摘要:
在这项工作中,我们提出了注意力池化(AP),一种用于判别模型训练的双向注意力机制。在使用神经网络进行成对排序或分类的背景下,AP使得池化层能够意识到当前的输入对,使得两个输入项的信息可以直接影响彼此的表示计算。结合这种成对输入的表示,AP共同学习一种在成对的投影段(例如,三元组)上的相似性度量,并随后,为每个输入导出相应的注意力向量来指导池化。我们的双向注意力机制是一个独立于底层表示学习的通用框架,它已经被应用于我们研究中的卷积神经网络(CNNs)和循环神经网络(RNNs)。来自三个非常不同的基准任务(问题回答/答案选择)的实证结果表明,我们提出的模型在所有基准测试中都优于多种强基线并达到了最先进的性能。
1.介绍
近年来,具有注意力机制的神经网络(NN)在不同的计算机视觉(CV)和自然语言处理(NLP)任务中取得了成功,例如图像描述(Xu et al., 2015)、机器翻译(Bahdanau et al., 2015)和事实问题回答(Hermann et al., 2015)。然而,最近关于神经注意力模型的工作主要集中在基于循环神经网络的单向注意力机制上,这些机制是为生成任务而设计的。
另一个重要的机器学习任务家族是围绕成对排序或分类展开的,这涵盖了广泛的应用,包括但不限于问题回答、蕴涵、释义和任何其他成对匹配问题。当前最先进的模型通常包括针对输入对的基于NN的表示,后面跟着一个判别性的排序或分类模型。例如,使用卷积(或RNN)和最大池化独立构建输入对的分布式向量表示,然后进行大间隔训练(Hu et al., 2014; Weston et al., 2014; Shen et al., 2014; dos Santos et al., 2015)。
这项工作的关键贡献是,我们提出了注意力池化(AP),一种双向注意力机制,通过使两个输入的表示及其相似性测量的联合学习成为可能,显著提高了这类判别模型在成对排序或分类上的性能。
具体来说,AP使得池化层能够意识到当前的输入对,使得两个输入项的信息可以直接影响彼此的表示计算。AP的主要思想在于学习两个输入对中的项的投影段(例如三元组)上的相似性度量,并使用段之间的相似性分数来计算双向的注意力向量。接下来,注意力向量被用于执行池化。
我们的模型有一些关键优点:
• 由于双向注意力,我们的模型将成对输入投影到一个共同的表示空间中,即使在某些应用中(例如,问题回答中的问题和答案)它们可能并不总是在语义上可比,这样它们就可以以更合理的方式进行比较。
• 我们的模型在匹配长度变化显著的输入对方面非常有效。双向注意力机制独立于底层的表示学习。例如,AP可以应用于CNN和RNN,这与主要基于循环网络的生成模型中使用的单向注意力形成对比。
