hashmap专题
- 常见map
- hashMap
- jdk1.8HashMap新变化
- hashmap源码中重要的常量
- 存储结构
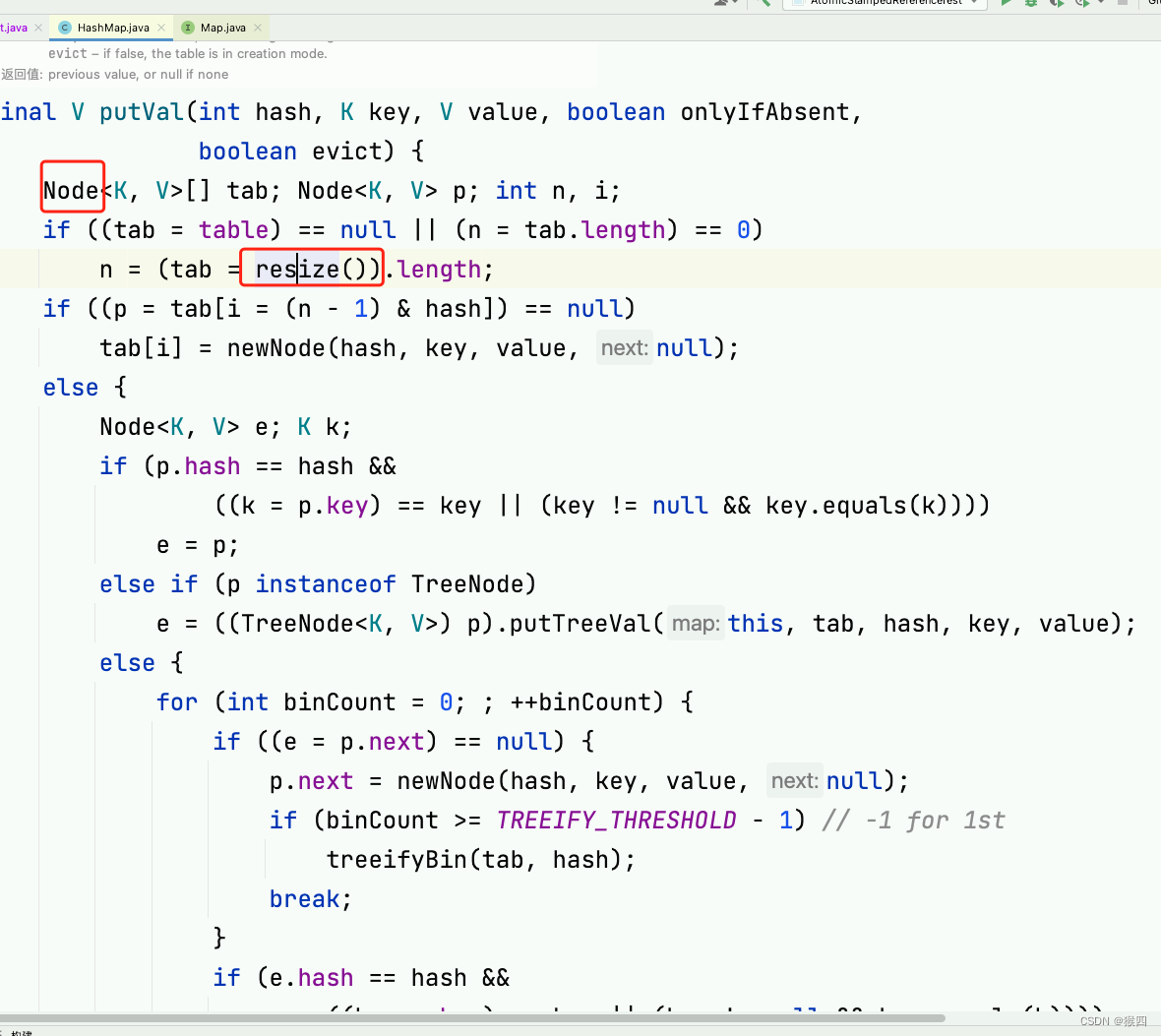
- put 存入数据过程
- 取数据过程get()
- 扩容
- hashmap 树化/链化
- hashmap的容量 桶的数量为什么要是2的n次方?
