1.需求
市面上常见的工作流组件一般都是前端通过拖拉拽配置流程图,后端流程引擎解析流程配置,这里我们手写一个简单的流程引擎,先实现串行流程,例如下:

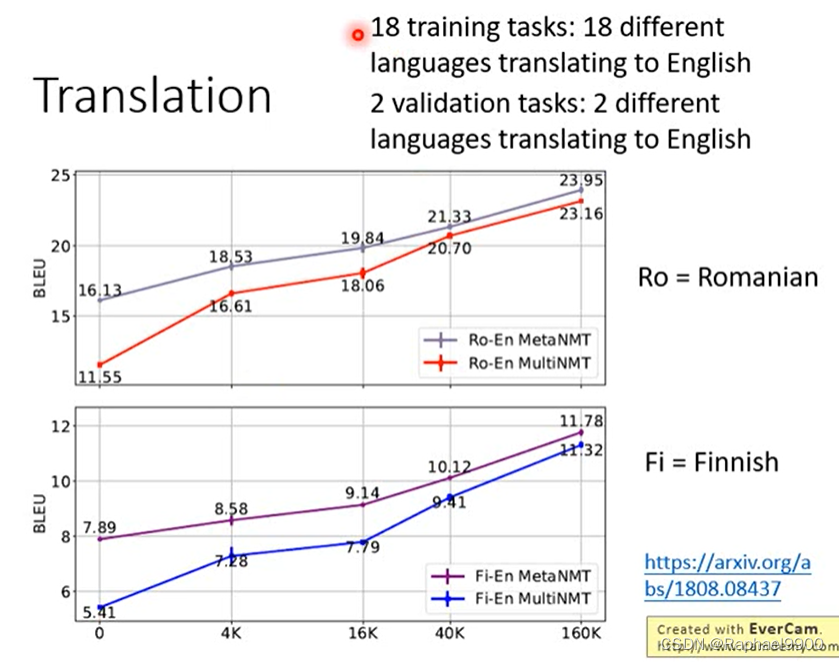
小明提交了一个申请单,然后经过经理审批,审批结束后,不管通过还是不通过,都会经过第三步把结果发送给小明
2.难点分析
- 每个节点审批时间是不确定的,工作流引擎主动式调取下一个节点的逻辑并不适合当前场景
- 节点类型不是固定的后续会增多,工作流引擎与节点类型判断的逻辑不能写死
- 审批时需要传递一些基本信息,如审批人、审批时间等,这些信息如何传递
3.设计
- 采用注册机制,把节点类型及其自有逻辑注册进工作流引擎,以便能够扩展更多节点,使得工作流引擎与节点解耦
- 工作流引擎增加被动式驱动逻辑,使得能够通过外部来使工作流引擎执行下一个节点
- 增加上下文语义,作为全局变量来使用,使得数据能够流经各个节点
4.实现
流程的表示
流程配置好后一般会生成xml或者json格式的文件,这里我们使用xml表示流程
<definitions>
<process id="process_2" name="简单审批例子">
<startEvent id="startEvent_1">
<outgoing>flow_1</outgoing>
</startEvent>
<sequenceFlow id="flow_1" sourceRef="startEvent_1" targetRef="approvalApply_1" />
<approvalApply id="approvalApply_1" name="提交申请单">
<incoming>flow_1</incoming>
<outgoing>flow_2</outgoing>
</approvalApply>
<sequenceFlow id="flow_2" sourceRef="approvalApply_1" targetRef="approval_1" />
<approval id="approval_1" name="审批">
<incoming>flow_2</incoming>
<outgoing>flow_3</outgoing>
</approval>
<sequenceFlow id="flow_3" sourceRef="approval_1" targetRef="notify_1"/>
<notify id="notify_1" name="结果邮件通知">
<incoming>flow_3</incoming>
<outgoing>flow_4</outgoing>
</notify>
<sequenceFlow id="flow_4" sourceRef="notify_1" targetRef="endEvent_1"/>
<endEvent id="endEvent_1">
<incoming>flow_4</incoming>
</endEvent>
</process>
</definitions>
- process表示一个流程
- startEvent表示开始节点,endEvent表示结束节点
- approvalApply、approval、notify分别表示提交申请单、审批、邮件通知节点
- sequenceFlow表示连线,从sourceRef开始,指向targetRef,例如:flow_3,表示一 从printProcessEngine_1到endEvent_1的连线。
节点的表示
outgoing表示出边,即节点执行完毕后,应该从那个边出去。
incoming表示入边,即从哪个边进入到本节点。
一个节点只有outgoing而没有incoming,如:startEvent;也可以 只有入边而没有出边,如:endEvent;也可以既有入边也有出边,如:approvalApply、approval、notify。
流程引擎的逻辑
基于上述XML,流程引擎的运行逻辑如下
- 找到process
- 找到开始节点(startEvent)
- 找到startEvent的outgoing边(sequenceFlow)
- 找到该边(sequenceFlow)指向的节点(targetRef=approvalApply_1)
- 执行approvalApply_1节点自身的逻辑
- 找到该节点的outgoing边(sequenceFlow)重复3-5,直到遇到结束节点(endEvent),流程结束
上代码
定义流程
public class PeProcess {
private String id;
public PeNode start;
public PeProcess(String id, PeNode start) {
this.id = id;
this.start = start;
}
public PeNode peNodeWithID(String peNodeID) {
PeNode node = this.start.out.to;
this.start = this.start.out.to;
return node;
}
}
定义节点
public class PeNode {
public String id;
public String type;
public PeEdge in;
public PeEdge out;
public PeNode(String id) {
this.id = id;
}
}
定义边
public class PeEdge {
private String id;
public PeNode from;
public PeNode to;
public PeEdge(String id) {
this.id = id;
}
}
接下来,构建流程图,代码如下:
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import java.util.HashMap;
import java.util.Map;
public class XmlPeProcessBuilder {
private String xmlStr;
private final Map<String, PeNode> id2PeNode = new HashMap<>();
private final Map<String, PeEdge> id2PeEdge = new HashMap<>();
public XmlPeProcessBuilder(String xmlStr) {
this.xmlStr = xmlStr;
}
public PeProcess build() throws Exception {
//strToNode : 把一段xml转换为org.w3c.dom.Node
Node definations = XmlUtil.strToNode(xmlStr);
//childByName : 找到definations子节点中nodeName为process的那个Node
Node process = XmlUtil.childByName(definations, "process");
NodeList childNodes = process.getChildNodes();
for (int j = 0; j < childNodes.getLength(); j++) {
Node node = childNodes.item(j);
