具体内容请看b站尚硅谷课程! 32_Flink运行时架构_提交流程_Yarn应用模式_哔哩哔哩_bilibili
窗口
Flink的窗口并不是静态准备好的,而是动态创建的。数据流到达时不会准备24个或者其他完整数量的桶,而是当下桶接满了,才临时又拿新桶。本质原因就是Flink是事件驱动型的计算引擎,数据流是未知而隐秘的。
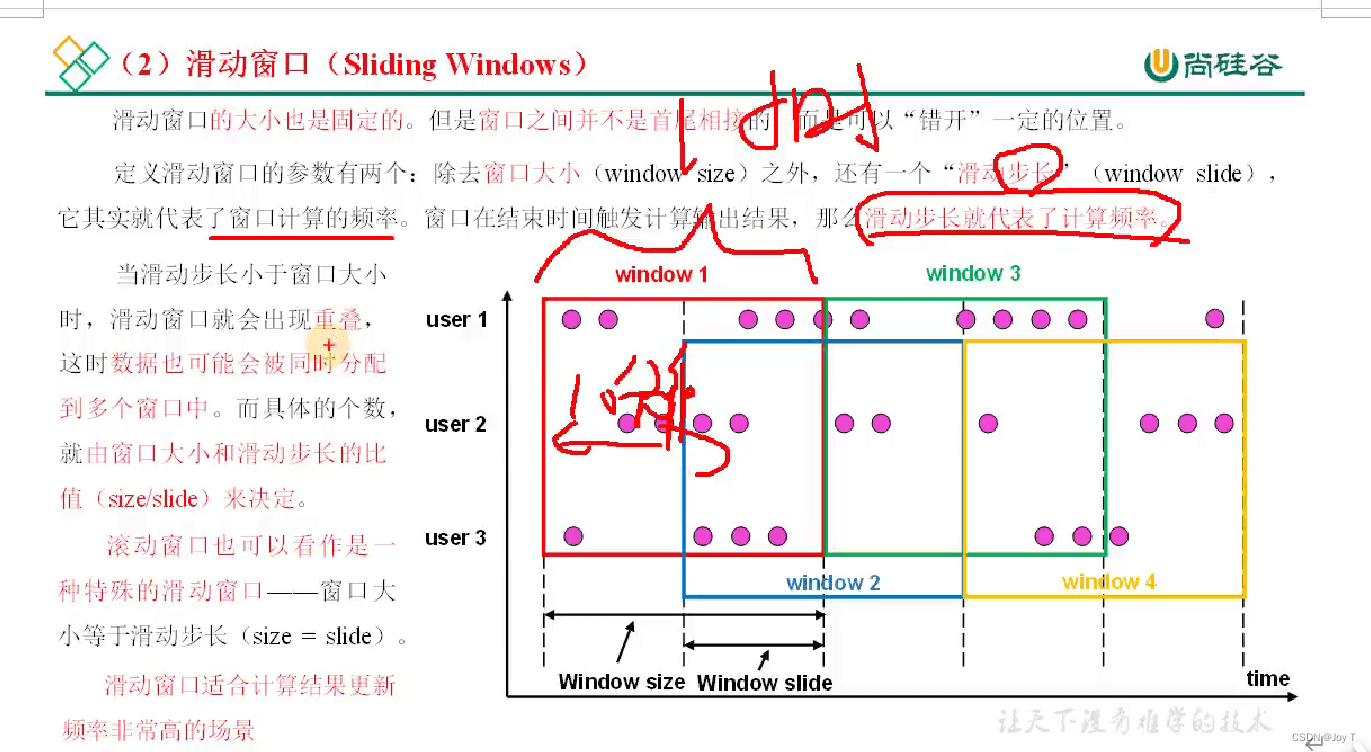
滚动和滑动都是可以基于时间和数量的,但是会话窗口只能是基于时间。会话这个概念没有基于数量的。


注意这一点很重要:一般的业务日志数据都含有时间戳!
