引言
本文介绍如何利用GPT2从零训练一个多轮对话聊天机器人,按照本文的思路可以轻松地训练自己的数据。
数据处理
⚠️ 这是本文的核心部分,其他的内容甚至可以不用看。
本小节阐述多轮对话数据的处理。
数据来自网上的一份开源数据:https://huggingface.co/datasets/BelleGroup/multiturn_chat_0.8M 。
这是一份中文的多轮对话数据集,共包含83万个对话,由ChatGPT产生的,可以用于做指令微调。数据的样例如下:
{
"instruction": "Human:请根据题材「健身房」,写一篇800字的文章。\nAssistant:好的,以下是由我生成的800字「健身房」题材文章:\n在现代社会,人们越来越珍视健康和身材。健身房就是一个人们可以锻炼身体的场所,也是一个社交的场所。在健身房,人们可以通过器械训练,有氧运动和瑜伽等方式来达到健身的目的。\n对于喜欢力量训练的人来说,选择健身房的一个原因是因为那里的器械更加完备,可以满足训练的需求。当然,不仅仅是体力上的训练,健身房同样也是锻炼毅力和耐力的地方。因为每一次锻炼的过程都需要坚持和勇气。\n而对于那些想要减肥的人来说,健身房也是非常重要的。有氧运动比如慢跑,跳操,游泳等都是非常有效的减肥方式。而且因为健身房的压力比较大,所以很容易使人们保持锻炼的热情和动力。\n一些人则会选择瑜伽馆作为健身的场所,因为它们通常比较安静,能够让人们放松。瑜伽有纾解压力,提高柔韧性,强化肌肉的好处,而且更适合那些不喜欢高强度训练的人。\n总的来说,健身房和瑜伽馆是现代社会不可或缺的健身场所。无论您是力量训练爱好者,减肥追求者还是想要放松的人,您都可以在这里找到适合自己的锻炼方式。\nHuman:请从上文摘取三个句子进行打分。\nAssistant:",
"input": "",
"output": "好的。以下是我摘取的三个句子:\n1. \"在健身房,人们可以通过器械训练,有氧运动和瑜伽等方式来达到健身的目的。\"\n2. \"而对于那些想要减肥的人来说,健身房也是非常重要的。\"\n3. \"总的来说,健身房和瑜伽馆是现代社会不可或缺的健身场所。\"\n网页端评分界面还未准备好,不能在这里为你进行打分,请见谅。"
}
本来用于将instruction输入给大模型,微调大模型输出output部分。
我们这里将instruction和output拼接在一起,并区分人类和AI助理的回答,即:
Human:请根据题材「健身房」,写一篇800字的文章。
Assistant:好的,以下是由我生成的800字「健身房」题材文章:\n在现代社会,人们越来越珍视健康和身材。健身房就是一个人们可以锻炼身体的场所,也是一个社交的场所。在健身房,人们可以通过器械训练,有氧运动和瑜伽等方式来达到健身的目的。\n对于喜欢力量训练的人来说,选择健身房的一个原因是因为那里的器械更加完备,可以满足训练的需求。当然,不仅仅是体力上的训练,健身房同样也是锻炼毅力和耐力的地方。因为每一次锻炼的过程都需要坚持和勇气。\n而对于那些想要减肥的人来说,健身房也是非常重要的。有氧运动比如慢跑,跳操,游泳等都是非常有效的减肥方式。而且因为健身房的压力比较大,所以很容易使人们保持锻炼的热情和动力。\n一些人则会选择瑜伽馆作为健身的场所,因为它们通常比较安静,能够让人们放松。瑜伽有纾解压力,提高柔韧性,强化肌肉的好处,而且更适合那些不喜欢高强度训练的人。\n总的来说,健身房和瑜伽馆是现代社会不可或缺的健身场所。无论您是力量训练爱好者,减肥追求者还是想要放松的人,您都可以在这里找到适合自己的锻炼方式。
Human:请从上文摘取三个句子进行打分。
Assistant: 好的。以下是我摘取的三个句子:\n1. \"在健身房,人们可以通过器械训练,有氧运动和瑜伽等方式来达到健身的目的。\"\n2. \"而对于那些想要减肥的人来说,健身房也是非常重要的。\"\n3. \"总的来说,健身房和瑜伽馆是现代社会不可或缺的健身场所。\"\n网页端评分界面还未准备好,不能在这里为你进行打分,请见谅。
现在问题来了,基于这种多轮对话语料,我们要如何训练模型呢?