//#text node should be skip
if (node.getNodeType() == Node.TEXT_NODE) continue;
if ("sequenceFlow".equals(node.getNodeName()))
buildPeEdge(node);
else
buildPeNode(node);
}
Map.Entry<String, PeNode> startEventEntry = id2PeNode.entrySet().stream().filter(entry -> "startEvent".equals(entry.getValue().type)).findFirst().get();
return new PeProcess(startEventEntry.getKey(), startEventEntry.getValue());
}
private void buildPeEdge(Node node) {
//attributeValue : 找到node节点上属性为id的值
PeEdge peEdge = id2PeEdge.computeIfAbsent(XmlUtil.attributeValue(node, "id"), id -> new PeEdge(id));
peEdge.from = id2PeNode.computeIfAbsent(XmlUtil.attributeValue(node, "sourceRef"), id -> new PeNode(id));
peEdge.to = id2PeNode.computeIfAbsent(XmlUtil.attributeValue(node, "targetRef"), id -> new PeNode(id));
}
private void buildPeNode(Node node) {
PeNode peNode = id2PeNode.computeIfAbsent(XmlUtil.attributeValue(node, "id"), id -> new PeNode(id));
peNode.type = node.getNodeName();
Node inPeEdgeNode = XmlUtil.childByName(node, "incoming");
if (inPeEdgeNode != null)
//text : 得到inPeEdgeNode的nodeValue
peNode.in = id2PeEdge.computeIfAbsent(XmlUtil.text(inPeEdgeNode), id -> new PeEdge(id));
Node outPeEdgeNode = XmlUtil.childByName(node, "outgoing");
if (outPeEdgeNode != null)
peNode.out = id2PeEdge.computeIfAbsent(XmlUtil.text(outPeEdgeNode), id -> new PeEdge(id));
}
}
定义上下文对象类,用于传递变量的,定义如下:
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class PeContext {
private Map<String, Object> info = new ConcurrentHashMap<>();
public Object getValue(String key) {
return info.get(key);
}
public void putValue(String key, Object value) {
info.put(key, value);
}
}
每个节点的处理逻辑是不一样的,此处应该进行一定的抽象,为了强调流程中节点的作用是逻辑处理,引入了一种新的类型–算子(Operator),定义如下:
/**
* 算子类:抽象每个节点的处理逻辑
*/
public interface IOperator {
//引擎可以据此来找到本算子
String getType();
//引擎调度本算子
void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext);
}
对于引擎来讲,当遇到一个节点时,需要调度之,但怎么调度呢?首先需要各个节点算子注册(registNodeProcessor())进来,这样才能找到要调度的那个算子。
其次,引擎怎么知道节点算子自有逻辑处理完了呢?一般来讲,引擎是不知道的,只能是由算子告诉引擎,所以引擎要提供一个功能(nodeFinished()),这个功能由算子调用。
最后,把算子任务的调度和引擎的驱动解耦开来,放入不同的线程中。
流程引擎的实现代码如下
import java.util.Map;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.LinkedBlockingQueue;
public class ProcessEngine {
private String xmlStr;
//存储算子
private Map<String, IOperator> type2Operator = new ConcurrentHashMap<>();
private PeProcess peProcess = null;
private PeContext peContext = null;
//任务数据暂存
public final BlockingQueue<PeNode> arrayBlockingQueue = new LinkedBlockingQueue();
//任务调度线程
public final Thread dispatchThread = new Thread(() -> {
while (true) {
try {
PeNode node = arrayBlockingQueue.take();
type2Operator.get(node.type).doTask(this, node, peContext);
} catch (Exception e) {
e.printStackTrace();
}
}
});
public ProcessEngine(String xmlStr) {
this.xmlStr = xmlStr;
}
//算子注册到引擎中,便于引擎调用之
public void registNodeProcessor(IOperator operator) {
type2Operator.put(operator.getType(), operator);
}
public void start() throws Exception {
peProcess = new XmlPeProcessBuilder(xmlStr).build();
peContext = new PeContext();
dispatchThread.setDaemon(true);
dispatchThread.start();
executeNode(peProcess.start.out.to);
}
private void executeNode(PeNode node) {
if (!node.type.equals("endEvent"))