水位线WaterMark

可以根据数据的事件时间设立一个逻辑时钟,不管什么时候处理,即使现在8:10分,处理事件的事件时间为8:05,那么逻辑时钟也是8:05,只随着新到数据的时间戳推动。可以想象,WaterMark水位线就是一种允许延迟的逻辑时钟。
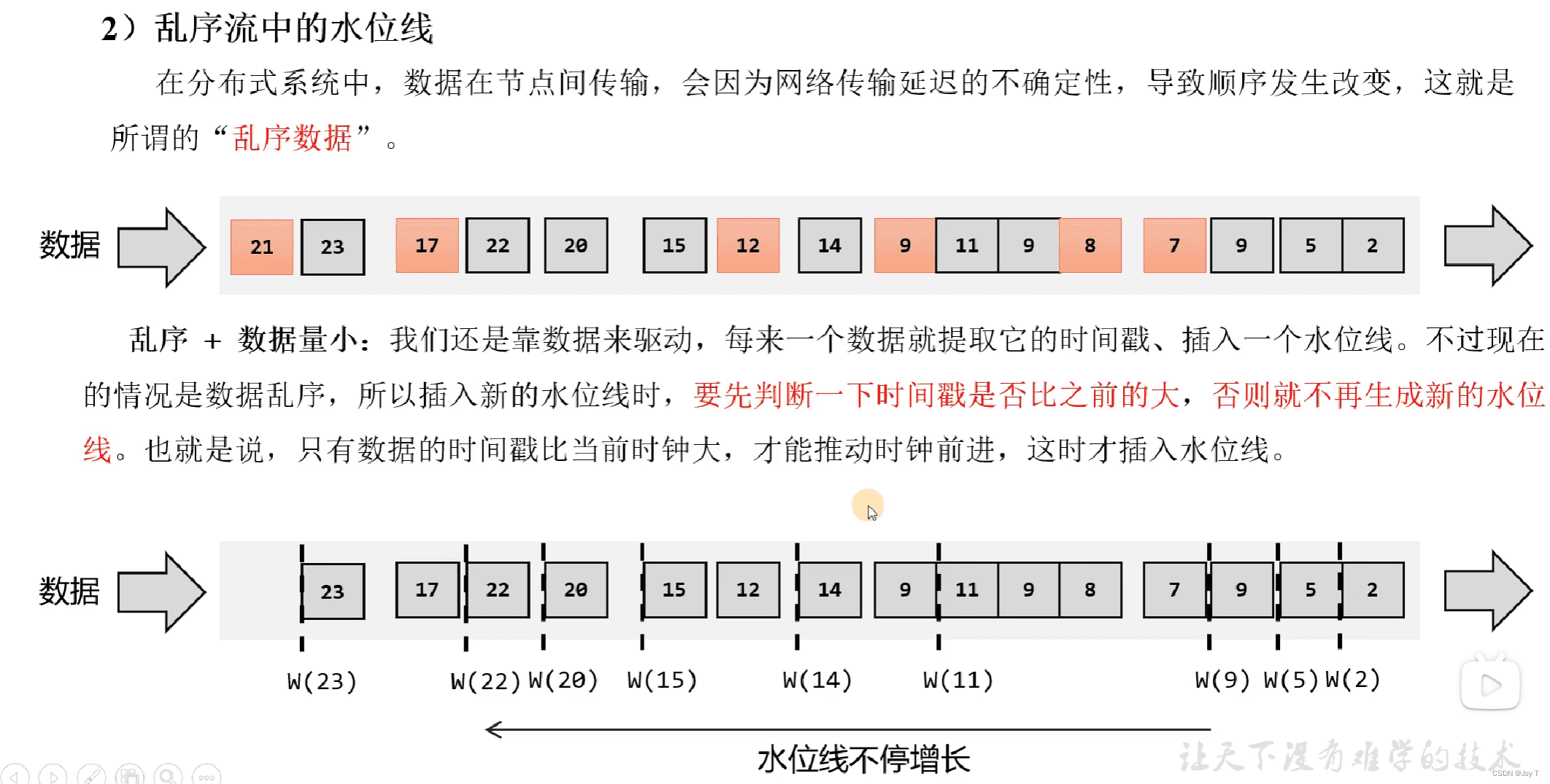
- 水位线这种逻辑时钟,表示的就是整个数据的处理过程。它只能增长,但允许延迟,等到从当前数据提取到的时间戳大于水位线时,才会插入一条新的水位线,表示该水位线之前的数据都已处理完毕。
- 数据量大的情况下,需要考虑两个问题,一是不能为每个数据都设置水位线,否则性能下降严重,需要间隔设置;二是需要考虑到数据的延迟和乱序(可能也有网络的原因),乱序需要保证每次插入水位线时都是当前所有数据的最大时间戳,无论是单独设置水位线还是间隔设置。而延迟往往需要水位线在当前最大时间戳的基础上推迟一小段时间,而这个时间是Flink窗口计算延迟性能的最关键时间。(因为此时,虽然确实能够在乱序数据流的时间上具有正确性,但实际意义并不完整,乱序只是延迟的表现结果之一。如果需要让水位线最大程度上表示可以开始窗口计算的时机,就必须要进一步考虑完整的延迟状态。延迟确实能够导致乱序,但是解决乱序的方法不一定能够满足绝大部分延迟数据被纳入窗口计算的要求。)
