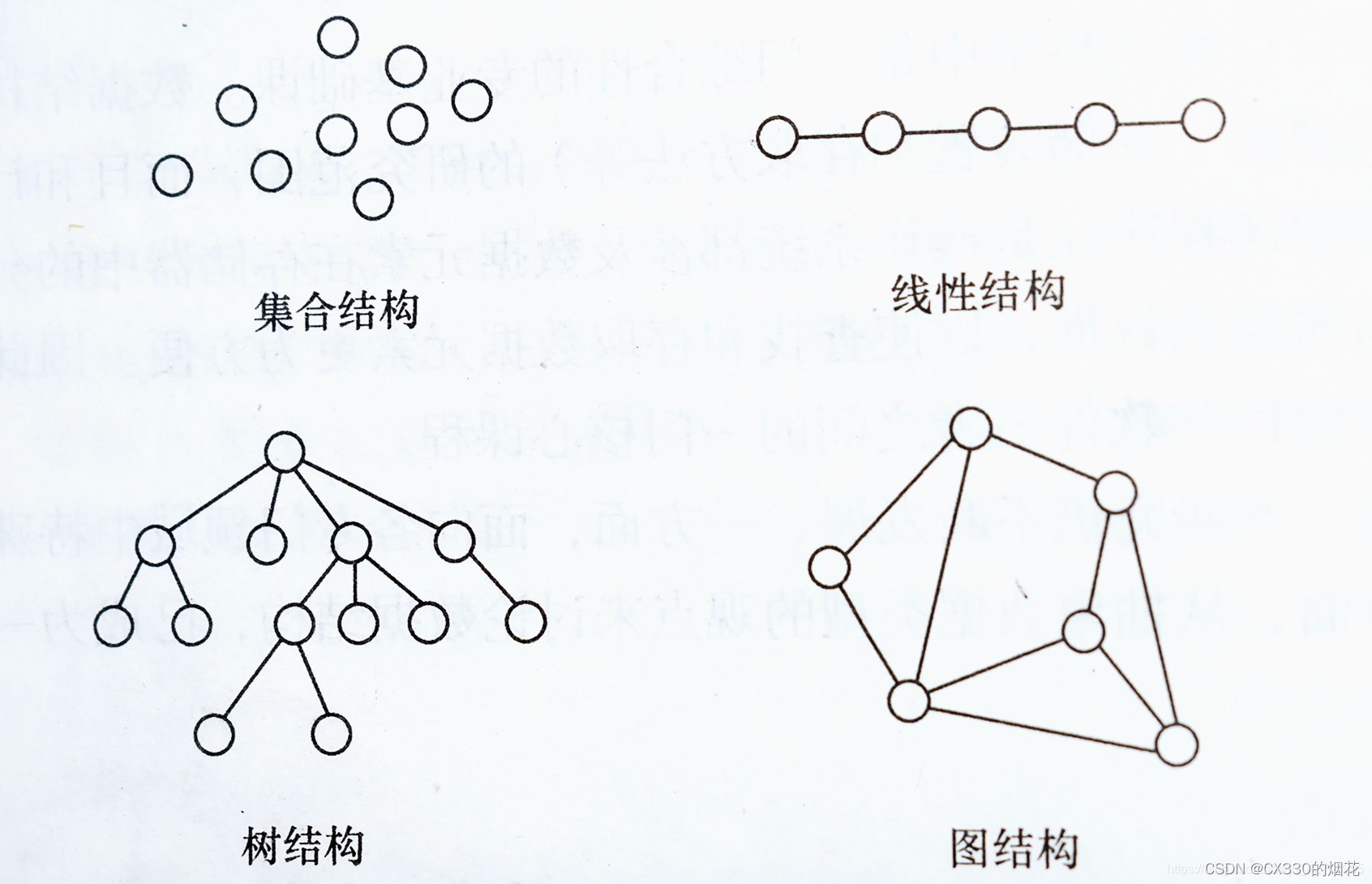
1、LULC 模型的现状
最近的土地利用和土地覆盖 (LULC) 建模进展来自两种方法。 在一种方法中,现有模型适用于 LULC,而在另一种方法中,模型架构是针对 LULC 明确设计的。
随着大型基础模型的兴起,人工智能和深度学习取得了重大进展。 这些模型已经过大量训练数据的训练,可以适应各种领域和数据集。 一个很好的例子是 Segment Anything Model,它是各种分割任务的基础模型。 我们已经开始探索 GeoAI 的分割任意模型的潜力。 通用图像分类模型的其他示例包括 FCN、UNet 或 DeepLab,所有这些模型的主干网络都在 Imagenet(标记摄影图像的参考数据集)上进行了预训练。
虽然这些基础模型有潜力解决一般分割任务,但它们仅限于单图像输入。 然而,正如我们之前概述的那样,时间维度对于准确的 LULC 建模至关重要。 GeoAI 的一个令人兴奋的研究领域特别关注利用时间维度。 这些模型成功地使用卷积、循环编码器和自注意力,通过从时间序列数据中学习来获得出色的结果。
下表总结了两种 GeoAI 方法的优缺点:
| 模型类别 | 优点 | 缺点 |
|---|---|---|
| 基础或重新调整用途 | 现有训练数据的深层堆栈,众所周知的架构和行为,即用型软件实施,预先训练的模型可以快速产生良好的结果 | 光谱带使用不足,专注于 3 波段 RGB,忽略红外波段,不知道时间维度,针对 2D 卷积进行训练,仅单图像分类 |
| 时间序列感知架构 | 面向特定的 LULC 挑战,例如变化检测,文献中证明了高 LULC 精度,时间感知架构利用图像堆栈 | 需要大量的训练数据,而这对于许多项目来说是不可用的,从头开始训练模型既困难又昂贵,需要更多的专业知识,因为软件实施通常不公开或易于安装 |
2、退一步才能前进
LULC 建模的一大限制是缺乏训练数据。 不同 LULC 模型的目标各不相同,通常需要自定义训练数据。 检测北非的城市地区与检测西亚或北美的城市地区是一个非常不同的挑战。 因此,在许多实际例子中,训练数据必须从头开始创建。
虽然建立基础模型是为了克服这一限制,但它们不适用于时间动态很重要的 LULC 制图。 另一方面,专业模型需要大量高质量的训练数据,而这些数据几乎不可能在合理的时间范围和预算限制内创建。
