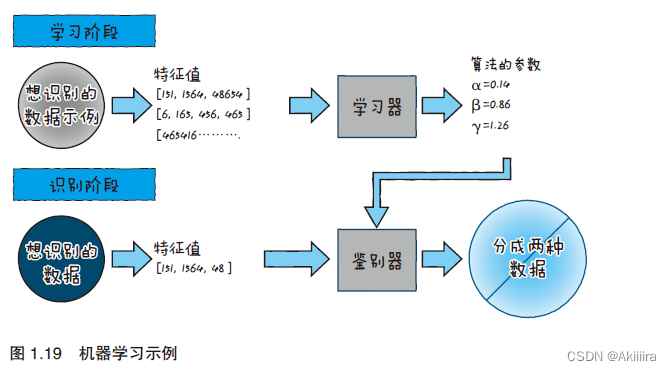
import pandas as pd
import matplotlib. pyplot as plt
df= pd. read_excel( 'mrbook.xlsx' )
df
序号 书号 序号.1 月份 销量 rate 0 B18 9.787569e+12 1 1月 1506 0.3 1 B19 9.787569e+12 2 2月 1200 -0.3 2 B25 9.787569e+12 3 3月 3305 0.6 3 B21 9.787569e+12 4 4月 6610 0.5 4 NaN NaN 5 5月 8888 0.3 5 B15 9.787569e+12 6 6月 12354 0.3
plt. rcParams[ 'font.sans-serif' ] = [ 'SimHei' ]
plt. rcParams[ 'axes.unicode_minus' ] = False
plt. figure( figsize= ( 12 , 9 ) )
fig, ax1 = plt. subplots( )
ax1. bar( df[ '月份' ] , df[ '销量' ] )
plt. title( label= ' 销量情况对比 ' ,
fontsize= 32 , weight= 'bold' , color= 'white' ,
backgroundcolor= '#cf778f' , ha = 'center' , pad = 30 )
ax1. tick_params( labelsize= 16 )
ax1. grid( lw = 0.5 , color = '#3c7f7f' , ls = '--' )
ax1. set_ylabel( '销售(册)' , fontsize= 18 )
ax2 = ax1. twinx( )
ax2. plot( df[ '月份' ] , df[ 'rate' ] , color= '#3c0f7f' , linestyle= '--' , marker= 'o' , linewidth= 2 )
ax2. set_ylabel( '增长率' , fontsize= 18 )
for a, b in zip ( df[ '月份' ] , df[ 'rate' ] ) :
plt. text( a, b+ 0.02 , '%.2f' % b, ha= 'center' , va= 'bottom' , fontsize= 10 , color= 'r' )
plt. show( )
mrtb= pd. read_excel( 'mrtb_data.xlsx' )
mrtb. shape
mrtb. head( )
买家会员名 买家实际支付金额 宝贝总数量 宝贝标题 类别 宝贝种类 总金额 收货人姓名 性别 收货地址 ... 物流单号 确认收货时间 联系手机 联系电话 订单付款时间 订单关闭原因 订单创建时间 订单备注 订单状态 运送方式 0 mr000145 1100.0 1.0 【正版即插即用】ASP.NET编程词典珍藏版(含1TB移动硬盘)资源库 编程词典 1.0 1100.0 *** 男 ********** ... No:21026 2018-03-19 16:23:07 **** 'null 2018-03-09 14:55:49 订单未关闭 2018-03-09 10:00:36 'null 交易成功 快递 1 mr000492 1198.0 1.0 【正版即插即用】ASP.NET编程词典珍藏版(含1TB移动硬盘)资源库 编程词典 1.0 1198.0 *** 男 ********** ... No:21373 2018-06-15 10:57:01 **** 'null 2018-06-09 09:25:16 订单未关闭 2018-06-08 19:33:32 'null 交易成功 快递 2 mr000493 1198.0 1.0 【正版即插即用】ASP.NET编程词典珍藏版(含1TB移动硬盘)资源库 编程词典 1.0 1198.0 *** 男 ********** ... No:21374 2018-06-15 10:57:01 **** 'null 2018-06-09 09:25:16 订单未关闭 2018-06-08 19:33:32 'null 交易成功 快递 3 mr000247 1168.0 1.0 【正版-即插即用】C#编程词典珍藏版(含1TB移动硬盘)资源库 编程词典 1.0 1168.0 *** 男 ********** ... No:21128 2018-12-02 10:46:44 **** 'null 2018-11-20 19:21:58 订单未关闭 2018-11-20 19:21:33 'null 交易成功 快递 4 mr000271 1168.0 1.0 【正版-即插即用】C#编程词典珍藏版(含1TB移动硬盘)资源库 编程词典 1.0 1168.0 *** 女 ********** ... No:21152 2018-11-01 18:41:44 **** 'null 2018-10-29 02:31:39 订单未关闭 2018-10-29 02:30:37 'null 交易成功 快递
5 rows × 21 columns
mrtb1= mrtb. groupby( [ '类别' ] ) [ '买家实际支付金额' ] . sum ( )
mrtb1
"""
类别
V1会员 7425.00
V2会员 14651.00
图书 44650.33
明日高级VIP 15096.00
编程词典 28681.20
Name: 买家实际支付金额, dtype: float64
"""
mrtb2= mrtb. groupby( [ '类别' , '性别' ] ) [ '买家会员名' ] . count( ) . reset_index( )
mrtb2
类别 性别 买家会员名 0 V1会员 女 31 1 V1会员 男 44 2 V2会员 女 36 3 V2会员 男 13 4 图书 女 50 5 图书 男 381 6 明日高级VIP 女 3 7 明日高级VIP 男 14 8 编程词典 女 6 9 编程词典 男 21
plt. figure( figsize= ( 8 , 6 ) )
plt. bar( mrtb1. index, mrtb1. values, color= 'blue' , alpha= 0.5 )
plt. xlabel( '类别' , fontsize= 12 )