arrayBlockingQueue.add(node);
else
System.out.println("process finished!");
}
public void nodeFinished(String peNodeID) {
PeNode node = peProcess.peNodeWithID(peNodeID);
executeNode(node.out.to);
}
}
接下来,简单(简陋)实现本示例所需的三个算子,代码如下
/**
* 提交申请单
*/
public class OperatorOfApprovalApply implements IOperator {
@Override
public String getType() {
return "approvalApply";
}
@Override
public void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext) {
peContext.putValue("form", "formInfo");
peContext.putValue("applicant", "小明");
processEngine.nodeFinished(node.id);
}
}
/**
* 审批
*/
public class OperatorOfApproval implements IOperator {
@Override
public String getType() {
return "approval";
}
@Override
public void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext) {
peContext.putValue("approver", "经理");
peContext.putValue("message", "审批通过");
processEngine.nodeFinished(node.id);
}
}
/**
* 结果邮件通知
*/
public class OperatorOfNotify implements IOperator {
@Override
public String getType() {
return "notify";
}
@Override
public void doTask(ProcessEngine processEngine, PeNode node, PeContext peContext) {
System.out.println(String.format("%s 提交的申请单 %s 被 %s 审批,结果为 %s",
peContext.getValue("applicant"),
peContext.getValue("form"),
peContext.getValue("approver"),
peContext.getValue("message")));
processEngine.nodeFinished(node.id);
}
另附工具类 XmlUtil.java和DomUtils.java代码
XmlUtil.java
import com.sun.org.apache.xerces.internal.dom.DeferredDocumentImpl;
import com.sun.org.apache.xerces.internal.dom.DeferredElementNSImpl;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import java.io.FileNotFoundException;
import java.util.ArrayList;
import java.util.List;
public class XmlUtil {
/**
* 将 xml文件转字符串
* @param filepath
* @return
* @throws Exception
*/
public static String XmlToString(String filepath) throws Exception {
Document document = com.example.demo.enginer.v2.DomUtils.xml2Doc(filepath);
String doc2FormatString = com.example.demo.enginer.v2.DomUtils.doc2FormatString(document);
return doc2FormatString;
}
/**
* 找到node节点上属性为id的值
*
* @param node
* @param attr
* @return
*/
public static String attributeValue(Node node, String attr) {
NamedNodeMap attributes = node.getAttributes();
return attributes.getNamedItem(attr).getNodeValue();
}
/**
* 找到definations子节点中nodeName为process的那个Node
*
* @param node
* @param incoming
* @return
*/
public static Node childByName(Node node, String incoming) {
Node ret = null;
NodeList childNodes = null;
if (node instanceof DeferredElementNSImpl) {
childNodes = ((DeferredElementNSImpl) node).getElementsByTagName(incoming);
} else if (node instanceof DeferredDocumentImpl) {
childNodes = ((DeferredDocumentImpl) node).getElementsByTagName(incoming);
}
ret = childNodes.item(0);;
return ret;
}
/**
* 得到inPeEdgeNode的nodeValue
*
* @param inPeEdgeNode
* @return
*/
public static String text(Node inPeEdgeNode) {
NodeList childNodes = inPeEdgeNode.getChildNodes();
String value = childNodes.item(0).getNodeValue();
return value;
}
/**
* 把一段xml转换为org.w3c.dom.Node
*
* @param xmlStr
* @return
*/
public static Node strToNode(String xmlStr) throws FileNotFoundException {
Document document = DomUtils.parseXMLDocument(xmlStr);
return document;
}
public static String childTextByName(Node xmlNode, String expr) {
