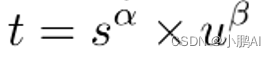文章目录
- 一、Meta Learning
- 什么是元学习?
- 元学习–第1步
- 元学习–第2步
- 元学习–步骤3
- 架构
- ML和Meta
- 回顾GD
- 学习好的初始化参数
- 学习学习率
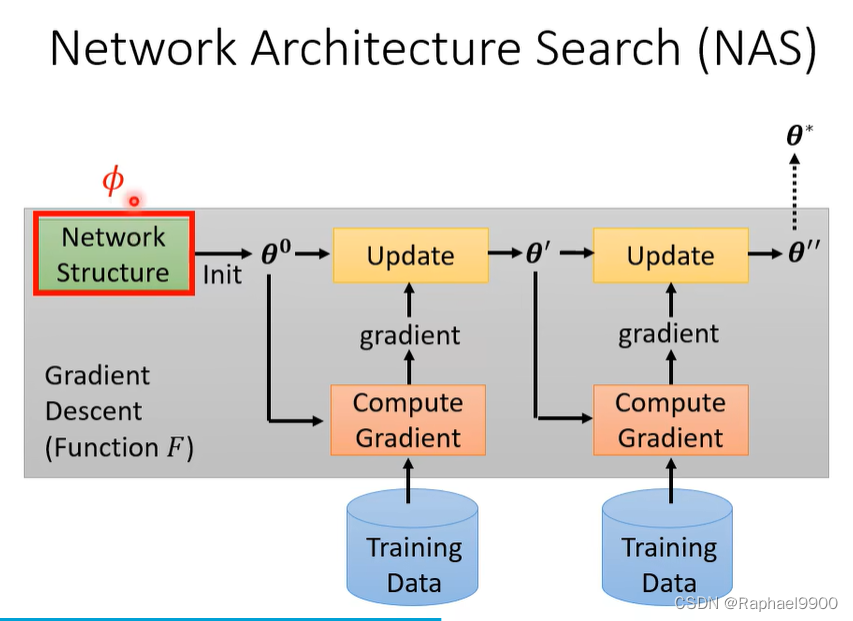
- NAS寻找网络结构
- data augmentation
- Sample Reweighting
- Few-shot Image Classification
- 元学习与自我监督学习
- 元学习和知识蒸馏
- 元学习和领域适应
- 元学习与终身学习
一、Meta Learning
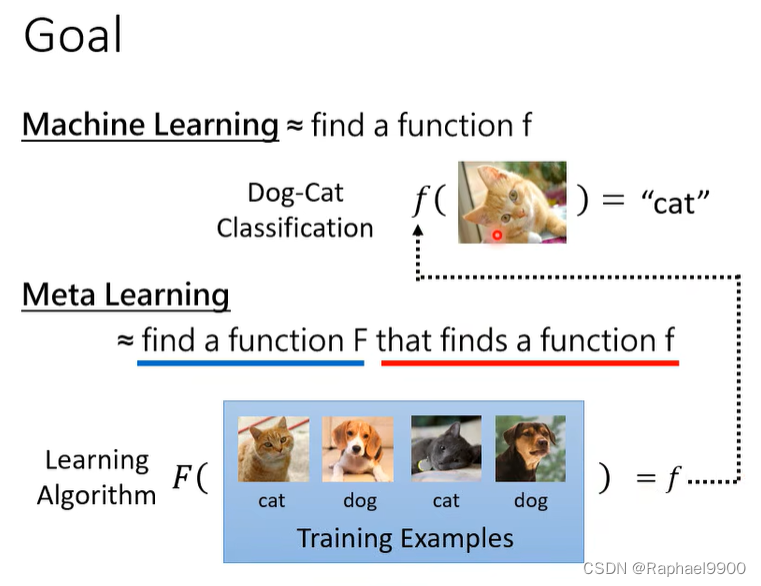
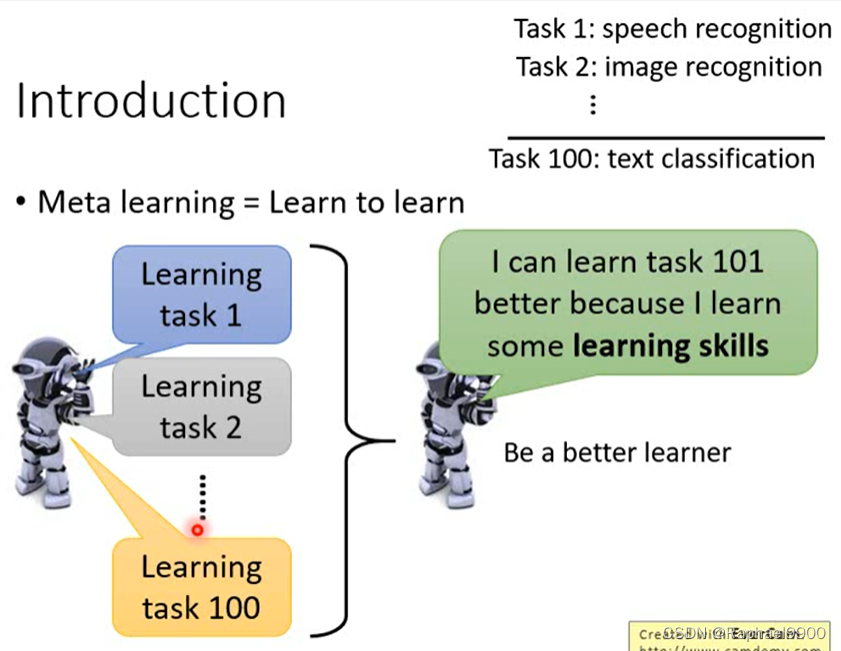
元学习:学会学习
在学术界,我们的GPU不多,超参数不能全列举。机器能自动确定超参数吗?

