本期作者

1.前言
在广告检索系统中,增量索引(实时索引)是一类常见的技术,用于使广告信息的变更及时生效。其中一种主要的思路即由检索系统消费广告更新数据流,实时更新内存索引,对此行业中已有很多优秀方案实现。然而,对与如何构建出“广告更新数据”,却鲜有提及。
本文将针对如何构建出完整、可靠、可维护的“广告更新数据流”进行展开叙述。
2.业务背景
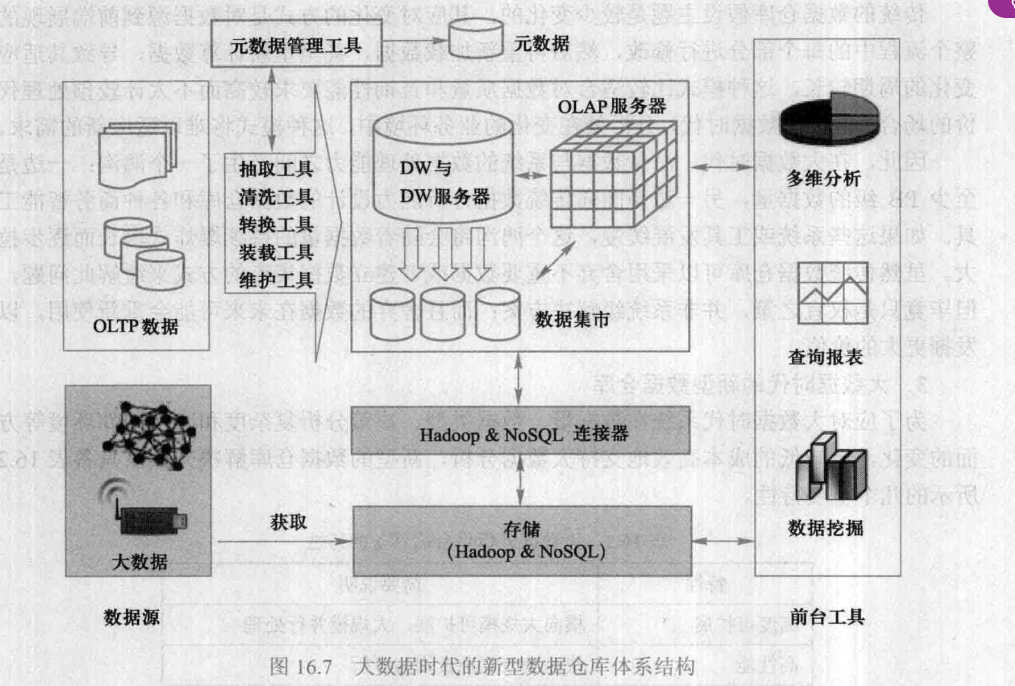
在线广告是实现流量变现重要业务模式。广告检索系统是其中的核心系统之一,其一种常见的架构是由“索引构建服务”构建出广告物料索引数据,再由“检索引擎”加载数据,用于在线广告检索。
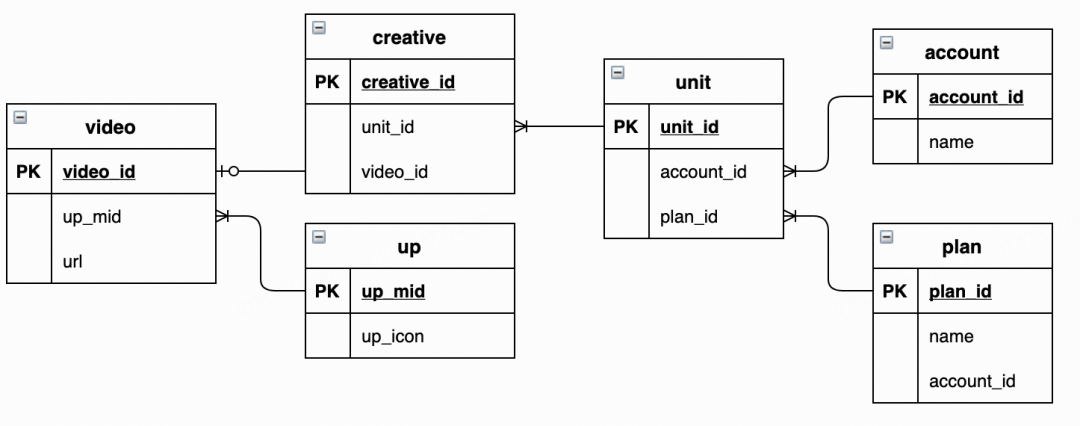
相比于搜索或推荐业务,广告的物料数据量不算最大,但构建逻辑极其复杂。以下图为例,构建广告物料索引以单元(unit)表为核心,查询相关的账号(account)、计划(plan)、创意(creative),进而再通过创意id查找图片(image),视频(video),up主(up)等。
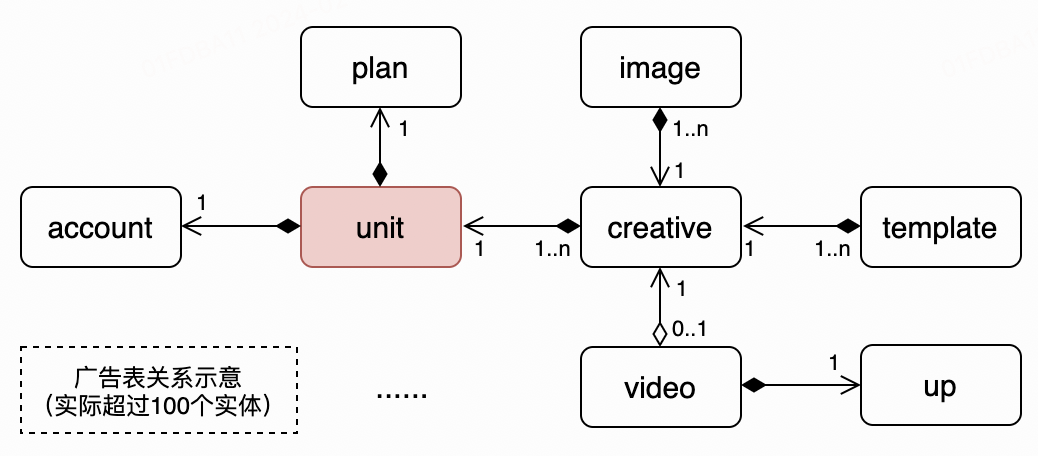
相关数据查询完后,提取各表数据并组装,形成一个个“广告文档(doc)"。单个doc的文本的形式如下:

由于单元数据量较大,相关数据库表多(超过100张表),这些单元还分属不同的业务线、不同类型、不同样式,所关联的构建逻辑也不尽相同,形成了复杂的查找链路。
