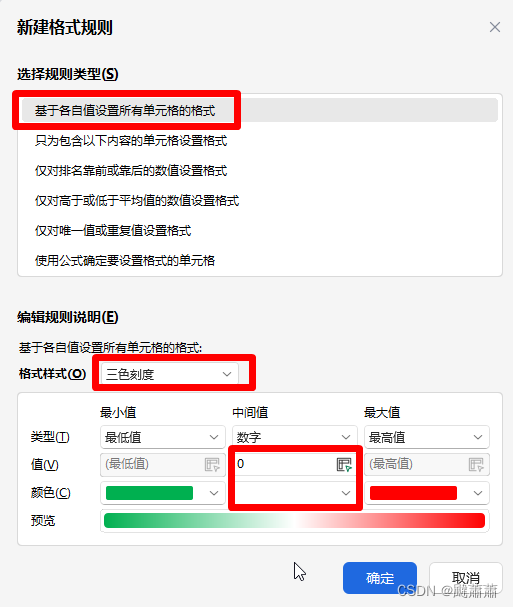
DBSCAN(基于密度的空间聚类应用噪声)是数据挖掘和机器学习中一个流行的聚类算法。与K-Means这样的划分方法不同,DBSCAN特别擅长于识别数据集中各种形状和大小的聚类,包括存在噪声和离群点的情况。
以下是DBSCAN工作原理的概述:
1. 核心概念:
- Epsilon (ε):距离参数,指定点周围邻域的半径。
- 最小点数 (MinPts):形成密集区域所需的最小点数,这将被视为一个聚类。
2. 过程:
- 算法从数据集中随机选择一个点开始。然后,它识别所有在ε距离内的点,形成一个邻域。
- 如果一个点的ε-邻域包含至少MinPts,这个点被标记为**核心点**。如果不是,但它位于一个核心点的ε-邻域内,它被标记为**边界点**。否则,它被认为是**噪声**。
- 接下来,对于每个核心点,如果它尚未被分配到一个聚类中,就创建一个新的聚类。然后,所有在其ε-邻域内的点都被添加到这个聚类中。这一步骤被递归地应用于新形成聚类中的所有点。
- 这个过程重复进行,直到所有点要么被分配到一个聚类中,要么被标记为噪声。
3. 优点:
- 形状和大小的灵活性:DBSCAN可以找到各种形状和大小的聚类,与假设聚类是球形的K-Means不同。
- 处理噪声:它能有效地识别和分离噪声或离群点。
- 最小输入参数:只需要两个参数(ε和MinPts),尽管选择它们的值有时可能是个挑战。
4. 缺点:
- 参数敏感性:DBSCAN的结果对于ε和MinPts的选择非常敏感。这些参数的不当选择可能导致过度聚类或欠聚类。
- 高维数据:DBSCAN在处理高维数据时可能会遇到困难,因为维度的诅咒影响了距离度量。
DBSCAN因其在处理复杂数据结构和噪声方面的鲁棒性而被广泛应用于各种应用中,包括异常检测、地理空间数据分析和生物信息学。
