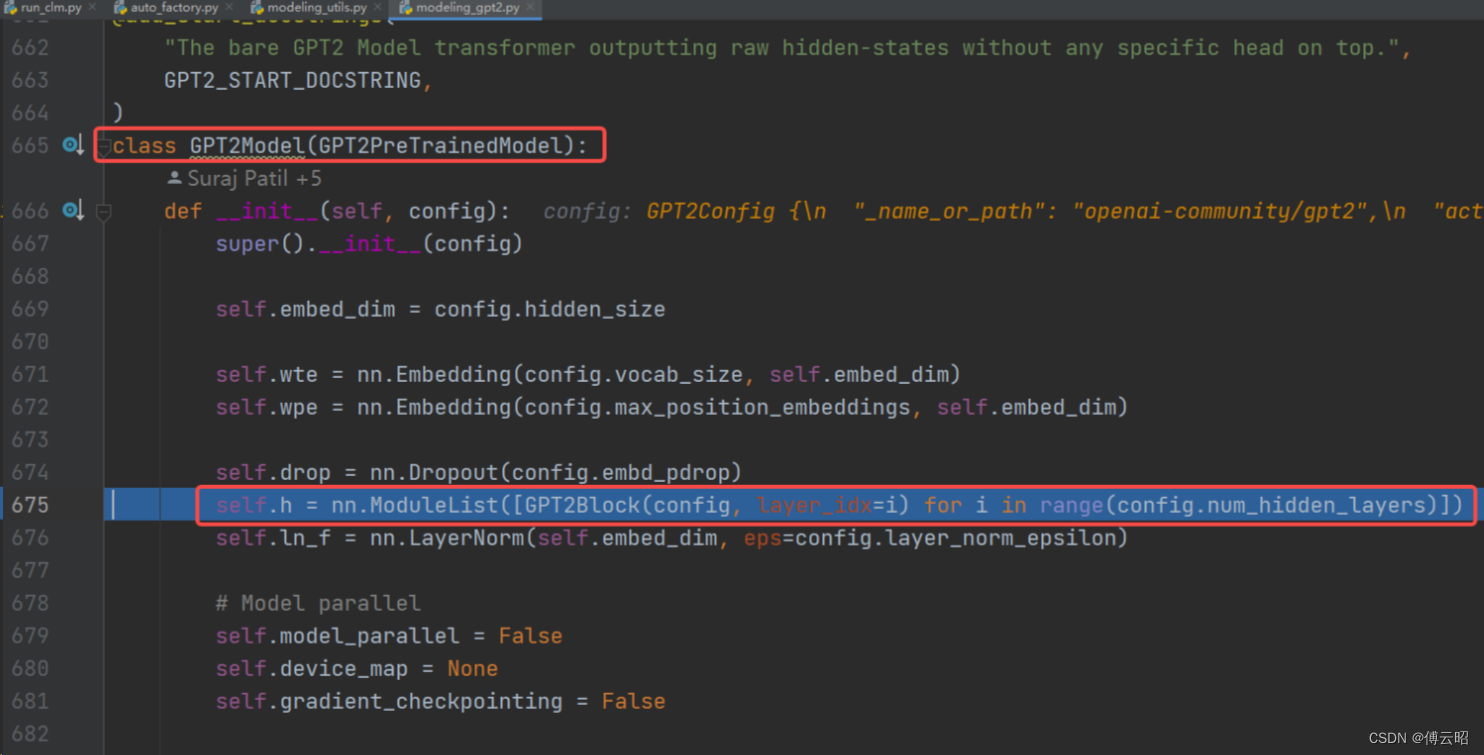
class GPT2Model(GPT2PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.embed_dim = config.hidden_size
self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
self.wpe = nn.Embedding(config.max_position_embeddings, self.embed_dim)
self.drop = nn.Dropout(config.embd_pdrop)
self.h = nn.ModuleList([GPT2Block(config, layer_idx=i) for i in range(config.num_hidden_layers)])
self.ln_f = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)
# Model parallel
self.model_parallel = False
self.device_map = None
self.gradient_checkpointing = False
# Initialize weights and apply final processing
self.post_init()
def forward():
head_mask = self.get_head_mask(head_mask, self.config.n_layer)
if inputs_embeds is None:
inputs_embeds = self.wte(input_ids) # bs,1024-->bs,1024,768
position_embeds = self.wpe(position_ids) # 1,1024-->1,1024,768
hidden_states = inputs_embeds + position_embeds # bs,1024,768
hidden_states = self.drop(hidden_states)
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
outputs = block(
hidden_states,
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask[i],
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
hidden_states = outputs[0]
if use_cache is True:
presents = presents + (outputs[1],)
hidden_states = self.ln_f(hidden_states)
hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [hidden_states, presents, all_hidden_states, all_self_attentions, all_cross_attentions]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)GPT2Model = inputs_embeds + position_embeds + 12*GPT2Block+BaseModelOutputWithPastAndCrossAttentions