回顾ML的三步骤
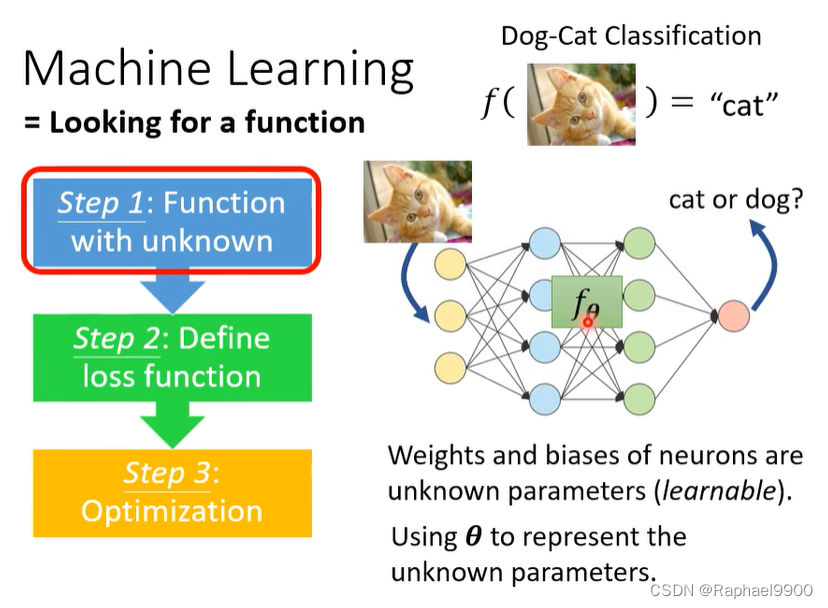
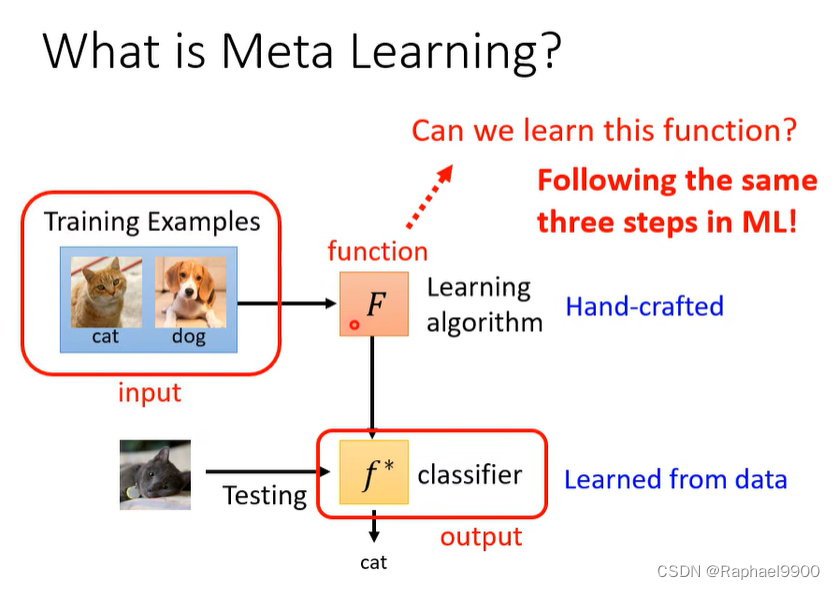
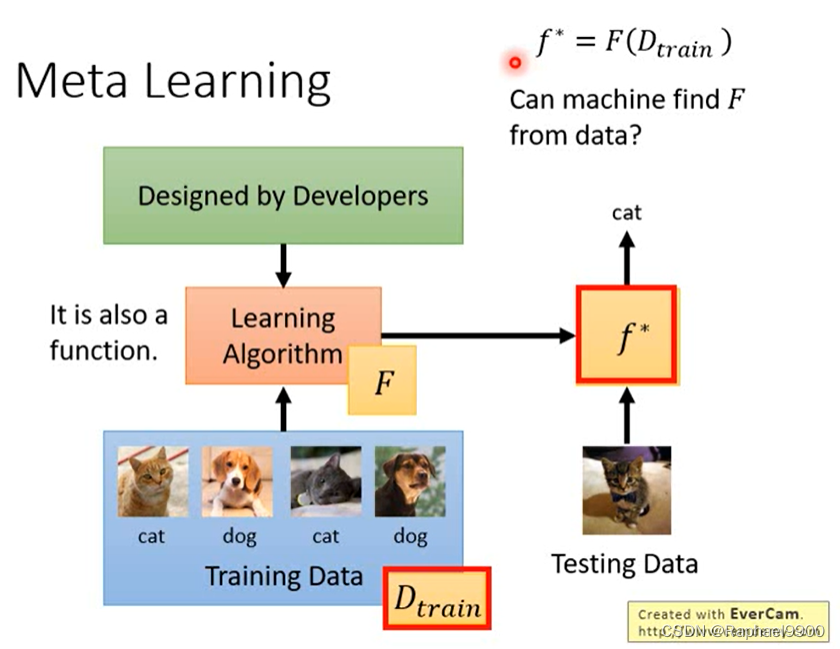
什么是元学习?
让机器学习找到这个方程。
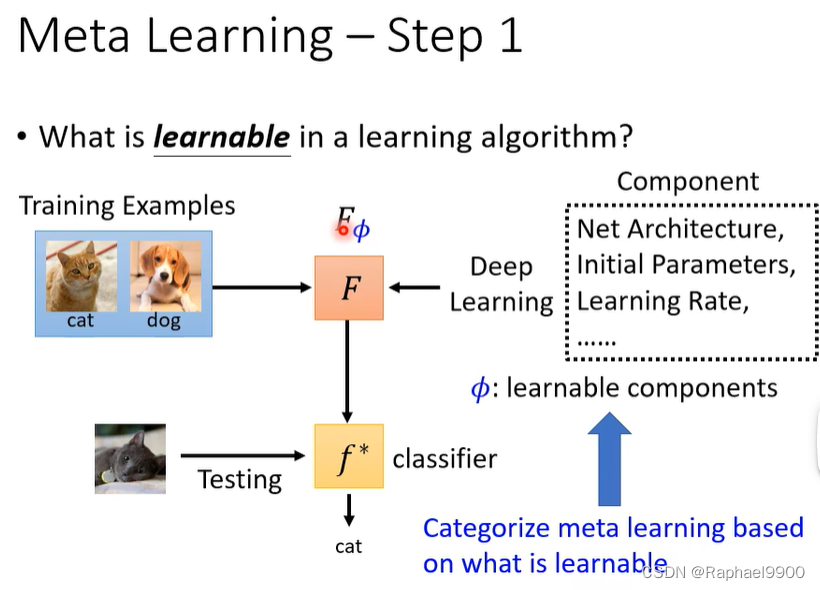
元学习–第1步
学习算法中什么是可以学习的?组成:网络架构,初始参数,学习率。根据什么是可学习的对元学习进行分类。
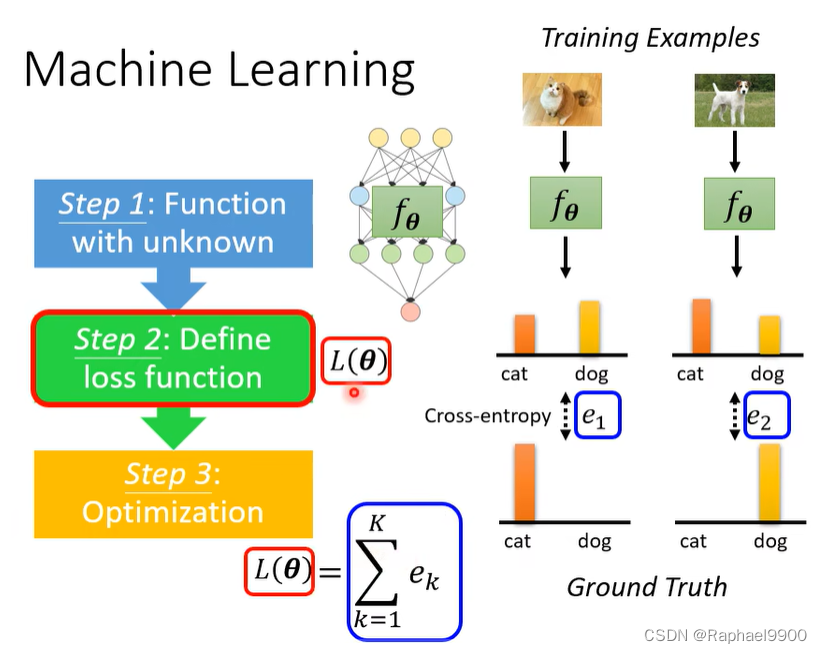
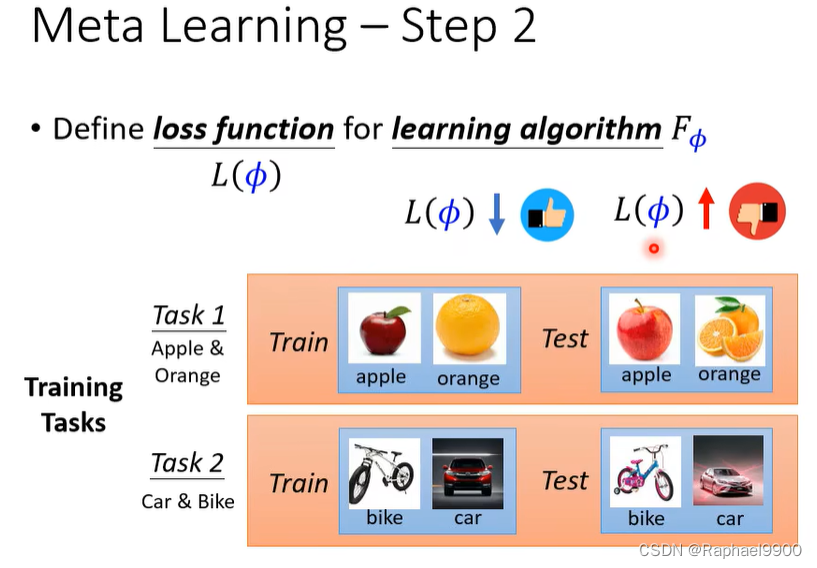
元学习–第2步
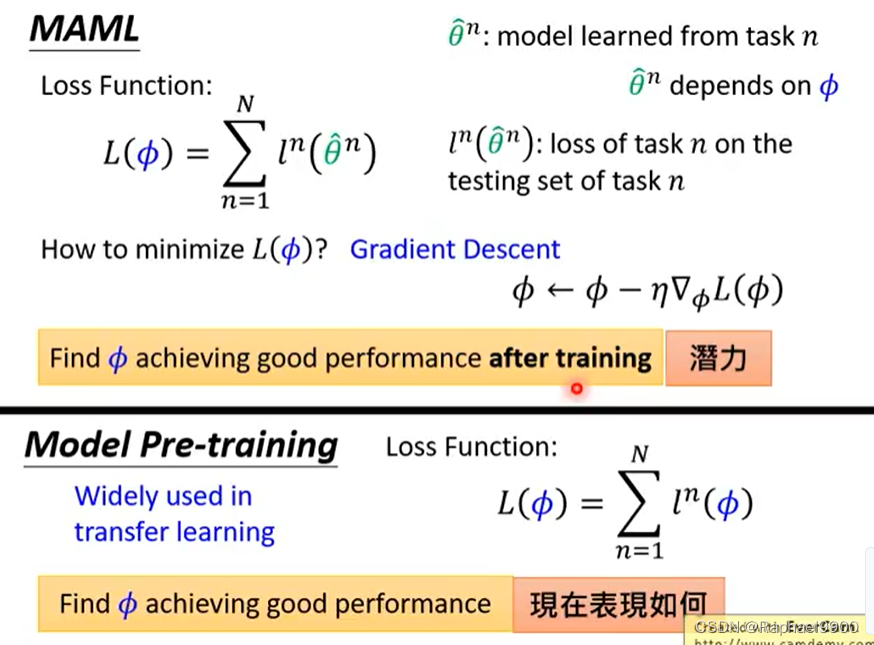
为学习算法Fφ定义损失函数L(φ)。
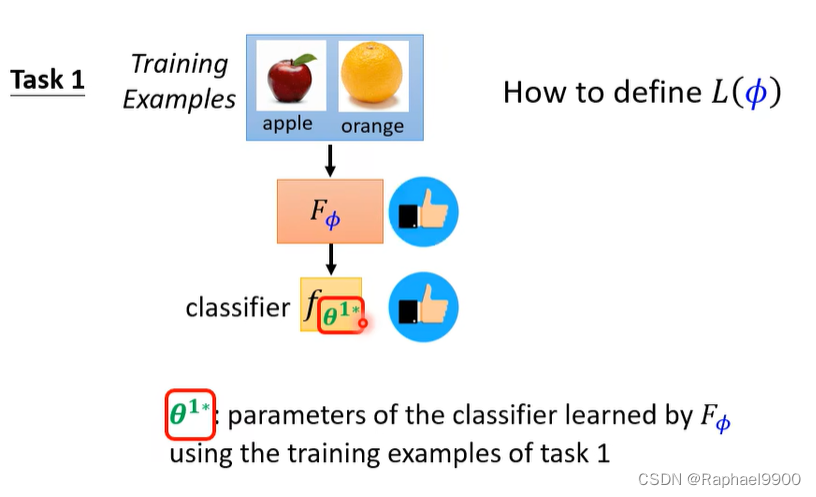
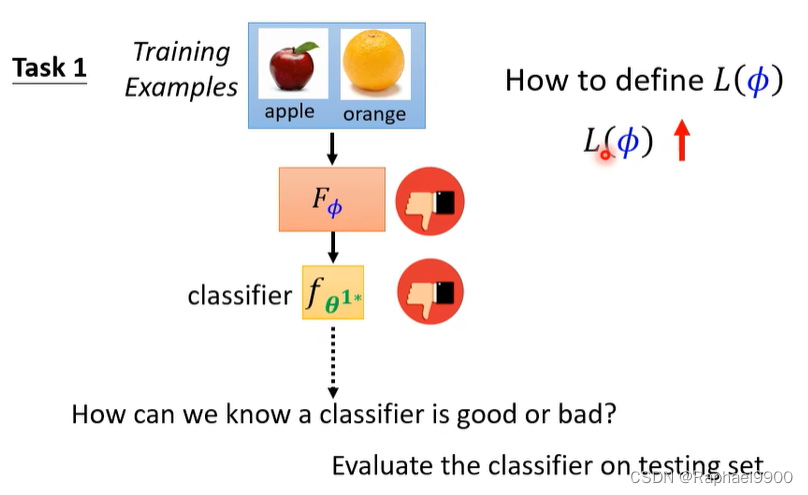
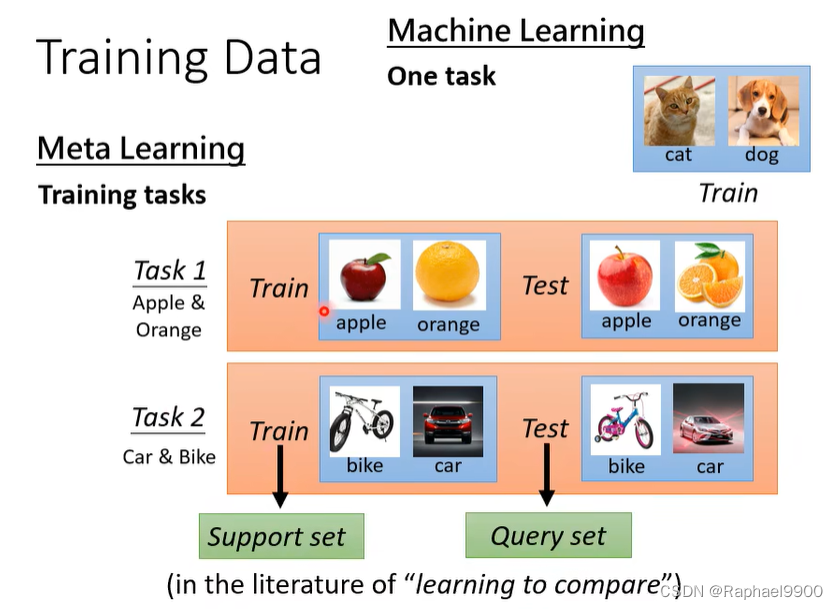
我们如何知道一个分类器是好是坏? 在测试集上评估分类器。
训练和测试资料都是有标注的。
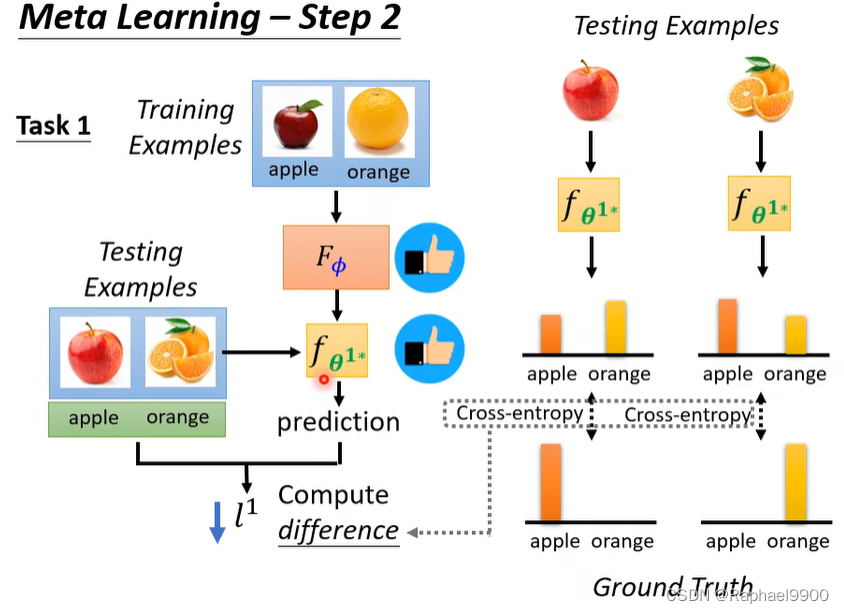
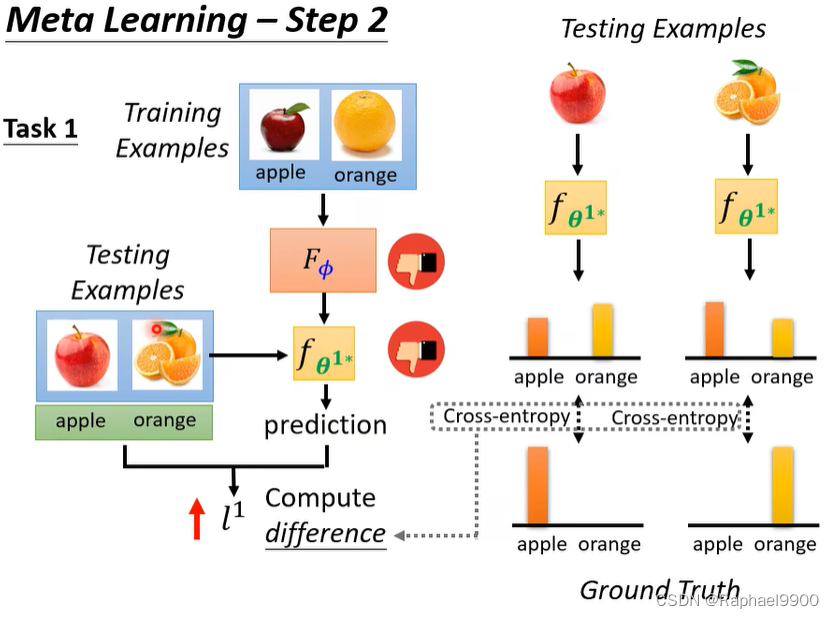
上面都是对同一个任务的训练,但是在元学习里面不止一个任务。