并且,随着业务量越来越大,整体的延迟越来越长,广告的物料数据更新不及时,影响了广告的时效性,最终降低了广告的投放体验和效率。
3.方案演进
广告索引的构建和下发经历了漫长的优化迭代,包括本文主要介绍的增量索引在内,主要分为如下三个阶段:
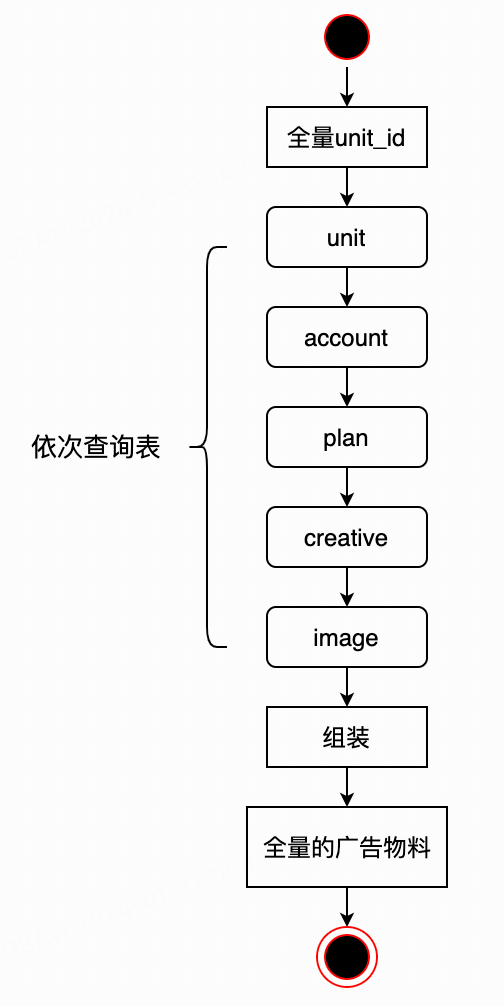
阶段一:全量串行——所有数据串行查询,串行构建
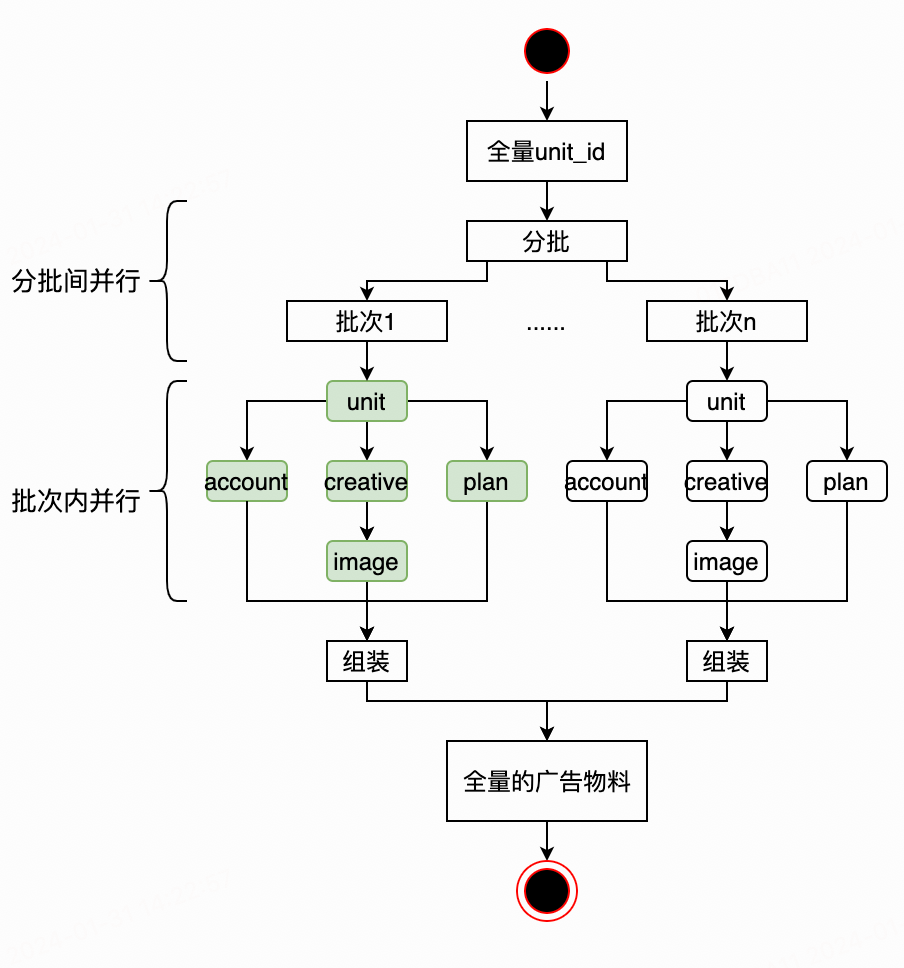
阶段二:分批间并行,批次内并行——将全量的单元id分为多个批次,多批次间并行执行,批次内按照数据依赖的拓扑关系并行查询组装
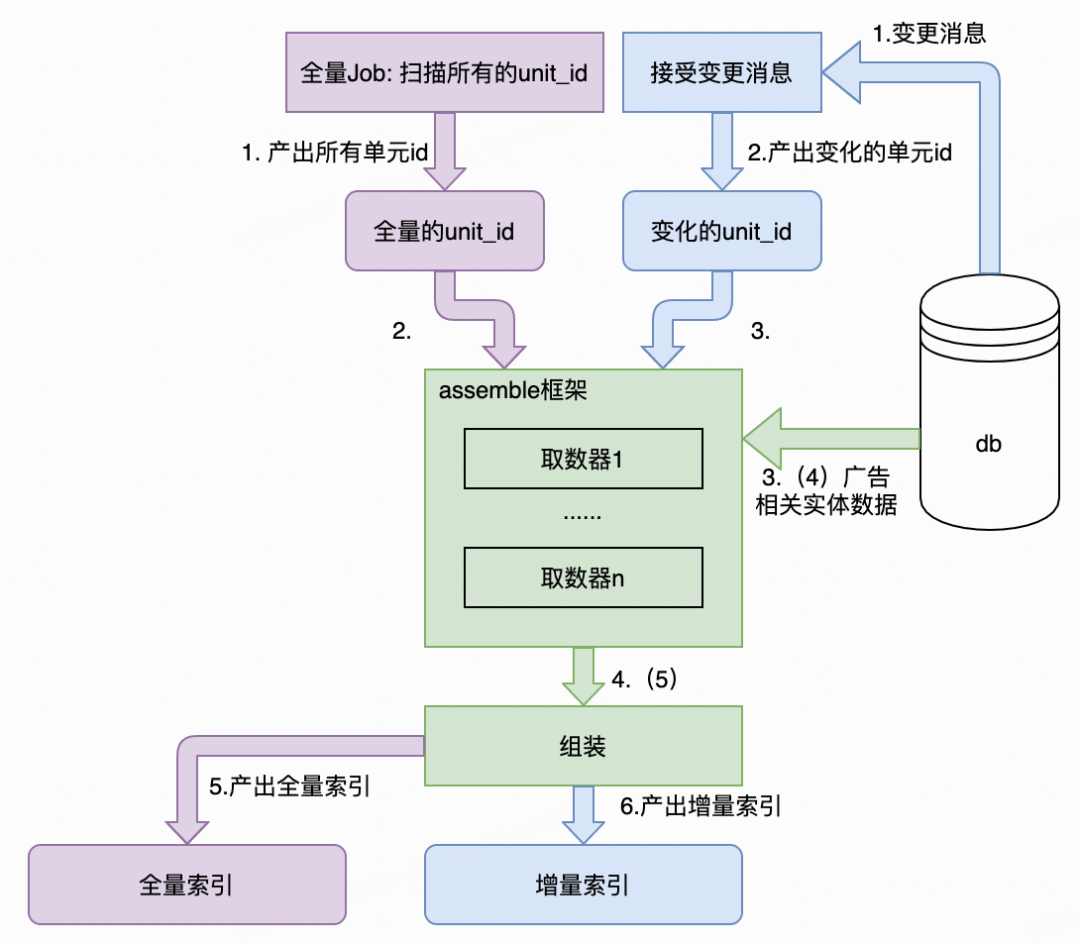
阶段三:增量构建+全量构建——定时构建的广告索引,有数据发生变更则构建发生数据变化的这部分广告物料索引
| 阶段一:全量串行 | 阶段二:分批并行 | 阶段三:增量+全量 | |
|---|---|---|---|
| 流程 |
|
|
|
| 特点 | 数据库负载:一般 构建耗时:长 数据传输负载:很高 | 数据库负载:很高 构建耗时:较短 数据传输负载:很高 | 数据库负载:很低 构建耗时:全量耗时长,增量耗时很短 数据传输负载:很低 |
从阶段一到阶段二,在时效性上有一定提升,但是给数据库带来了很大的压力,且网络传输负载很高。
在查询全量数据的前提下,无论做何种并行化优化,该查的数据还是得查,数据库负载会随着业务扩张不断增加,数据量也会一直膨胀,更新时效性也越来越差,优化的边际递减效应明显。