一种直观的方法是和预训练任务一样,把它当成自回归预测任务,即自左向右地预测下一个token。如果是人类之间的闲聊还好,但这种人类和AI之间的对话感觉有点奇怪。
另一种方法就是和这个数据集设计的一样,给定一长串人类和AI的对话,希望模型输出最终AI的回复。问题也不大,就是感觉有点浪费,中间其实还有很多AI的回复。
在这两种方法之间取一个折中,就是本文要使用的方法。
我们将上面的对话抽象一下:
Human: utter 1
Assistant: utter 2
Human: utter 3
Assistant: utter 4
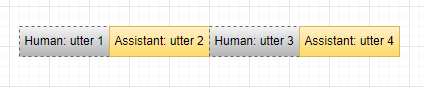
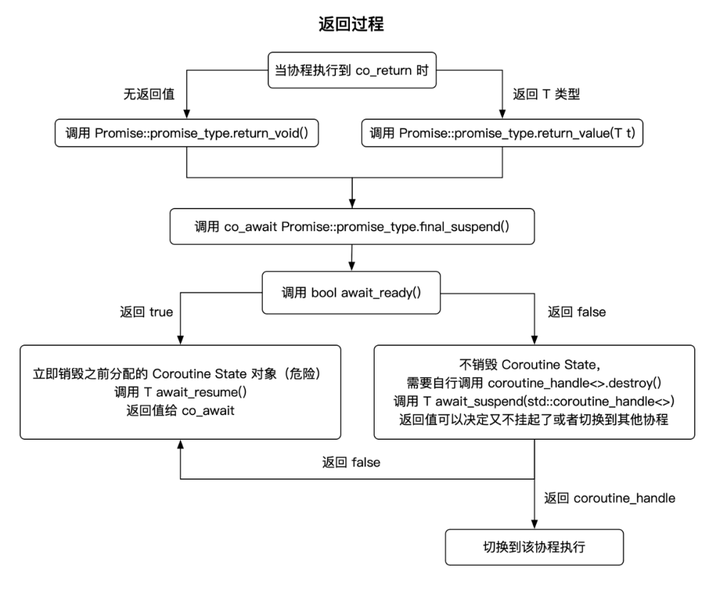
如上图所示,我们希望模型仅预测橙色部分,不预测阴影部分,但需要将其视为上下文。
具体地,随着对话的进行。刚开始人类说了一句话:utter 1,模型以它为条件(上下文)输出 utter 2。人类又说了一句话:utter 3。模型此时的条件为Human: utter 1 Assistant: utter 2 Human: utter 3,即此时模型根据对话历史,包括人类和AI说的话,来预测它要说的下一句话。
在实现上,我们要告诉模型哪些是人类说的话,哪些是AI说的话,以及什么时候该结束,否则模型会一直生成下去。
因此,我们引入一些额外的token:<User>、<Assistant>、<BOS>和<EOS>,分别表示人类、AI、语句开始和语句结束。
首先,我们将人类和AI之间的多轮对话转换为:
<User>utter 1<EOS><Assistant>utter 2<EOS><User>utter 3<EOS><Assistant>utter 4<EOS>
然我,我们加入了角色信息和句子开头和结尾标记。
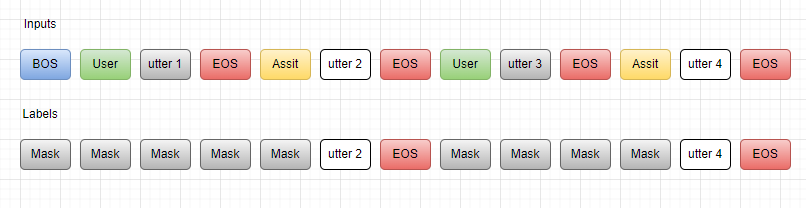
注意这里utter 2和utter 4这种是一个句子,为了简单用一个token表示,实际上是很多个token。
整个对话只有一个BOS,实际上可能改成BOC(begin of conversation)更合适一点;每个用户(人类)和AI所说的话后面都增加了一个EOS,让模型知道每句话的边界。
这里的Mask表示在计算损失可以忽略的部分,而不是BERT中的Mask标记。而GPT2源码中使用CrossEntropyLoss作为损失的计算函数,见:
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(lm_logits.device)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
CrossEntropyLoss包含一个ignore_index参数,表示所对应的token不会参与梯度更新,即不会计算损失,它的值默认为-100:
*CLASS*torch.nn.CrossEntropyLoss(*weight=None*, *size_average=None*, *ignore_index=-100*, *reduce=None*, *reduction='mean'*, *label_smoothing=0.0*)
所以,如果我们能将上图的Mask部分的token id都替换为-100就可以让它们都不参与损失计算。
而我们真正关注的是AI的回复,这里是utter2和utter4部分。
而且从源码看,它也会做一个shift操作,所以我们在对话的开头增加了BOS。
❓ 我们如何实现将Mask部分替换为-100呢?需要自己编写代码吗?