在这项工作中,我们对应用注意力池化CNN(AP-CNN)和双向LSTM(AP-biLSTM)进行答案选择任务进行了大量实验。在这个任务中,给定一个问题q和一个候选答案池P = {a1, a2, · · · , ap},目标是在P中搜索并选择正确回答q的候选答案a。我们使用三个公开可用的基准数据集进行实验,这些数据集在数据规模、复杂性和问题与答案之间的长度比例上各不相同:InsuranceQA、TREC-QA和WikiQA。对于这三个数据集,AP-CNN和AP-biLSTM分别优于不使用注意力的CNN和biLSTM。此外,AP-CNN在这三个数据集上均达到了最先进的结果。
我们的实验结果还表明,注意力池化使CNN对大型输入文本更加健壮。这是一个重要的发现,因为最近的工作已经证明,在语义等价问题检索的背景下,基于CNN的表示随着输入文本大小的增加而表现不佳(dos Santos et al., 2015)。此外,由于AP-CNN不仅依赖于最终的向量表示来捕捉输入问题和答案之间的交互,因此它比常规的CNN需要更少的卷积滤波器。这意味着基于AP-CNN的表示更加紧凑,这有助于加快训练过程。
尽管我们只展示了NLP任务的实验结果,但AP是一种通用方法,也可以应用于执行两个输入匹配的不同类型的NN。因此,我们认为AP可以用于不同的应用,如计算机视觉和生物信息学。
本文的组织结构如下。在第2节中,我们描述了近期文献中提出的两种用于答案选择的NN架构。在第3节中,我们详细介绍了注意力池化方法。在第4节中,我们讨论了一些相关工作。第5节和第6节分别详细介绍了我们的实验设置和结果。在第7节中,我们提出了我们的最终评论。
2.答案选择的神经网络
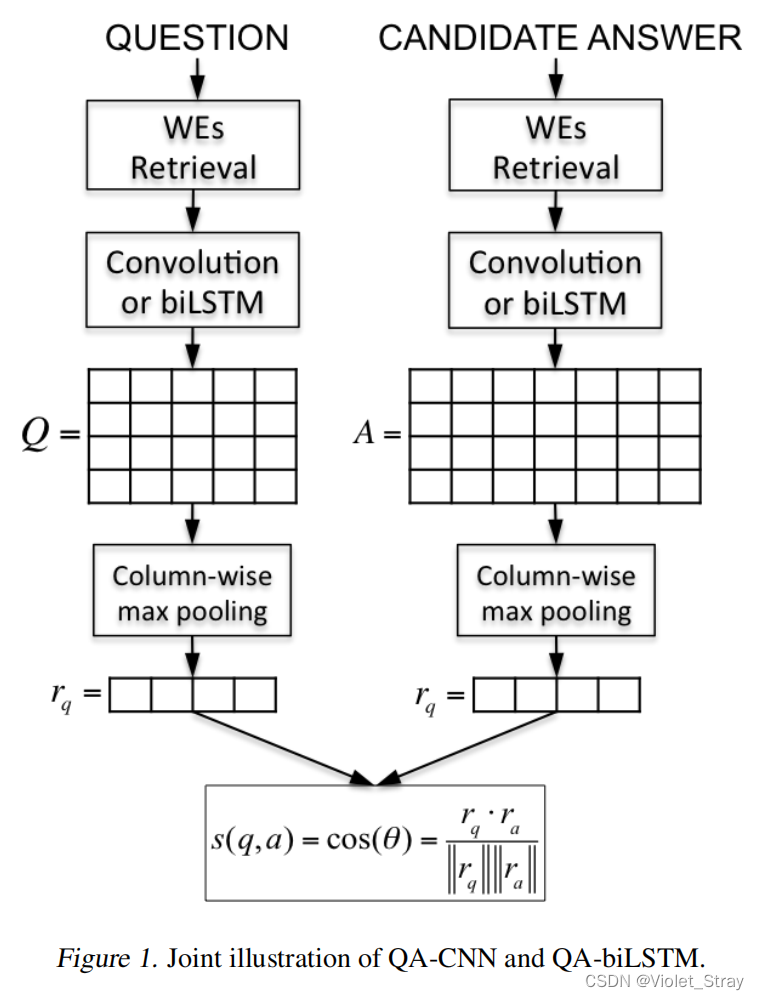
最近提出了不同的神经网络架构来执行语义相关文本片段的匹配(Yu et al., 2014; Hu et al., 2014; dos Santos et al., 2015; Wang & Nyberg, 2015; Severyn & Moschitti, 2015; Tan et al., 2015)。在本节中,我们简要回顾了两种之前应用于答案选择任务的NN架构:QA-CNN(Feng et al., 2015)和QA-biLSTM(Tan et al., 2015)。给定一个由问题q和候选答案a组成的对(q, a),这两个网络首先通过计算固定长度的独立连续向量表示rq和ra,然后计算这两个向量之间的余弦相似度来对这对进行评分。
在图1中,我们展示了这两个神经网络的联合插图。QA-CNN和QA-biLSTM中的第一层都将每个输入词w转换为固定大小的实值词嵌入rw ∈ Rd。词嵌入(WEs)由嵌入矩阵W0 ∈ Rd×|V|中的列向量编码,其中V是固定大小的词汇表,d是词嵌入的维度。给定输入对(q, a),其中问题q包含M个标记,候选答案a包含L个标记,第一层的输出由两个词嵌入序列qemb = {rw1, …, rwM}和aemb = {rw1, …, rwL}组成。