class GPT2Block(nn.Module):
def __init__(self, config, layer_idx=None):
super().__init__()
hidden_size = config.hidden_size
inner_dim = config.n_inner if config.n_inner is not None else 4 * hidden_size
self.ln_1 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
self.attn = GPT2Attention(config, layer_idx=layer_idx)
self.ln_2 = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
if config.add_cross_attention:
self.crossattention = GPT2Attention(config, is_cross_attention=True, layer_idx=layer_idx)
self.ln_cross_attn = nn.LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
self.mlp = GPT2MLP(inner_dim, config)
def forward():
residual = hidden_states
hidden_states = self.ln_1(hidden_states)
attn_outputs = self.attn( # multi_head attention
hidden_states,
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
attn_output = attn_outputs[0] # output_attn: a, present, (attentions)
outputs = attn_outputs[1:]
# residual connection 1 add
hidden_states = attn_output + residual
residual = hidden_states
hidden_states = self.ln_2(hidden_states)
feed_forward_hidden_states = self.mlp(hidden_states) # Feed Forward
# residual connection 2 add
hidden_states = residual + feed_forward_hidden_states
if use_cache:
outputs = (hidden_states,) + outputs
return outputs # hidden_states, present, (attentions, cross_attentions)GPT2Block = ln_1(layernorm) + self.attn(GPT2Attention) + residual + ln_2 + mlp(GPT2MLP) + residual
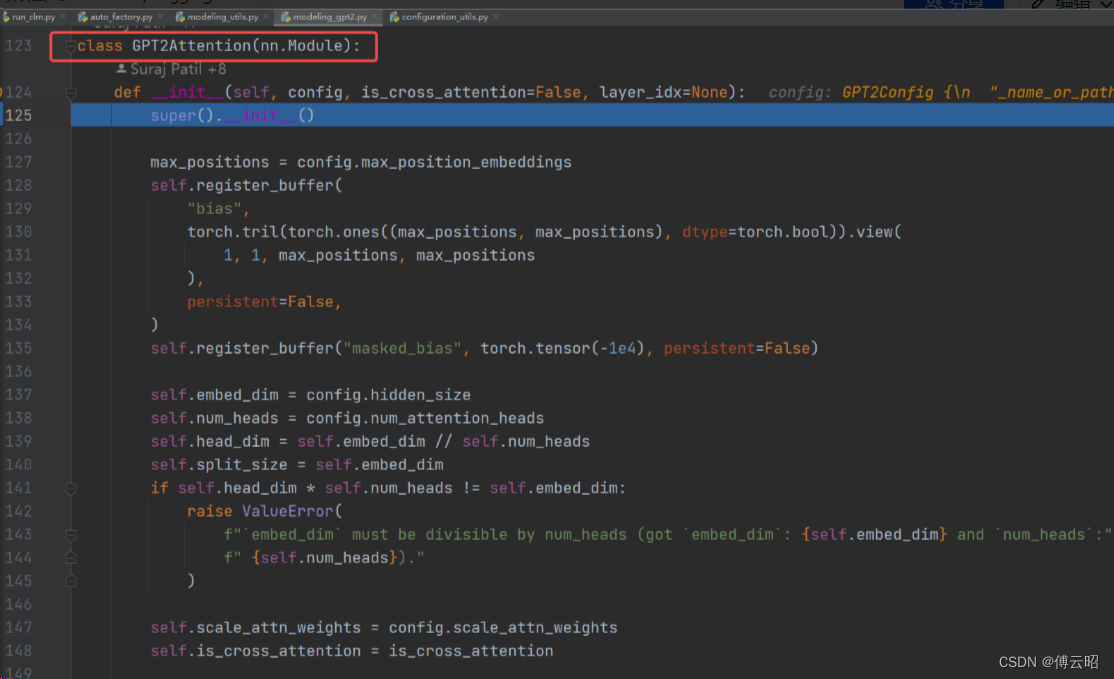
class GPT2Attention(nn.Module):
def __init__(self, config, is_cross_attention=False, layer_idx=None):
super().__init__()