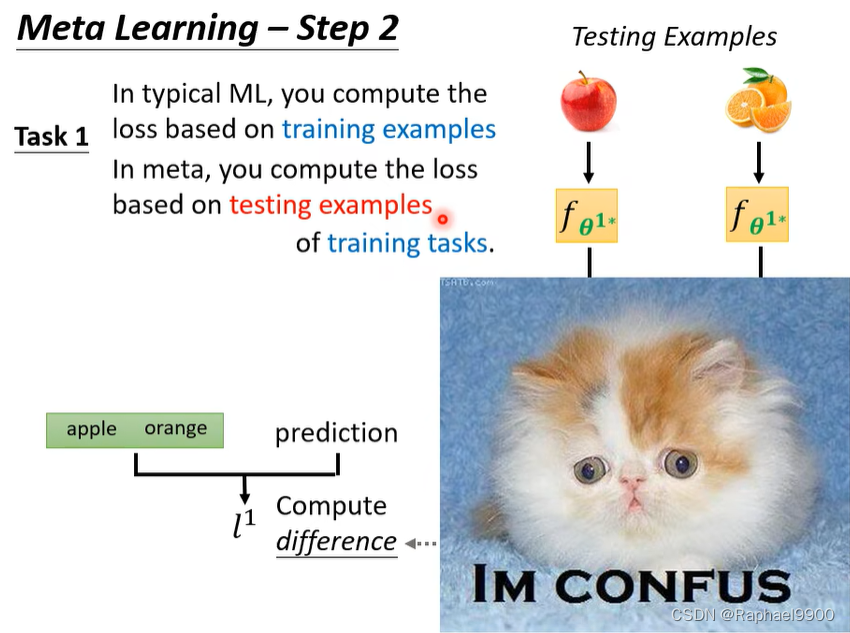
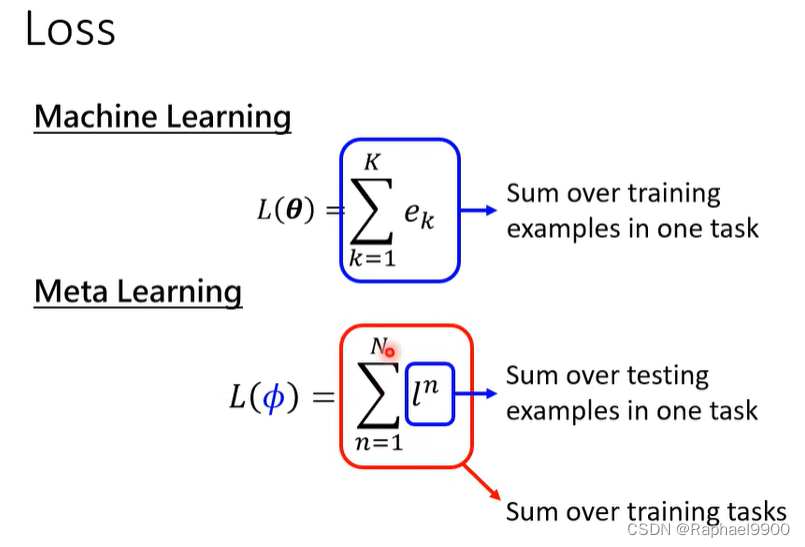
在典型的ML中,是基于训练示例来计算损失,但是在元学习上用的是测试资料计算loss。
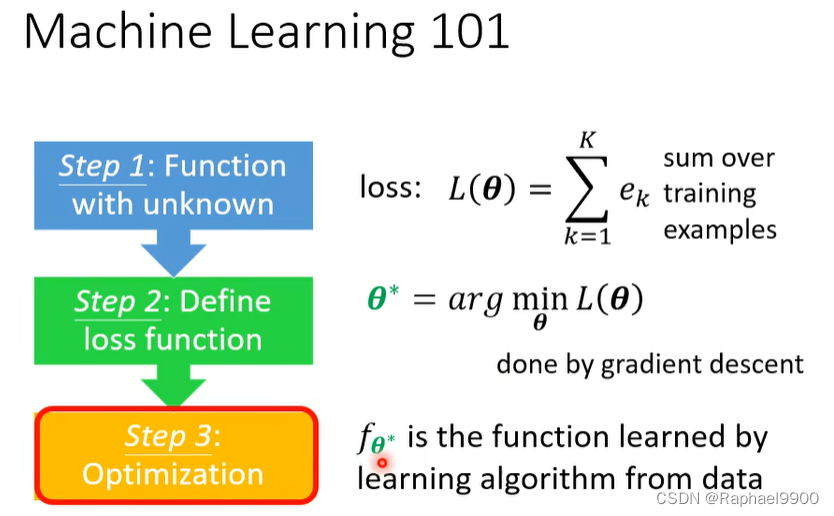
元学习–步骤3
求出最好的参数和Fφ。在参数φ没办法求微分的时候可以用RL。

架构
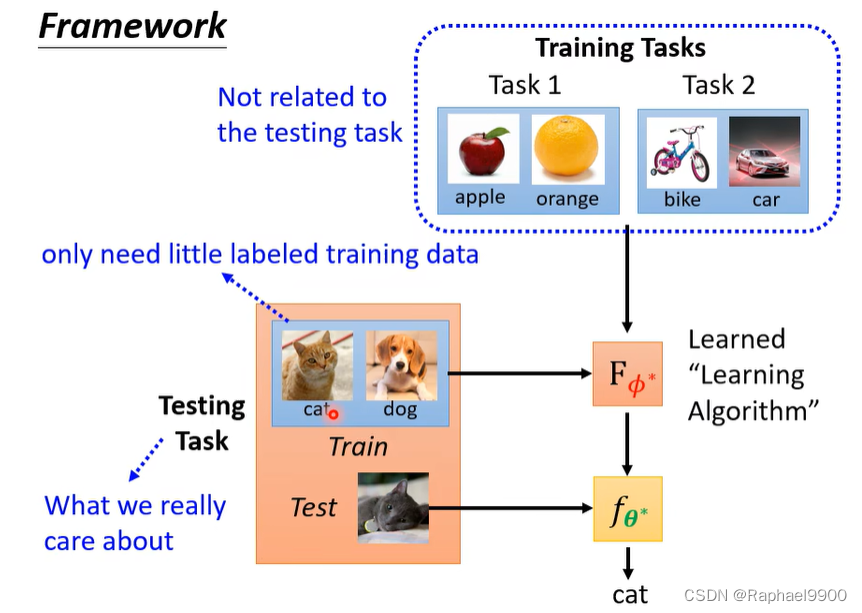
使用训练任务的资料,运用上面的三步骤就能得到一个学习出来的算法Fφ * 。
然后使用测试任务里面的训练资料放到这个学出的算法里面得到一个分类器fθ * 。
然后把分类器用在测试任务里面的测试资料上得到结果。
训练任务是跟测试任务无关的任务。小任务学习是用一点标注的资料就能得到好的结果,这两个还是有区别的。在ML里面的测试资料是不能用的!在元学习里面需要使用。
ML和Meta
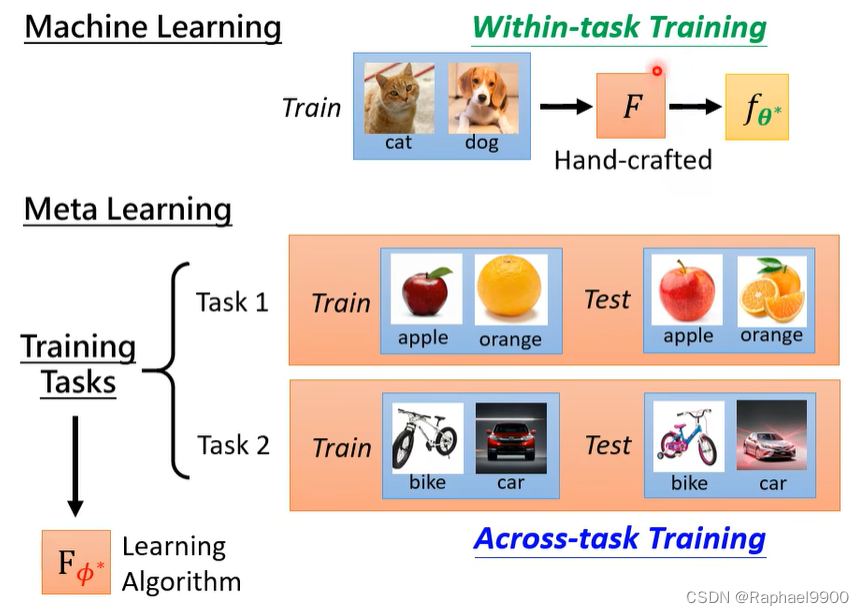
元学习——跨任务学习,ML——任务内学习
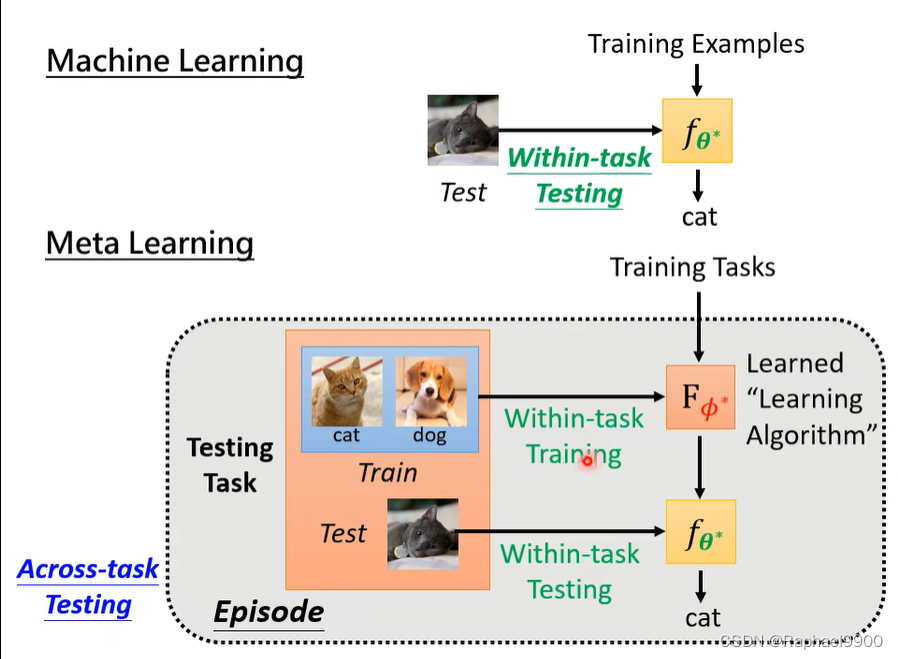
元学习的一次episode运算量大。
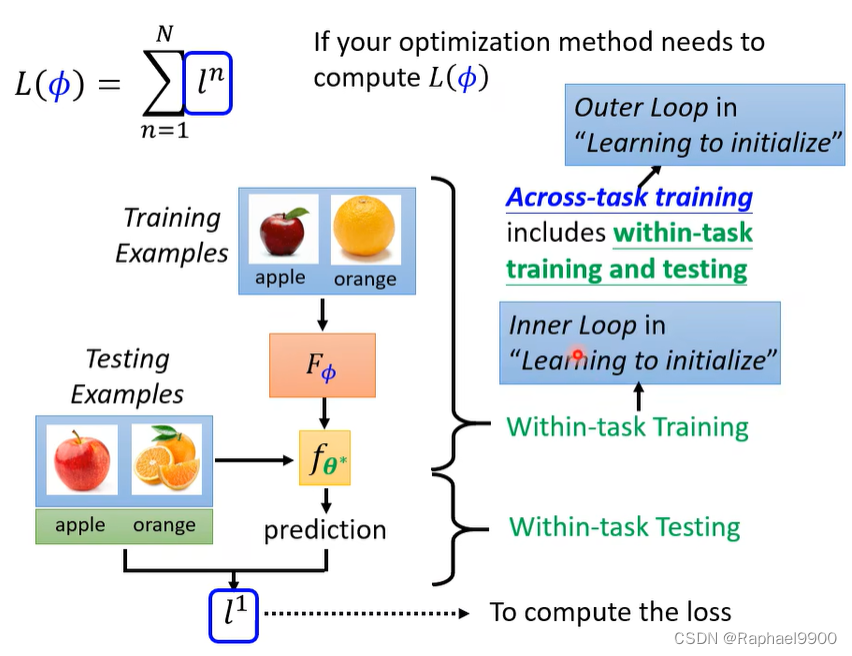
你所知道的关于ML的知识通常可以应用到元学习中:
过度适应训练任务,获得更多训练任务以提高结果,任务扩充,学习学习算法时也有超参数…,改善任务(元学习也应该有个验证集)