接下来,QA-CNN和QA-biLSTM使用不同的方法来处理这些序列。QA-CNN使用卷积处理qemb和aemb,而QA-biLSTM使用双向长短期记忆RNN(Hochreiter & Schmidhuber, 1997)来处理这些序列。
2.1 卷积
给定序列qemb = {rw1, …, rwM},让我们定义矩阵Zq = [z1, …, zM]为一个矩阵,其中每一列包含一个向量zm ∈ Rdk,这个向量是以问题中的第m个词为中心的k个词嵌入序列的连接。卷积在问题q上使用c个过滤器的输出如下计算:
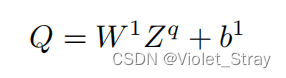
其中,Q ∈ Rc×M中的每一列m包含在q的第m个词周围的上下文窗口中提取的特征。矩阵W1和向量b1是需要学习的参数。卷积滤波器的数量c和词上下文窗口的大小k是用户需要选择的超参数。
以类似的方式,使用相同的NN参数W1和b1,我们计算A ∈ Rc×L,即候选答案a上卷积的输出。
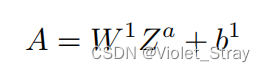
2.2 双向LSTM(biLSTM)
我们的LSTM实现与(Graves et al., 2013)中的类似,但有轻微修改。给定序列
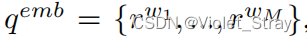
,在时间步t的隐藏向量h(t)(大小为H)更新如下:在LSTM架构中,有三个门(输入i,遗忘f和输出o)和一个单元记忆向量c。σ是sigmoid函数。输入门可以决定传入向量rwt如何改变记忆单元的状态。输出门可以允许记忆单元对输出产生影响。最后,遗忘门允许单元记住或忘记其先前状态。W ∈ RH×d,U ∈ RH×H和b ∈ RH×1是网络参数。
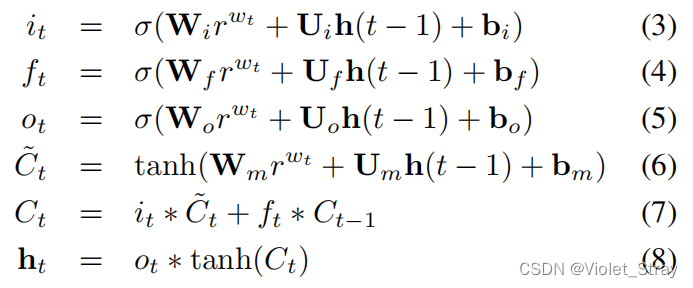
单向LSTM的一个弱点是没有利用来自未来标记的上下文信息。双向LSTM通过在两个方向上处理序列,利用先前和未来的上下文,并生成两个独立的LSTM输出向量序列。一个在前向方向上处理输入序列,另一个在反向方向上处理输入。每个时间步的输出是两个方向上的两个输出向量的连接,即ht = →ht ⊖ ←ht。我们定义c = 2×H,以保持与前一小节的符号一致。在计算每个时间步t的隐藏状态ht之后,我们生成矩阵Q ∈ R_c×M和A ∈ R_c×L,其中Q(A)中的第j列对应于由biLSTM在处理q(a)时计算的第j个隐藏状态hj。相同的网络参数用于处理问题和候选答案。
2.3 计分和训练过程
给定矩阵Q和A,我们通过对Q和A进行列方向的最大池化,然后应用一个非线性函数,来计算向量表示rq ∈ Rc和ra ∈ Rc。形式上,向量rq和ra的第j个元素分别如下计算:
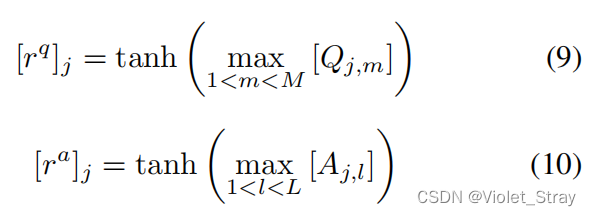
QA-CNN和QA-biLSTM中的最后一层通过计算两个表示之间的余弦相似度来对输入对(q,a)进行评分:
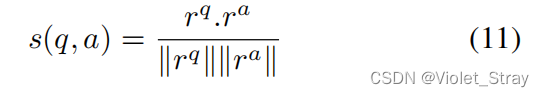
两个网络通过最小化训练集D上的成对排名损失函数来进行训练。每轮的输入是两对(q, a+)和(q, a−),其中a+是q的正确答案,a−是错误答案。如(Weston et al., 2014; Hu et al., 2014)中所定义,我们将训练目标定义为铰链损失:
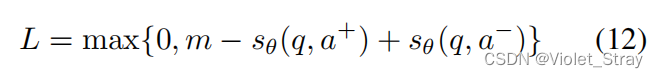
其中m是常数边界,sθ(q, a+)和sθ(q, a−)是由带有参数集θ的网络生成的分数。在训练过程中,对于每个问题,我们从整个答案集中随机抽取50个负面答案,但只使用得分最高的一个来更新模型。
我们使用随机梯度下降(SGD)来最小化关于θ的损失函数。反向传播算法用于计算网络的梯度。
3. 答案选择的注意力池化网络
注意力池化是一种方法,使池化层能够意识到当前的输入对,以一种使来自问题q的信息可以直接影响答案表示ra的计算,反之亦然的方式。主要思想包括学习输入对中投影段上的相似性度量,并使用段之间的相似性分数来计算注意力向量。当AP应用于CNN时,我们称之为AP-CNN,网络学习卷积输入序列上的相似性度量。当AP应用于biLSTM时,我们称之为AP-biLSTM,网络学习在处理两个输入序列时由biLSTM产生的隐藏状态上的相似性度量。我们使用具有双线性形式但后跟非线性的相似性度量。
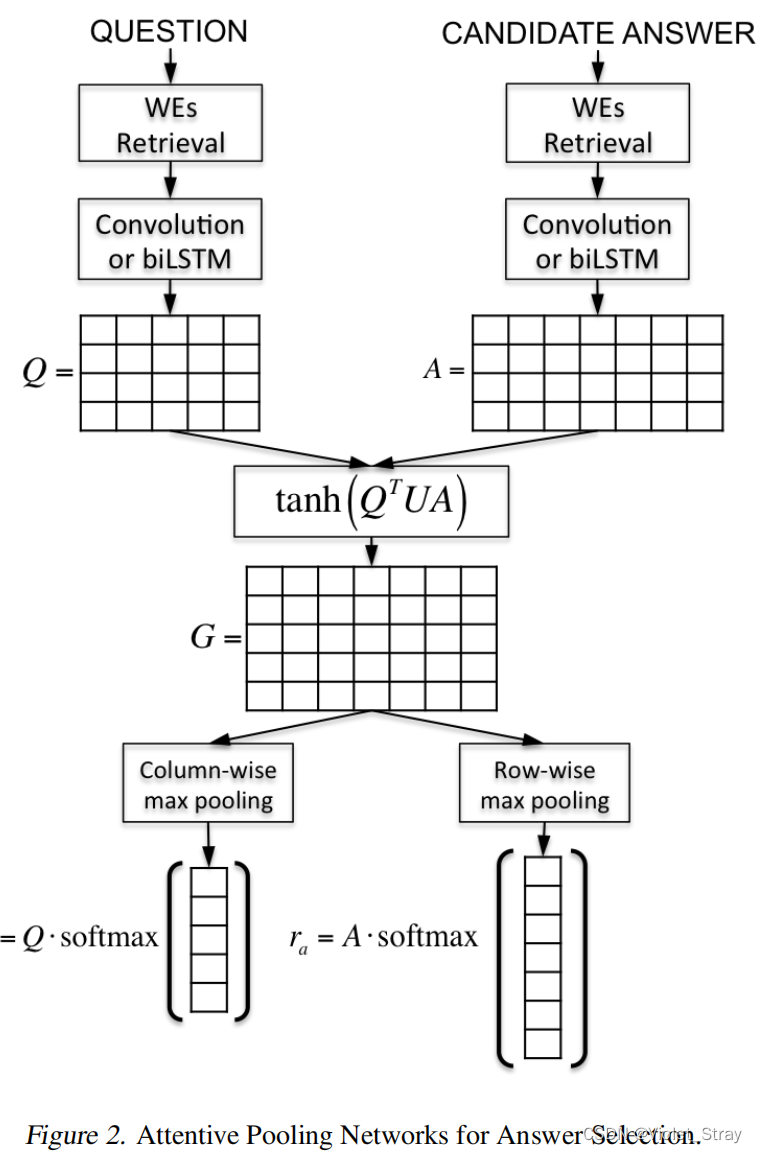
在图2中,我们展示了在卷积或biLSTM的输出上应用AP来构建表示rq和ra的示例。考虑输入对(q, a),其中问题的大小为M,答案的大小为L1。在我们通过卷积或biLSTM计算出矩阵Q ∈ Rc×M和A ∈ Rc×L之后,我们按如下方式计算矩阵G ∈ RM×L:
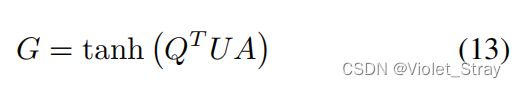
其中U ∈ Rc×c是神经网络需要学习的参数矩阵。当使用卷积来计算Q和A时,矩阵G包含了q和a中卷积后的k大小上下文窗口之间的软对齐分数。当使用biLSTM来计算Q和A时,矩阵G包含了q和a中每个标记的隐藏向量之间的软对齐分数。
接下来,我们对G进行列方向和行方向的最大池化,分别生成向量gq ∈ RM和ga ∈ RL。形式上,向量gq和ga的第j个元素如下计算:

我们可以将向量ga的每个元素j解释为候选答案a中第j个词周围上下文相对于问题q的重要性分数。同样地,向量gq的每个元素j可以解释为问题q中第j个词周围上下文相对于候选答案a的重要性分数。