因此阶段三中引入了增量索引技术,采用全量索引+增量索引的构建模式。
4.增量索引
增量索引的广告物料分为两类:
-
全量广告索引——定时(1小时或者更长)全量构建所有广告单元数据,产出一份包含全量单元的索引数据
-
增量广告索引——只构建数据发生了变化的广告单元,单独产出一份增量单元索引数据
两者的触发机制不同,产出的数据结构类似,但是包含的内容范围不同。
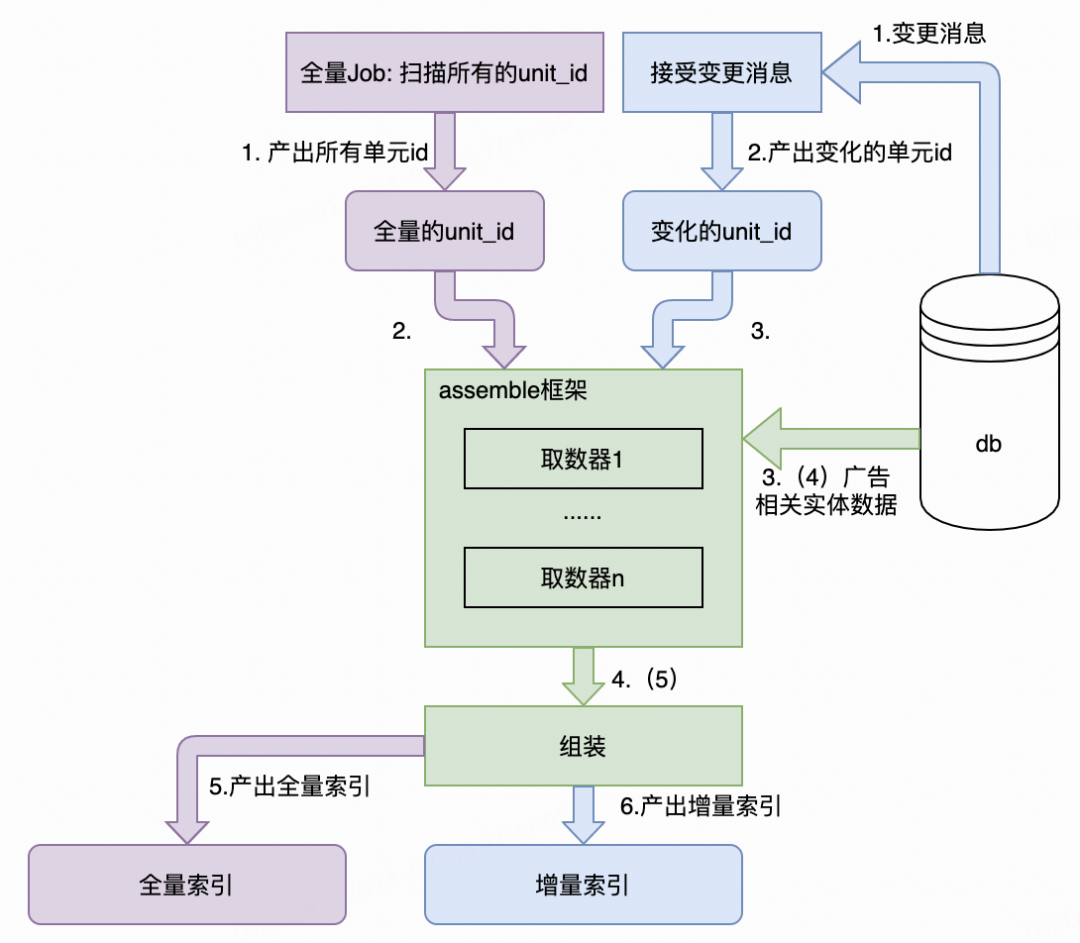
如上图,紫色模块是全量索引构建的流程,蓝色部分是增量索引构建的流程,绿色部分是公共的部分。全量增量的主要差异在于:全量索引任务的unit_id是所有单元的unit_id,增量索引任务的unit_id是广告数据发生变化的单元的unit_id。
下游检索引擎加载这两类索引,将其合并成一个整体,作为广告物料库使用。
相比起之前的全量方案,增量索引的方案里的全量索引构建频率降低到小时级别,增量只构建和下发发生变化的广告单元,大大降低了数据库负载和数据传输的带宽,提高了更新时效性。
变化的unit_id —— 反查库表?
上图中,接收到DB的原始变更消息后,还需要将其转译为相关变化的unit_id。那么,当单元关联的上百个实体(表)中,部分的数据发生了变化时,如何确认其对应的哪个unit_id发生了变化?
一种简单的想法是根据实体之间的逻辑联系,根据发生变化的实体id反查出其关联的unit_id。