max_positions = config.max_position_embeddings
self.register_buffer(
"bias",
torch.tril(torch.ones((max_positions, max_positions), dtype=torch.bool)).view(
1, 1, max_positions, max_positions
),
persistent=False,
)
self.register_buffer("masked_bias", torch.tensor(-1e4), persistent=False)
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
self.split_size = self.embed_dim
if self.head_dim * self.num_heads != self.embed_dim:
raise ValueError(
f"`embed_dim` must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
f" {self.num_heads})."
)
self.scale_attn_weights = config.scale_attn_weights
self.is_cross_attention = is_cross_attention
# Layer-wise attention scaling, reordering, and upcasting
self.scale_attn_by_inverse_layer_idx = config.scale_attn_by_inverse_layer_idx
self.layer_idx = layer_idx
self.reorder_and_upcast_attn = config.reorder_and_upcast_attn
if self.is_cross_attention:
self.c_attn = Conv1D(2 * self.embed_dim, self.embed_dim)
self.q_attn = Conv1D(self.embed_dim, self.embed_dim)
else:
self.c_attn = Conv1D(3 * self.embed_dim, self.embed_dim)
self.c_proj = Conv1D(self.embed_dim, self.embed_dim)
self.attn_dropout = nn.Dropout(config.attn_pdrop)
self.resid_dropout = nn.Dropout(config.resid_pdrop)
self.pruned_heads = set()
def forward(
self,
hidden_states: Optional[Tuple[torch.FloatTensor]],
layer_past: Optional[Tuple[torch.Tensor]] = None,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = False,
output_attentions: Optional[bool] = False,
) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
# bs,1024,768-->Conv1D-->q,k,v:bs,1024,768
query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2) # Conv1D