plt. ylabel( '买家实际支付金额' , fontsize= 12 )
plt. title( '不同类别的买家实际支付金额' , fontsize= 16 )
plt. xticks( rotation= 45 )
plt. tight_layout( )
plt. show( )
mrtb1_df = pd. DataFrame( mrtb1)
pivot_table = pd. pivot_table( mrtb1_df. merge( mrtb2, on= '类别' ) , index= '类别' , columns= '性别' , values= '买家实际支付金额' , aggfunc= 'sum' )
pivot_table
性别 女 男 类别 V1会员 7425.00 7425.00 V2会员 14651.00 14651.00 图书 44650.33 44650.33 明日高级VIP 15096.00 15096.00 编程词典 28681.20 28681.20
plt. figure( figsize= ( 8 , 6 ) )
categories = pivot_table. index
labels = pivot_table. columns
colors = [ 'pink' , 'lightblue' ]
bottom = None
for label in labels:
values = pivot_table[ label]
plt. bar( categories, values, bottom= bottom, label= label, color= colors. pop( 0 ) )
if bottom is None :
bottom = values
else :
bottom += values
for i, value in enumerate ( values) :
plt. annotate( f'¥ { value: .2f } ' , ( i, bottom[ i] ) , ha= 'center' , va= 'bottom' )
plt. xlabel( '类别' , fontsize= 12 )
plt. ylabel( '买家实际支付金额' , fontsize= 12 )
plt. title( '不同性别在不同类别的消费分布' , fontsize= 16 , backgroundcolor= '#cf778f' )
plt. legend( )
plt. xticks( rotation= 45 )
plt. tight_layout( )
plt. show( )
win = pd. read_csv( 'data.csv' , encoding= 'gb2312' )
win. head( )
开奖日期 期号 中奖号码 销售额(元) 中奖注数一等奖 中奖注数二等奖 0 2020/1/16 2020007 05 12 17 20 25 31 10 358035962 38 (津 冀 吉 沪..) 269 1 2020/1/14 2020006 03 04 05 10 16 32 09 361697316 20 (浙 豫 粤 桂..) 363 2 2020/1/12 2020005 11 16 17 22 26 32 04 400642476 8 (冀 皖 赣 鄂..) 224 3 2020/1/9 2020004 02 15 17 27 32 33 03 370826158 7 (晋 浙 鲁 粤..) 189 4 2020/1/7 2020003 09 17 26 29 30 32 03 368960938 16 (苏 浙 鄂 湘..) 134
winning_numbers = win[ '中奖号码' ] . str . split( ' ' , expand= True )
winning_numbers
0 1 2 3 4 5 6 7 8 9 10 11 12 0 05 12 17 20 25 31 10 1 03 04 05 10 16 32 09 2 11 16 17 22 26 32 04 3 02 15 17 27 32 33 03 4 09 17 26 29 30 32 03 ... ... ... ... ... ... ... ... ... ... ... ... ... ... 827 08 10 12 14 18 28 14 828 01 04 19 22 24 25 15 829 06 10 11 28 30 33 12 830 04 21 23 31 32 33 04 831 03 09 15 20 27 29 01
832 rows × 13 columns
number_counts = winning_numbers. apply ( pd. value_counts) . fillna( 0 )
number_counts = number_counts[ [ 0 , 2 , 4 , 6 , 8 , 10 , 12 ] ]
number_counts. set_axis( range ( 1 , len ( number_counts. columns) + 1 ) , axis= 1 , inplace= True )
number_counts. head( )
1 2 3 4 5 6 7 0.0 0.0 0.0 0.0 0.0 0.0 0.0 01 163.0 0.0 0.0 0.0 0.0 0.0 60.0 02 128.0 22.0 0.0 0.0 0.0 0.0 49.0 03 85.0 38.0 3.0 0.0 0.0 0.0 47.0 04 80.0 39.0 10.0 0.0 0.0 0.0 56.0
plt. figure( figsize= ( 10 , 8 ) )
sns. heatmap( number_counts, annot= True , fmt= 'g' , cmap= 'YlGnBu' )
plt. title( ' 双色球中奖号码次数热力图 ' , fontsize= 16 , backgroundcolor= '#cf778f' )
plt. xlabel( '中奖号码位置' , fontsize= 12 )
plt. ylabel( '中奖号码' , fontsize= 12 )
plt. xticks( rotation= 45 )
plt. yticks( rotation= 0 )
plt. tight_layout( )
plt. show( )