- hashmap为什么线程不安全
常见map
- hashtable线程安全,但效率太低。
- hashmap 线程不安全。
- LinkedHashMap线程也不安全
- ConcurrentHashMap线程安全
hashMap
hashmap的数据结构有数组和链表来实现对数据的存储,但这2个基本上是两个极端。
- 数组:数组的存储区是连续的,占用内存比较严重,故空间复杂度很大,但因其地址连续,查找很快。数组的特点就是,寻址容易,插入和删除困难。
- 链表 链表的存储区离散,占用内存比较宽容,故空间复杂度小,但时间复杂度大(因其内存地址不连续,查找会慢),链表的特点:寻址慢,插入和删除容易
JDK7及以前版本,hashmap是数组+链表结构,
JDK8以后,Hashmap是数组+链表+红黑树
jdk1.8HashMap新变化
- HashMap map = new HashMap();//默认情况下,先不创建长度为16的数组。
- 当首次调用map.put()时,在创建长度为16的数组 。
- 数组为Node类型,在jdk17中称为Entry数组。
- 当数组指定索引位置的链表长度>8时,且map中的数组长度>64时,此索引位置上的所有key-value对使用红黑树进行存储。
hashmap源码中重要的常量
- DEFAULT_INITIAL_CAPACITY : 默认16,HashMap的默认容量
- MAXIMUM_CAPACITY :默认2^30, HashMap的最大支持容量
- DEFAULT_LOAD_FACTOR:默认0.75, HashMap的默认加载因子
- TREEIFY_THRESHOLD:默认8 Bucket中链表长度大于该默认值,转化为红黑树
- UNTREEIFY_THRESHOLD: 默认6,Bucket中红黑树存储的Node小于该默认值,转化为链表
- MIN_TREEIFY_CAPACITY: 默认64,桶中的Node被树化时最小的hash表容量。(当桶中Node的数量大到需要变红黑树时,若hash表容量小于MIN_TREEIFY_CAPACITY时,此时应执行resize扩容操作这个MIN_TREEIFY_CAPACITY的值至少是TREEIFY_THRESHOLD的4倍。)
- table: 存储元素的数组,总是2的n次幂
存储结构
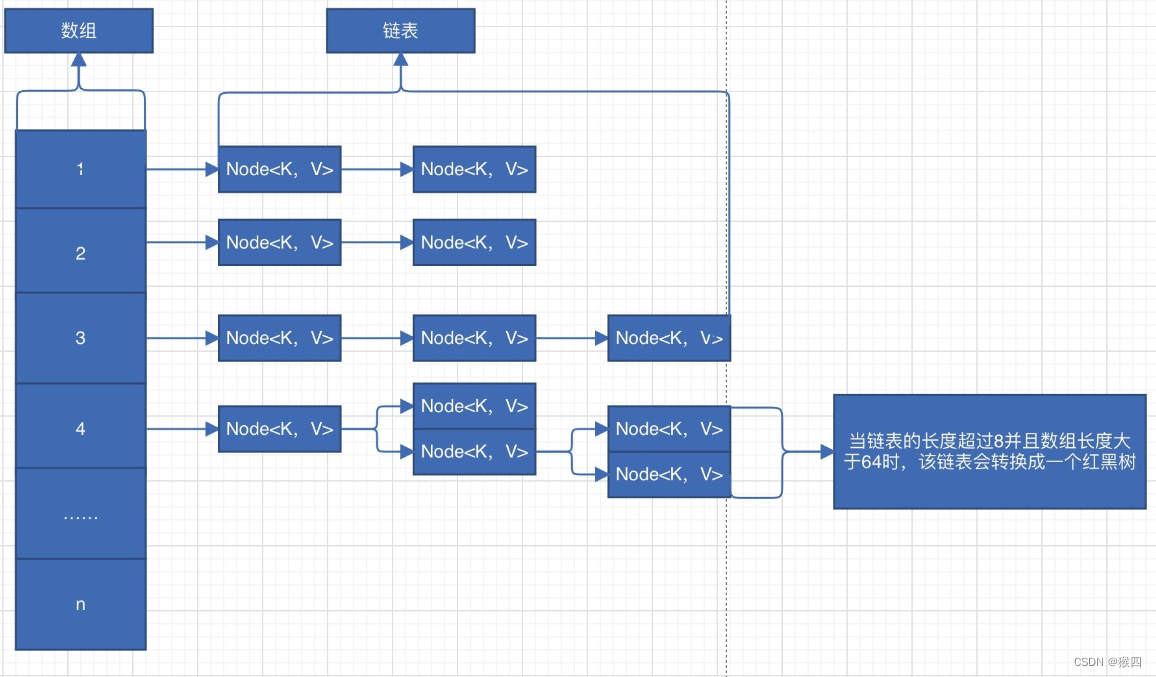
在jdk1.8后,内部数据结构使用数组+链表+红黑树进行存储。
- 数组类型为Node[],每个Node都保存了某个KV键值对元素的key、value、hash、next等值。
- 链表 他由一系列节点组成,每个节点包含两部分:数据和指向下一个节点的指针。
- 当链表的长度超过8并且数组长度大于64,为了避免查找搜索性能下降,该链表会转换成一个红黑树。
put 存入数据过程
- hashmap在存储数据时,会将key和value封装在一个Node[]
- 调用key的hashcode()方法获取key的哈希码。
- 通过转换算法将其转换为数组的下标。
- 当数组下标没有值,就直接将此Node[]放在这个下标
- 当数组下标下有值,就会将key和链表上的每一个值进行比较
- 如果equal()都返回false则将其加入链表最后
- 如果equal()和链表某个节点返回true则将其节点进行覆盖