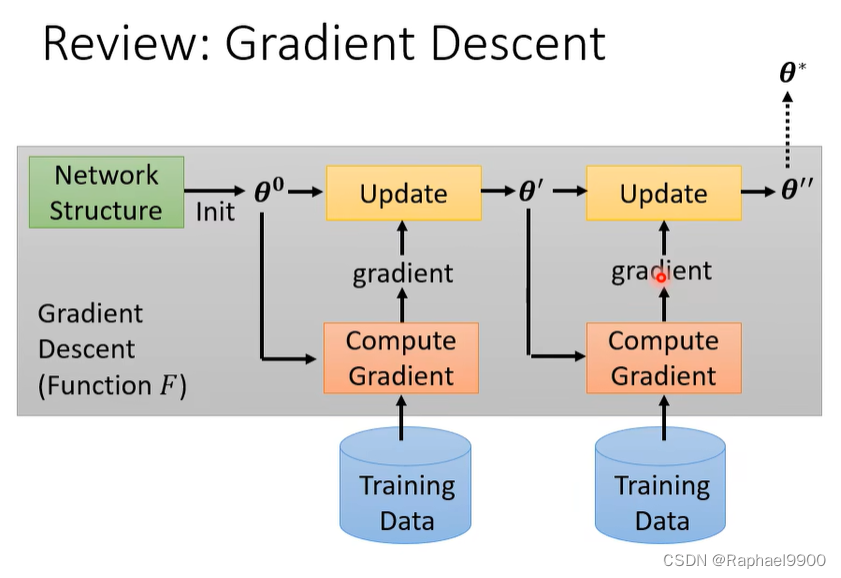
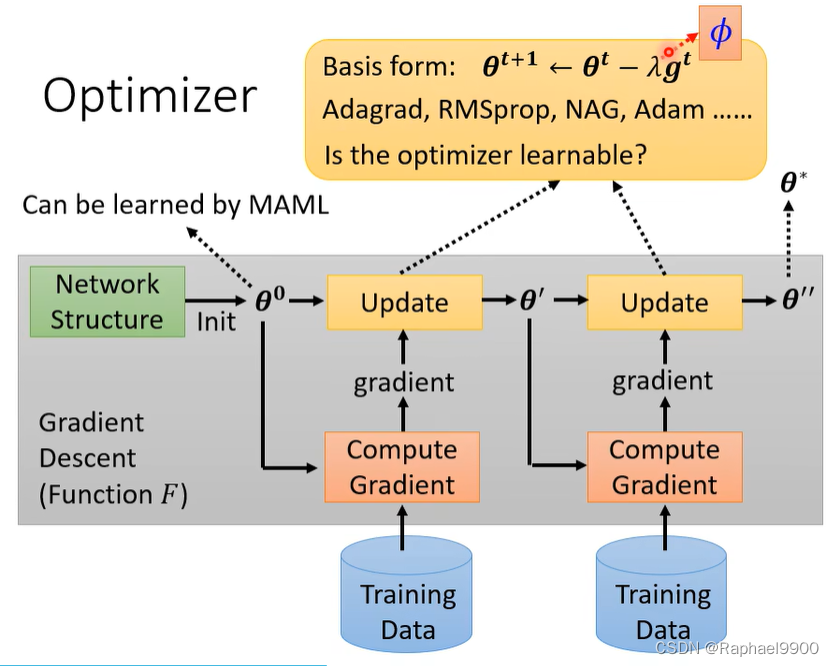
回顾GD
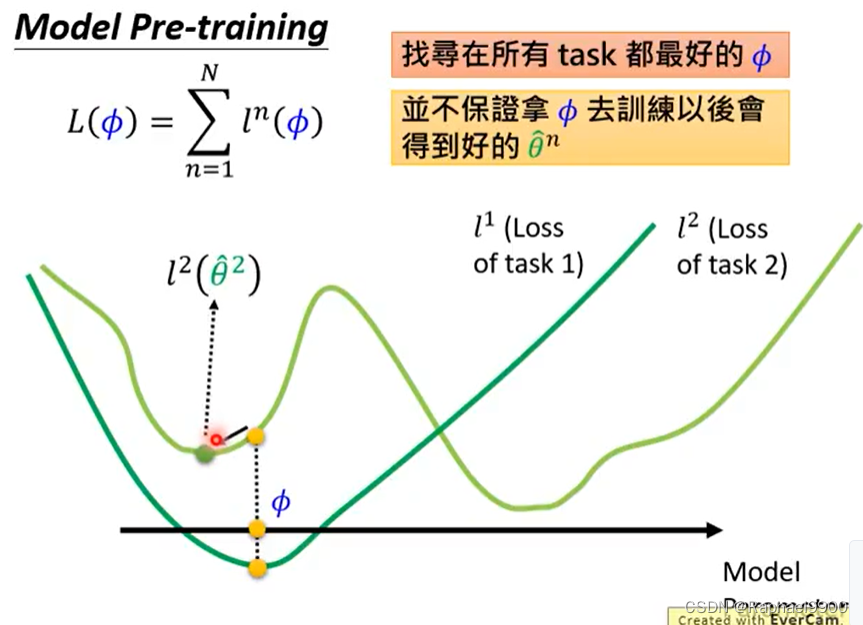
学习好的初始化参数
初始化参数θ0是随机取样的
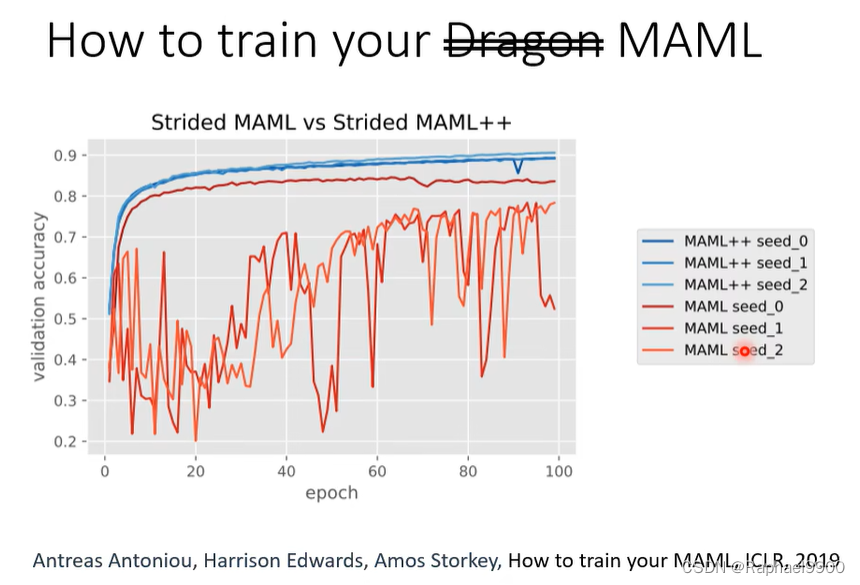
好的初始化也很重要。

也需要随机种子和调参
预训练由代理任务训练。预训练和MAML很像,都可以找到一个好的初始化参数。区别:MAML需要标注资料,预训练没有标注资料。
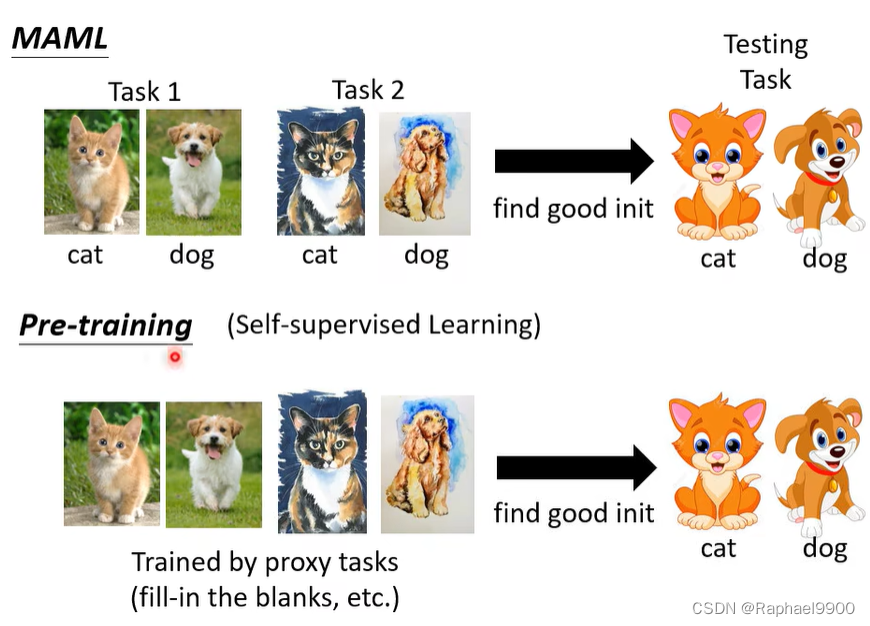
预训练是把很多任务都混在一起训练,也可以说是多任务学习。
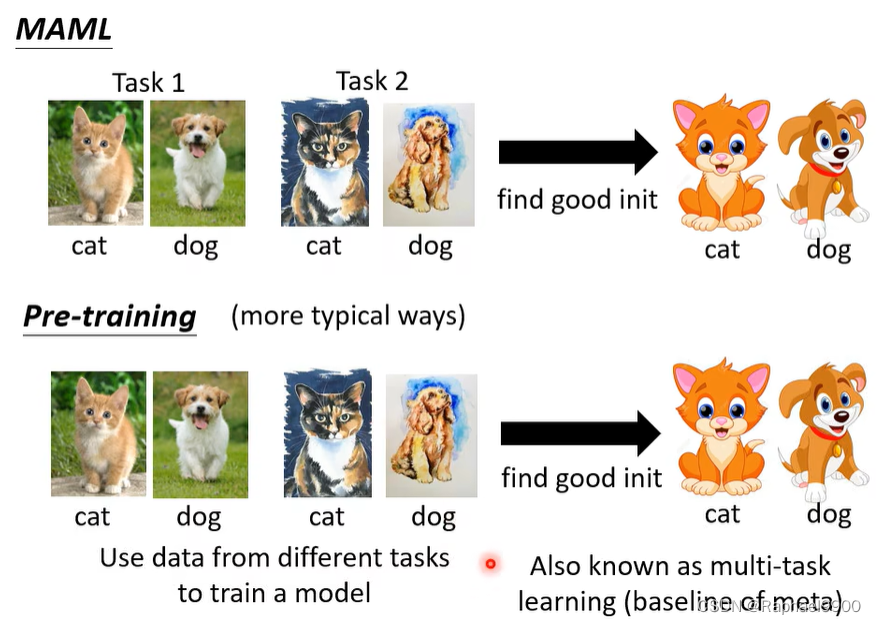
元学习也很像领域适应/迁移学习
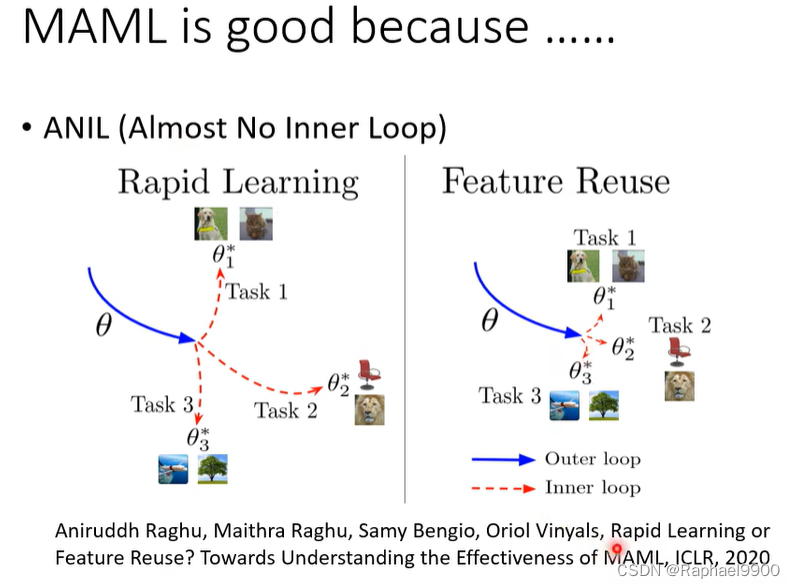
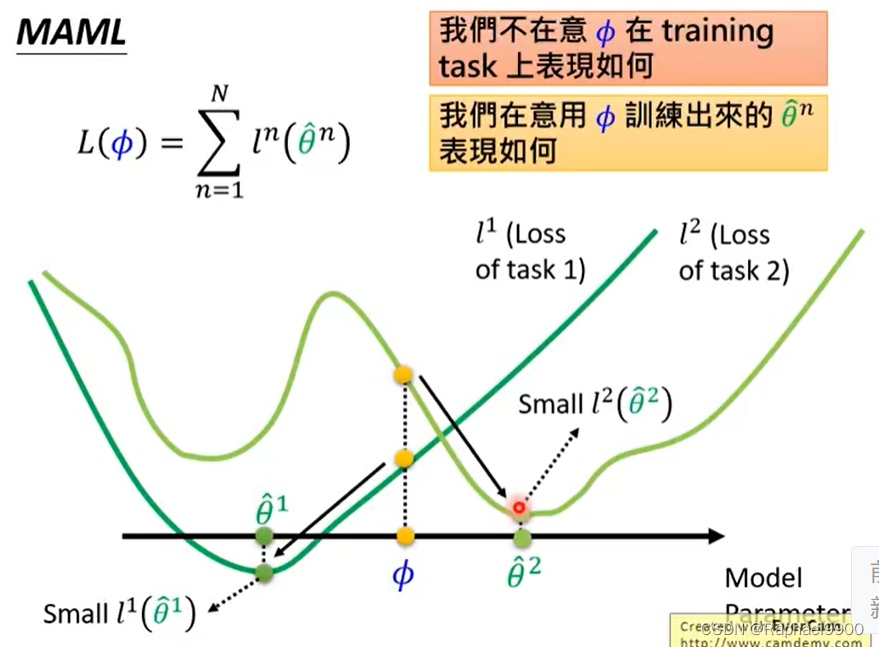
MAML好在初始化的参数跟好参数接近。
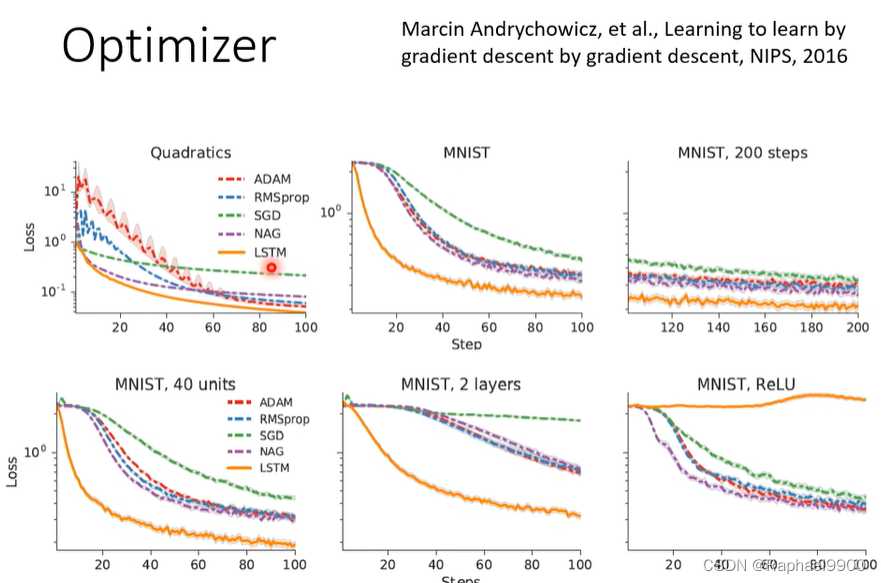
学习学习率
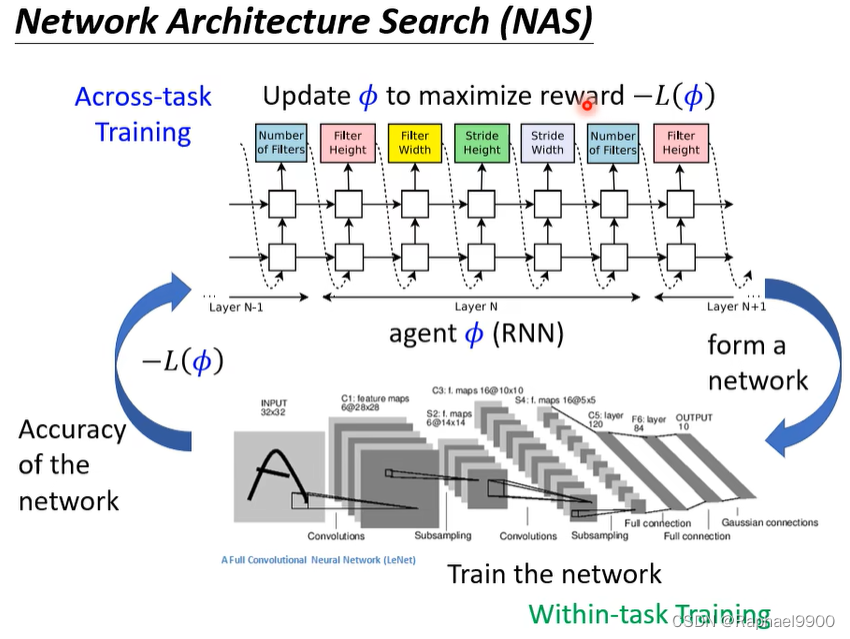
NAS寻找网络结构


