前言
这个问题算是我的一个羞耻点,起源于一次面试中,面试官问ThreadLocal的底层实现是啥,我那时候一直以为ThreadLocal是一个类似于Redis一样的独立于线程外的第三方存储容器,如何底层维护了一个Map结构,以线程ID为Key,存储的数据为Value,通过线程id去找到这个存储值,那时候还很坚定这个想法,最后面试官说:em~你再回去了解下吧。我:⊙ˍ⊙
ThreadLocal 底层原理
ThreadLocal是多线程中对于解决线程安全的一个操作类,它会为每个线程都分配一个独立的线程副本从而解决了变量并发访问冲突的问题。ThreadLocal 同时实现了线程内的资源共享,可以把ThreadLocal理解为商场的寄存柜,一个人只能有一个柜口,但是可以有多个寄存柜(为啥这样子比喻?看下去~)
set()源码
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
// 当前线程自身所绑定的ThreadLocal对象
return t.threadLocals;
}可以看到它调用了Thread的 threadLocals 对象:
public class Thread implements Runnable {
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
。。。
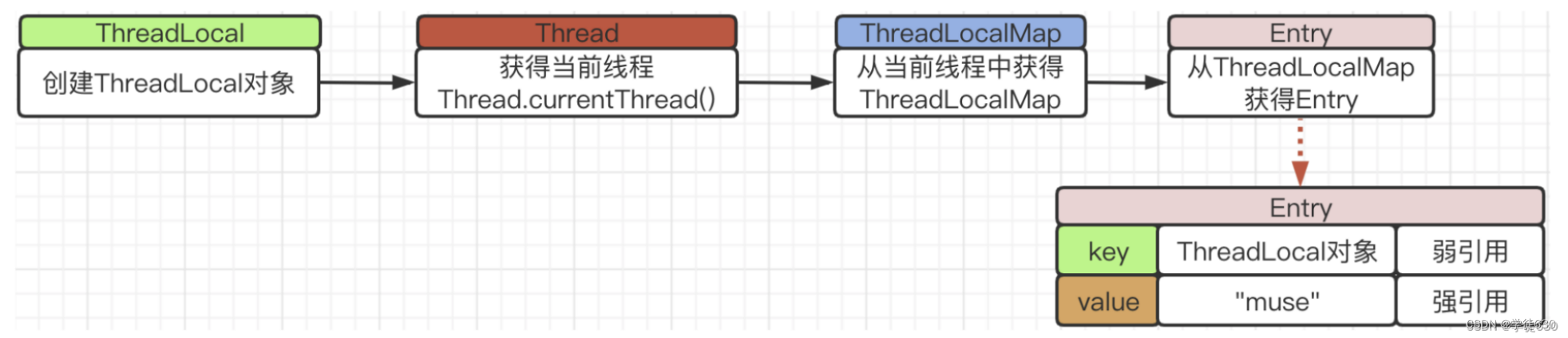
} 到这里我们基本可以知道ThreadLocal数据隔离的真相了,每个线程Thread都维护了自己的 ThreadLocalMap 成员变量,所以每次使用ThreadLocal.get()时都是从自己线程里面拿到自己的ThreadLocalMap 变量,拿不到别人的变量,从而实现了数据隔离。由于每一条线程均含有各自私有的ThreadLocalMap容器,这些容器相互独立互不影响,因此不会存在线程安全性问题,从而也无需使用同步机制来保证多条线程访问容器的互斥性。
// 第一次执行set操作需要调用createMap函数初始化线程内部的ThreadLocal
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}在ThreadLocalMap的构造方法里,蕴含着初始化创建table数组(封装类Entry的数组集合,Entry封装了当前的ThreadLocal对象和要存放的值)的逻辑,源码和注释如下所示:
是不是迷惑为什么ThreadLocalMap中需要存放的是个数组,不是说好了同一个ThreadLocal中只能找到一个位置存一个值吗?