例如下图中,若检测到up.up_icon发生了变化,可通过video表查找出与up_mid关联的video_id, 再通过creative表以video_id为条件查找出关联的unit_id。

上述逻辑看起来是通顺的,然而理清“实体之间的逻辑联系”实际执行时却相当困难。
举几个例子说明:
例1:缺少索引,不适合反查
上图中的例子已经隐约可看出反查unit_id的困难之处,一条记录变更需要通过多次反查才能找到目标。而且在实际应用中,并非每张表都适合反查,例如图中的creative.video_id字段其实并没有索引,若以video_id为条件进行查询,则会发生全表扫描,效率极低。
例2:字段类型复杂,无法反查
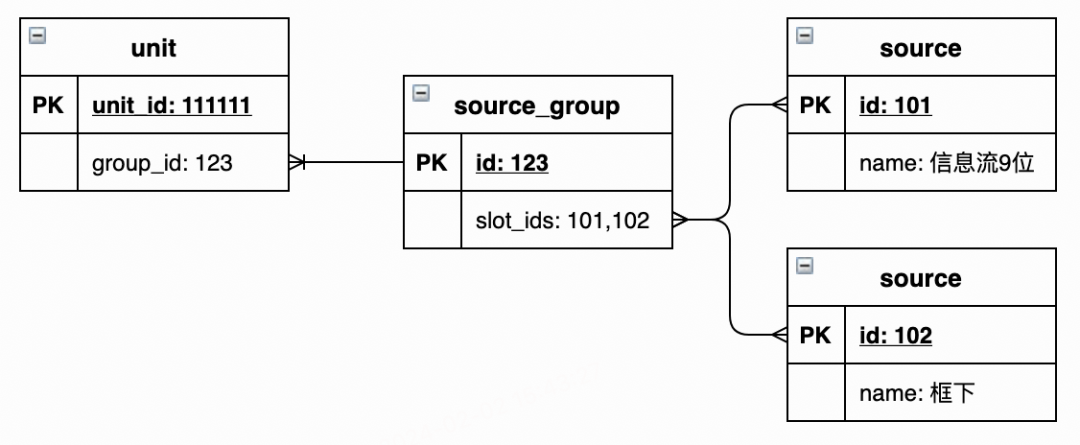
除此以外,还可能存在反查条件字段难以直接用于查询的情况。例如下图中,若source表中id位101的数据发生了变化,则需要以"source_group.slot_ids包含101"为条件才能查找出对应的source_group.id,难以执行。
例3:逻辑复杂很难理清
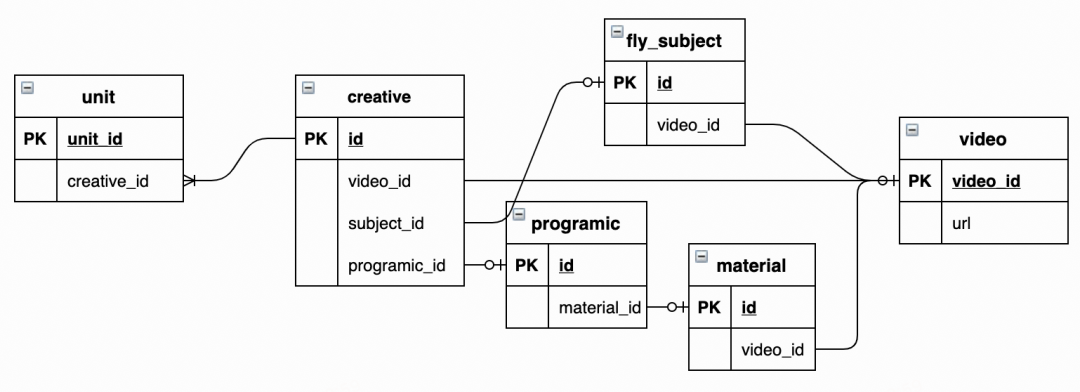
即便没有上述数据库查找问题,分析实体间关联关系本身也是有一定难度的。如下图,unit和video以多种路径相关联,编写反查逻辑时需要覆盖多种情况,容易遗漏。况且,对广告相关的上百张表都要做此分析,极大地增加迭代和维护成本。
利用历史索引?