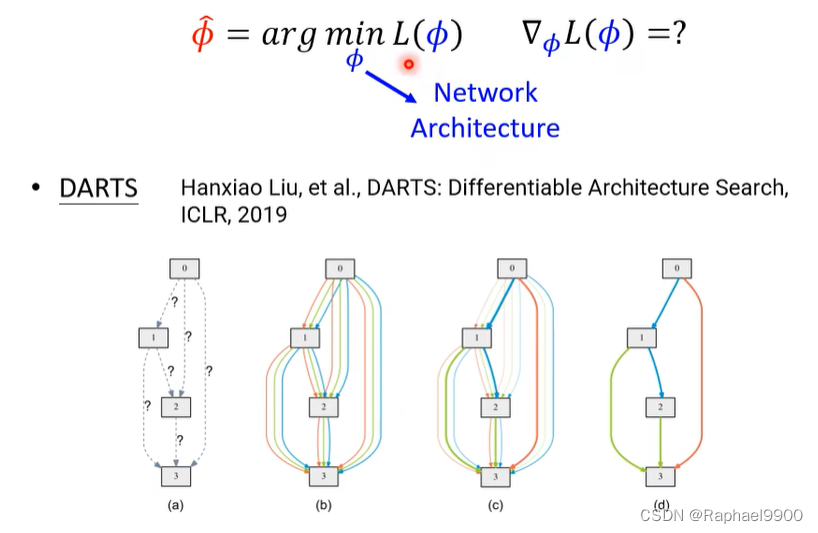
让网络可以微分:
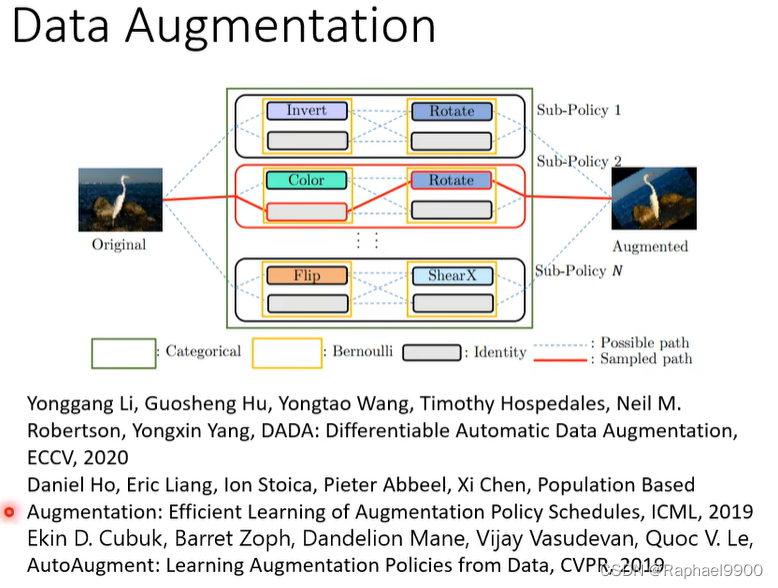
data augmentation
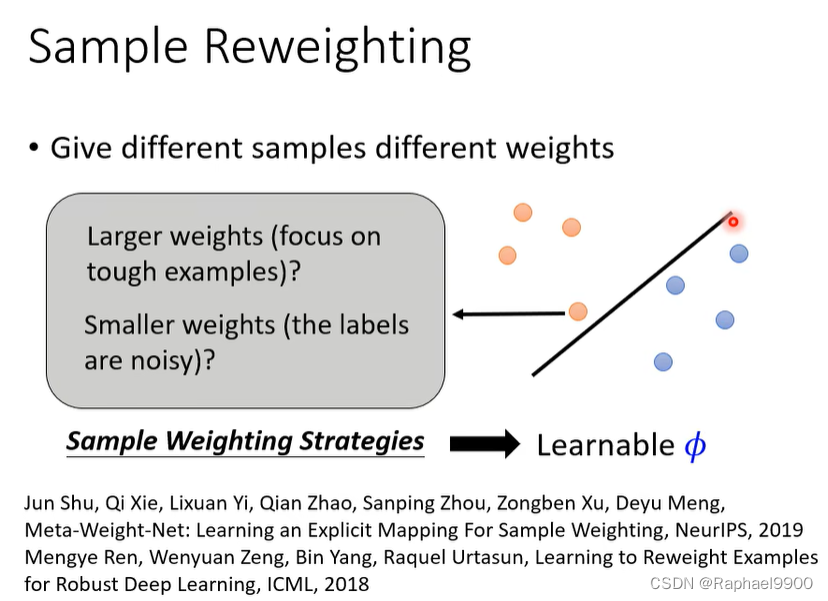
Sample Reweighting
给不同的样品不同的重量
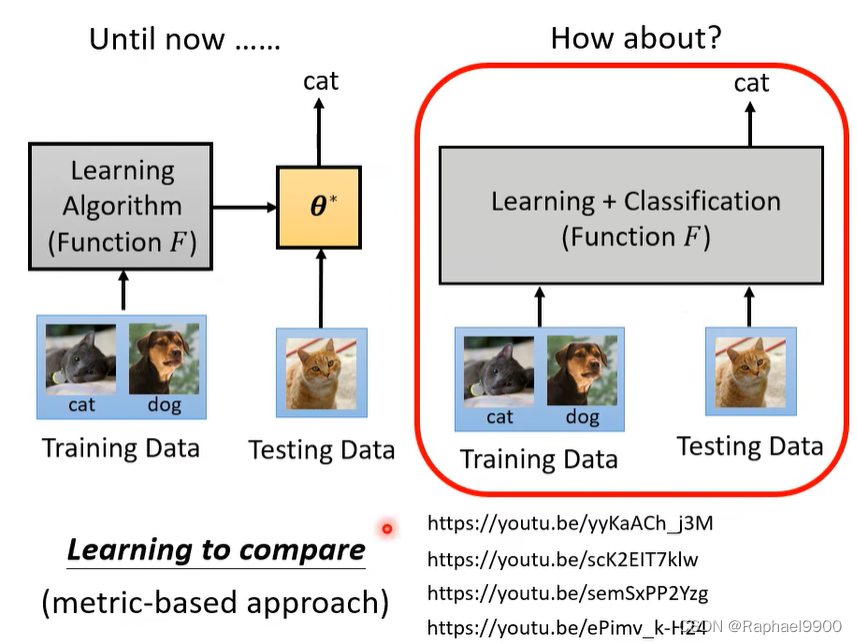
以上方法都是基于GD的。

所有训练和测试资料一起输入:
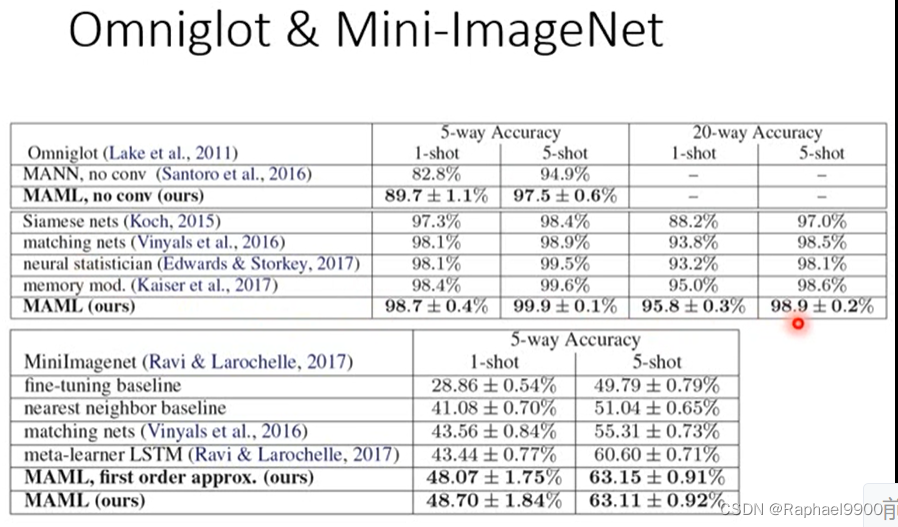
Few-shot Image Classification
Few-shot Image Classification·:每个类只有几个图像。



元学习与自我监督学习
BERT和MAML都是找初始化的参数:

MAML学习初始化参数φ是通过梯度下降算法。因为GD也需要进行随机初始化,所以初始化参数φ0是什么?可以从BERT里面产生!

