若该文为原创文章,转载请注明原文出处。
注:转换测试使用的是Autodl服务器,CUDA11.1版本,py3.8。
一、PP-YOLOE环境安装
创建环境
# 使用 conda 创建一个名为 PaddleYOLO 的环境,并指定 python 版本
conda create -n PaddleYOLO python=3.8激活
conda activate PaddleYOLO安装(参考官网)
# 安装 Paddle,PaddleYOLO 代码库推荐使用 paddlepaddle-2.4.2 以上的版本
# 教程测试使用 conda 安装 gpu 版 paddlepaddle 2.5
python -m pip install paddlepaddle-gpu==2.5.2.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html二、PP-YOLOE+ 模型简单使用
1、获取 PaddleYOLO 源码
# 拉取 PaddleYOLO
git clone https://github.com/PaddlePaddle/PaddleYOLO.git
# 切换到 PaddleYOLO 目录,安装相关依赖库
cd PaddleYOLO
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# install2、模型推理
下載模型
# PP-YOLOE+_s
wget https://bj.bcebos.com/v1/paddledet/models/ppyoloe_plus_crn_s_80e_coco.pdparams
# PP-YOLOE+_m
wget https://bj.bcebos.com/v1/paddledet/models/ppyoloe_plus_crn_m_80e_coco.pdparams使用 tools/infer.py 进行推理:
# 可能需要安装 9.5.0 版本的 Pillow
pip install Pillow==9.5.0推理測試
python tools/infer.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml -o weights=ppyoloe_plus_crn_s_80e_coco.pdparams --infer_img=demo/000000014439_640x640.jpg --draw_threshold=0.5# -c 指定配置文件,configs/目录下的配置文件(测试使用 ppyoloe_plus_crn_s_80e_coco.yml)也可以是自己添加的,
# -o 或者 --opt 设置配置选项,这里设置了 weights 使用前面手动下载的权重,也可以直接设置
weights=https://bj.bcebos.com/v1/paddledet/models/ppyoloe_plus_crn_s_80e_coco.pdparams
# --infer_dir 指定推理的图片路径或者文件夹,--draw_threshold 画框的阈值,默认 0.5,
图像尺寸是 640*640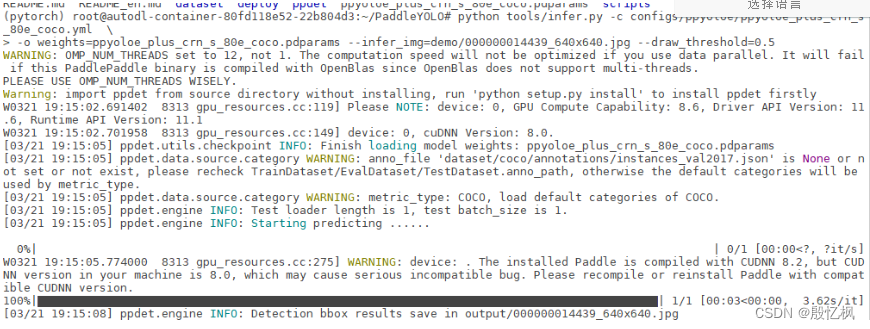

推理正常
三、Train
1、数据集下载
# 数据集很大,有18G
http://images.cocodataset.org/zips/train2017.zip2、train
config=configs/${model_name}/${job_name}.yml
python tools/train.py -c ${config} --eval --amp根据readme提供的train方法
执行下面命令
python tools/train.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml --eval --amp这里没有重新train,直接使用官方模型
四、板卡部署模型
1、针对 RKNN 优化
为了在 RKNPU 上获得更优的推理性能,我们调整了模型的输出结构,这些调整会影响到后处理
的逻辑,主要包含以下内容
• DFL 结构被移至后处理
• 新增额外输出,该输出为所有类别分数的累加,用于加速后处理的候选框过滤逻辑
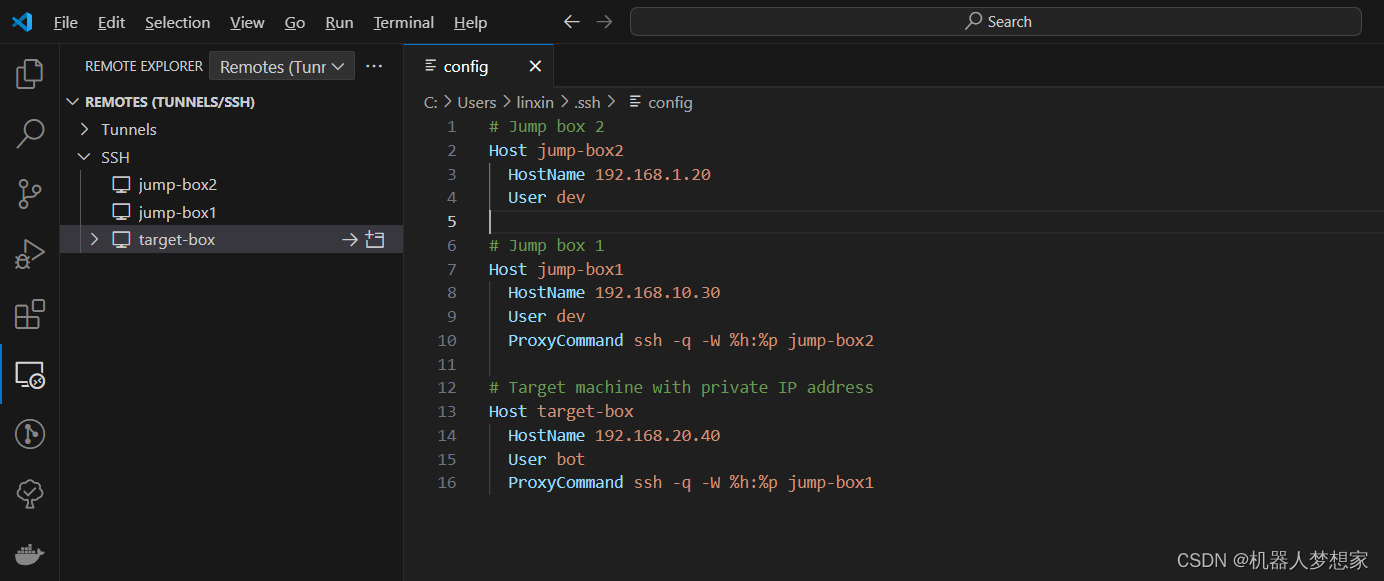
具体请参考 rknn_model_zoo 。我们在前面拉取的 PaddleDetection 源码或者 PaddleYOLO 源码基础上,简单修改下源码(版本是release/2.6)
使用的版本是:
https://github.com/PaddlePaddle/PaddleYOLO/tree/release/2.6
下载后解压
cd PaddleYOLO-release-2.6列表 1: ppdet/modeling/architectures/yolo.py
if self.training:
yolo_losses = self.yolo_head(neck_feats, self.inputs)
return yolo_losses
else:
