基本概念
- TP(True Positive):正确的正例,一个实例是正类并且也被判定成正类
- FN(False Negative):错误的反例,漏报,本为正类但判定为假类
- FP(False Positive):错误的正例,误报,本为假类但判定为正类
- TN(True Negative):正确的反例,一个实例是假类并且也被判定成假类
召回率
召回率=TP/(TP+FN)
精确率
精确率=TP/(TP+FP)
举例说明
有一堆苹果,好苹果100个,坏苹果100个,因为吃坏苹果会拉肚子,所以要把好苹果挑出来,不能出现误报(把坏苹果识别成好的)。因为要把苹果拿出来卖,为了挣钱,出现几个坏苹果也没关系,不能出现漏报(把好苹果识别成坏的)。所以在算法中就会有权重的设置,来权衡关系。
第一轮结果
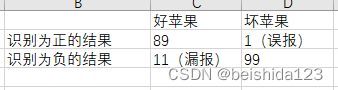
召回率=89/(89+11)=89% ------------- 召回率较低,原因是漏报较多。(可能把有斑点的苹果识别成坏的了,妨碍挣钱)
精确率=89/(89+1)=98.8% ------------ 误报少,精确率高
第二轮结果 (为优化召回率低问题,将部分斑点调整为好苹果)
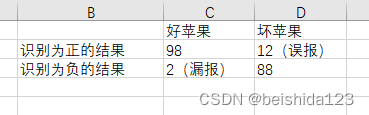
召回率=98/(98+2)=98% ---------------------- 漏报少,召回率高
精确率=98/(98+12)=89.1% ------------------ 误报比第一次多,因为有些斑点被识别为好苹果了,吃了坏苹果拉肚子
结论
召回率越高,漏报越少。精确率越高,误报越少。但大多数情况下,两者会相互制约。