答:一个线程只能在一个ThreadLocal中存放一个值没错。但是现在的问题是我ThreadLocal又不是只有一个,不要把ThreadLocal当作一个第三方缓存啊。可以把ThreadLocal理解为商场的寄存柜,一个人只能有一个柜口;商场那么多,你可以在多个商场的寄存柜中各自存放一件商品,对于你自身来说,你只需要做好记录,说我在哪个商场存放过东西就行。
ThreadLocal——商场的寄存柜
当前线程Thread——你
Thread.ThreadLocalMap——存放记录清单,里面维护了个数组,支持记录多个商场的寄存柜地址,你用一个ThreadLocal来调用set / get 方法,本质上就是校验清单中寄存柜地址并执行相关操作
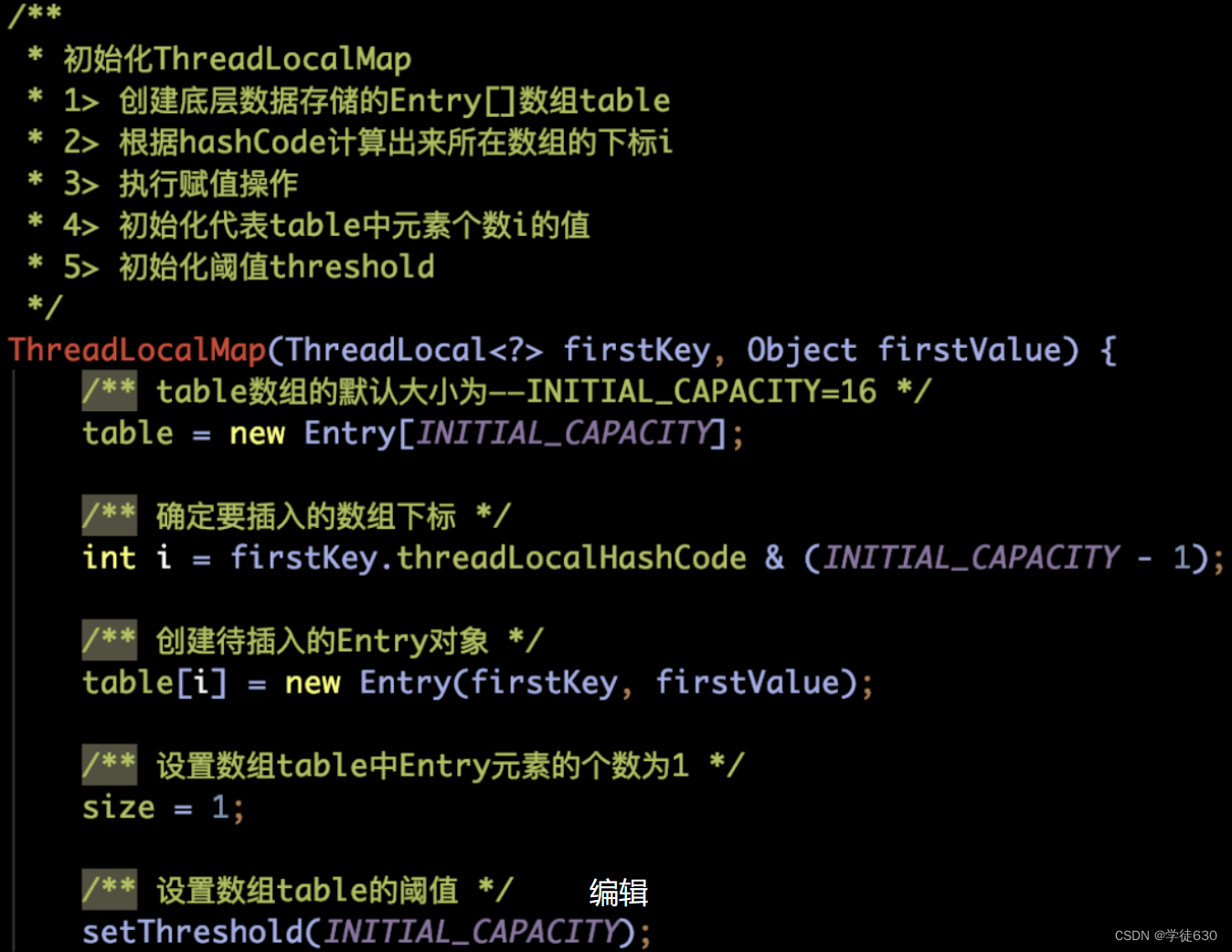
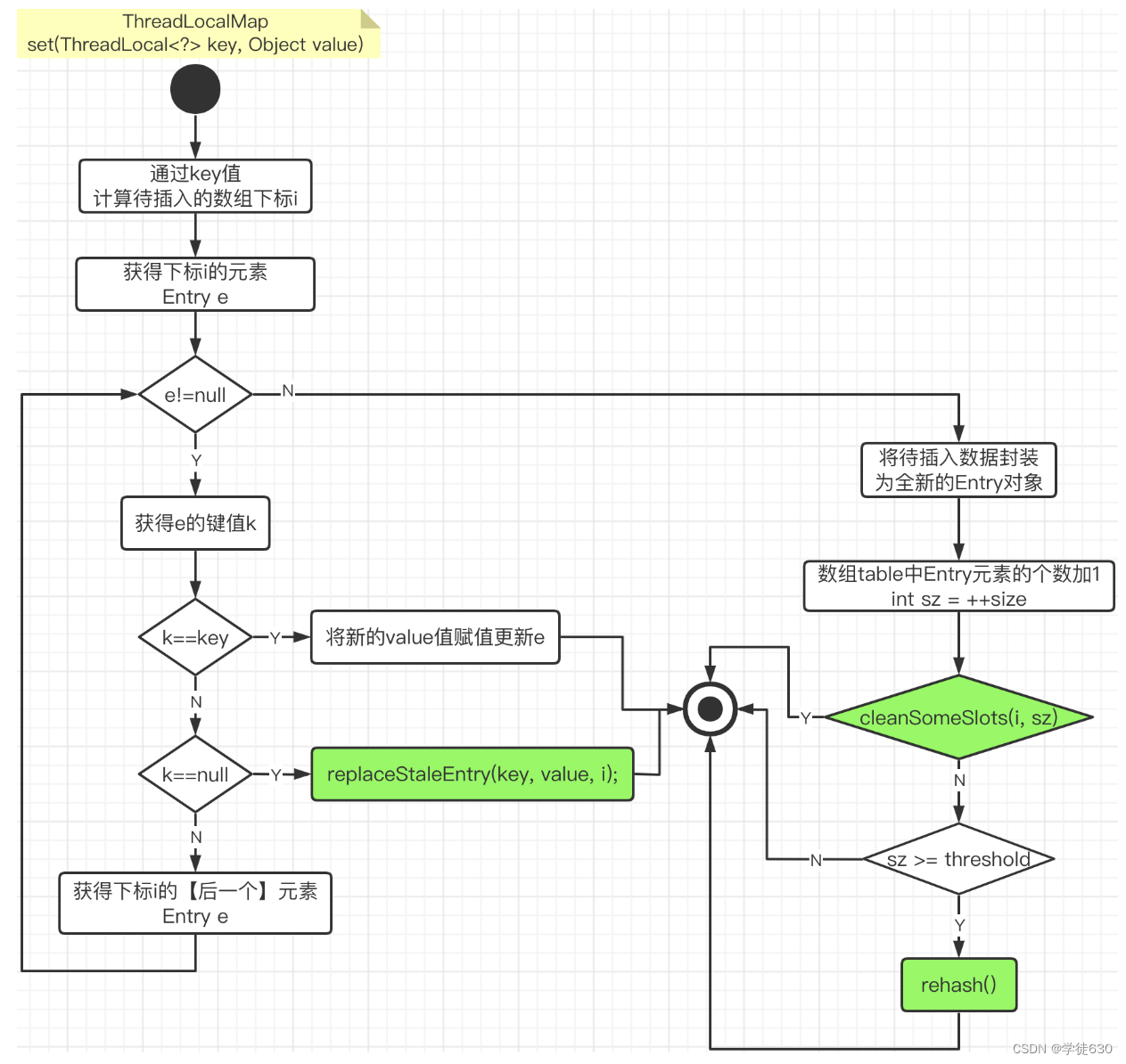
【解释】从上面源码中我们可以看到,数组默认大小是 16 ,设定的阈值为 0.75 倍的数组长度,并且根据传入的参数,创建了table数组中的第一个Entry元素对象(ThreadLocal对象为Key, 数据值为Value)。其中,size用来记录数组中存在的Entry元素的个数。
set插入操作其实很简单,大概流程看看:
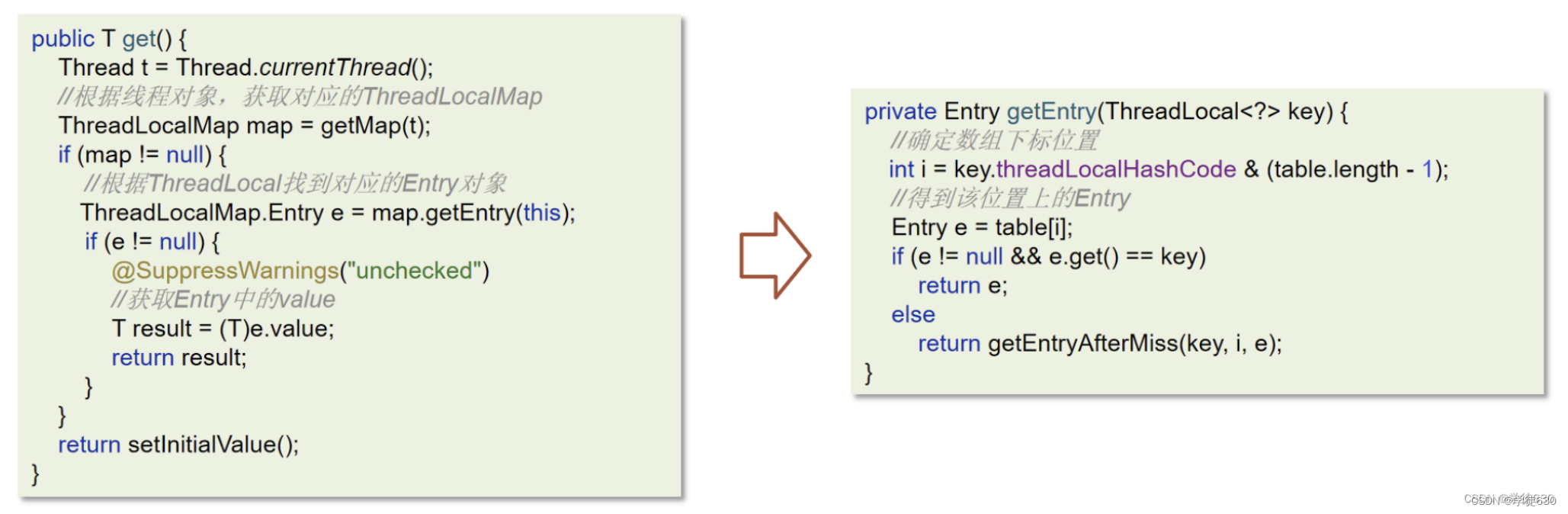
get源码