反查库表难以执行,那么尝试换一种思路。在全量构建索引时,单元相关的实体数据通常已经记录在doc中,那么能否考虑从历史已构建出的doc中直接根据变化的条件查找出对应的广告?
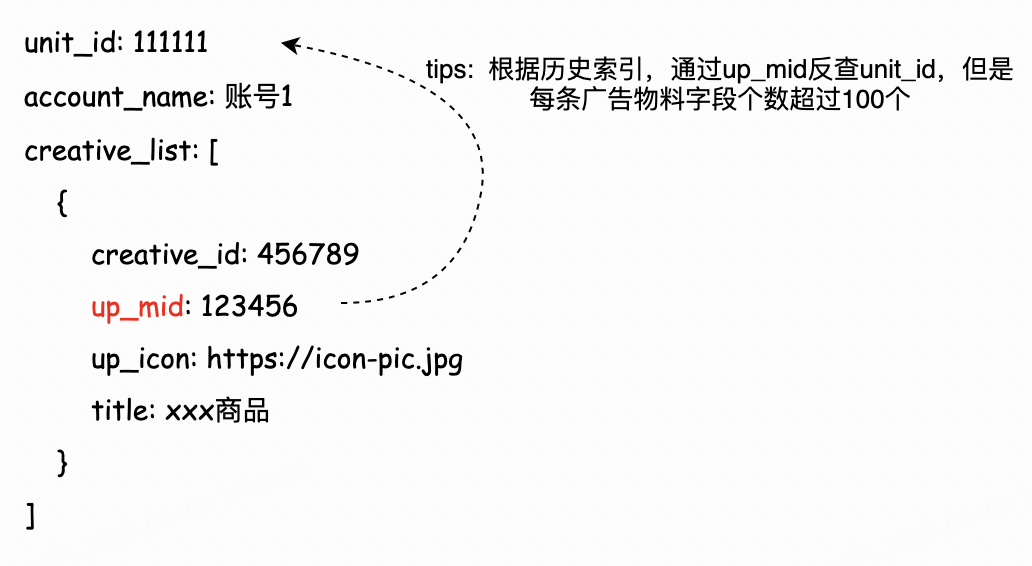
例如,历史全量索引存储了每个有效广告关联的up_mid列表。那么当up表的数据变化时,如果遍历此前已构建出的有效历史索引中的每一个doc,即可查找出哪些广告unit_id关联了这个变化的up_mid,从而触发这些广告的增量更新。
但如此一来,又引发了以下三个问题:
问题1
广告doc的数据结构非常复杂,层级众多,从其中找出up_mid的逻辑是定制的;对每一个unit表的关联实体都需要定制,产生大量与构建过程耦合的代码,仍然容易出错。且对层级很深的数据,查找的代码编写起来也有难度。
问题2
每次触发同类事件时,都需要遍历历史索引中的每一个doc,遍历过程系统开销大、耗时长,难以满足业务需求。
问题3
这种方式查找出的广告unit_id是比预期更少的,因为在索引构建过程中可能发生过滤,而当这个过滤条件被满足时理应触发被过滤的广告更新,但由于被过滤的广告ID不会被保存下来,因而无法触发。
比如,plan某条记录的状态为“关闭”,导致索引里没有与其相关联的unit,某个时刻,这条plan记录的状态从“关闭”变更为“开启”,此时应该触发相关单元的构建,但是由于历史索引里缺少数据而无法触发。
在构建过程中记录关联关系
上面的问题1,本质就是要从广告的索引数据结构中查找出其关联的其他各类ID,相关代码定制性强,耦合度高,可维护性差。
因此需要寻找一种方法,可以用标准化、低耦合、自动化程度高的方式记录下每一个广告单元ID与其他各类ID之间的关联,与索引数据一同存储下来, 从而当捕获到某种触发事件时,无论其与广告之间的关系有多么曲折,直接从这份关联数据中查找到。
为了建立一一对应的关联关系,且方便从其他实体的ID反查出广告单元ID,在此对构建的流程做出以下假设:
-
假设1:构建逻辑针对每一个待构建的广告单元,是逐个处理的(而不是批量处理),不同单元的构建过程之间不存在逻辑上的关联。
-
假设2:构建指定的单个广告单元,从数据源获取相关数据时,都是通过类似"KV"形式的模块(称之为“取数器”)进行获取。
举个例子,假如有如下的关系表依赖:
一般而言,每个表对应一个“取数器”,根据上述的关系依赖,每个取数器的入参和返回可定义如下:
interface UnitBaseService {// 获取广告单元的基本信息,这些信息不足以直接使用,需要拼装其他数据UnitBase getUnitById(long unitId);}interface CreativeService {// 获取创意List<Creative> getCreativeByUnitId(int unitId);}interface VideoService {// 获取视频Map<Long, Video> getVideoByVideoIds(Iterable<Long> videoIds);}interface UpService {// 获取Up主Map<Long, Up> getUpByUpMids(Iterable<Long> upMids);}