# Splits hidden_size dim into attn_head_size and num_heads
query = self._split_heads(query, self.num_heads, self.head_dim)
key = self._split_heads(key, self.num_heads, self.head_dim) # 768 = 12 heads * 64 dims
value = self._split_heads(value, self.num_heads, self.head_dim)
present = (key, value)
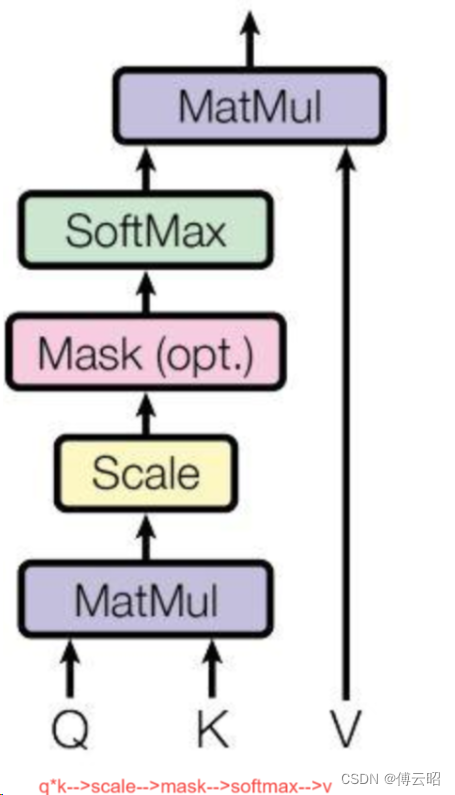
# 计算q*k-->scale-->atten_weight[atten_mask]-->softmax-->*value
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)# 12*64-->768
attn_output = self.c_proj(attn_output) # CONV1D
attn_output = self.resid_dropout(attn_output) # dropout
outputs = (attn_output, present)
if output_attentions:
outputs += (attn_weights,)
return outputs # a, present, (attentions)
def _attn(self, query, key, value, attention_mask=None, head_mask=None):
"""实际的attention计算:
q*k-->scale-->atten_weight[atten_mask]-->softmax-->*value"""
attn_weights = torch.matmul(query, key.transpose(-1, -2))
if self.scale_attn_weights:
attn_weights = attn_weights / torch.full(
[], value.size(-1) ** 0.5, dtype=attn_weights.dtype, device=attn_weights.device )
if not self.is_cross_attention:
query_length, key_length = query.size(-2), key.size(-2)
causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length]
mask_value = torch.finfo(attn_weights.dtype).min
mask_value = torch.full([], mask_value, dtype=attn_weights.dtype, device=attn_weights.device)
attn_weights = torch.where(causal_mask, attn_weights.to(attn_weights.dtype), mask_value)
if attention_mask is not None:
attn_weights = attn_weights + attention_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
