RAG模型已经取得了显著的进展,但其性能仍然受到排序质量的限制。在实践中,我们发现重排序技术能够有效地改善排序的效果,从而进一步提升RAG模型在问答任务中的表现。
重排序的作用
与传统的嵌入模型不同,重排序器(reranker)直接以问题和文档作为输入,并输出相似度,而不是嵌入。通过将查询和文段输入到重排序器中,您可以获得相关性分数。重排序器基于交叉熵损失进行优化,因此相关性分数不限于特定范围。
unsetunsetFlagEmbeddingunsetunset
https://github.com/FlagOpen/FlagEmbedding
在FlagEmbedding中,重点放在了检索增强的语言模型上,目前包括以下项目:
-
语言模型微调(Fine-tuning of LM)
-
嵌入模型(Embedding Model)
-
重排序模型(Reranker Model)
pip install -U FlagEmbedding
如下是一个rerank的例子,获取相关性分数(较高的分数表示更高的相关性):
from FlagEmbedding import FlagReranker
# 初始化重排序器,您可以选择是否启用混合精度以加快计算速度
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True)
# 单个查询和文段的相关性分数
score = reranker.compute_score(['query', 'passage'])
print(score)
# 批量查询和文段的相关性分数
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
也可以直接通过transformers使用:
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
unsetunsetReRank原理unsetunset
跨编码器(Cross-encoder)采用全注意力机制对输入文本对进行完整关注,相比嵌入模型(例如双编码器),其精度更高,但也更耗时。因此,它可以用于重新排列嵌入模型返回的前k个文档,从而提高排序的准确性。
跨编码器的引入为多语言文本检索任务带来了更加准确和高效的解决方案。通过在全文本对上进行完整关注,跨编码器能够更好地理解语义信息,从而提高了排序的精度。
基础ReRank模型
基础的ReRank模型本质是一个序列分类模型,旨在对输入的文本对进行分类。它基于预训练的Transformer架构,通常是BERT、RoBERTa或类似的模型,其中编码器部分对输入文本进行编码,而解码器部分则用于分类任务。
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-v2-m3', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score) # -5.65234375
# You can map the scores into 0-1 by set "normalize=True", which will apply sigmoid function to the score
score = reranker.compute_score(['query', 'passage'], normalize=True)
print(score) # 0.003497010252573502
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores) # [-8.1875, 5.26171875]
# You can map the scores into 0-1 by set "normalize=True", which will apply sigmoid function to the score
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']], normalize=True)
print(scores) # [0.00027803096387751553, 0.9948403768236574]
LLM-based reranker
LLM-based reranker的思路,其主要思想是利用预训练的语言模型来对查询和文档进行编码,并根据编码结果生成相应的分数,以评估它们之间的相关性。
预设定的提示词如下:
Given a query A and a passage B, determine whether the passage contains an answer to the query by providing a prediction of either ‘Yes’ or ‘No’.
from FlagEmbedding import FlagLLMReranker
reranker = FlagLLMReranker('BAAI/bge-reranker-v2-gemma', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
# reranker = FlagLLMReranker('BAAI/bge-reranker-v2-gemma', use_bf16=True) # You can also set use_bf16=True to speed up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
LLM-based layerwise reranker
based layerwise reranker是一种基于语言模型的重排序器,它允许您选择特定层的输出来计算分数,以加速推断过程并适应多语言环境。
from FlagEmbedding import LayerWiseFlagLLMReranker
reranker = LayerWiseFlagLLMReranker('BAAI/bge-reranker-v2-minicpm-layerwise', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
# reranker = LayerWiseFlagLLMReranker('BAAI/bge-reranker-v2-minicpm-layerwise', use_bf16=True) # You can also set use_bf16=True to speed up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'], cutoff_layers=[28]) # Adjusting 'cutoff_layers' to pick which layers are used for computing the score.
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']], cutoff_layers=[28])
print(scores)
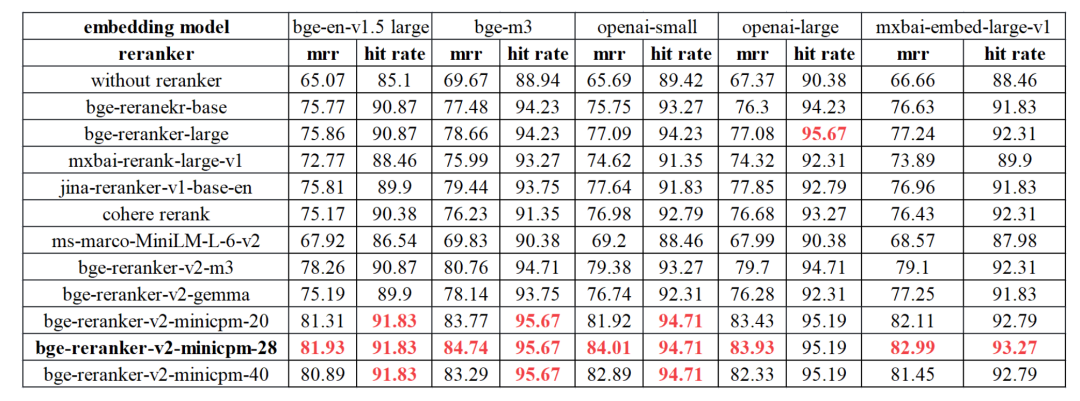
unsetunset模型精度对比unsetunset
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:技术交流
用通俗易懂方式讲解系列
- 用通俗易懂的方式讲解:自然语言处理初学者指南(附1000页的PPT讲解)
- 用通俗易懂的方式讲解:1.6万字全面掌握 BERT
- 用通俗易懂的方式讲解:NLP 这样学习才是正确路线
- 用通俗易懂的方式讲解:28张图全解深度学习知识!
- 用通俗易懂的方式讲解:不用再找了,这就是 NLP 方向最全面试题库
- 用通俗易懂的方式讲解:实体关系抽取入门教程
- 用通俗易懂的方式讲解:灵魂 20 问帮你彻底搞定Transformer
- 用通俗易懂的方式讲解:图解 Transformer 架构
- 用通俗易懂的方式讲解:大模型算法面经指南(附答案)
- 用通俗易懂的方式讲解:十分钟部署清华 ChatGLM-6B,实测效果超预期
- 用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
- 用通俗易懂的方式讲解:如何用大语言模型构建一个知识问答系统
- 用通俗易懂的方式讲解:最全的大模型 RAG 技术概览
- 用通俗易懂的方式讲解:利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
- 用通俗易懂的方式讲解:使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
- 用通俗易懂的方式讲解:面了 5 家知名企业的NLP算法岗(大模型方向),被考倒了。。。。。
- 用通俗易懂的方式讲解:NLP 算法实习岗,对我后续找工作太重要了!。
- 用通俗易懂的方式讲解:理想汽车大模型算法工程师面试,被问的瑟瑟发抖。。。。
- 用通俗易懂的方式讲解:基于 Langchain-Chatchat,我搭建了一个本地知识库问答系统
- 用通俗易懂的方式讲解:面试字节大模型算法岗(实习)
- 用通俗易懂的方式讲解:大模型算法岗(含实习)最走心的总结
- 用通俗易懂的方式讲解:大模型微调方法汇总