解决这个难题的方法之一是退后一步,专注于目标。 如果我们简化模型并利用数据最重要的方面,我们就可以用更少的努力获得高质量的结果。 我们尝试了利用数据的多光谱和时间性质的模型,但没有考虑土地覆盖的空间特征。
卫星图像堆栈中的光谱和时间信息可以补偿空间背景。 在我们的实验中,即使不利用空间特征,基于像素的模型也可以产生与 2D 模型相同质量的结果。
2.1 简化的训练数据集创建
为 LULC 项目创建训练数据集是一项劳动密集型工作。 简化标记过程可以说是抛开空间上下文的最重要优势。 打标签者不必非常详细地理解和追踪空间背景。 这使得生成训练数据集变得快速而简单。
在绘制 2D 映射的分割掩模时,需要对图像中的每个像素进行注释(图 1 中的左图)。 此过程可能需要 5 到 30 分钟,具体取决于土地利用类别或景观的复杂程度。
一维模型的注释方法更直接、更快速。 注释者只需标记他们最有信心的像素,无需注释每个像素或处理复杂的空间细节(图 1 中的右图)。 不必追踪每个功能的每个细节,可以大大降低复杂性。 此过程通常会将每个图像的标记时间缩短至 5 秒到一分钟。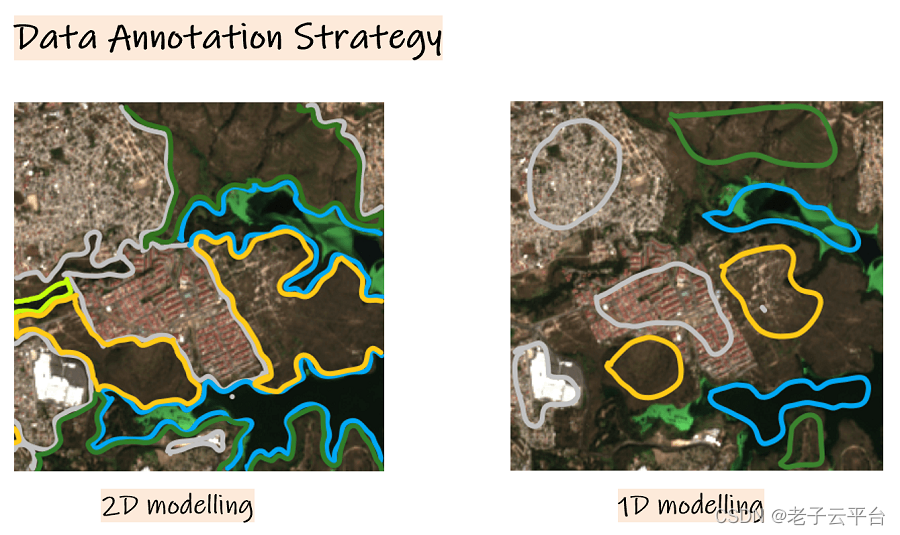
图 1:2D标注 vs. 1D标注
2.2 紧凑模型
简化的模型更小,因此更容易训练和部署。 与卷积模型相比,它们的可训练参数大小减少了高达 1000 倍。 简化的模型也需要更少的数据来实现良好的拟合。 最后,即使在常规 CPU 实例上,较小模型的训练和推理速度也很快。 这使得运行和使用模型的成本大大降低。 对于资源有限的项目来说,这可能是一个显着的优势。
2.3 快速迭代
随着创建训练数据和训练模型的周转速度加快,简化的模型加快了迭代过程,促进了高效的模型细化。 在这些模型之上构建主动学习循环变得毫不费力。
这就是建模周期在实践中的样子:
- 在数小时内创建第一个训练数据集。
- 训练模型并创建第一个模型预测。
- 在模型输出的基础上创建额外的标签,专注于主动学习并在最需要的地方帮助模型。
- 返回步骤 2 并迭代,直到模型输出令人满意。
3、森林类型映射测试用例
我们在一个项目中测试了上述技术,其目标是区分森林类型和景观类别。 使用具有四个月内每两周一次的时间序列和十个光谱带的单像素模型,我们实现了与 U-Net 2D 模型相同的质量。