attn_weights = attn_weights.type(value.dtype)
attn_weights = self.attn_dropout(attn_weights)
attn_output = torch.matmul(attn_weights, value)
return attn_output, attn_weights
class Conv1D(nn.Module):
def __init__(self, nf, nx):
super().__init__()
self.nf = nf
self.weight = nn.Parameter(torch.empty(nx, nf)) # 768*768
self.bias = nn.Parameter(torch.zeros(nf)) # 768
nn.init.normal_(self.weight, std=0.02)
def forward(self, x):
size_out = x.size()[:-1] + (self.nf,) # BS,1024,768
x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight) # X * W + bias
x = x.view(size_out) # BS,1024,768
return xGPT2Attention = Conv1D+ 计算q*k-->scale-->atten_weight[atten_mask]-->softmax-->*value + Conv1D
class GPT2MLP(nn.Module):
def __init__(self, intermediate_size, config):
super().__init__()
embed_dim = config.hidden_size
self.c_fc = Conv1D(intermediate_size, embed_dim)
self.c_proj = Conv1D(embed_dim, intermediate_size)
self.act = ACT2FN[config.activation_function]
self.dropout = nn.Dropout(config.resid_pdrop)
def forward(self, hidden_states: Optional[Tuple[torch.FloatTensor]]) -> torch.FloatTensor:
hidden_states = self.c_fc(hidden_states)
hidden_states = self.act(hidden_states)
hidden_states = self.c_proj(hidden_states)
hidden_states = self.dropout(hidden_states)
return hidden_statesGPT2MLP = conv1d * 2+ 激活函数 + dropout
总结:
GPT2LMHeadModel = self.transformer(GPT2Model) + CausalLMOutputWithCrossAttentions(head+loss)
GPT2Model = inputs+position_embeds + 12*GPT2Block+BaseModelOutputWithPastAndCrossAttentions
GPT2Block = ln_1(layernorm) + self.attn(GPT2Attention) + residual + ln_2 + mlp(GPT2MLP) + residual