String str = null;
NodeList childNodes = xmlNode.getChildNodes();
for(int i = 0 ; i < childNodes.getLength(); i++){
Node item = childNodes.item(i);
if(expr.equals(item.getNodeName())){
str = item.getTextContent();
break;
}
}
return str;
}
public static List<Node> childsByName(Node node, String incoming) {
List<Node> ret = new ArrayList<>();
NodeList childNodes = null;
if (node instanceof DeferredElementNSImpl) {
childNodes = ((DeferredElementNSImpl) node).getElementsByTagName(incoming);
} else if (node instanceof DeferredDocumentImpl) {
childNodes = ((DeferredDocumentImpl) node).getElementsByTagName(incoming);
}
for(int i=0 ; i<childNodes.getLength();i++){
ret.add(childNodes.item(i));
}
return ret;
}
}
DomUtils.java
import com.sun.org.apache.xml.internal.serialize.OutputFormat;
import com.sun.org.apache.xml.internal.serialize.XMLSerializer;
import org.w3c.dom.Document;
import org.w3c.dom.DocumentType;
import org.w3c.dom.Node;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.*;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import java.io.*;
import java.util.Properties;
public class DomUtils {
/**
* 将给定文件的内容或者给定 URI 的内容解析为一个 XML 文档,并且返回一个新的 DOM Document 对象
*
* @param filePath 文件所在路径
* @return DOM的Document对象
* @throws Exception
*/
public static Document xml2Doc(String filePath) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = null;
FileInputStream inputStream = null;
Document doc = null;
try {
builder = factory.newDocumentBuilder();
/* 通过文件方式读取,注意文件保存的编码和文件的声明编码要一致(默认文件声明是UTF-8) */
File file = new File(filePath);
doc = builder.parse(file);
/* 通过一个URL方式读取 */
// URI uri = new URI(filePath);//filePath="http://java.sun.com/index.html"
// doc = builder.parse(uri.toString());
/* 通过java IO 流的读取 */
// inputStream = new FileInputStream(filePath);
// doc = builder.parse(inputStream);
return doc;
} catch (Exception e) {
return null;
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
return null;
}
}
}
}
/**
* Document 转换为 String 并且进行了格式化缩进
*
* @param doc XML的Document对象
* @return String
*/
public static String doc2FormatString(Document doc) {
StringWriter stringWriter = null;
try {
stringWriter = new StringWriter();
if(doc != null){
OutputFormat format = new OutputFormat(doc,"UTF-8",true);
format.setIndenting(true);//设置是否缩进,默认为true
format.setIndent(4);//设置缩进字符数
format.setPreserveSpace(false);//设置是否保持原来的格式,默认为 false
format.setLineWidth(500);//设置行宽度
XMLSerializer serializer = new XMLSerializer(stringWriter,format);
serializer.asDOMSerializer();
serializer.serialize(doc);
return stringWriter.toString();
} else {
return null;
}
} catch (Exception e) {
return null;
} finally {
if(stringWriter != null){
try {
stringWriter.close();
} catch (IOException e) {
return null;
}
}
}
}
/**
* Document 转换为 String
*
* @param doc XML的Document对象
* @return String
*/
public static String doc2String(Document doc){
try {
Source source = new DOMSource(doc);
StringWriter stringWriter = new StringWriter();
Result result = new StreamResult(stringWriter);
TransformerFactory factory = TransformerFactory.newInstance();
Transformer transformer = factory.newTransformer();
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
transformer.transform(source, result);
return stringWriter.getBuffer().toString();