yolo_head_outs = self.yolo_head(neck_feats)
+ return yolo_head_outs
列表 2: ppdet/modeling/heads/ppyoloe_head.py
+ rk_out_list = []
for i, feat in enumerate(feats):
_, _, h, w = feat.shape
l = h * w
avg_feat = F.adaptive_avg_pool2d(feat, (1, 1))
cls_logit = self.pred_cls[i](self.stem_cls[i](feat, avg_feat)
reg_dist = self.pred_reg[i](self.stem_reg[i](feat, avg_feat))
+ rk_out_list.append(reg_dist)
+ rk_out_list.append(F.sigmoid(cls_logit))
+ rk_out_list.append(paddle.clip(rk_out_list[-1].sum(1, keepdim=True), 0, 1))
reg_dist = reg_dist.reshape(
[-1, 4, self.reg_channels, l]).transpose([0, 2, 3, 1])
if self.use_shared_conv:
reg_dist = self.proj_conv(F.softmax(
reg_dist, axis=1)).squeeze(1)
else:
reg_dist = F.softmax(reg_dist, axis=1)
# cls and reg
cls_score = F.sigmoid(cls_logit)
cls_score_list.append(cls_score.reshape([-1, self.num_classes,1]))
reg_dist_list.append(reg_dist)
+ return rk_out_list 上面简单的修改只用于模型导出,训练模型时请注释掉,(上面版本是2.6不要弄错)源码修改也可以直接打补丁(源码版本是 release/2.5),具体参考下 rknn_model_zoo/models/CV/object_detection/yolo/patch_for_model_export/ppyoloe at v1.5.0 · airockchip/rknn_model_zoo (github.com)
上面简单的修改只用于模型导出,训练模型时请注释掉,(上面版本是2.6不要弄错)源码修改也可以直接打补丁(源码版本是 release/2.5),具体参考下 rknn_model_zoo/models/CV/object_detection/yolo/patch_for_model_export/ppyoloe at v1.5.0 · airockchip/rknn_model_zoo (github.com)
2、导出 ONNX 模型
# 切换到 PaddleDetection 或者 PaddleYOLO 源码目录下,然后使用 tools/export_model.py 导出 paddle 模型
cd PaddleDetectionpython tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_s_80e_coco.yml -o weights=ppyoloe_plus_crn_s_80e_coco.pdparams exclude_nms=True exclude_post_process=True --output_dir inference_model# 其中 -c 是设置配置文件,configs/目录下的配置文件
# --output_dir 指定模型保存目录,默认是 output_inference
# -o 或者 --opt 设置配置选项,这里设置了 weights 使用前面手动下载的权重等等
 模型保存在 inference_model/ppyoloe_plus_crn_s_80e_coco 目录下:
模型保存在 inference_model/ppyoloe_plus_crn_s_80e_coco 目录下:
ppyoloe_plus_crn_s_80e_coco ├── infer_cfg.yml # 模型配置文件信息 ├── model.pdiparams # 静态图模型参数 ├── model.pdiparams.info # 参数额外信息,一般无需关注 └── model.pdmodel # 静态图模型文件
然后将 paddle 模型转换成 ONNX 模型:
pip install paddle2onnx# 转换模型
paddle2onnx --model_dir inference_model/ppyoloe_plus_crn_s_80e_coco --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file ./inference_model/ppyoloe_plus_crn_s_80e_coco/ppyoloe_plus_crn_s_80e_coco.onnx# 固定模型 shape