存在“学习差距”:自我监督的目标不同于下游任务,BERT预训练的任务有很多,但是不一定适配下游任务。但是MAML关心学会在训练任务中取得好的表现。MAML需要使用训练资料,但是BERT可以使用大量无标注资料。

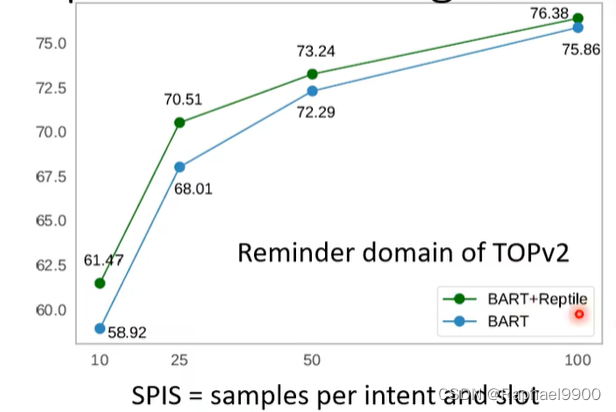
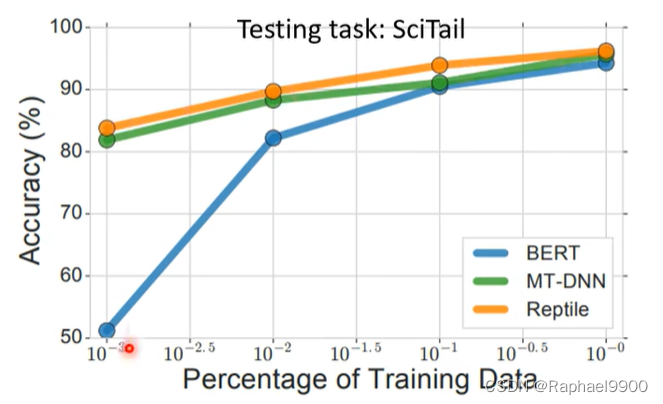
BERT和元学习的联合会有好的结果。
元学习和知识蒸馏
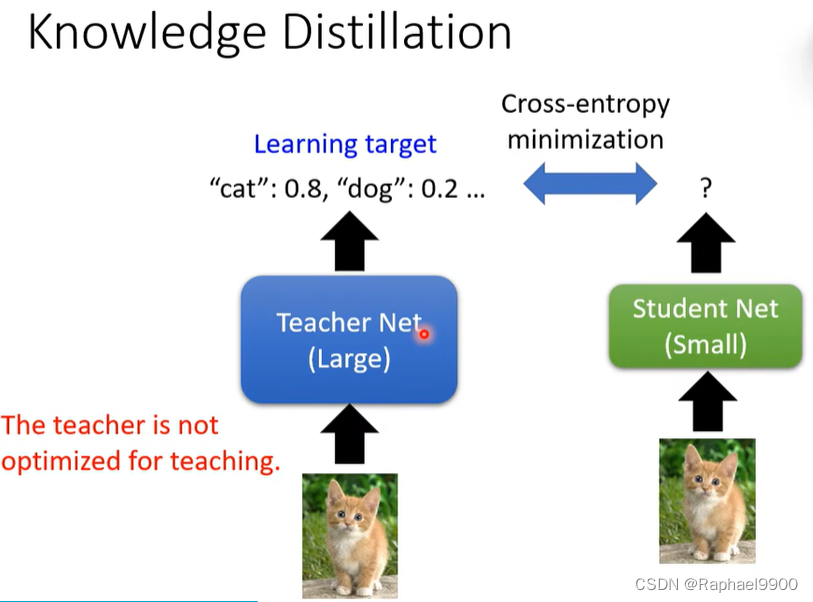
让学生网络学习教师网络,但是我们不知道教师网络是好的还是不好的。
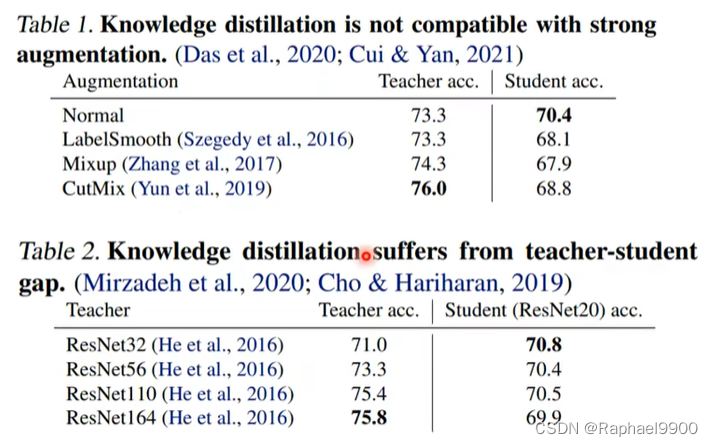
我们可以发现结果最好的老师网络不见得教的好!
我们可以用元学习让老师网络学习如何去教。
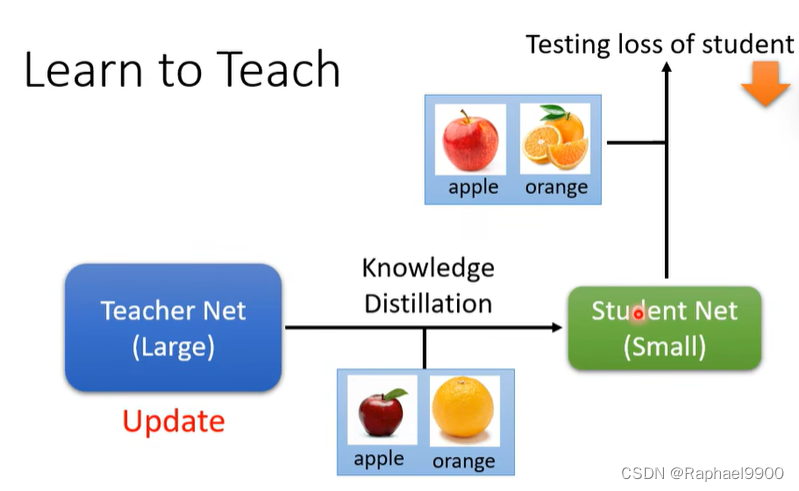
我们需要更新教师网络(加入温度参数,不用整个大网络都更新)让学生的结果是最好的(loss低)。
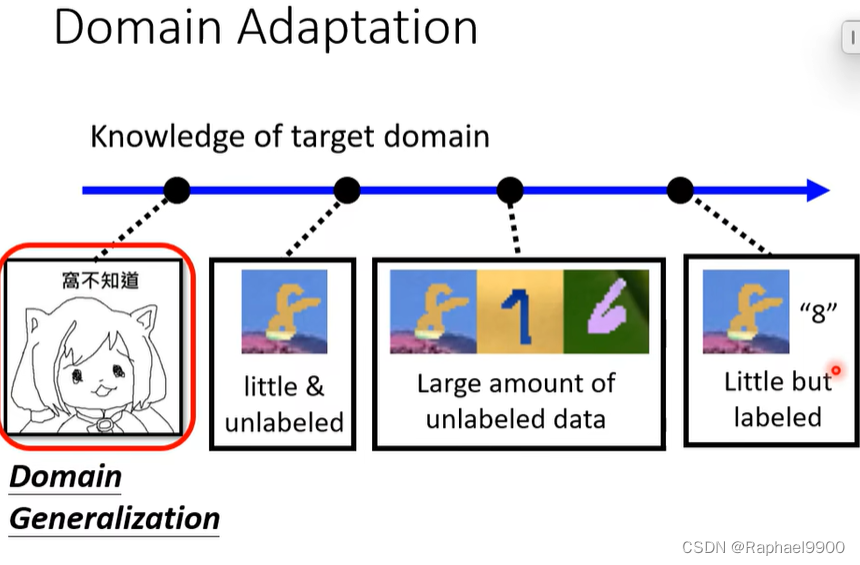
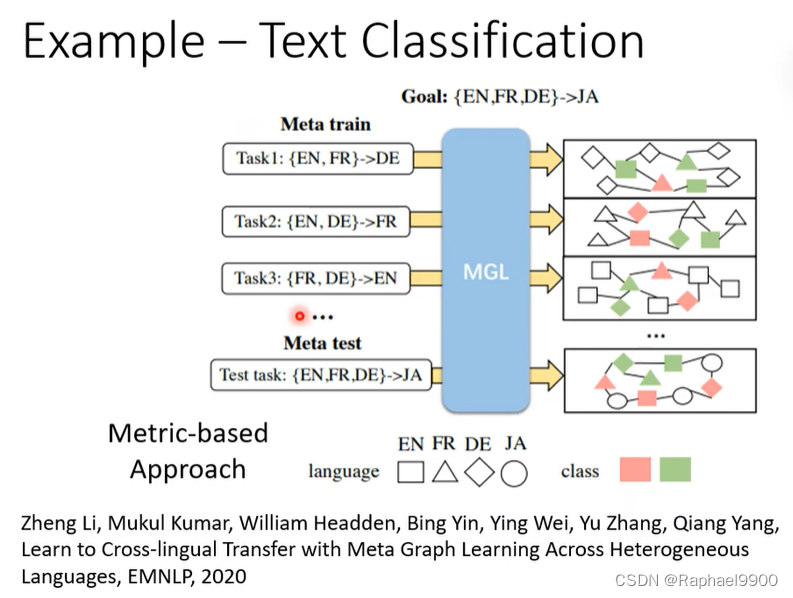
元学习和领域适应
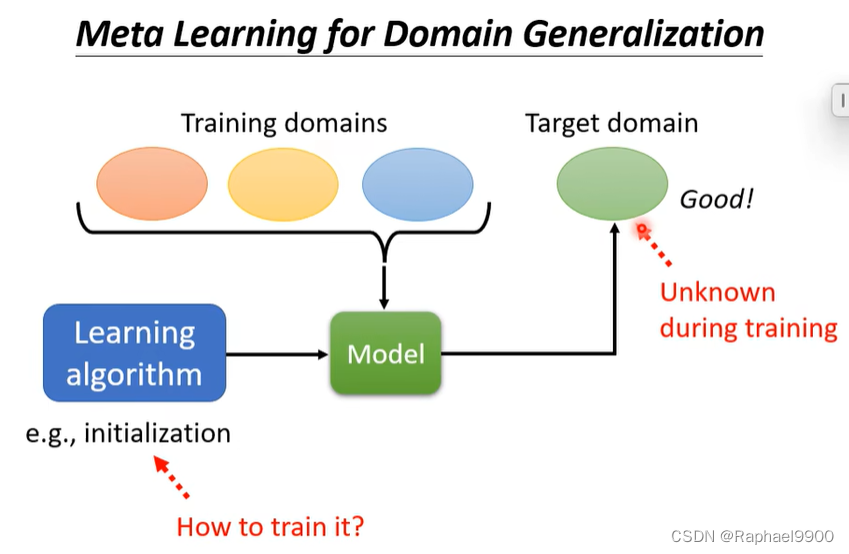
我们不知道目标领域(训练阶段没有目标领域的数据),可以训练domain generalization来让网络在未知领域表现好。
使用训练领域中的一个领域作为伪目标域:
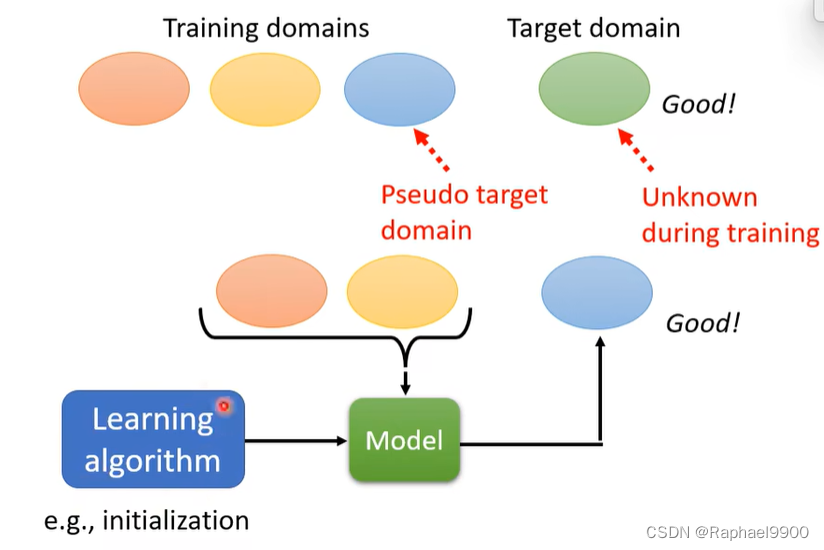
可以分别作为为目标域:
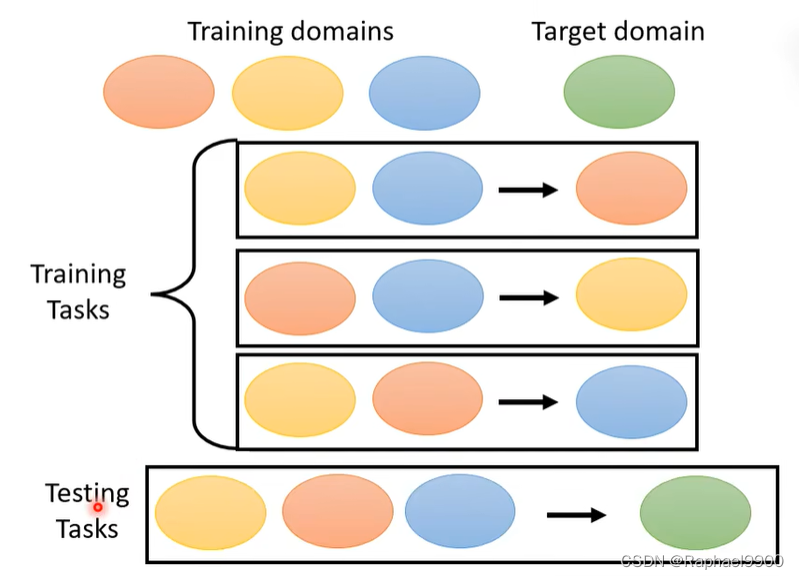
训练样本和测试样本可以具有不同的分布。训练任务和测试任务也可以有不同的分布。