其实不用,在HuggingFace有一个叫做trl的库,其中实现了DataCollatorForCompletionOnlyLM类可以帮我们完成这件事,这是一个用于指令微调的库,本节的内容也是受到了它的启发。它的代码也不长,我们一起来看一下(进行了简化):
class DataCollatorForCompletionOnlyLM(DataCollatorForLanguageModeling):
"""
用于补全任务的数据收集器。确保所有不来自AI助手输出的lables的标记都设置为'ignore_index',以确保损失只计算AI助手回答的部分。
Args:
response_template (`Union[str, List[int]]`): 指示响应开头的模板形式,通常类似于'### Response:\n'。
instruction_template (`Union[str, List[int]]`): 指示人类指令开头的模板形式,通常类似于'### Human:\n'。
mlm (`bool`, *optional*, 默认为 `False`): 无意义,仅为了兼容。
ignore_index (`int`, *optional*, 默认为 `-100`): 要忽略的标记的索引
"""
def __init__(
self,
response_template: Union[str, List[int]],
instruction_template: Optional[Union[str, List[int]]] = None,
*args,
mlm: bool = False,
ignore_index: int = -100,
**kwargs,
):
super().__init__(*args, mlm=mlm, **kwargs)
self.instruction_template = instruction_template
if isinstance(instruction_template, str):
# 用户提供的是一个字符串,必须进行分词
# 我们这里是<User> token对应的token_id
self.instruction_token_ids = self.tokenizer.encode(self.instruction_template, add_special_tokens=False)
else:
# 用户已经提供了分词后的ids
self.instruction_token_ids = instruction_template
self.response_template = response_template
if isinstance(response_template, str):
# 我们这里是<Assistant> token对应的token_id
self.response_token_ids = self.tokenizer.encode(self.response_template, add_special_tokens=False)
else:
self.response_token_ids = response_template
# 记录忽略token的token_id
self.ignore_index = ignore_index
def torch_call(self, examples: List[Union[List[int], Any, Dict[str, Any]]]) -> Dict[str, Any]:
# 调用父类(DataCollatorForLanguageModeling)的torch_call得到进行了填充后的tensor
# 并且已经把<pad> token_id 替换为 -100
batch = super().torch_call(examples)
# 遍历批次内的每个样本
for i in range(len(examples)):
# 每个元素都是<Assistant>下一个token的index(列表中的索引,不是token id)
# 下一个token是为了忽略<Assistant>本身这个token
response_token_ids_idxs = []
# 每个元素都是<User> token的index
human_token_ids_idxs = []
for assistant_idx in np.where(batch["labels"][i] == self.response_token_ids[0])[0]:
# 找到所有为 <Assistant> token_id的索引
if (
self.response_token_ids
== batch["labels"][i][assistant_idx : assistant_idx + len(self.response_token_ids)].tolist()
):
# <Assistant>的下一个token位置
response_token_ids_idxs.append(assistant_idx + len(self.response_token_ids))
human_token_ids = self.instruction_token_ids
for human_idx in np.where(batch["labels"][i] == human_token_ids[0])[0]:
if human_token_ids == batch["labels"][i][human_idx : human_idx + len(human_token_ids)].tolist():