} catch (Exception e) {
return null;
}
}
/**
* String 转换为 Document 对象
*
* @param xml 字符串
* @return Document 对象
*/
public static Document string2Doc(String xml) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = null;
Document doc = null;
InputSource source = null;
StringReader reader = null;
try {
builder = factory.newDocumentBuilder();
reader = new StringReader(xml);
source = new InputSource(reader);//使用字符流创建新的输入源
doc = builder.parse(source);
return doc;
} catch (Exception e) {
return null;
} finally {
if(reader != null){
reader.close();
}
}
}
/**
* Document 保存为 XML 文件
*
* @param doc Document对象
* @param path 文件路径
*/
public static void doc2XML(Document doc, String path) {
try {
Source source = new DOMSource(doc);
Result result = new StreamResult(new File(path));
Transformer transformer = TransformerFactory.newInstance().newTransformer();
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
transformer.transform(source, result);
} catch (Exception e) {
return;
}
}
public static String XmlToString(String filepath) throws Exception {
Document document = xml2Doc(filepath);
String doc2FormatString = doc2FormatString(document);
System.out.println(doc2FormatString);
return doc2FormatString;
}
/**
* 初始化一个空Document对象返回。
*
* @return a Document
*/
public static Document newXMLDocument() {
try {
return newDocumentBuilder().newDocument();
} catch (ParserConfigurationException e) {
throw new RuntimeException(e.getMessage());
}
}
/**
* 初始化一个DocumentBuilder
*
* @return a DocumentBuilder
* @throws ParserConfigurationException
*/
public static DocumentBuilder newDocumentBuilder()
throws ParserConfigurationException {
return newDocumentBuilderFactory().newDocumentBuilder();
}
/**
* 初始化一个DocumentBuilderFactory
*
* @return a DocumentBuilderFactory
*/
public static DocumentBuilderFactory newDocumentBuilderFactory() {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
dbf.setNamespaceAware(true);
return dbf;
}
/**
* 将传入的一个XML String转换成一个org.w3c.dom.Document对象返回。
*
* @param xmlString
* 一个符合XML规范的字符串表达。
* @return a Document
*/
public static Document parseXMLDocument(String xmlString) {
if (xmlString == null) {
throw new IllegalArgumentException();
}
try {
return newDocumentBuilder().parse(
new InputSource(new StringReader(xmlString)));
} catch (Exception e) {
throw new RuntimeException(e.getMessage());
}
}
/**
* 给定一个输入流,解析为一个org.w3c.dom.Document对象返回。
*
* @param input
* @return a org.w3c.dom.Document
*/
public static Document parseXMLDocument(InputStream input) {
if (input == null) {
throw new IllegalArgumentException("参数为null!");
}
try {
return newDocumentBuilder().parse(input);
} catch (Exception e) {
throw new RuntimeException(e.getMessage());
}
}
/**
* 给定一个文件名,获取该文件并解析为一个org.w3c.dom.Document对象返回。
*
* @param fileName
* 待解析文件的文件名
* @return a org.w3c.dom.Document
*/
public static Document loadXMLDocumentFromFile(String fileName) {
if (fileName == null) {
throw new IllegalArgumentException("未指定文件名及其物理路径!");
}
try {
return newDocumentBuilder().parse(new File(fileName));
} catch (SAXException e) {
throw new IllegalArgumentException("目标文件(" + fileName
+ ")不能被正确解析为XML!" + e.getMessage());
} catch (IOException e) {
throw new IllegalArgumentException("不能获取目标文件(" + fileName + ")!"