- 举个例子,如果我们的窗口是从9:00到9:05(这就是时间 B),我们会等待直到 Watermark 告诉我们:“到9:05为止的树叶我认为都已经到了”。即使此时已经是9:06或9:07(此时-9:05就是等待的时间),因为考虑到了树叶(数据)可能的延迟,我们仍然可以准确地计算9:00到9:05这个时间窗口内的树叶数量。
- Watermark 的机制使得 Flink 能够在处理实时数据流时,智能地处理数据的延迟和乱序问题。它让 Flink 知道何时可以开始对特定时间窗口的数据进行处理和聚合计算,即便这些数据不是完全按照实际发生的时间顺序到达的。这对于需要按时间段进行分析和统计的实时应用尤其重要,比如实时监控、实时统计分析等场景。
- 在 Flink 中,处理窗口数据的延迟主要有两个部分:一是数据到达的延迟,二是等待 Watermark 的延迟。实际上,等待 Watermark 的延迟通常是决定窗口计算总体延迟的主要因素,尤其是在处理乱序数据或有延迟到达数据的场景中。
- 水位线是真实在数据流中生成的数据!表示当前事件时间的进展(单调递增,无法倒流)。
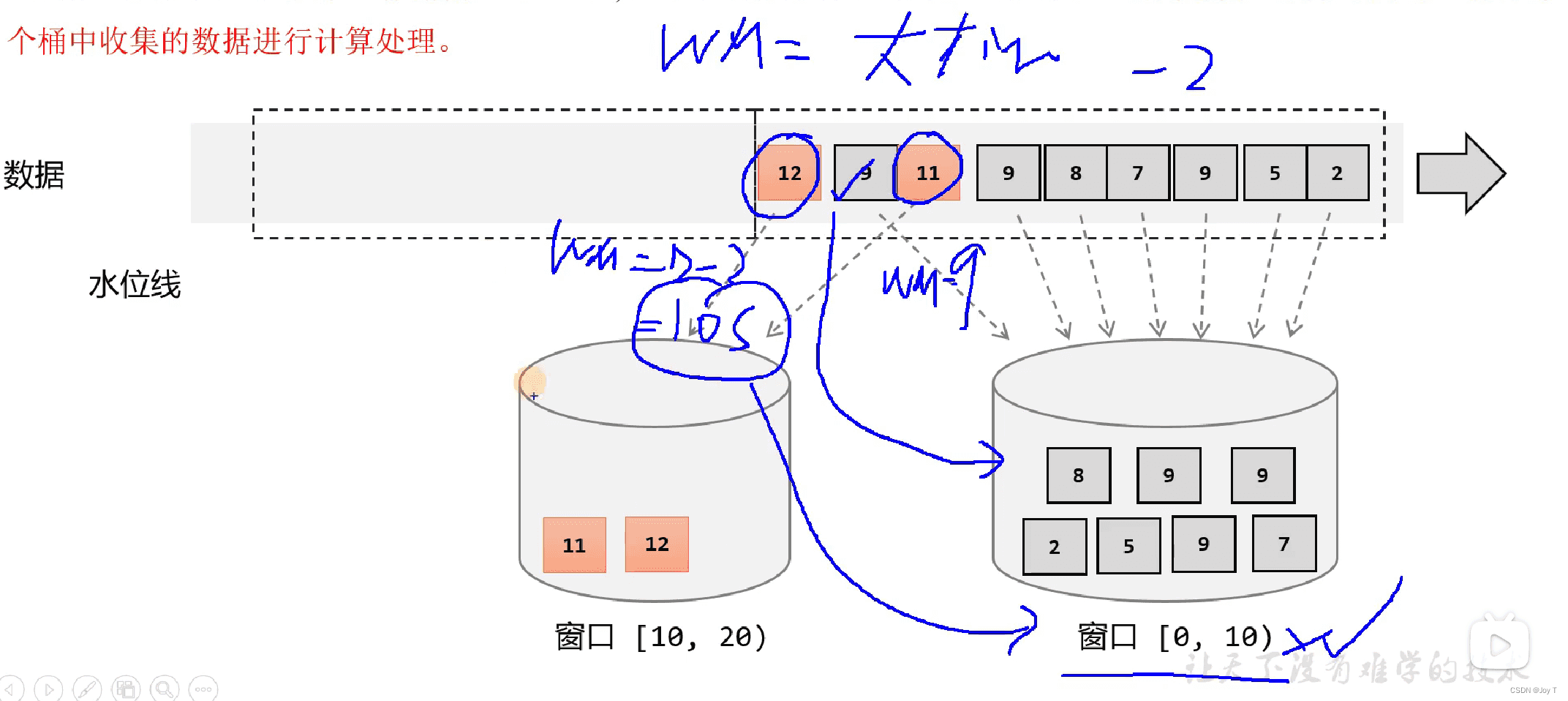
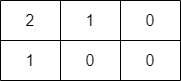
直到时间戳为12的数据来了,此时WaterMark=12-2=10,超过了窗口(桶)的时间容积,所以换新桶。并且之前时间戳大于10的数据都会放在新桶中。(WaterMark只是决定当前窗口是否关闭)
- 在实时流处理中,是有可能存在多个窗口同时“开启”(即接收数据)的情况。例如,当处理一个滑动窗口或者数据到达有延迟时,不同事件时间的数据可能会被分配到不同的窗口中,这些窗口可能部分重叠或完全独立。
窗口的存储和计算
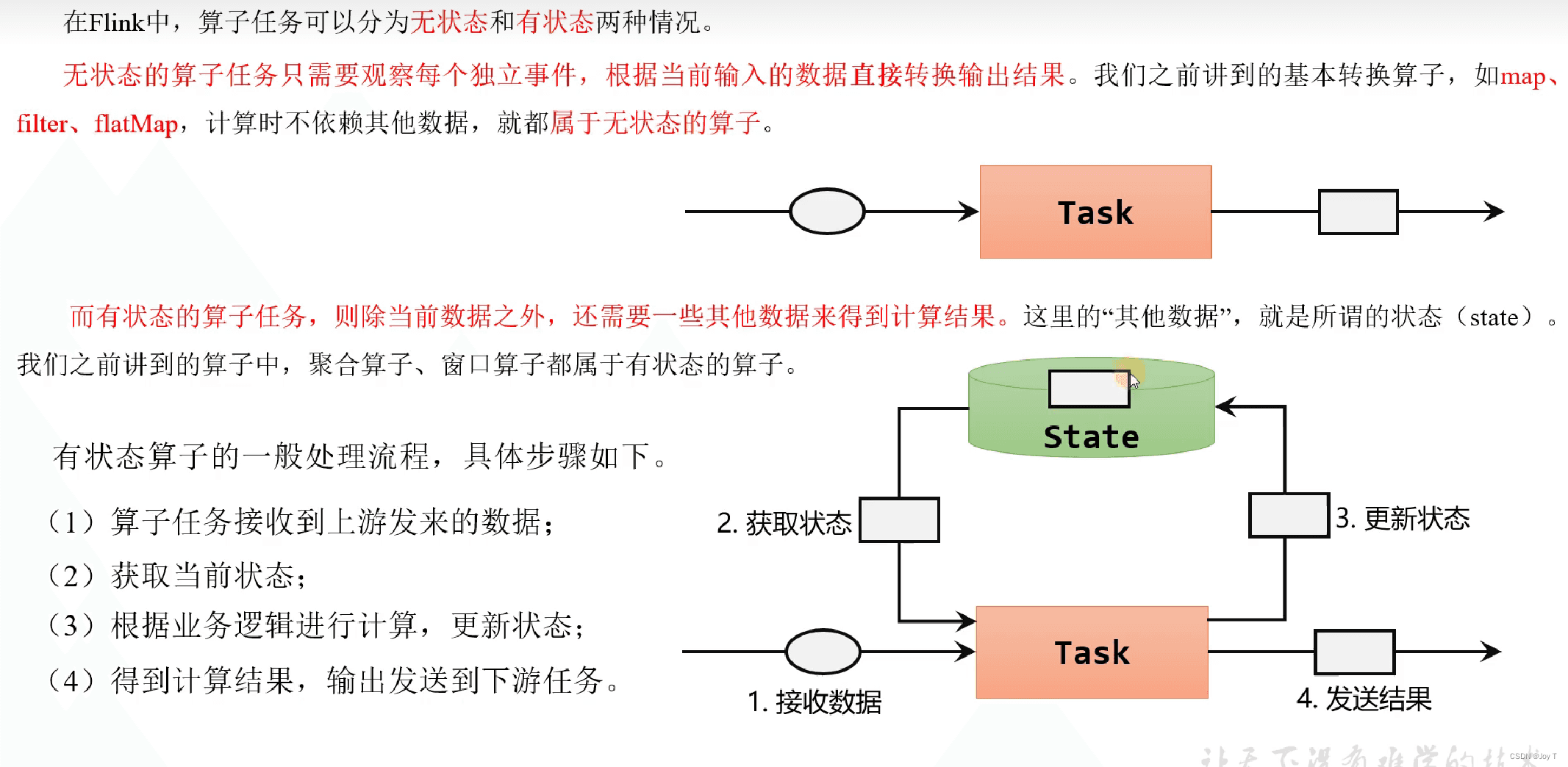
- 数据的暂存:在窗口关闭之前,属于该窗口的数据(或窗口的中间计算状态)会在 Flink 的状态中暂存。这意味着,对于每个窗口,Flink 需要维护一个状态来存储属于该窗口的数据或计算结果。
- 窗口的触发计算:当水位线超过某个窗口的结束时间时,表明该窗口可以被触发计算了(即该窗口内的所有相关数据都已到达)。这时,Flink 会对该窗口的数据执行定义好的计算逻辑(如聚合操作),并输出计算结果。此后,该窗口的状态可以被清理以释放资源。
延迟数据的处理
- Flink 允许窗口在其正常关闭(即水位线超过窗口结束时间)后还能处理一些延迟到达的数据。这是通过定义“允许的延迟”(allowed lateness)来实现的。如果设置了允许的延迟时间,即使窗口已经触发计算,但在这段延迟时间内到达的数据仍然可以被添加到对应的窗口中,并可能导致窗口再次触发计算(更新计算结果)。
- 最后的绝招:Flink 允许通过侧输出(Side Outputs)机制处理超出水位线太多的迟到数据,提供了额外的灵活性来处理这些数据。
状态清理
关于窗口状态的清理,Flink 提供了几种不同的策略。默认情况下,当窗口触发计算后,如果没有设置允许的延迟时间,窗口状态会被立即清理。如果设置了允许的延迟时间,窗口状态会在延迟时间过后才被清理。



![uniapp运行项目到微信小程序报错——未找到[“sitemapLocation“]](https://img-blog.csdnimg.cn/direct/d670e1dfc189487a8eec4dc6f5efb370.png#pic_center)