接下来,我们对向量gq和ga应用softmax函数,创建注意力向量σq和σa。例如,向量σq的第j个元素如下计算: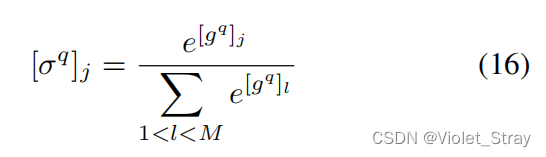
最后,表示rq和ra分别作为注意力向量σq和σa与卷积(或biLSTM)在q和a上的输出之间的点积计算得出:

与QA-CNN和QA-biLSTM一样,最终分数也是使用rq和ra之间的余弦相似度计算得出的。我们使用SGD通过最小化与QA-CNN和QA-biLSTM中使用的相同的成对损失函数来训练AP-CNN和AP-biLSTM。
4. 相关工作
传统的答案选择工作通常使用特征工程、语言学工具或外部资源(Yih et al., 2013; Wang & Manning, 2010; Wang et al., 2007)。最近,深度学习(DL)方法已被用于这项任务,并与传统的非DL方法相比取得了显著的超越。例如,在(Yu et al., 2014; Feng et al., 2015; Severyn & Moschitti, 2015),作者分别生成问题和答案的表示,并使用这些表示上的相似性度量来评分一个QA对。在Wang & Nyberg (2015)中,首先从连接问题和答案的长短期记忆(LSTM)模型中学习到联合特征向量,然后将任务转化为学习排序问题。
与此同时,基于注意力的系统在各种NLP任务上显示出非常有希望的结果,如机器翻译(Bahdanau et al., 2015; Sutskever et al., 2014)、标题生成(Xu et al., 2015)和事实问题回答(Hermann et al., 2015)。这样的模型学会将注意力集中在输入的特定部分。一些最近提出的方法在答案选择任务中引入了注意力机制。Tan et al. (2015)开发了一个基于双向长短期记忆的注意力阅读器,根据问题嵌入突出答案的某些部分。与(Tan et al., 2015)不同,在该研究中只对答案嵌入生成施加注意力,AP-CNN和AP-biLSTM考虑了问题和答案之间的相互依赖性。
在双向注意力的背景下,与我们的工作相关的两项非常近期的工作是Rockt¨aschel et al. (2015)提出了一种双向注意力方法,该方法受到双向LSTM的启发,后者读取序列及其反向以改进编码。他们的方法仅针对RNN设计,在许多方面不同于本文描述的方法,后者可以轻松应用于CNN和RNN。Yin et al. (2015)提出了一种针对CNN的双向注意力机制。他们的方法与本文的主要区别有:(1)他们使用简单的欧几里得距离来计算两个输入文本之间的相互依赖性,而在这项工作中,我们应用相似性度量学习,这具有学习更好的方法来衡量输入项段之间的交互的潜力;(2)(Yin et al., 2015)中的模型使用对齐矩阵上的求和池化来计算注意力向量,并使用经注意力更新的卷积输出作为另一层卷积层的输入。在这项工作中,我们使用对齐矩阵上的最大池化加softmax,以明确创建一个用于执行池化的注意力向量。实验结果表明,这种差异在WikiQA数据集上显著提高了性能。