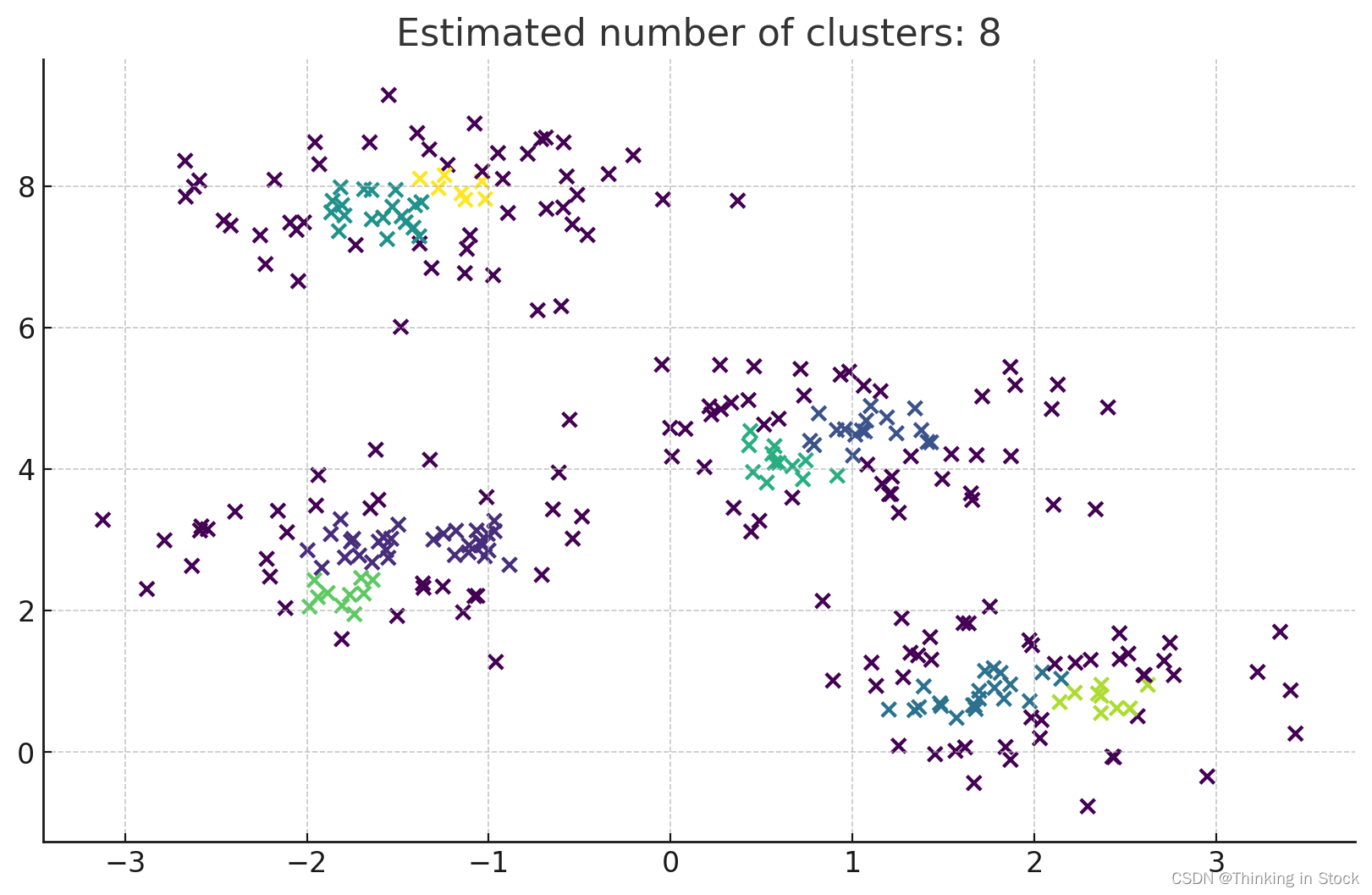
要在Python中实现DBSCAN聚类算法,可以使用scikit-learn库中的sklearn.cluster模块中的DBSCAN类。以下是一个示例代码片段,演示了如何在样本数据集上使用DBSCAN。
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成一个样本数据集
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 应用DBSCAN
# eps:两个样本被认为是邻居的最大距离。
# min_samples:一个点被认为是核心点的邻域中的样本数量。
dbscan = DBSCAN(eps=0.3, min_samples=10).fit(X)
# 获取聚类标签
labels = dbscan.labels_
# 标签中的聚类数量,如果存在噪声则忽略。
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
# 绘制聚类
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.title(f'估计的聚类数量:{n_clusters_}')
plt.show()
这段代码执行以下操作:
- 使用
make_blobs生成了一个包含300个样本、分为4个中心的样本数据集。 - 使用
eps值为0.3和min_samples为10的DBSCAN算法应用于这个数据集。这些参数可能需要根据您的具体数据集进行调整,以获得最佳的聚类结果。 - 提取聚类标签并计算聚类数量。
- 使用Matplotlib绘制聚类,每个聚类用不同颜色表示。
记住,选择正确的eps和min_samples值对于DBSCAN在数据集上的成功至关重要。可能需要实验这些参数,以找到适合特定情况的最佳值。