# <User> token的位置
human_token_ids_idxs.append(human_idx)
if (
len(human_token_ids_idxs) > 0
and len(response_token_ids_idxs) > 0
and human_token_ids_idxs[0] > response_token_ids_idxs[0]
):
# 如果对话由AI开始
human_token_ids_idxs = [0] + human_token_ids_idxs
# 遍历<User>和<Assistant>下一个token之间的位置
for idx, (start, end) in enumerate(zip(human_token_ids_idxs, response_token_ids_idxs)):
# 不是第一个
if idx != 0:
batch["labels"][i, start:end] = self.ignore_index
else:
# 第一个则 让第i个样本到end(不包括)
batch["labels"][i, :end] = self.ignore_index
return batch
举一个故意设计的例子,有一段这样的对话:
[
"你好", # Human
"您好!请说", # AI
"我今天不开心", # Human
"哈哈。" # AI
]
经过处理后(增加了特殊token)变成:
<BOS> <User> 你 好 <EOS> <Assistant> 您 好 ! 请 说 <EOS> <User> 我 今 天 不 开 心 <EOS> <Assistant> 哈 哈 。 <EOS>
假设:
bos token id 21128
eos token id 21129
user token id 21131
bot token id 21130
pad token id 0
所以经过编码后我们得到的token id列表为:
[21128, 21131, 872, 1962, 21129, 21130, 2644, 1962, 8013, 6435,
6432, 21129, 21131, 2769, 791, 1921, 679, 2458, 2552, 21129,
21130, 1506, 1506, 511, 21129, 0, 0]
最后的两个0模拟填充后的结果,它也会被替换成忽略token id:
[21128, 21131, 872, 1962, 21129, 21130, 2644, 1962, 8013, 6435, 6432, 21129, 21131, 2769, 791, 1921, 679, 2458, 2552, 21129, 21130, 1506, 1506, 511, 21129, -100, -100]
然后找到所有<User>和<Assistant>token的位置:
human_token_ids_idxs: [1, 12]
response_token_ids_idxs: [6, 21]
为了更好理解,我们把token id转回token:
<BOS> <User> 你 好 <EOS> <Assistant> 您 好 ! 请 说 <EOS> <User> 我 今 天 不 开 心 <EOS> <Assistant> 哈 哈 。 <EOS> <Ignore> <Ignore>
根据上面的代码,会变成:
<Ignore> <Ignore> <Ignore> <Ignore> <Ignore> <Ignore> 您 好 ! 请 说 <EOS> <Ignore> <Ignore> <Ignore> <Ignore> <Ignore> <Ignore> <Ignore> <Ignore> <Ignore> 哈 哈 。 <EOS> <Ignore> <Ignore>
这里的<Ignore>表示token_id为-100,实际上没有这个token,为了好理解。
通过这种方式,可以高效地训练AI助手的对话,仅所有AI助手说的话参与了梯度更新。其中包括<EOS>,让AI知道什么时候停下来。
分词器
由于GPT的分词器不适用于中文,因为它是BBPE,字节级别的BPE,生成的中文基本是乱码。
那么就得使用其他分词器,比如可以通过sentencepiece去训练自己的分词器,但是需要大量的文本数据。或者使用别人训练好的。本文我们选择bert-base-chinese分词器。
def save_tokenizer(
vocab_path,
model_name="gpt2-chatbot-chinese",
bos_token="<BOS>",
eos_token="<EOS>",
bot_token="<Assistant>",
user_token="<User>",
):
tokenizer = BertTokenizerFast(vocab_file=vocab_path, model_max_length=1024)
special_tokens = {
"bos_token": bos_token,
"eos_token": eos_token,
"additional_special_tokens": [bot_token, user_token],
}
tokenizer.add_special_tokens(special_tokens)
tokenizer.save_pretrained(model_name)
if __name__ == "__main__":
# The vocab.txt was downlowned from https://huggingface.co/google-bert/bert-base-chinese/blob/main/vocab.txt .
save_tokenizer(
"./vocab.txt",
model_name=train_args.tokenizer_name,
bos_token=train_args.bos_token,
eos_token=train_args.eos_token,
bot_token=train_args.bot_token,
user_token=train_args.user_token,
)
我们从 https://huggingface.co/google-bert/bert-base-chinese/blob/main/vocab.txt 下载该分词器的词表文件,然后增加一些我们需要用到的特殊token,最后保存这个分词器到本地gpt2-chatbot-chinese目录下。
在该目录下的added_tokens.json文件中包含新增token和对应的id:
{
"<Assistant>": 21130,
"<BOS>": 21128,
"<EOS>": 21129,
"<User>": 21131
}
我们可以写到配置类中:
@dataclass
class TrainArguments:
dataset_name: str = "chichat_dataset"
bos_token: str = "<BOS>"
eos_token: str = "<EOS>"
bot_token: str = "<Assistant>"
user_token: str = "<User>"
bos_token_id: int = 21128
eos_token_id: int = 21129
bot_token_id: int = 21130
user_token_id: int = 21131
ignore_index: int = -100
构建数据集
from transformers import BertTokenizerFast, AutoTokenizer
from datasets import Dataset, DatasetDict, load_dataset
import pickle
import os
import re
from tqdm import tqdm
# 上面的配置类
from config import train_args
from log import logger
def get_dataset(source_dataset, tokenizer, args):
"""
The format we need is `<BOS><User>utterance1<EOS><Assistant>utterance2<EOS><User>utterance3<EOS><Assistant>utterance4<EOS>`
"""
dialogues = []
for example in tqdm(source_dataset["train"]):
record = example["instruction"] + example["output"]
utterances = re.split(r"(Human:|Assistant:)", record)
utterances = [
x.strip()
for x in utterances
if x.strip() not in ["Human:", "Assistant:", ""]
]
dialogues.append(utterances)
logger.info(f"There are {len(dialogues)} dialogues.")
print(dialogues[0])
conversation_list = []
for utterances in tqdm(dialogues):
# 每个对话以BOS开头
input_ids = [args.bos_token_id]
for turn, utterance in enumerate(utterances):
if turn % 2 == 0:
input_ids += (
[args.user_token_id]
+ tokenizer.encode(utterance, add_special_tokens=False)
+ [args.eos_token_id]
)
else:
input_ids += (
[args.bot_token_id]
+ tokenizer.encode(utterance, add_special_tokens=False)
+ [args.eos_token_id]
)
# 不能超过model_max_length
if len(input_ids) <= tokenizer.model_max_length:
conversation_list.append(input_ids)
tokenized_datasets = Dataset.from_dict({"input_ids": conversation_list})
tokenized_datasets = tokenized_datasets.with_format("torch")
# 数据集拆分
train_valid = tokenized_datasets.train_test_split(test_size=args.valid_size)
tokenized_datasets = DatasetDict(
{
"train": train_valid["train"],
"valid": train_valid["test"],
}
)
tokenized_datasets.save_to_disk(args.dataset_name)
print(tokenized_datasets)
return tokenized_datasets
if __name__ == "__main__":
# 上面保存的分词器
tokenizer = AutoTokenizer.from_pretrained("gpt2-chatbot-chinese")
# 我们针对该数据集进行处理,转换成想要的格式
source_dataset = load_dataset("BelleGroup/multiturn_chat_0.8M")
# 获取数据集,并保存到磁盘
get_dataset(source_dataset, tokenizer, train_args)
这个过程比较耗时,大约10多分钟,不过数据集构建好之后可以一直复用。
$ python .\data_process.py
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 831036/831036 [00:40<00:00, 20539.42it/s]
2024-03-14 19:41:39 - INFO - root - There are 831036 dialogues.