5. 实验设置
5.1 数据集
我们将AP-CNN、AP-biLSTM、QA-CNN和QA-biLSTM应用于三个不同的答案选择数据集:InsuranceQA、TREC-QA和WikiQA。这些数据集包含不同领域的文本,并具有不同的特点。表1展示了有关数据集的一些统计信息,包括每个集合中的问题数量、问题(M)和答案(L)的平均长度、开发/测试集中候选答案的平均数量以及问题及其真实答案长度之间的平均比率。
InsuranceQA是一个最近发布的大规模非事实性QA数据集,来自保险领域。这个数据集提供了一个训练集、一个验证集和两个测试集。我们在两个测试集的问题之间没有看到明显的分类差异。对于开发/测试集中的每个问题,有一个包含500个候选答案的集合,其中包括真实答案和随机选择的负面答案。更多细节可以在(Feng et al., 2015)中找到。
TREC-QA是由Wang et al. (2007)基于文本检索会议(TREC)QA轨迹(8-13)数据创建的。我们遵循(Wang & Nyberg, 2015)中训练/开发/测试问题选择的确切方法,其中所有只有正面或负面答案的问题都被移除。最终,我们有1162个训练问题、65个开发问题和68个测试问题。
WikiQA是一个开放领域的问答数据集。我们使用假设问题至少有一个正确答案的子任务。相应的数据集包括训练集中的20,360个问题/候选对,开发集中的1,130对和测试集中的2,352对。我们采用标准设置,只考虑有正确答案的问题进行评估。

5.2 词嵌入
为了公平比较我们的结果与先前工作中的结果,我们使用了两套不同的预训练词嵌入。对于InsuranceQA数据集,我们使用Feng et al. (2015)使用word2vec(Mikolov et al., 2013)训练的100维向量。遵循Wang & Nyberg (2015)、Tan et al. (2015)和Yin et al.(2015),对于TREC-QA和WikiQA数据集,我们使用使用word2vec训练并在该工具的网站上公开可用的300维向量。
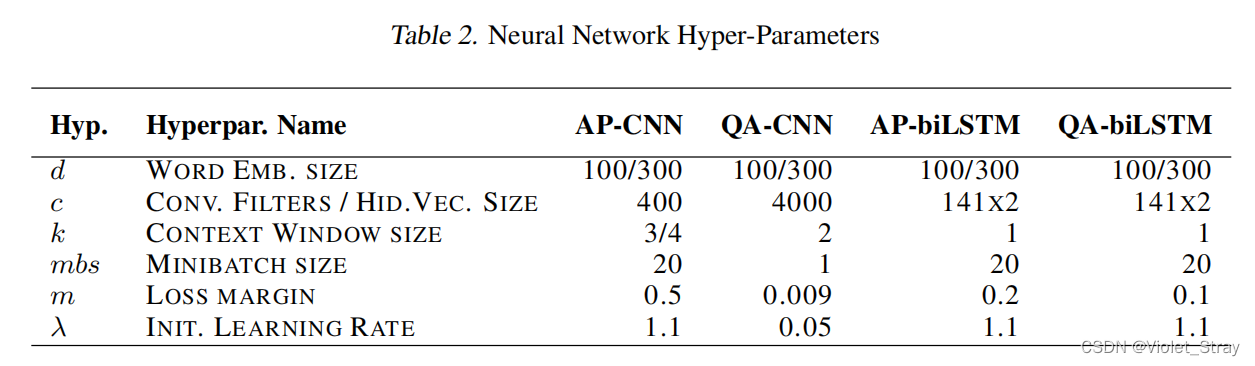
5.3 神经网络设置
