想折腾bert的同学,应该也遇到这个问题。
一、报错信息分析
完整报错信息:OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like google/mt5-small is not the path to a directory containing a file named config.json. Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
OSError 是 Python 中的一个内置异常,在处理文件或目录操作时可能会遇到。OSError 错误通常涉及到文件系统相关的操作,例如创建、读取、写入或删除文件,以及操作目录等。当执行这些操作时,如果出现了错误,就会抛出 OSError 异常。发生这个问题,处理起来就相对麻烦一点,不像ImportError只用下载安装包即可。
We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like google/mt5-small is not the path to a directory containing a file named config.json.总之huggingface这个网站连不上去不能下载文件,虽然Hugging Face 可以连上,但没什么用,报错也支出不能在缓存文件中找到,这里就有个思路处理这个问题,把模型下载下来,然后通过缓存直接调用!
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.报错的提示是,检查你的网络连接,或者如何通过离线模式运行对应库,这两个提示也代表了两种方案,前提都是网络能连上,但连不上就不考虑了。
二、问题处理
根据上述分析给出一种基于镜像网站的解决方案。
步骤一:找到镜像网站:HF-Mirror - Huggingface 镜像站,并搜索模型

步骤二:点开Files and versions查看文件

步骤三:文件分析与下载。先读readme,讲解了"Text-to-Text Transfer Transformer" (T5)的大概,不过没用说对应文件是什么用的,各文件分析:
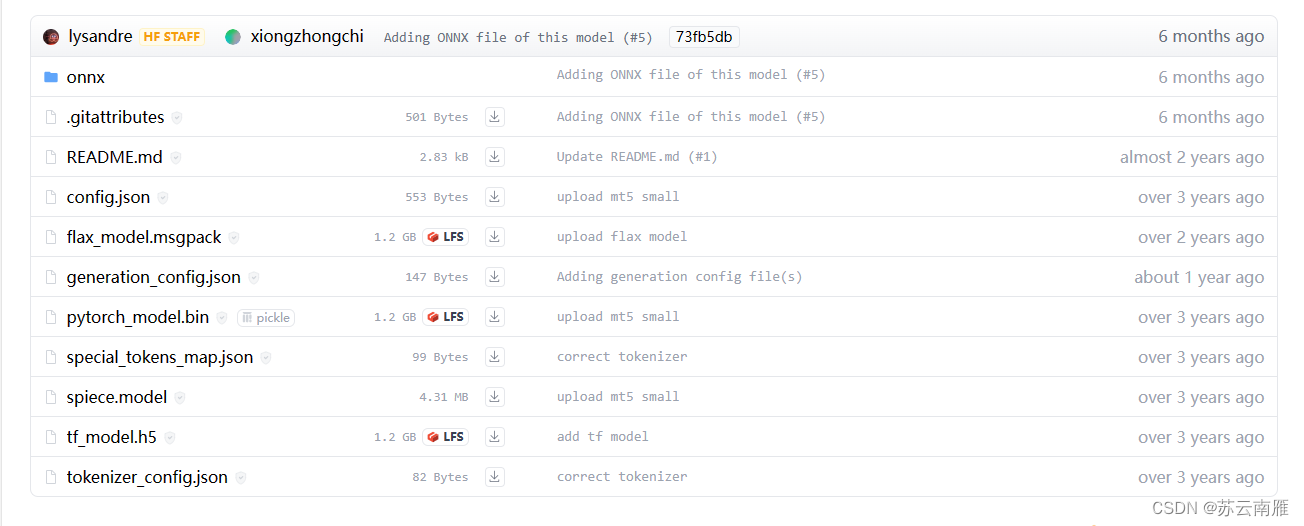
.gitattributes :git操作相关属性说明。当执行 git 动作时,.gitattributes 文件允许你指定由 git 使用的文件和路径的属性,例如:git commit 等。换句话说,每当有文件保存或者创建时,git 会根据指定的属性来自动地保存。
README.md : 说明文件,一般都得看下。
config.json :定义了architectures等超参数flax_model.msgpack:标注了LFS(Large File Storage),和其他两个一样,有个_model都是模型文件。Flax库和pytorch、TensorFlow一样,也是个神经网络框架。
generation_config.json:和config.json类似,也是一些超参数信息,不过是训练之后的超参数信息。
pytorch_model.bin:pytorch版本的模型,用bin存储
special_tokens_map.json:记载了特殊字符的映射,比如"unk_token"、"<unk>"都映射为空
spiece.model:包含vocab(词汇表),mt5模型由于vocab词汇表中的词汇过多,采用从spiece.model之中读取的方式处理。
tf_model.h5:TensorFlow版本的模型,用h5存储,H5文件是层次数据格式第5代的版本(Hierarchical Data Format,HDF5),它是用于存储科学数据的一种文件格式和库文件。
tokenizer_config.json:也是一种字符设置,和special_tokens_map.json类似
分析完之后,其实模型下载自己神经网络框架对应版本,其他配置文件全部下载:
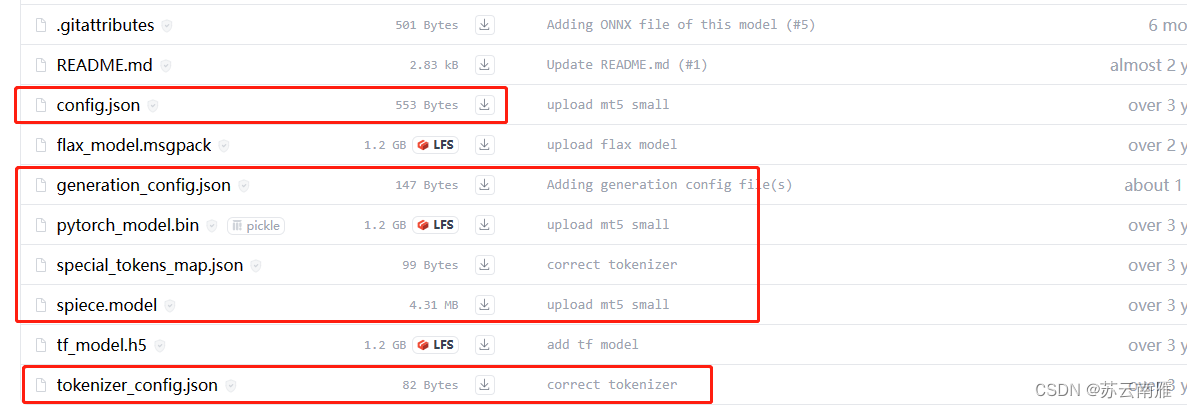
步骤四:将下载好的文件放在你需要的目录下,比如我把下载文件放在'D:/download/model/mt5s/'
步骤五:修改缓存路径,并调用就行了。
model_checkpoint = 'D:/download/model/mt5s/'
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)



![洛谷_P2678 [NOIP2015 提高组] 跳石头_python写法](https://img-blog.csdnimg.cn/direct/46eafd9a6cbc4ee5a74df55614c6856e.png)