这个其实没啥好说的,就是通过你调用的这个ThreadLocal对象去找当前线程中内置的ThreadLocalMap清单,找到该ThreadLocal对象通过Hash后得到的对应的那个数组下标提取数据就行,如果有
ThreadLocal-哈希冲突
ThreadLocalMap 使用开放定址法解决冲突,具体来说是线性探测法(linear probing)。线性探测法会在发生哈希冲突时,依次检查下一个位置,直到找到可用的槽位存储数据。
问:线性探测法通过后移寻找空闲位置来插入发生哈希冲突的值,那这样子的话该空闲位置不就被占用了吗?如果下一次有个元素hash后刚好到这个位置咋办?
答:在这种情况下,线性探测法会继续往后查找下一个空闲位置,并依次检查是否有其他元素占用。这个过程被称为"探测"。如果找到了下一个空闲位置,则将元素插入到该位置。如果整个哈希表都被占满了(即没有空闲位置),则说明哈希表已满,无法再插入新的元素。如果哈希表发生冲突较多,可以考虑使用其他的解决冲突的方法,如链式寻址法或开放定址法的二次探测、双重散列等。
为什么要采用线性探测法不用链式寻址法
-
线性探测法比较适用于哈希表大小相对较小的情况,而 ThreadLocal 的规模通常比较小。因为每个线程都需要独立的空间,所以使用链式寻址法的方式,在开销和效率方面不如线性探测法。
-
线性探测法具有较好的局部性和缓存友好性,可以使 CPU 缓存的效率得到优化,提高程序的执行效率。
ThreadLocal-内存泄露
-
强引用:最为普通的引用方式,表示一个对象处于有用且必须的状态,如果一个对象具有强引用,则GC并不会回收它。即便堆中内存不足了,宁可出现OOM,也不会对其进行回收