图 2 中的可视化显示了一些基于像素的模型输出以及每个预测的基础图像系列:

图 2:该模型对于不断变化的景观、季节性和大气影响具有稳健性。
对于此示例,我们开发了一种基于像素的小规模模型,而不是用于 LULC 映射的深层模型。 该编码器由一个 2 层 1D 卷积块组成,具有不同的内核映射,用于处理时间序列数据立方体的各种属性。 这些提取的特征被输入多层感知器(MLP)以生成像素级掩模。
通过采用基于像素的模型,我们还克服了在处理平铺数据时 2D 模型中常见的边缘伪影的挑战。
高级模型结构如下图所示。 有关我们如何实现模型架构的更多详细信息,您可以查看以下模型要点文件。
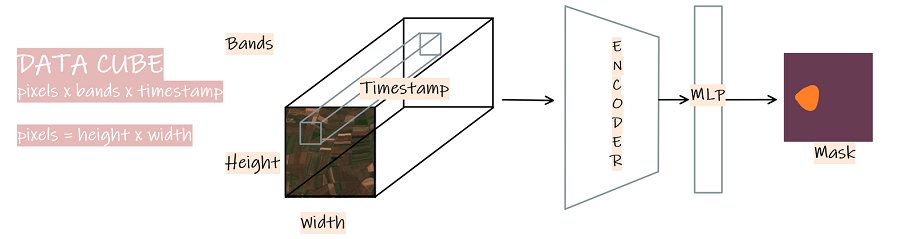
图3:Data Cube模型结构
为了有效地查询数据集,我们利用了时空资产目录(STAC)。 我们利用了云优化的 GeoTIFF (COG) 格式,这使我们能够在基于云的基础设施上执行高效的查询。
查询数据集时,我们使用元数据指定我们的要求,例如:
- 目录类型(例如“哨兵”、“陆地卫星”、“hls”等)。
- GeoJSON 或用于定义感兴趣的地理区域的边界框。
- 用于指定数据时间范围的时间范围(例如“2021 年 1 月 - 2022 年 5 月”)。
对于每个训练样本,我们随时间收集一堆图像,并定期合成图像。 在上面的示例中,我们使用 14 天的间隔和简单的云去除算法来尽可能减少云。
对于模型训练,我们使用 xarray 创建数据立方体,由沿时间维度的像素复合组成。 这些数据立方体还包括每个土地利用类别的栅格化标签。 该管道的概述如图 4 所示。
图 4:数据管道
4、结束语
我们强调了时间序列数据在土地利用建模中的关键作用。 时间信息在准确绘制土地利用地图方面的重要性变得显而易见,特别是随着深度时间档案的可访问性不断提高。 在土地利用模型中包含时间序列数据可以增强其稳健性和准确性。
此外,时间上下文可以成为获取空间 2D 上下文的可行替代方案,而空间 2D 上下文通常具有挑战性。 通过用时间上下文替代空间上下文,为更简单的模型创建训练数据变得更快、更经济、更高效。 这种替代在许多实际用例中证明是有价值的,证明时间上下文和频谱深度可以有效地替代空间上下文。