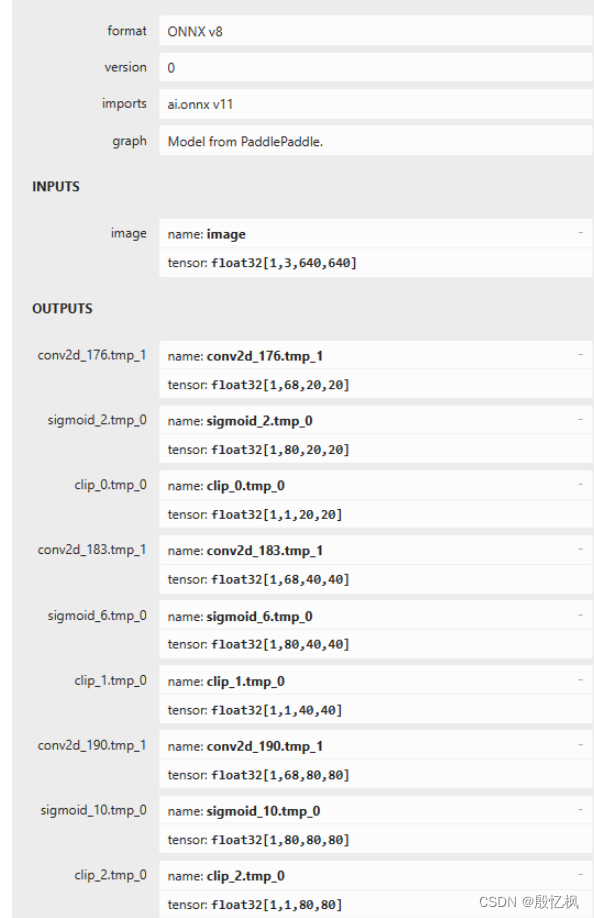
python -m paddle2onnx.optimize --input_model inference_model/ppyoloe_plus_crn_s_80e_coco/ppyoloe_plus_crn_s_80e_coco.onnx --output_model inference_model/ppyoloe_plus_crn_s_80e_coco/ppyoloe_plus_crn_s_80e_coco.onnx --input_shape_dict "{'image':[1,3,640,640]}" 使用 Netron 查看下导出的ppyoloe_plus_crn_s_80e_coco.onnx模型的输出和输出:
使用 Netron 查看下导出的ppyoloe_plus_crn_s_80e_coco.onnx模型的输出和输出:
3、导出RKNN模型
使用 rknn-Toolkit2 工具,将onnx 转换为 rknn模型,并进行推理测试(参考配套例程):
代码参考rknn_model_zoo程序。
import os
import cv2
import sys
import numpy as np
from copy import copy
from rknn.api import RKNN
# model,image path
ONNX_MODEL = './ppyoloe_plus_crn_s_80e_coco.onnx'
RKNN_MODEL = 'ppyoloe_plus_crn_s_80e_coco.rknn'
IMG_PATH = './test.jpg'
#IMG_PATH = './000000087038.jpg'
DATASET = './dataset.txt'
QUANTIZE_ON = True
OBJ_THRESH = 0.5
NMS_THRESH = 0.45
# OBJ_THRESH = 0.001
# NMS_THRESH = 0.65
IMG_SIZE = (640, 640) # (width, height)
CLASSES = ("person", "bicycle", "car","motorbike ","aeroplane ","bus ","train","truck ","boat","traffic light",
"fire hydrant","stop sign ","parking meter","bench","bird","cat","dog ","horse ","sheep","cow","elephant",
"bear","zebra ","giraffe","backpack","umbrella","handbag","tie","suitcase","frisbee","skis","snowboard","sports ball","kite",
"baseball bat","baseball glove","skateboard","surfboard","tennis racket","bottle","wine glass","cup","fork","knife ",
"spoon","bowl","banana","apple","sandwich","orange","broccoli","carrot","hot dog","pizza ","donut","cake","chair","sofa",
"pottedplant","bed","diningtable","toilet ","tvmonitor","laptop ","mouse ","remote ","keyboard ","cell phone","microwave ",
"oven ","toaster","sink","refrigerator ","book","clock","vase","scissors ","teddy bear ","hair drier", "toothbrush ")
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with object threshold.
"""
box_confidences = box_confidences.reshape(-1)
class_max_score = np.max(box_class_probs, axis=-1)
classes = np.argmax(box_class_probs, axis=-1)
_class_pos = np.where(class_max_score* box_confidences >= OBJ_THRESH)
scores = (class_max_score* box_confidences)[_class_pos]
boxes = boxes[_class_pos]
classes = classes[_class_pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def dfl(position):