-
弱引用:表示一个对象处于可能有用且非必须的状态。在GC线程扫描内存区域时,一旦发现弱引用,就会回收到弱引用相关联的对象。对于弱引用的回收,无关内存区域是否足够,也就是说
被弱引用关联的对象只能存活到下一次垃圾回收发生之前。
每一个Thread维护一个ThreadLocalMap,在ThreadLocalMap中的Entry对象继承了WeakReference。其中key为使用弱引用的ThreadLocal实例,value为强引用的线程变量副本
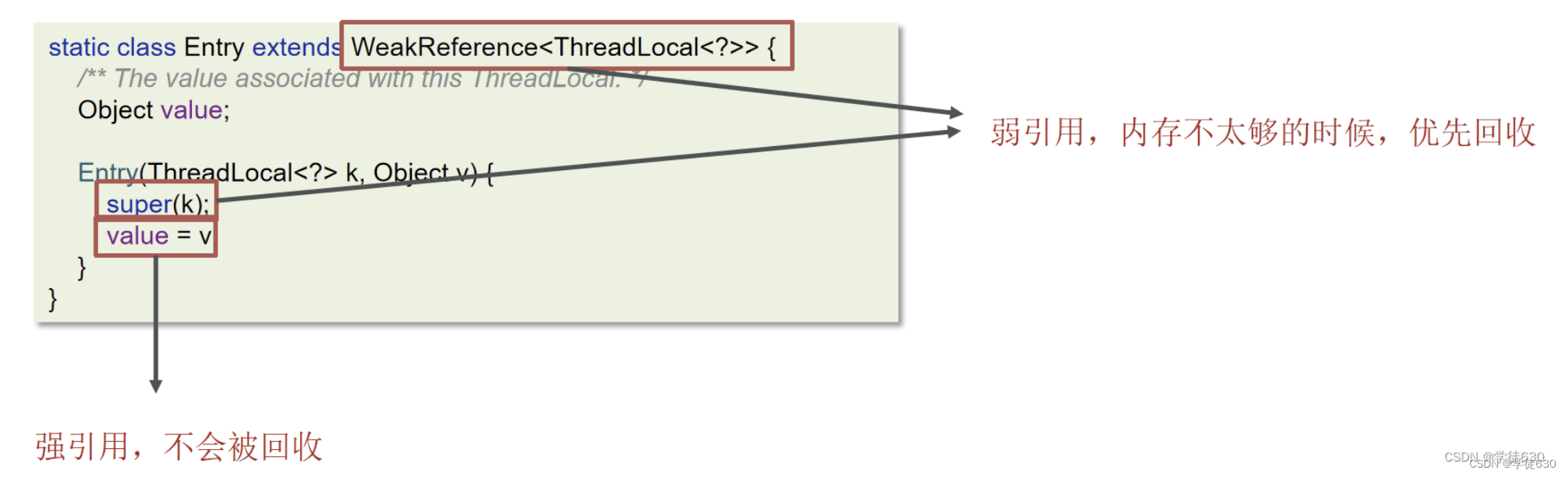
一旦Key被回收了,key 的引用就变成了 null,就会导致这个内存永远无法被访问,造成内存泄漏。
问题:如果这个线程被回收了,那线程里面的成员变量不是都会被回收吗?就不会存在内存泄漏问题啊?
答:在实际应用中,我们一般都是使用线程池,而线程池本身是重复利用的,所以还是会存在内存泄漏的问题。
解决方法
ThreadLocal自救:
-
ThreadLocal每次调用 get、set、remove 等方法时,会顺便检查并清理掉 Entry 中 Key 为 null 的数据。
伟大的shi山创造者干涉:
-
每次使用完 ThreadLocal 以后,主动调用 remove()方法移除数据
-
把 ThreadLocal 声明称全局变量,使得它无法被回收
ThreadLocal 使用场景
-