在此基础上,查询数据的流程示意如下:
class Assembler {UnitBaseService unitBaseService;CreativeService creativeService;VideoService videoService;UpService upService;// 组装单个广告Unit assembleUnit(long unitId) {UnitBase unitBase = unitBaseService.queryByUnitId(unitId);List<Creative> creativeList = creativeService.queryByUnitId( unitId );从 creativeList 中提取出 videoIdsMap<Long, Video> videoMap = videoService.queryByVideoIds( videoIds );从 videoMap 中提取出 upMidsMap<Long, Up> upMap = upService.queryByUpMids( upMids );// ...// 将所有相关数据组装起来,成为可用的广告单元数据;Unit unit = doAssemble(unitBase, creativeList, videoMap, upMap);return unit;}}
上述的查询流程方法(assembleUnit)中,输入参数只有一个unitId,满足了假设一。在assembleUnit方法里调用服务查询时,各种输入参数(videoIds,upMids)便和唯一的unitId关联起来。
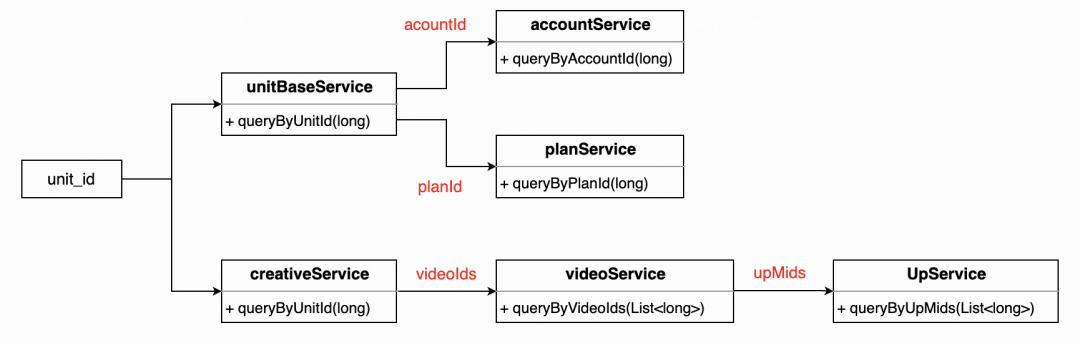
如上图所示,unit_id和其他表字段的联系可以构建如下:
| 关系 | |
|---|---|
| 1 | unitId → accountId |
| 2 | unitId → planId |
| 3 | unitId → videoIds → upMids |
前两条关系是直接关系,当account表和plan表的数据发生变化时,都可直接追溯至unitId。
但第三条关系 unitId → videoIds → upMids,关联了超过2类id,从unitId到upMids是间接关系,在实际检索中很难使用。
使用直接关系替代间接关系
间接关系是很难使用和维护的,将间接关系转为直接关系。如下图所示:
| 关联关系 | 直接关系 |
| unitId → videoIds → upMids | unitId → videoIds unitId → upMids |
举例说明直接关系如何运作,存在如下的数据:
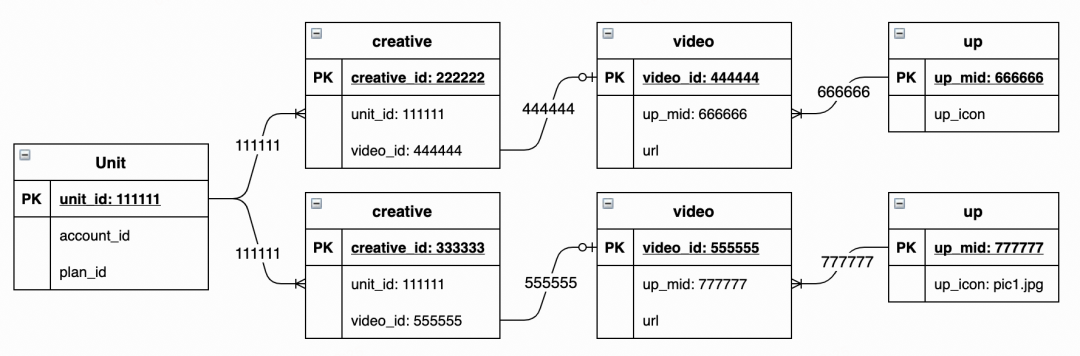
建立的直接关系如下:
| (unitId → videoIds) | (unitId → upMids) |
|---|---|
| 111111 → 444444,555555 | 111111 → 666666, 777777 |
如果up表里的up_icon发生了变化,从 pic1.jpg 变为 pic2.jpg,对应的这个up_mid是777777.