# Distribution Focal Loss (DFL)
import torch
x = torch.tensor(position)
n,c,h,w = x.shape
p_num = 4
mc = c//p_num
y = x.reshape(n,p_num,mc,h,w)
y = y.softmax(2)
acc_metrix = torch.tensor(range(mc)).float().reshape(1,1,mc,1,1)
y = (y*acc_metrix).sum(2)
return y.numpy()
def box_process(position):
grid_h, grid_w = position.shape[2:4]
col, row = np.meshgrid(np.arange(0, grid_w), np.arange(0, grid_h))
col = col.reshape(1, 1, grid_h, grid_w)
row = row.reshape(1, 1, grid_h, grid_w)
grid = np.concatenate((col, row), axis=1)
stride = np.array([IMG_SIZE[1]//grid_h, IMG_SIZE[0]//grid_w]).reshape(1,2,1,1)
position = dfl(position)
box_xy = grid +0.5 -position[:,0:2,:,:]
box_xy2 = grid +0.5 +position[:,2:4,:,:]
xyxy = np.concatenate((box_xy*stride, box_xy2*stride), axis=1)
return xyxy
def post_process(input_data):
boxes, scores, classes_conf = [], [], []
defualt_branch=3
pair_per_branch = len(input_data)//defualt_branch
# Python 忽略 score_sum 输出
for i in range(defualt_branch):
boxes.append(box_process(input_data[pair_per_branch*i]))
classes_conf.append(input_data[pair_per_branch*i+1])
scores.append(np.ones_like(input_data[pair_per_branch*i+1][:,:1,:,:], dtype=np.float32))
def sp_flatten(_in):
ch = _in.shape[1]
_in = _in.transpose(0,2,3,1)
return _in.reshape(-1, ch)
boxes = [sp_flatten(_v) for _v in boxes]
classes_conf = [sp_flatten(_v) for _v in classes_conf]
scores = [sp_flatten(_v) for _v in scores]
boxes = np.concatenate(boxes)
classes_conf = np.concatenate(classes_conf)
scores = np.concatenate(scores)
# filter according to threshold
boxes, classes, scores = filter_boxes(boxes, scores, classes_conf)
# nms
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
if len(keep) != 0:
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
def draw(image, boxes, scores, classes):
for box, score, cl in zip(boxes, scores, classes):
top, left, right, bottom = [int(_b) for _b in box]
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(top, left, right, bottom))
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 2)
cv2.putText(image, '{:.2f}'.format(score),
(top, left - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
def letter_box(im, new_shape, color=(0, 0, 0)):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