+ e.getMessage());
} catch (ParserConfigurationException e) {
throw new RuntimeException(e.getMessage());
}
}
/*
* 把dom文件转换为xml字符串
*/
public static String toStringFromDoc(Document document) {
String result = null;
if (document != null) {
StringWriter strWtr = new StringWriter();
StreamResult strResult = new StreamResult(strWtr);
TransformerFactory tfac = TransformerFactory.newInstance();
try {
Transformer t = tfac.newTransformer();
t.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
t.setOutputProperty(OutputKeys.INDENT, "yes");
t.setOutputProperty(OutputKeys.METHOD, "xml"); // xml, html,
// text
t.setOutputProperty(
"{http://xml.apache.org/xslt}indent-amount", "4");
t.transform(new DOMSource(document.getDocumentElement()),
strResult);
} catch (Exception e) {
System.err.println("XML.toString(Document): " + e);
}
result = strResult.getWriter().toString();
try {
strWtr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return result;
}
public static String toStringFromDoc1(Document document) {
String result = null;
BufferedOutputStream bos = null;
try {
/**
* 解决DocType问题
*/
Transformer transformer = TransformerFactory.newInstance()
.newTransformer();
DocumentType doctype = document.getDoctype();
if (doctype != null) {
String systemId = doctype.getSystemId();
String publicId = doctype.getPublicId();
if (systemId != null) {
transformer.setOutputProperty(OutputKeys.DOCTYPE_SYSTEM,
systemId);
transformer.setOutputProperty(OutputKeys.DOCTYPE_PUBLIC,
publicId);
}
}
DOMSource source = new DOMSource(document);
StringWriter strWtr = new StringWriter();
StreamResult stream = new StreamResult(strWtr);
transformer.transform(source, stream);
result = stream.getWriter().toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (bos != null) {
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return result;
}
/**
* 给定一个节点,将该节点加入新构造的Document中。
*
* @param node
* a Document node
* @return a new Document
*/
public static Document newXMLDocument(Node node) {
Document doc = newXMLDocument();
doc.appendChild(doc.importNode(node, true));
return doc;
}
/**
* 获取一个Transformer对象,由于使用时都做相同的初始化,所以提取出来作为公共方法。
*
* @return a Transformer encoding gb2312
*/
public static Transformer newTransformer() {
try {
Transformer transformer = TransformerFactory.newInstance()
.newTransformer();
Properties properties = transformer.getOutputProperties();
properties.setProperty(OutputKeys.ENCODING, "gb2312");
properties.setProperty(OutputKeys.METHOD, "xml");
properties.setProperty(OutputKeys.VERSION, "1.0");
properties.setProperty(OutputKeys.INDENT, "no");
transformer.setOutputProperties(properties);
return transformer;
} catch (TransformerConfigurationException tce) {
throw new RuntimeException(tce.getMessage());
}
}
/**
* 返回一段XML表述的错误信息。
*
* @param title
* 提示的title
* @param errMsg
* 提示错误信息
* @param errClass
* 抛出该错误的类,用于提取错误来源信息。
* @return a XML String show err msg
*/
public static String errXMLString(String title, String errMsg,
Class errClass) {
StringBuffer msg = new StringBuffer(100);
msg.append("<?xml version='1.0' encoding='utf-8' ?>");
msg.append("<errNode title=" + title + "errMsg=" + errMsg
+ "errSource=" + errClass.getName() + "/>");
return msg.toString();
}
}
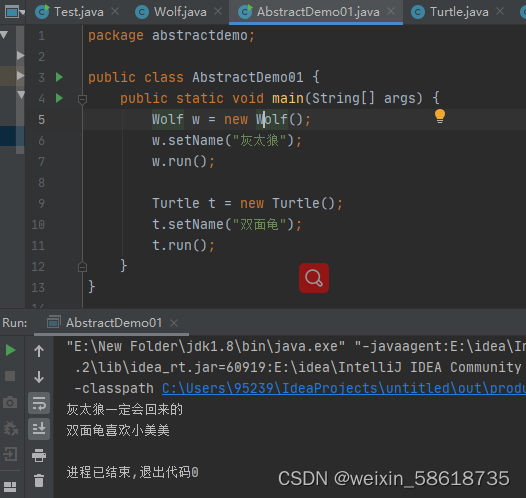
运行下测试类,代码如下
import org.junit.Test;
public class ProcessEngineTest {
@Test
public void testRun() throws Exception {
//读取文件内容到字符串
String modelStr= XmlUtil.XmlToString("E:\\gitee\\springboot-demo\\src\\main\\java\\com\\example\\demo\\enginer\\xml\\v1.xml");
ProcessEngine processEngine = new ProcessEngine(modelStr);
processEngine.registNodeProcessor(new OperatorOfApproval());
processEngine.registNodeProcessor(new OperatorOfApprovalApply());
processEngine.registNodeProcessor(new OperatorOfNotify());
processEngine.start();
Thread.sleep(1000 * 1);
}
}
输出如下:
小明 提交的申请单 formInfo 被 经理 审批,结果为 审批通过
process finished!
下篇我们实现并行的流程,如下: