如果对你有用的话,希望能够点赞支持一下,这样我就能有更多的动力更新更多的学习笔记了。😄😄
使用Alexnet进行CIFAR-10数据集进行测试,这里使用的是将CIFAR-10数据集的分辨率扩大到224X224,因为在测试训练的时候,发现将CIFAR10数据集的分辨率拉大可以让模型更快地进行收敛,并且识别的效果也是比低分辨率的更加好。
首先来介绍一下,Alexnet:
1.论文下载地址:http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf
2.Alexnet的历史地位:
①在ILSVRC-2010和ILSVRC-2012比赛中,使用ImageNet数据集的一个子集,训练了一个最大的卷积神经网络,并且在该数据集取得相对于现在来说很好的结果。
②完成高度优化的GPU实现,用于2D卷积和训练神经网络的操作,并将其公开。
③使用了一些技巧(ReLu、多块GPU并行训练、局部响应归一化、Overlapping池化、Dropout等),能够改善性能、减少训练时间。
3.Alexnet的网络结构图(使用了两个GPU,所以网络的结构是分开进行画出来的):

4.代码实现:
数据集的处理:
调用torchvision里面封装好的数据集(CIFAR10)进行数据的训练,并且利用官方已经做好的数据集分类(using 50000 images for training, 10000 images for validation)是数据集的划分大小。进行了一些简单的数据增强,分别是随机的随机剪切和随机的水平拉伸操作。
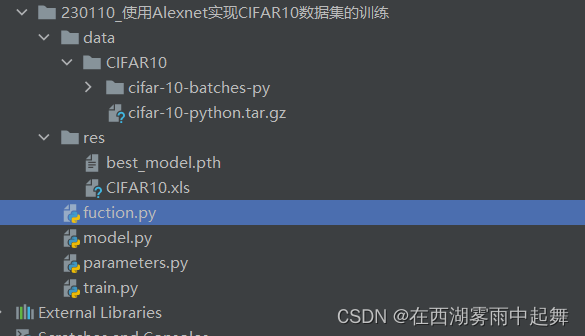
模型的代码结构目录:

data:进行模型训练的时候会自动开始下载数据集的信息到这个文件夹里面。
res:该文件夹会保存模型的权重和记录模型在训练过程当中计算出来的train_loss, train_acc和val_acc做成的xml文件夹。
train.py代码如下:
import torchvision
from model import AlexNet
import os
import parameters
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
from tqdm import tqdm
from fuction import writer_into_excel_onlyval
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
epochs = parameters.epoch
save_model = parameters.alexnet_save_model
save_path = parameters.alexnet_save_path_CIFAR10
data_transform = {
# 进行数据增强的处理
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
}
train_dataset = torchvision.datasets.CIFAR10(root='./data/CIFAR10', train=True,
download=True, transform=data_transform["train"])
val_dataset = torchvision.datasets.CIFAR10(root='./data/CIFAR10', train=False,
download=False, transform=data_transform["val"])
train_num = len(train_dataset)
val_num = len(val_dataset)
print("using {} images for training, {} images for validation.".format(train_num, val_num))
batch_size = parameters.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=nw,
)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=nw,
)
model = AlexNet(num_classes=parameters.CIFAR10_class)
model.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=parameters.alexnet_lr)
best_acc = 0.0
# 记录训练产生的数据
train_acc_list = []
train_loss_list = []
val_acc_list = []
for epoch in range(epochs):
# train
model.train()
running_loss_train = 0.0
train_accurate = 0.0
train_bar = tqdm(train_loader)
for images, labels in train_bar:
optimizer.zero_grad()
outputs = model(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
predict = torch.max(outputs, dim=1)[1]
train_accurate += torch.eq(predict, labels.to(device)).sum().item()
running_loss_train += loss.item()
train_accurate = train_accurate / train_num
running_loss_train = running_loss_train / train_num
train_acc_list.append(train_accurate)
train_loss_list.append(running_loss_train)
print('[epoch %d] train_loss: %.7f train_accuracy: %.3f' %
(epoch + 1, running_loss_train, train_accurate))
# validate
model.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_loader = tqdm(val_loader)
for val_data in val_loader:
val_images, val_labels = val_data
outputs = model(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
val_acc_list.append(val_accurate)
print('[epoch %d] val_accuracy: %.3f' %
(epoch + 1, val_accurate))
writer_into_excel_onlyval(save_path, train_loss_list, train_acc_list, val_acc_list, "CIFAR10")
# 选择最好的模型进行保存,此处的评价指标是acc
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(model.state_dict(), save_model)
if __name__ == '__main__':
main()
parameters.py代码如下:
# -*- coding:utf-8 -*-
# @Time : 2023-01-10 19:12
# @Author : DaFuChen
# @File : CSDN写作代码笔记
# @software: PyCharm
# 训练的次数
epoch = 2
# 训练的批次大小
batch_size = 4
# 数据集的分类类别数量
CIFAR10_class = 10
# 模型训练时候的学习率大小
alexnet_lr = 0.002
# 保存模型权重的路径 保存xml文件的路径
alexnet_save_path_CIFAR10 = './res/'
alexnet_save_model = './res/best_model.pth'
model.py代码如下:
# -*- coding:utf-8 -*-
# @Time : 2023-01-10 19:08
# @Author : DaFuChen
# @File : CSDN写作代码笔记
# @software: PyCharm
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(48, 128, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(128, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
# output[128, 6, 6]
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
fuction代码如下:
# -*- coding:utf-8 -*-
# @Time : 2023-01-10 19:09
# @Author : DaFuChen
# @File : CSDN写作代码笔记
# @software: PyCharm
import xlwt
def writer_into_excel_onlyval(excel_path,loss_train_list, acc_train_list, val_acc_list,dataset_name:str=""):
workbook = xlwt.Workbook(encoding='utf-8') # 设置一个workbook,其编码是utf-8
worksheet = workbook.add_sheet("sheet1", cell_overwrite_ok=True) # 新增一个sheet
worksheet.write(0, 0, label='Train_loss')
worksheet.write(0, 1, label='Train_acc')
worksheet.write(0, 2, label='Val_acc')
for i in range(len(loss_train_list)): # 循环将a和b列表的数据插入至excel
worksheet.write(i + 1, 0, label=loss_train_list[i]) # 切片的原来是传进来的Imgs是一个路径的信息
worksheet.write(i + 1, 1, label=acc_train_list[i])
worksheet.write(i + 1, 2, label=val_acc_list[i])
workbook.save(excel_path + str(dataset_name) +".xls") # 这里save需要特别注意,文件格式只能是xls,不能是xlsx,不然会报错
print('save success! .')
最后的实验结果保存:
其中部分参数,例如是学习率的大小,训练的批次大小,数据增强的一些小参数,可以根据自己的经验和算力的现实情况进行调整。
如果对你有用的话,希望能够点赞支持一下,这样我就能有更多的动力更新更多的学习笔记了。😄😄