def get_real_box(src_shape, box, dw, dh, ratio):
bbox = copy(box)
# unletter_box result
bbox[:,0] -= dw
bbox[:,0] /= ratio
bbox[:,0] = np.clip(bbox[:,0], 0, src_shape[1])
bbox[:,1] -= dh
bbox[:,1] /= ratio
bbox[:,1] = np.clip(bbox[:,1], 0, src_shape[0])
bbox[:,2] -= dw
bbox[:,2] /= ratio
bbox[:,2] = np.clip(bbox[:,2], 0, src_shape[1])
bbox[:,3] -= dh
bbox[:,3] /= ratio
bbox[:,3] = np.clip(bbox[:,3], 0, src_shape[0])
return bbox
if __name__ == '__main__':
# Create RKNN object
#rknn = RKNN(verbose=True)
rknn = RKNN()
# pre-process config,target_platform='rk3588'
print('--> Config model')
rknn.config(mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], target_platform='rk3588')
print('done')
# Load ONNX model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL)
if ret != 0:
print('Load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET)
if ret != 0:
print('Build model failed!')
exit(ret)
print('done')
# Export RKNN model
print('--> Export rknn model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export rknn model failed!')
exit(ret)
print('done')
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
# ret = rknn.init_runtime('rk3566')
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
# Set inputs
img_src = cv2.imread(IMG_PATH)
src_shape = img_src.shape[:2]
img, ratio, (dw, dh) = letter_box(img_src, IMG_SIZE)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
#img = cv2.resize(img_src, IMG_SIZE)
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[img])
print('done')
# post process
boxes, classes, scores = post_process(outputs)
img_p = img_src.copy()
if boxes is not None:
draw(img_p, get_real_box(src_shape, boxes, dw, dh, ratio), scores, classes)
cv2.imwrite("result.jpg", img_p)五、部署测试
rknn_model_zoo测试前面有提及,这里不在复现。自行测试。
六、参考连接
GitHub - PaddlePaddle/PaddleYOLO: 🚀🚀🚀 YOLO series of PaddlePaddle implementation, PP-YOLOE+, RT-DETR, YOLOv5, YOLOv6, YOLOv7, YOLOv8, YOLOX, YOLOv5u, YOLOv7u, YOLOv6Lite, RTMDet and so on. 🚀🚀🚀
https://github.com/airockchip/rknn_model_zoo/tree/main/models/CV/object_detection/yolo/
注意:rknn_model_zoo使用的是PaddleDetection版本2.5,这里使用的是PaddleYOLO版本2.6.
如有侵权,或需要完整代码,请及时联系博主。
![[flask]flask的路由](https://img-blog.csdnimg.cn/direct/dd07fed1a33e4978b668a5091bd6213d.png)