在表2中,我们展示了使用验证集调整的选定超参数值。我们尽可能对所有三个数据集使用相同的超参数。由于我们对InsuranceQA和其他两个数据集使用了不同的预训练版本,词嵌入的大小不同。我们为InsuranceQA使用大小为3的上下文窗口,而我们将这个参数设置为4用于TREC-QA和WikiQA。使用选定的超参数,最佳结果通常在15到25个训练周期之间实现。对于AP-CNN、AP-biLSTM和QA-LSTM,我们还使用了一个学习率计划,根据训练周期t减少学习率λ。遵循dos Santos & Zadrozny (2014),我们使用以下方程设置第t个周期的学习率λt:
λt = λ / t。
在我们的实验中,四种NN架构QA-CNN、AP-CNN、QA-biLSTM和AP-biLSTM使用Theano(Bergstra et al., 2010)实现。
6. 实验结果
6.1. InsuranceQA
在表3中,我们展示了四种NN在InsuranceQA数据集上的实验结果。结果以准确率表示,相当于排在第一位的精确度。在这个表的底部,我们可以看到AP-CNN在两个测试集以及开发集中都大幅度优于QA-CNN。AP-biLSTM也在所有三个集合中优于QA-biLSTM。AP-CNN和AP-biLSTM的性能相似。
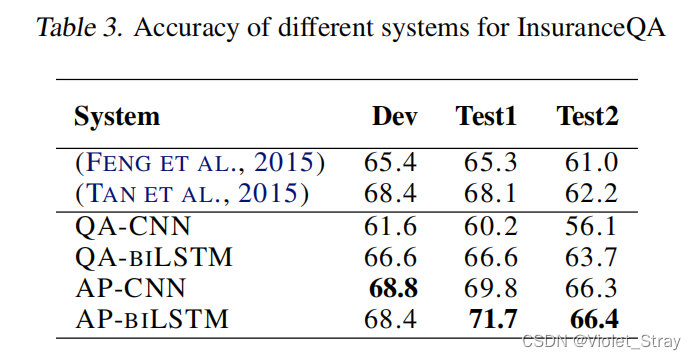
AP-CNN的一个重要特点是它比QA-CNN需要更少的卷积滤波器。对于InsuranceQA数据集,AP-CNN使用的滤波器(400)比QA-CNN(4000)少10倍。在AP-CNN中使用800个滤波器产生的结果与使用400个滤波器非常相似。另一方面,正如(Feng et al., 2015)中发现的那样,QA-CNN需要至少2000个滤波器才能在InsuranceQA上达到60%以上的准确率。AP-CNN需要更少的滤波器,因为它不仅依赖于最终的向量表示来捕捉输入问题和答案之间的交互。因此,尽管AP-CNN具有更复杂的架构,但其训练时间是QA-CNN的两倍快。使用Tesla K20Xm,我们的Theano实现的AP-CNN需要大约16分钟来完成一个周期(训练+在验证集上的推理),用于处理150万个文本片段。
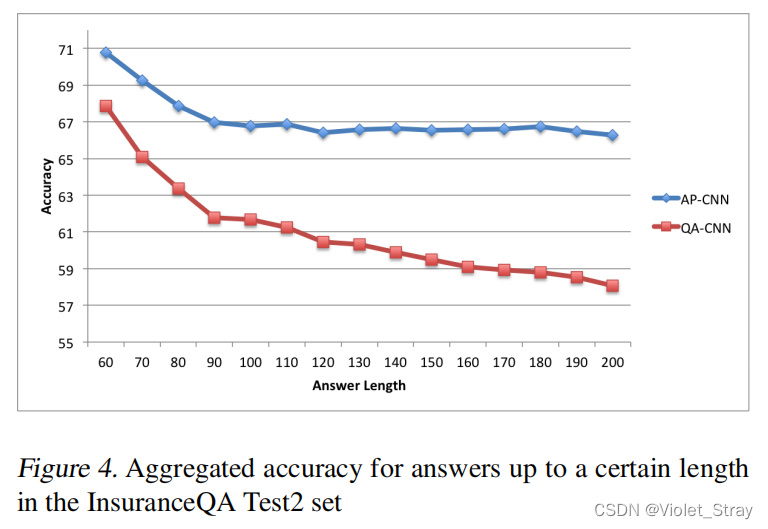
在图3和图4中,我们分别绘制了AP-CNN和QA-CNN在Test1和Test2集合中对于一定长度以下的答案的聚合准确率。我们可以在两个图中看到,两个系统对于较短的答案性能更好。然而,虽然QA-CNN的性能随着考虑更大的答案而继续下降,但AP-CNN的性能在达到约90个标记的长度后似乎保持稳定。这些结果支持我们的假设,即注意力池化有助于CNN对较大的输入文本保持鲁棒性。
对于这个数据集的最先进系统。在(Feng et al., 2015)中,作者提出了一个与QA-CNN相似的CNN架构,但使用了不同的相似性度量而不是余弦相似度。在(Tan et al., 2015)中,作者使用了一个利用单向注意力的biLTSM架构。AP-CNN和AP-biLSTM都优于最先进的系统。