GPT2Attention = Conv1D+ 计算q*k-->scale-->atten_weight[atten_mask]-->softmax-->*value + Conv1D
GPT2MLP = conv1d * 2+ 激活函数 + dropout
GPT2Block等价于transformer的decoder,12层GPT2Block就是12层decoder
GPT2LMHeadModel = embeds+12层decoder + head
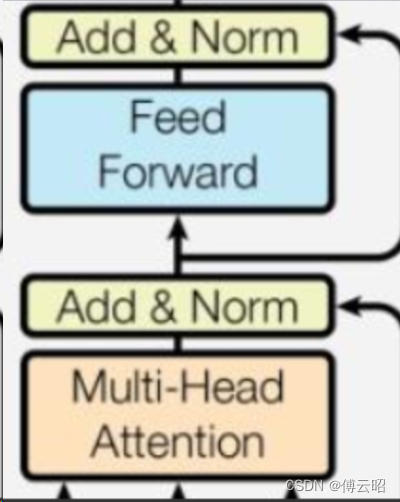
简单解释一下:
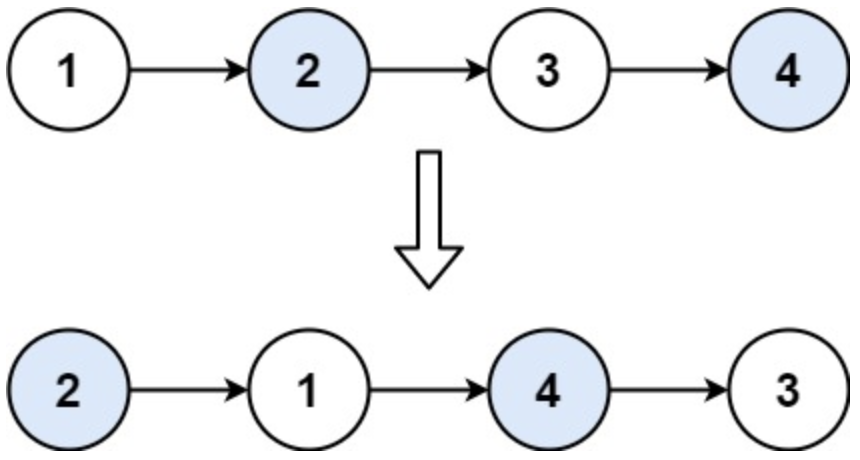
gpt的decoder和transformer的decoder是有一点区别的,下图中红色的qkv是output的qkv,而蓝色的kv是来自input的经过encoder的kv,q是来自output经过mask multi head attention的q,第1个attention可以看作output自己的self attention,而第二个attention可以看作是input的kv和ouput的q的cross attention。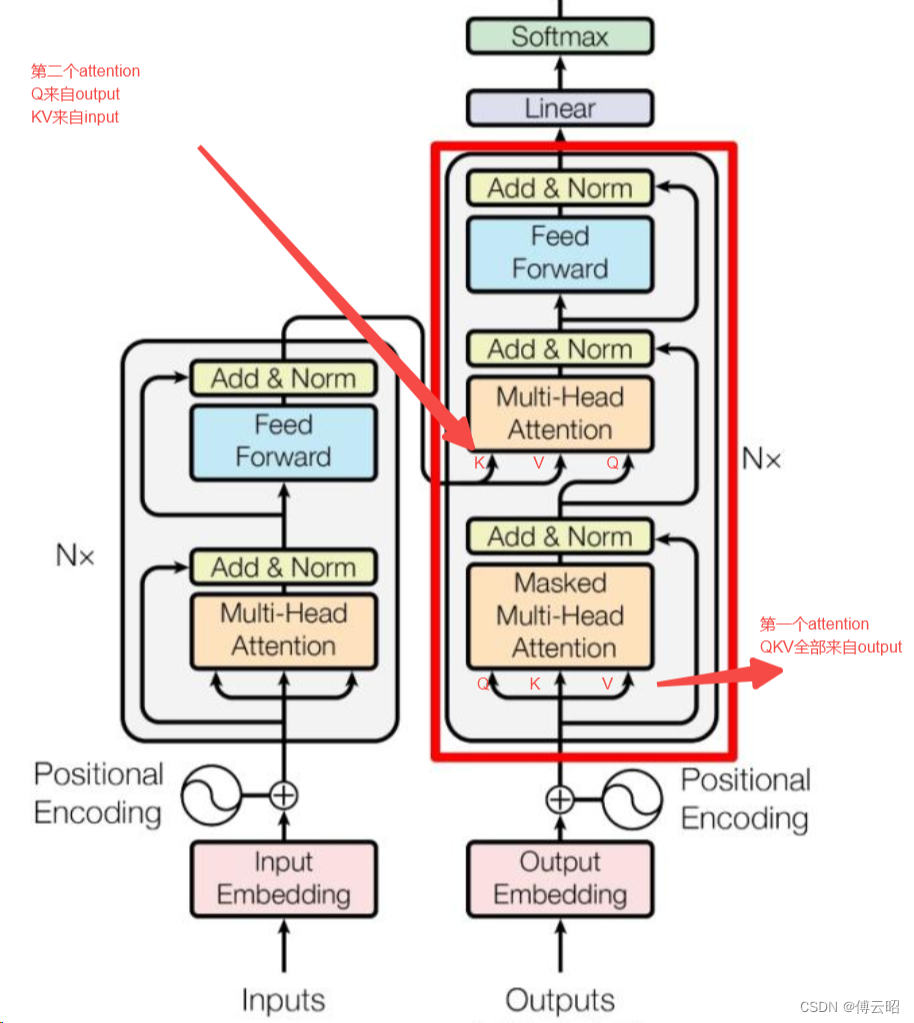
但是gpt2的全部都是self attention,所以不需要cross attention
https://zhuanlan.zhihu.com/p/338817680
关于loss和因果语言模型:

https://huggingface.co/docs/transformers/model_summary
GPT模型的训练过程中使用的损失函数是语言模型的损失函数,通常是交叉熵损失(Cross-Entropy Loss)。
在预训练阶段,GPT模型的目标是根据上下文预测下一个词。给定一个输入序列,模型会根据前面的词来预测下一个词的概率分布。损失函数的作用是衡量模型的预测结果与真实下一个词的分布之间的差异。
具体地,对于每个位置上的词,GPT模型会计算预测的概率分布和真实下一个词的分布之间的交叉熵。交叉熵损失函数对于两个概率分布之间的差异越大,损失值就越高。
在训练过程中,GPT模型通过最小化整个序列上所有位置的交叉熵损失来优化模型的参数。这样,模型就能够逐渐学习到语言的统计规律和上下文的依赖关系,从而提高生成文本的质量和准确性。
需要注意的是,GPT模型的预训练阶段使用的是无监督学习,没有人工标注的标签。因此,损失函数在这个阶段是根据自身预测和输入序列来计算的,而不需要与外部标签进行比较。
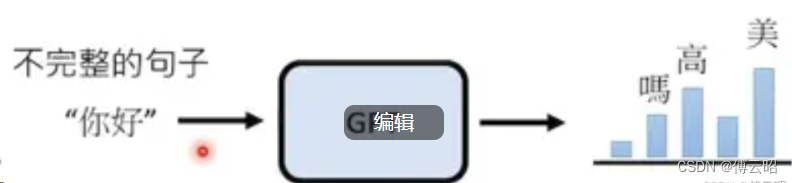
你好_
把上面的第三个字预测的概率分布和真实词的分布之间的交叉熵
_是一个被mask的词,假如真是的词是高,即你好高,那么真实词的概率分布应该是高这个词无限接近1,其他无限接近0,然后拿这个真实词汇的分布和预测分布计算交叉熵。
交叉熵: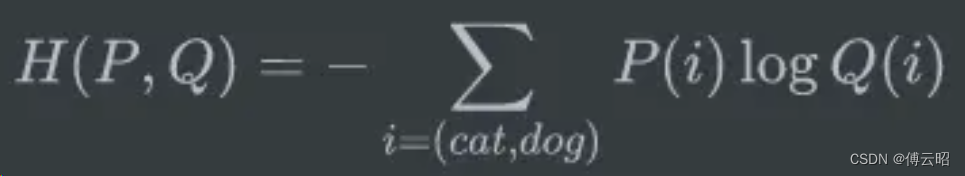
真实标签为[1, 0, 0, 0 ] P(i)
预测结果1为[0.7, 0.2, 0.05, 0.05] Q(i)
交叉熵计算:
-( 1*log0.7 + 0*log0.2 + 0*long0.05 + 0*log0.05) = 0.155
预测结果2为[0.1, 0.5, 0.3 ,0.1]
计算:
-(1*log0.1 + 0*log0.5 +0*log0.3 +0*log0.1) = 0.999
明显0.999>0.155,就是说预测结果2的loss更大,比较合理