在unitId → upMids的关系里,存在111111 → 666666, 777777的关系,因此这个变化可以被捕获并反查出变化的unit_id 111111,由此触发了111111这个单元的构建。
因此从间接关系拆为直接关系后,up表的变更无需通过video表,即可查出来哪些unit_id发生了变化。
框架自动捕获依赖关系
具体到框架层面,使用装饰模式(可用AOP技术、静态代理、动态代理等技术实现),自动地记录下构建过程中unit关联的其他ID(account_id, plan_id)的关系。
// 代表一个广告单元一次构建过程的上下文; 其中的各类Service是被装饰过的,含有记录所访问ID的功能
class BuildingContext {
UnitService unitService;
CreativeService creativeService;
VideoService videoService;
UpService upService;
}
// 上下文工厂,在其中可以对各类Service进行装饰,自动记录unitId与其他ID的关联关系
class BuildingContextFactory {
UnitBaseService unitBaseService;
CreativeService creativeService;
VideoService videoService;
UpService upService;
BuildingContext getContext(long unitId) {
// decoratedUpService是经过装饰的UpService
UpService decoratedUpService = new UpService() {
Map<Integer, Up> queryByUpMids(Iterable<Long> upMids) {
// 记录下unitId与被查找的upMids存在关联
record(unitId, upMids);
// 调用基本功能
return upService.queryByUpMids(upMids);
}
};
// decoratedVideoService同理
VideoService decoratedVideoService = new VideoService(){ ... };
return new BuildingContext(unitBaseService, creativeService, decoratedVideoService, decoratedUpService);
}
}
// 记录一个单元与其他ID存在联系;这里仅用于示意,实际开发中的定义会更加抽象,自动适用于各类ID
class UnitRelation {
long unitId;
List<Long> creativeIds;
List<Long> videoIds;
}
// 组装器可得知待更新广告单元ID列表
List<Long> unitIds;
for(long unitId : unitIds) {
// 调用Assembler
BuildingContext context = buildingContextFactory.getContext(unitId);
Unit unit = assembler.assembleUnit(unitId, context);
// 导出构建过程中发现的unitId与其他各类ID的关联,并与索引数据一同记录下来
UnitRelation unitRelation = exportRelation(context);
record(unitRelation);
}特别注意的是,在上述的record(unitId, videoIds)方法里,直接记录了unitId和upMids的关系。
从而,问题1得到解决;同时由于提前记录了关系而不受过滤的影响,也解决了问题3。
生成关系倒排表
接下来则要解决问题2,即提高查找关联的效率
由于在上述的构建流程中记录了广告单元ID其他各类ID之间的关联后,如此一来,可以形成其他表和unit_id的关系如下:
| unitId | account_id | plan_id | video_id | up_mid |
|---|---|---|---|---|
| u1 | [a1] | [p1] | [v1,v2] | [m1, m2] |
| u2 | [a1] | [p2] | [] | [] |
| u3 | [a2] | [p3] | [v3] | [m2] |
| u4 | [a2] | [p3] | [v1] | [m1] |
在以上关系中,每行是unit_id构建一次时建立的直接关系。实际使用场景是关联表数据发生了变化需要回溯到单元id。
为此将其转化为如下的倒排关系:
| relation | relation_id | unit_id |
|---|---|---|
account_id | a1 | [u1, u2] |
| a2 | [u3, u4] | |
| plan_id | p1 | [u1] |
| p2 | [u2] | |
| p3 | [u3, u4] | |
| video_id | v1 | [u1, u4] |
| v2 | [u1] | |
| v3 | [u3] | |
| up_mid | m1 | [u1, u4] |
| m2 | [u1, u3] |
如此一来,如果up表里up_mid为m1的记录的up_icon发生了变化,可快速从上述的表中通过m1→[u1,u2]的关系记录,反查到单元id为u1和u2的单元需要重新构建,问题2也得到解决。
检测数据变更
上述方案解决了核心问题:当数据发生变更时,检测出影响到的unit_id。
而对于如何检测数据变更,本方案采用了如下两种:
1.binlog触发
即监听binlog消息,提取出直接关系的id。

以video表的binlog为例,由于binlog里有修改前和修改后的记录的完整信息,因此不论是修改了关联字段还是删除,都可以找到对应的video_id,进而反查出unit_id。
Binlog触发时效性高,且信息完整,可以体现硬删除和变更前旧值的信息,是主要的检测手段。但其对于生产、投递、消费各环节可靠性要求较高,不能丢失消息。
2.近期扫描触发
按我司数据库规范要求,所有表必须携带mtime(最后修改时间),因而可用mtime检测近期的数据变更情况。