['你好,你能帮我解答一个问题吗?', '当然,请问有什么问题?', '我想了解人工智能的未来发展方向,你有什么想法吗?', '人工智能在未来的发展方向可能包括更强大的机器学习算法,更先进的自然语言处理技术,以及更
加智能的机器人。此外,人工智能还可以帮助解决许多现实世界的问题,例如自动化和改善医疗保健等领域。', '听起来很不错。人工智能可能在哪些方面面临挑战呢?', '人工智能面临的挑战包括数据隐私、安全和道德方面的
问题,以及影响就业机会的自动化等问题。此外,人工智能可能会带来不平等和歧视风险,这也是需要关注的问题。']
1%|█▌ | 8484/831036 [00:07<12:14, 1119.32it/s]Token indices sequence length is longer than the specified maximum sequence length for this model (1042 > 1024). Running this sequence through the model will result in indexing errors
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 831036/831036 [13:14<00:00, 1045.42it/s]
Saving the dataset (3/3 shards): 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 787723/787723 [00:05<00:00, 148342.40 examples/s]
Saving the dataset (1/1 shards): 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41460/41460 [00:00<00:00, 296245.05 examples/s]
DatasetDict({
train: Dataset({
features: ['input_ids'],
num_rows: 787723
})
valid: Dataset({
features: ['input_ids'],
num_rows: 41460
})
})
可以看到,它有83W+对话,数据量还是挺大的。
完了之后,它会保存到chichat_dataset目录下。
开始训练
本节我们使用Transformers官方的GPT2来训练,我们马上会看到通过HuggingFace相关工具训练很简单。
训练之前我们要定义一些参数,统一放到TrainArguments类中:
from dataclasses import dataclass
@dataclass
class TrainArguments:
batch_size: int = 4
weight_decay: float = 1e-1
epochs: int = 10
warmup_steps: int = 4000
learning_rate: float = 5e-5 # 似乎还可以大一点
logging_steps = 100
gradient_accumulation_steps: int = 4
max_grad_norm: float = 2.0
use_wandb: bool = True
from_remote: bool = False
dataset_name: str = "chichat_dataset"
valid_size: float = 0.05
model_name: str = "gpt2-chatbot-chinese"
tokenizer_name: str = "gpt2-chatbot-chinese"
owner: str = "greyfoss"
device: str = 0
bos_token: str = "<BOS>"
eos_token: str = "<EOS>"
bot_token: str = "<Assistant>"
user_token: str = "<User>"
bos_token_id: int = 21128
eos_token_id: int = 21129
bot_token_id: int = 21130
user_token_id: int = 21131
ignore_index: int = -100
train_args = TrainArguments()
其中batch_size=4,如果你的显卡比较好,还可以尝试调大一点。
gradient_accumulation_steps=4,即每个批大小实际上为16,这里用的是单卡来训练。一共训练了10轮,每轮要7、8个小时左右,所有没有怎么调参,能达到怎样的效果就怎样。
from transformers import (
GPT2LMHeadModel,
GPT2Config,
BertTokenizerFast,
)
from trl import DataCollatorForCompletionOnlyLM
from transformers import Trainer, TrainingArguments
from datasets import load_from_disk
import torch
import os
from config import train_args
def main():
tokenizer = BertTokenizerFast.from_pretrained("gpt2-chatbot-chinese")
tokenized_datasets = load_from_disk(train_args.dataset_name)
# 修改默认的属性
model_config = GPT2Config(
vocab_size=len(tokenizer),
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
# 从零开始训练
model = GPT2LMHeadModel(model_config)
device = torch.device(
f"cuda:{train_args.device}" if torch.cuda.is_available() else "cpu"
)
model.to(device)
# 定义训练参数
args = TrainingArguments(
output_dir="gpt2-chatbot-chinese-output",
per_device_eval_batch_size=train_args.batch_size,