元学习与终身学习
机器如果通过终身学习,会最终变很厉害!
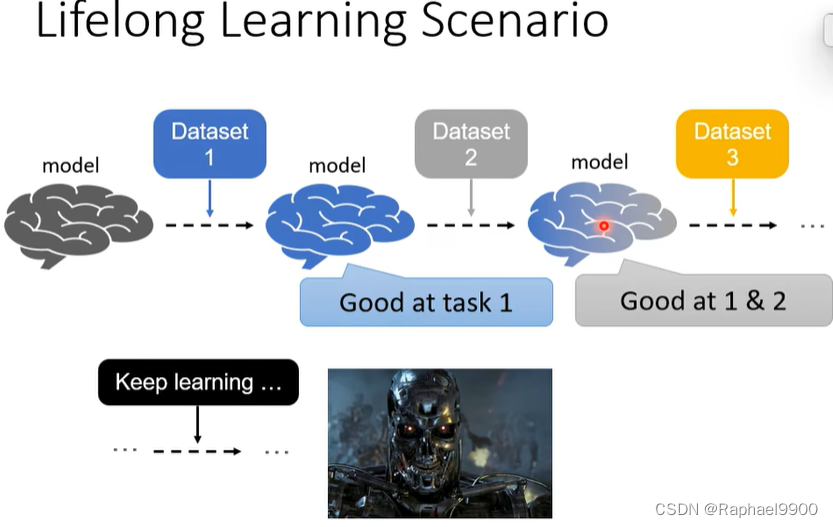
但是实际上如果一个任务一个任务的训练,机器会产生灾难性遗忘的结果
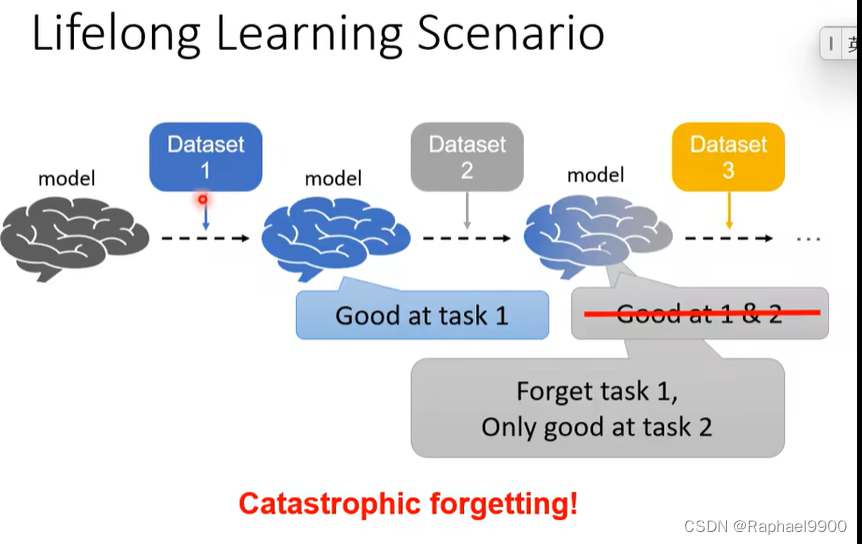
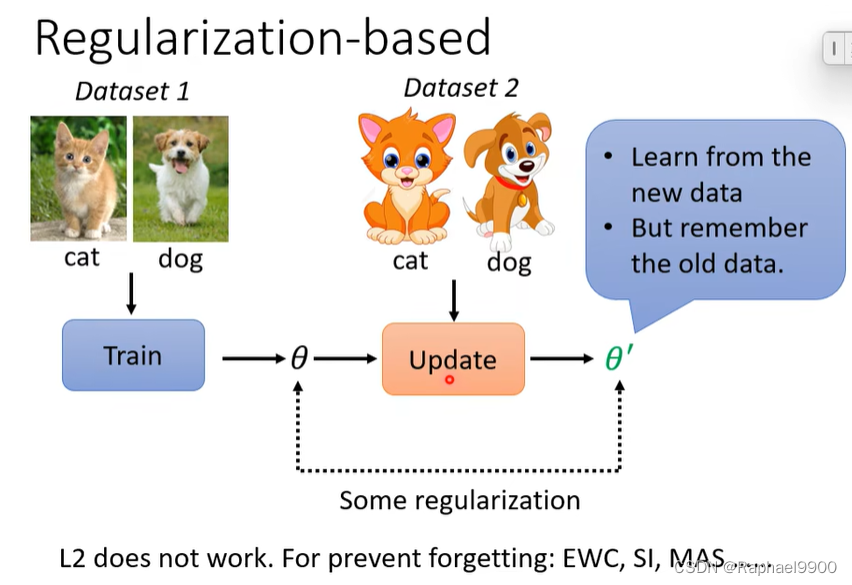
解决灾难性遗忘:

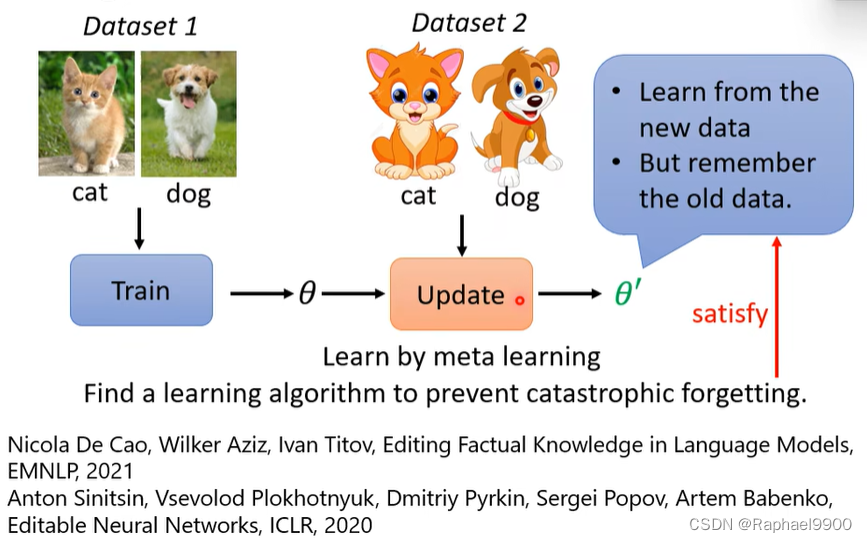
元学习也可以用在这个过程中!可以用元学习学习参数更新的时候不忘记旧任务。
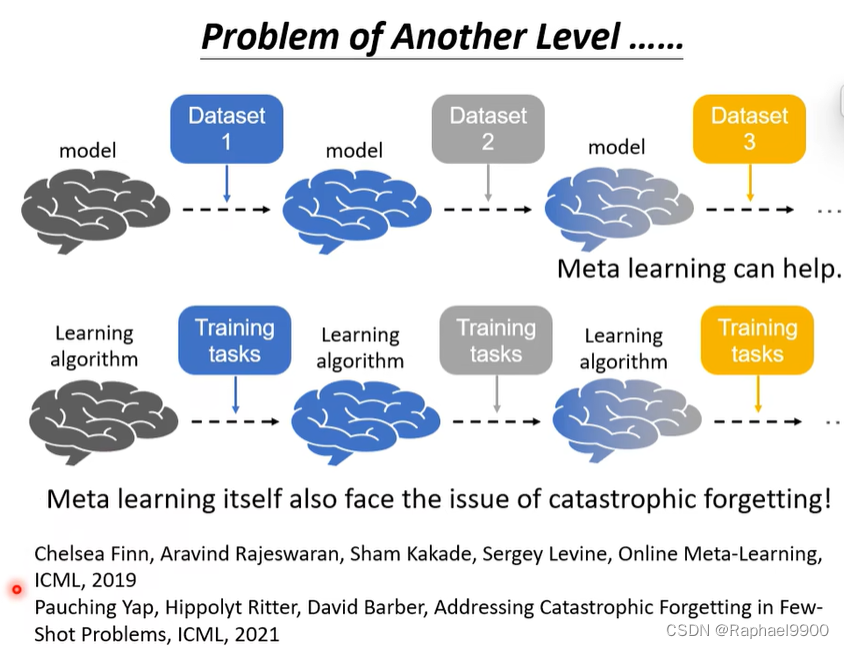
元学习也有毁灭性遗忘的问题:
元学习学会学习:
”
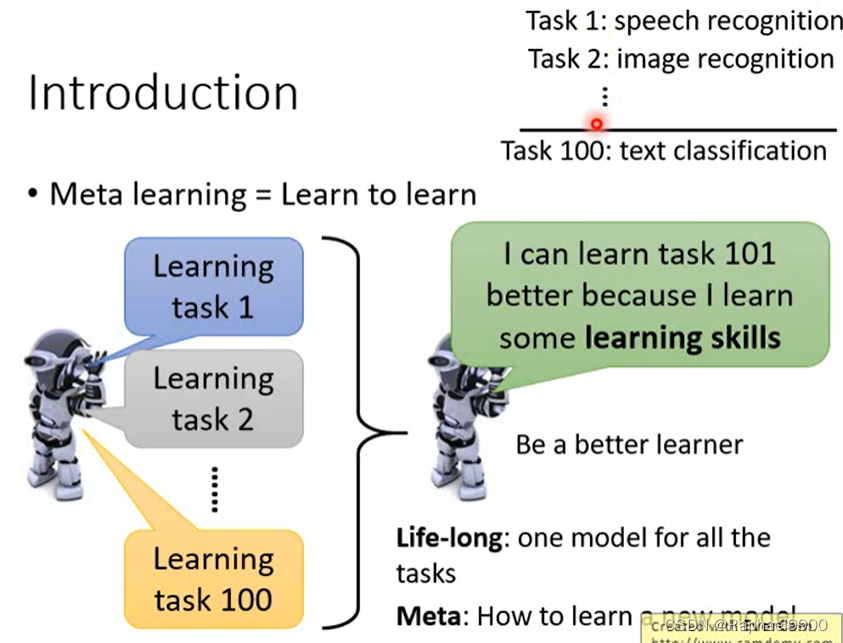
元学习不同任务有不同的模型,但是终身学习是一个任务学习多个任务。