但这种方式有所缺陷:1. 时效性较低;2. 不可用于检测硬删除的情况;3. 不能直接获取变更前的旧值。
并且,还有一类update的情况需要注意,例如有如下表the_table
| material_id | unit_id | material_content | mtime |
|---|---|---|---|
| m1 | u1 | content1 | yesterday |
通过类似这样的sql可以发现最近变更的unit_id:
-- SQL1select unit_id from the_table where mtime >= 'today'
如果发生了下面SQL2这样的update,则该条记录的mtime会发生变化,因此上面的SQL1检测到unit_id(u1)的变化
-- SQL2update the_table set material_content = "something else" where unit_id = 'u1'
但如果是下面SQL3这样的更新操作,则无法检测到u1单元的变化:
-- SQL3update the_table set unit_id = `u2` where unit_id = 'u1'
虽然该条记录的mtime仍然会发生变化,但同时unit_id也发生了变化,通过SQL1查询出的结果只有u2, 而不包含u1
因而,unit_id为u1的记录发生了变化,却不会被监测到,这是不符合预期的。
针对这样的问题,有以下解决方式:
1.与业务端约定,凡在组装器(假设2)中作为ID检索条件的字段,不能够被update
-
作为检索条件的字段,通常也是实体ID;记录实体间关系的记录,通过update改变关系的情况较少
2.方式1无法满足时,可以稍微改造组装器逻辑:
-
原本组装器中sql select * from the_table where unit_id = 'u1',即查出该表与u1相关的记录,而不需要查找关联关系
-
现改为:select material_id from the_table where unit_id = 'u1',可查出关联的m1 ,再执行select * from the_table where material_id in ('m1'),可查出相关记录
-
这样一来,关联关系中会记录m1与u1存在关联关系
-
既然material实体与unit相关,那么就需要检测其变化select material_id from the_table where mtime >= 'today'
-
再代入执行上面的SQL3,虽然库中记录的unit_id被改为了u2,通过SQL1已不能直接查出u1的变化,但我们能够查出material m1的变化
-
再配合历史记录的m1与u1的关联关系,即可得知u1也发生了变化,从而触发u1的重新构建
降频
在上述两种触发器中,对任何相关实体的所有信息变化都触发相关广告变更,可能是没有必要的。因为有很多变化实质上并不会影响索引的构建结果。这种情况下触发变更会增加构建器及其依赖数据源的压力,还会使得检索系统中累计更多的增量,是对资源的浪费。
因而可对无用的触发进行降频。采用技术如下:
无关字段降频
-
索引构建中,对某个实体表很可能并没有使用到全部字段,而是只使用其中一部分,那么当其中只有不关注的字段发生变化时,可以不触发构建
-
binlog触发器中,可以对比新旧值,判断是否有受关注字段发生了变化
-
近期扫描触发器中,由于无法直接获取旧值,可以配合取数器,在每次取数时缓存旧值,触发时使用缓存旧值与当前值对比
分级降频
-
对数值类、或可聚合的实体信息,并非任何一点变化都需要触发,可以分级处理
-
例如稿件的收藏数从1000变为1001时,这一变化很可能并不会影响广告的策略或样式,则可以不触发构建
-
对此,可将数值类信息进行分级,通过对比新旧值的级别是否发生变化,决定是否触发构建
-
同样binlog触发器中可获取到新旧值直接计算分级和对比,近期扫描触发器中可以配合取数器缓存判断
状态降频
-
若将实体分为有效和无效状态:有效状态即为索引构建需要纳入该实体的状态;反之,无效状态即索引构建无需纳入该实体的状态
-
若实体处于有效状态时,其他的受关注字段变化时应当触发构建
-
若发现实体在有效、无效状态间切换,也应当触发构建
-
若实体处于无效状态,则即使其受关注字段变化,也无需触发构建
低优降频
-
并非所有的实体信息变化都是需要立即反馈在索引中的,对于时效性要求较低的变更,可以暂不触发,而是等待全量触发,或主动全量触发
整合流程
倒排关系和框架整合进构建流程如下:
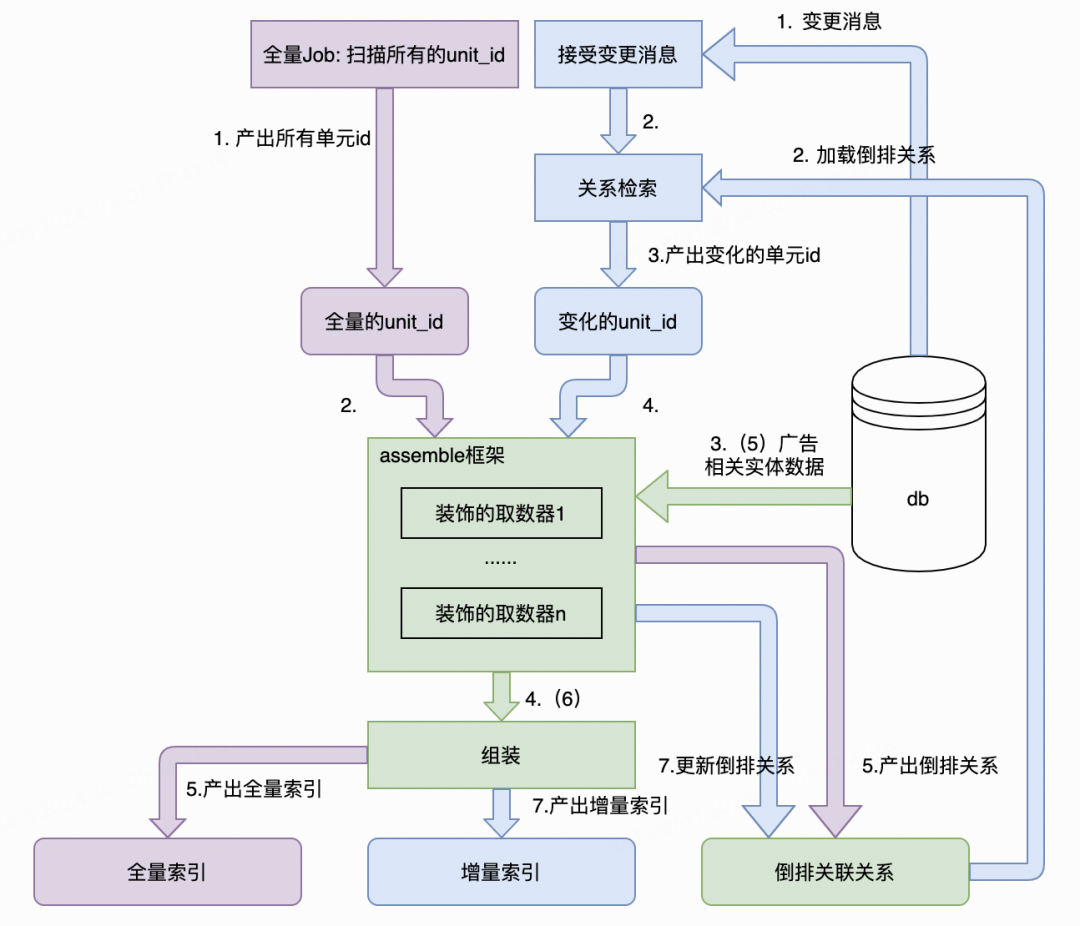
全量索引构建流程(图中紫色的模块,绿色部分是公共流程)
1.全量索引定时构建开始,查询单元表(unit),产出所有的unit_id,
2.以每个unit_id为入参,控制每一个unit_id的调用组装流程
3.使用装饰的取数器查询数据库,获取全量的数据
4.组装广告物料
5.产出全量广告索引和倒排关系,其中全量广告索引供在线广告检索引擎使用
增量索引构建流程(图中蓝色部分)
1.接受db的变更消息——扫描mtime 和 接受binlog
2.从接受的消息中提取出实体id,并加载倒排关系索引
3.根据倒排关系索引和变更的实体id,回溯出需要更新的unit_id
4.以每个unit_id为入参,控制每一个unit_id的调用组装流程
5.使用装饰的取数器查询数据库,获取全量的数据
6.组装广告物料
7.产出增量广告物料索引供在线广告检索引擎使用,同时更新倒排关系数据
通过增量索引技术,实现了广告变更秒级对在线检索引擎生效,同时构建过程对数据库压力大幅降低,相关的数据存储、传输开销也得到了大幅优化。
5.思考展望
增量构建从根本上解决了全量构建带来的数据库负载高,数据传输量大的问题。下游接入增量构建物料后,广告的延时降低到秒级别,且CPU、内存、网络IO等资源的使用效率得到了明显改善,在此过程中,研发团队也积累了丰富的经验和知识,将为未来的项目研发提供了重要支持。
根据目前线上迭代情况,存在以下问题需要持续优化:
增量物料易用性优化
增量物料是由全量和增量两个部分组成的,业务方在使用的时候需要对其进行合并,这会带来一定的接入困难,如何更好的让系统适配全量加增量的模式,是该方案能得到推广的一大保障。