在进行对象跨层传递的时候,使用ThreadLocal可以避免多次传递,打破层次间的约束
-
线程间数据隔离
-
进行事务操作,用于存储线程事务信息。
-
数据库连接,通过线程池管理连接可以提高性能和资源利用率。在这种情况下,可以使用 ThreadLocal 来存储每个线程中的数据库连接,确保每个线程都有自己独立的连接对象,避免多线程间的共享和竞争。
Spring框架在事务开始时会给当前线程绑定一个Jdbc connection,在整个事务过程都是使用该线程绑定的connection来执行数据库操作,实现了事务的隔离性。Spring框架里面就是用的ThreadLocal来实现这种隔离
CASE说明
一个常见的使用场景是在 Web 应用中,需要在每个用户请求的线程中存储用户会话信息。比如,在一个使用了线程池的 Web 服务器中,每个用户请求会被分配到一个线程中处理,如果直接将用户会话信息存储在普通的成员变量中,就会导致线程安全问题。这时就可以使用 ThreadLocal 来存储用户会话信息,确保每个线程中都有自己独立的数据副本,避免线程之间的数据混乱。
举个实际业务例子,比如在一个电子商务网站中,用户登录之后需要存储用户的购物车信息。使用 ThreadLocal 可以在用户登录成功后将购物车信息存储在 ThreadLocal 中,在用户每次请求时从 ThreadLocal 中获取购物车信息进行处理,确保每个用户在线程中都有自己独立的购物车数据,不会被其他线程干扰。这样既保证了数据的线程安全,又避免了频繁的数据传递和同步操作。