6.2. TREC-QA
在表4中,我们展示了四种NN在TREC-QA数据集上的实验结果。结果以平均精确度均值(MAP)和平均倒数排名(MRR)表示,这些是以前使用相同数据集的工作中通常使用的指标。我们使用官方的trec eval评分器来计算MAP和MRR。在表4中,我们可以看到AP-CNN在两个指标上都大幅度超过QA-CNN。AP-biLSTM优于QA-biLSTM,但其性能不如AP-CNN。
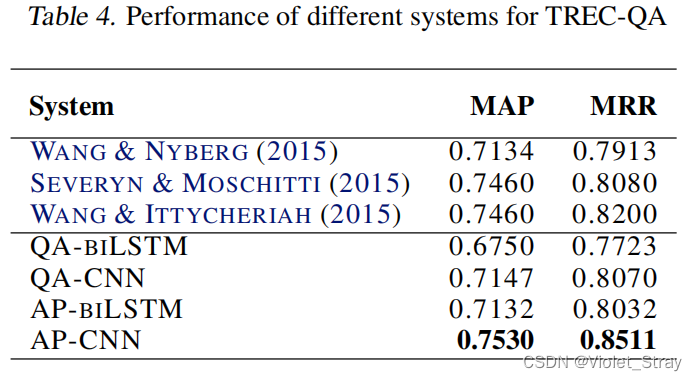
在表4的顶部,我们展示了三项使用TREC-QA作为基准的最近工作的结果。在(Wang & Nyberg, 2015)中,作者提出了一个用于答案选择的LSTM架构。他们最好的结果是LSTM和BM25算法的组合。在(Severyn & Moschitti, 2015)中,作者提出了一个NN架构,其中卷积层创建的表示是相似性度量学习的输入。Wang & Ittycheriah (2015)提出了一种适用于FAQ式问答任务的基于词对齐的方法。AP-CNN在两个指标,MAP和MRR上都超过了最先进的系统。
6.3. WikiQA
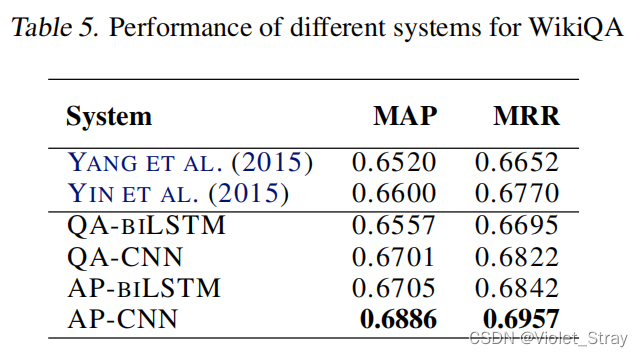
表5展示了四种NN在WikiQA数据集上的实验结果。与其他两个数据集一样,AP-CNN优于QA-CNN,AP-biLSTM优于QA-biLSTM。AP-CNN和QA-CNN之间的性能差异小于InsuranceQA数据集。我们认为这是因为WikiQA中答案的平均大小(25)比InsuranceQA(95)小得多。预计注意力池化会对具有较大答案/问题长度的数据集产生更大影响。
在表5中,我们还展示了两项使用WikiQA作为基准的最近工作的结果。Yang et al. (2015)提出了一个带有平均池化的二元CNN模型。在(Yin et al., 2015)中,作者提出了一个基于注意力的CNN。为了进行公平比较,在表5中,我们包括了Yin等人使用仅词嵌入的结果。AP-CNN在两个指标上都优于这两个系统。
7. 结论
我们提出了注意力池化,一种用于判别模型训练的双向注意力机制。本文的主要贡献包括:(1)AP比最近提出的双向注意力机制更通用,因为:(a)它学习如何计算输入对中的项之间的交互;(b)它可以应用于CNN和RNN;(2)我们证明AP可以在答案选择任务的背景下有效地与CNN和biLSTM一起使用,使用三个不同的基准数据集;(3)我们的实验结果表明,AP有助于CNN处理大型输入文本;(4)我们为InsuranceQA和TREC-QA数据集提供了新的最先进结果。(5)对于WikiQA数据集,我们的结果是迄今为止报告的最好的结果,对于不使用手工特征的方法。