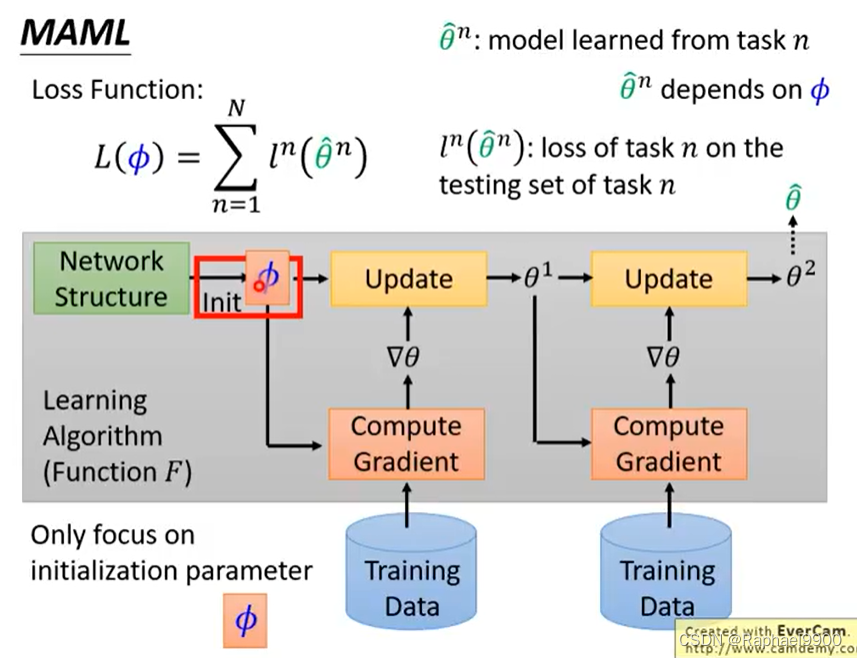
MAML是用训练过的模型来计算loss 的,而预训练直接使用模型的参数进行计算loss。

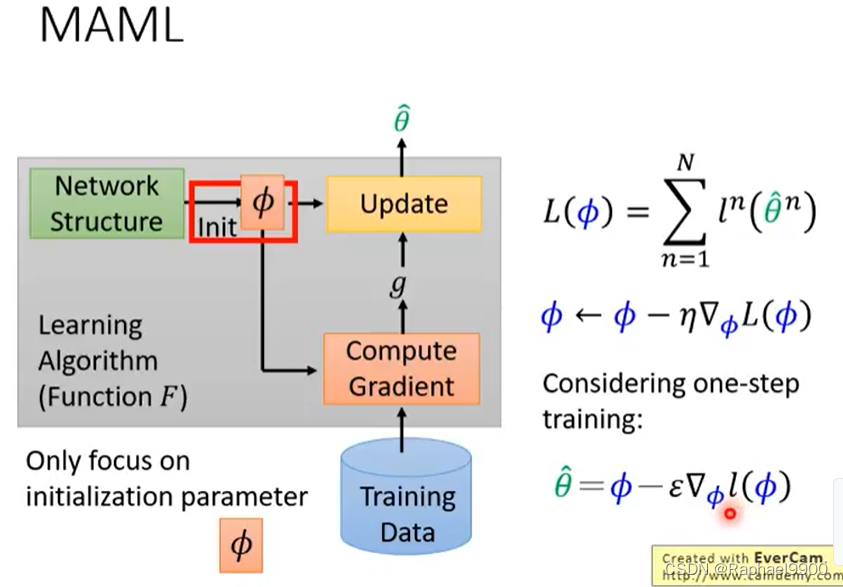
一步到位训练出一个模型。在使用算法时,仍然要多次更新。few-shot学习的数据有限。MAML在训练的时候一般只更新一次。
每个任务:给定一个目标正弦函数y = a sin(x + b),从目标函数中采样K个点,使用样本估计目标函数。
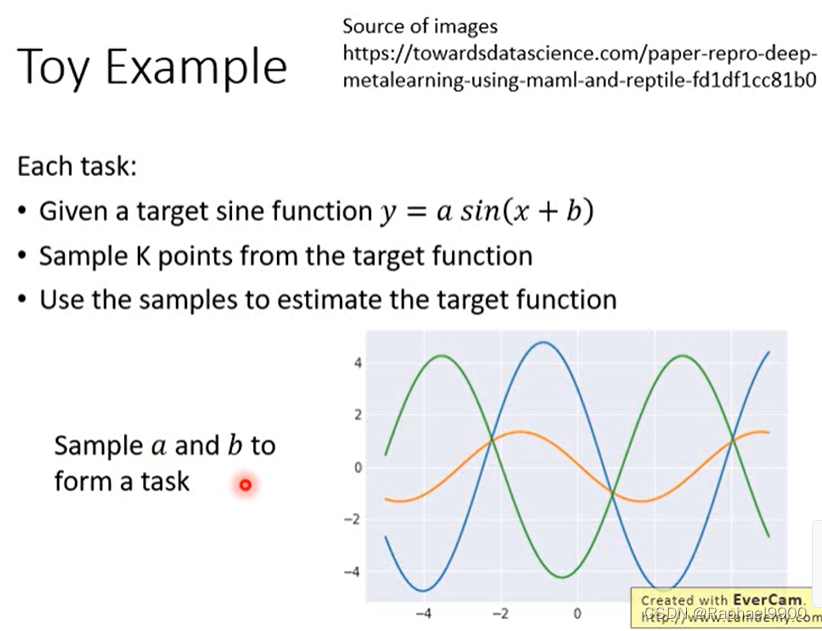
预训练做的不太好,但是MAML做的好一点。
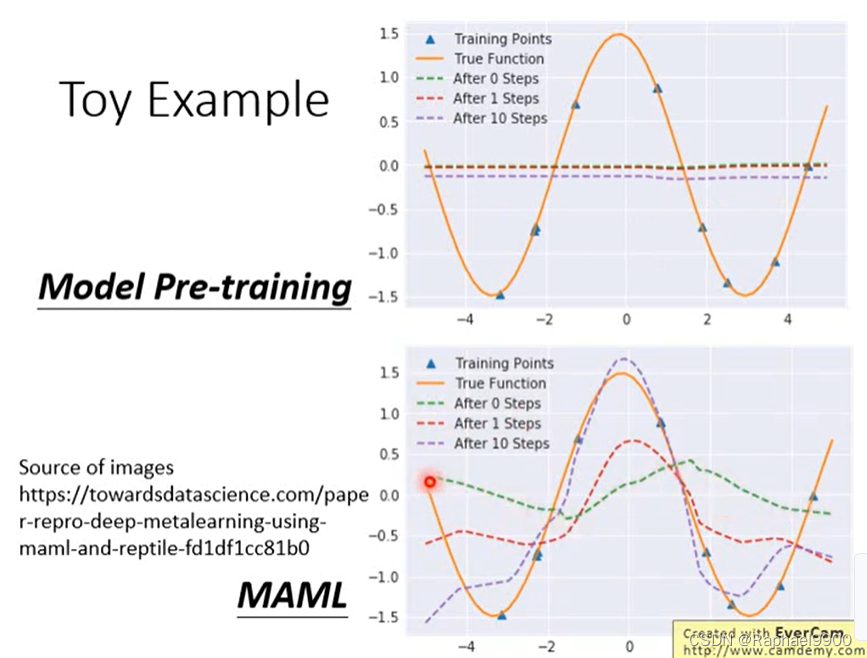
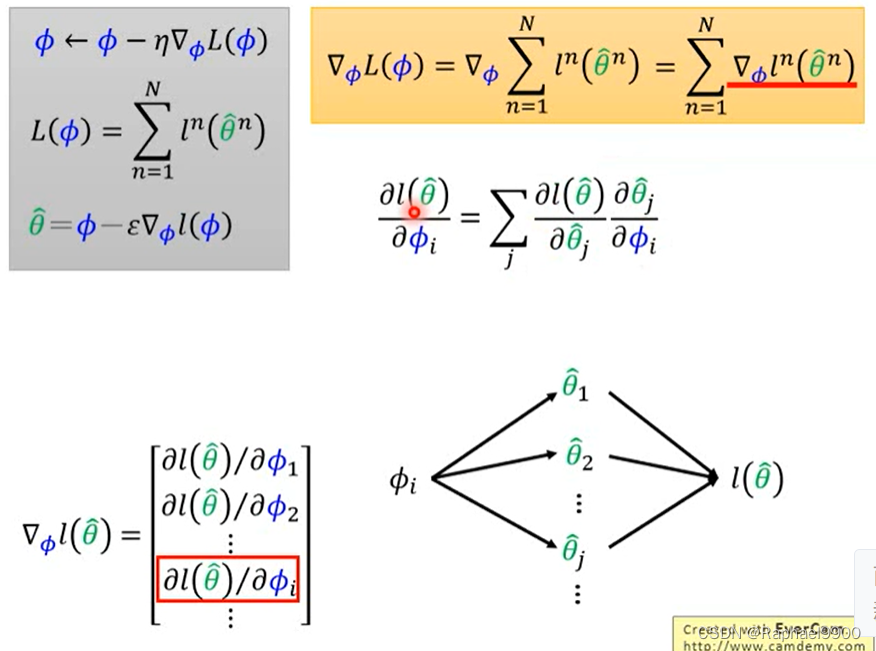
φi是初始参数


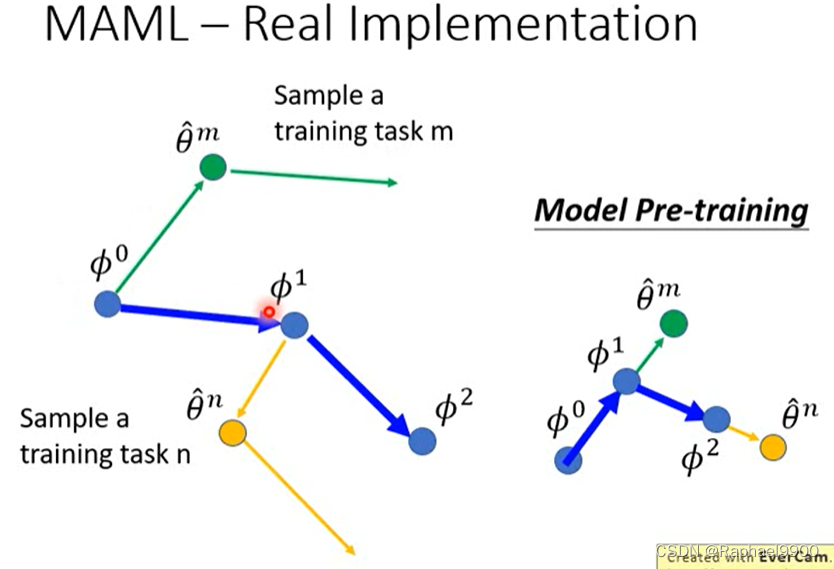
MAML是用两次更新的参数的方向来更新参数,预训练用的是每步更新参数的方向来更新参数。
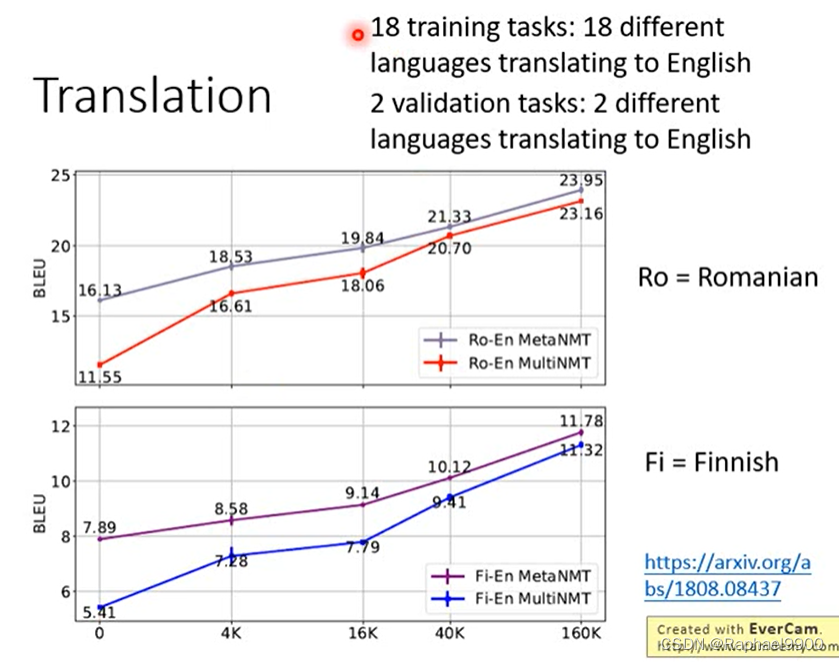
上面的元学习比预训练好。