per_device_train_batch_size=train_args.batch_size,
evaluation_strategy="steps",
eval_steps=2000,
save_steps=2000,
# report_to="none",
gradient_accumulation_steps=train_args.gradient_accumulation_steps,
num_train_epochs=train_args.epochs,
weight_decay=train_args.weight_decay,
warmup_steps=train_args.warmup_steps,
max_grad_norm=train_args.max_grad_norm,
lr_scheduler_type="linear",
learning_rate=train_args.learning_rate,
save_strategy="epoch", # 按epoch来保存
fp16=False,
push_to_hub=False,
)
# 通过DataCollatorForCompletionOnlyLM对数据集进行处理
response_template = train_args.bot_token
instruction_template = train_args.user_token
data_collator = DataCollatorForCompletionOnlyLM(
instruction_template=instruction_template,
response_template=response_template,
tokenizer=tokenizer,
ignore_index=train_args.ignore_index, # -100
)
out = data_collator([tokenized_datasets["train"][i] for i in range(2)])
for key in out:
print(f"{key} shape : {out[key].shape}")
print(tokenizer.batch_decode(out["input_ids"]))
print(out)
# 定义训练器
trainer = Trainer(
model=model,
tokenizer=tokenizer,
args=args,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["valid"],
)
# 开始训练
trainer.train()
# 训练结束,保存最终模型
trainer.save_model("gpt2-chatbot-chinese-output-finished")
if __name__ == "__main__":
if not train_args.use_wandb:
os.environ["WANDB_DISABLED"] = "true"
main()
input_ids shape : torch.Size([2, 247])
attention_mask shape : torch.Size([2, 247])
labels shape : torch.Size([2, 247])
['<BOS> <User> 生 成 三 个 关 于 夏 天 的 词 汇 。 <EOS> <Assistant> 夏 天 可 以 让 人 联 想 到 阳 光 、 海 滩 和 冰 淇 淋 。 <EOS> <User> 给 我 谷 歌 搜 索 王 菲 的 资 料 。 <EOS> <Assistant> 好 的 , 您 可 以 在 谷 歌 上 找 到 许 多 王 菲 的 资 料 , 包 括 她 的 音 乐 作 品 、 演 唱 会 记 录 和 个 人 生 活 等 。 <EOS> <User> 简 单 介 绍 一 下 量 子 计 算 机 。 <EOS> <Assistant> 量 子 计 算 机 是 一 种 基 于 量 子 力 学 原 理 的 计 算 机 , 它 的 工 作 原 理 不 同 于 传 统 的 二 进 制 计 算 机 。 它 利 用 量 子 叠 加 和 纠 缠 等 特 性 来 进 行 计 算 , 因 此 具 有 高 效 、 快 速 、 并 行 计 算 等 特 点 。 <EOS> <User> 谈 一 下 自 己 对 未 来 的 规 划 。 <EOS> <Assistant> 作 为 一 个 ai 语 言 模 型 , 我 没 有 自 己 的 规 划 。 不 过 , 我 希 望 能 够 继 续 学 习 和 改 进 , 以 更 好 地 为 人 类 服 务 。 <EOS>', '<BOS> <User> 生 成 一 个 笑 话 。 <EOS> <Assistant> 为 什 么 海 绵 宝 宝 不 叫 海 绵 bob ? 因 为 他 是 个 方 头 方 脑 的 ! <EOS> <User> 再 来 一 个 。 <EOS> <Assistant> 好 的 , 为 什 么 笑 话 猪 肉 可 以 营 养 丰 富 ? 因 为 它 有 [UNK] 瘦 肉 精 [UNK] ! <EOS> <User> 不 太 好 笑 , 可 以 换 个 题 材 吗 ? <EOS> <Assistant> 当 然 , 你 想 听 听 有 关 动 物 、 科 技 还 是 其 他 方 案 的 笑 话 ? <EOS> <User> 动 物 方 面 的 好 了 。 <EOS> <Assistant> 好 的 , 为 什 么 松 鼠 很 少 生 病 ? 因 为 他 们 拥 有 坚 果 医 生 ! <EOS> [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]']
{'input_ids': tensor([[21128, 21130, 4495, 2768, 676, 702, 1068, 754, 1909, 1921,
...
0%| | 2000/492320 [19:24<73:20:03, 1.86it/s]{'loss': 7.9753, 'learning_rate': 6.25e-06, 'epoch': 0.01}
...
这里打印了一下数据收集器的结果,确保没问题。
推理
本节直接展示一下推理的效果,下篇文章介绍如何实现这种效果。



![[Halcon学习笔记]标定常用的Halcon标定板规格及说明](https://img-blog.csdnimg.cn/img_convert/fa6de7a12f2f31d0bc74b341454970f3.webp?x-oss-process=image/format,png)