取数据过程get()
- 根据key的值算出hashcode
- 通过转换算法将其转换为数组的下标
- 如果当前下标为null则直接返回空
- 如果当前下标是链表,会使用equal()方法和链表上的节点进行比较
- 如果都返回false则返回空
- 如果有一个节点为true则返回当前节点的值
扩容
- loadFactor 负载因子,默认值0.75
当Hashmap中的元素个数超过数组大小(数组总大小length,不是数组中个数size)loadFactor 时,就 会 进 行 数 组 扩 容 , loadFactor 的 默 认 值(DEFAULT_LOAD_FACTOR)为0.75, 这是一个折中的取值。 也就是说, 默认情况下, 数组大小(DEFAULT_INITIAL_CAPACITY)为16, 那么当HashMap中元素个数超过160.75=12(这个值就是代码中的threshold值, 也叫做临界值)的时候, 就把数组的大小扩展为 2*16=32, 即扩大一倍, 然后重新计算每个元素在数组中的位置, 而这是一个非常消耗性能的操作, 所以如果我们已经预知HashMap中元素的个数, 那么预设元素的个数能够有效的提高HashMap的性能。
hashmap 树化/链化
当hashmap中的其中一个链表的对象个数达到了8个,此时如果capacity没有达到64个,那么hashmap会先扩容解决,如果已经达到了64,那么这个链会变成树,节点类型由Node变成treeNode类型。当然,如果当映射关系被移除后,下次resize方法时判断树的节点小于6个,也会把树在转换为链表。
hashmap的容量 桶的数量为什么要是2的n次方?
HashMap为了存取高效,要尽量较少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同。
关键就在于把当前数据存放到哪一个桶中,这个算法就是取模运算。
假设: length:HashMap的容量 hash:当前key的哈希值 取模运算为 hash % length
但是,在计算机中,直接取模运算的效率不如位运算(&),什么是位运算?就是对于二进制数据的按位运算,1和1才得1,其他都得0,比如:1011
& 1100 = 1000
sun公司的大牛们发现,当容量为2的n次方时,hash & (length - 1) == hash % length
,于是就在源码中做了优化,通过 hash & (length - 1) 来替代取模运算,而前提就是容量必须为2的n次方。这样做的好处在于:提高操作运算效率(位运算效率 > 取模运算效率) 减少碰撞,数据均匀分布,提高HashMap查询效率
为什么可以减少碰撞?
举个例子,现在两个hash分别是2和3:
比如 length 为 9 的情况:3&(9-1)=0 2&(9-1)=0 ,都在0上,碰撞了;
比如 length 为 8 的情况:3&(8-1)=3 2&(8-1)=2 ,不同位置上,不碰撞;
hashmap为什么线程不安全
- 并发修改导致数据不一致(hash碰撞)。
- 并发扩容导致死循环或者数据丢失。






![[ C++ ] STL---string类的模拟实现](https://img-blog.csdnimg.cn/direct/d0bf4ebbcb8b48d1956915a20441bafc.gif)