作者:宋文欣,智领云科技联合创始人兼CTO
01 简介
大语言模型(LLMs)正逐渐成为人工智能领域的一颗璀璨明星,它们的强大之处在于能够理解和生成自然语言,为各种应用提供了无限可能。为了让这些模型更好地服务于实际业务场景,我们引入了检索增强生成(RAG)技术。RAG 技术将各种文档类型转换成 LLMs 易于解读的格式,通过结合检索和生成的方式,极大地提升了模型处理复杂任务的能力,尤其是在处理需要广泛知识和理解的长文本时表现得尤为出色。
PDF 文档作为信息传递的重要载体,其内容的抽取和理解对于实现高质量的 RAG 输出至关重要。要充分发挥RAG技术的潜力,我们需要解决一个关键问题:如何高效地解析和提取PDF文档中的信息。PDF 的文档格式使用广泛,结构复杂且多样,给自动化解析带来了不小的挑战。随着技术的进步,我们有了多种工具来应对这一挑战。本文将带你了解如何在 Docker 容器中运行三个业界领先的PDF解析器:LLMSherpa、Unstructured和LlamaParse。
本文将演示如何在容器化环境中快速部署和使用,完成从环境搭建到PDF解析器选择的全过程:
LLMSherpa[1]
Unstructured[2]
LlamaParse[3]
本文还对关键的技术要点和实践经验进行总结,通过本文的阅读,将对 RAG 技术在 LLMs 中的应用有一个全面的认识,无论是 LLMSherpa 的高效性,Unstructured 的灵活性,还是 LlamaParse 的稳定性,我们都将为您提供全面的比较和深入的分析,帮助选择最适合需求的 PDF 解析器。
02 技术背景
LLMSherpa
LLMSherpa 提供了一个免费的 API 服务器,用于解析各种类型的 PDF文件,同时还支持在私有服务器上托管,确保数据的安全性和隐私性。LayoutPDFReader(基于规则的解析器),作为 LLMSherpa 的核心组件之一,使用来自修改版的 Tika 的文本坐标(边界框)、图形和字体数据,以极高的精度解析 PDF 文件中的文本和布局。
在本次演示中,我们将展示如何在 Docker 容器中运行一个自托管的 LLMSherpa API 服务器,在自己的环境中轻松处理 PDF 文件。
Unstructured
Unstructured 是 unstructured.io 提供的开源库,用于摄取和预处理包括 PDF、HTML、Word 文档等格式在内的图像和文本文档,极大地简化了从文档中提取有价值信息的过程。Unstructured 还提供了一个免费的 API 服务,允许用户免费处理高达 1000 页的文档。
本文演示中,我们将重点关注如何独立使用 Unstructured 的开源库进行文档处理,而不依赖其 API 服务。用户可以在自己的服务器上部署和使用这个强大的库,享受数据处理的灵活性和自主性。
LlamaParse
LlamaParse 是由 LlamaIndex 推出的 API,旨在高效解析和呈现文件内容,进而配合LlamaIndex 框架实现快速检索和上下文增强。截至 2024年2月26日,这项服务目前处于免费预览阶段,且只专注于支持 PDF 格式文件的处理。
03 成果展示
RAG 技术使得模型能够通过解析不同领域的 PDF 文档,适应各种领域的查询,增加了模型的应用范围和灵活性。通过直接从 PDF 文档中检索信息,可以减轻对 LLMs 进行大规模、跨领域训练的需求,降低训练成本。在提高回答的准确性和信息的丰富度的同时,为特定用户群体提供更加个性化和深度的信息服务。
本示例演示步骤如下:
(1) PDF 文件上传
用户通过界面,上传需要解析的 PDF 文件
(2) 选择解析类型
本实例运行了三个业界领先的PDF解析器:LLMSherpa、Unstructured 和 LlamaParse,可供用户选择,本文以 LLMSherpa 为例:
LLMSherpa:适用于需要精确文本定位和布局分析的高级文档处理任务,如文本的具体位置、字体大小和样式等。
Unstructured:支持多种文档类型的解析,适合需要统一处理多种格式文档的应用场景,如文档管理系统、内容抽取和索引建立等。
LlamaParse:适合在需要进行大规模文档检索和分析的场景,如需要从大量PDF文档中检索信息并进行上下文增强的应用场景等。
(3) PDF 文本解析
向 LLMSherpa 的 API 发送解析请求,包括要解析的 PDF 文档。
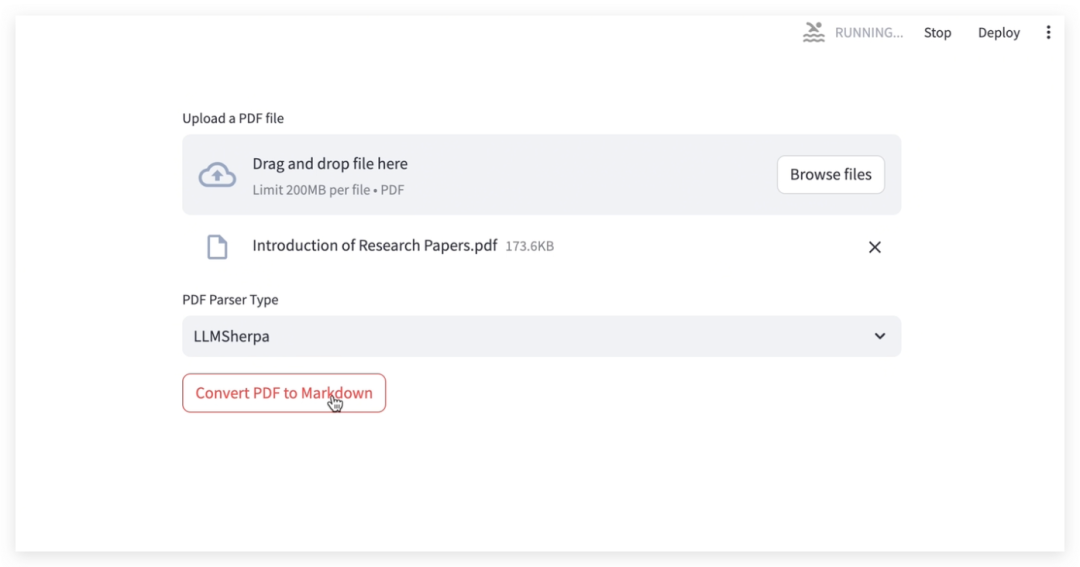
(4) 结果展示
LLMSherpa 处理完毕,会返回响应,其中包含解析结果。根据 LLMSherpa 的设计,其响应可包含文本内容、边界框(文本的位置信息)、图形和字体数据等。本示例中为文本内容:
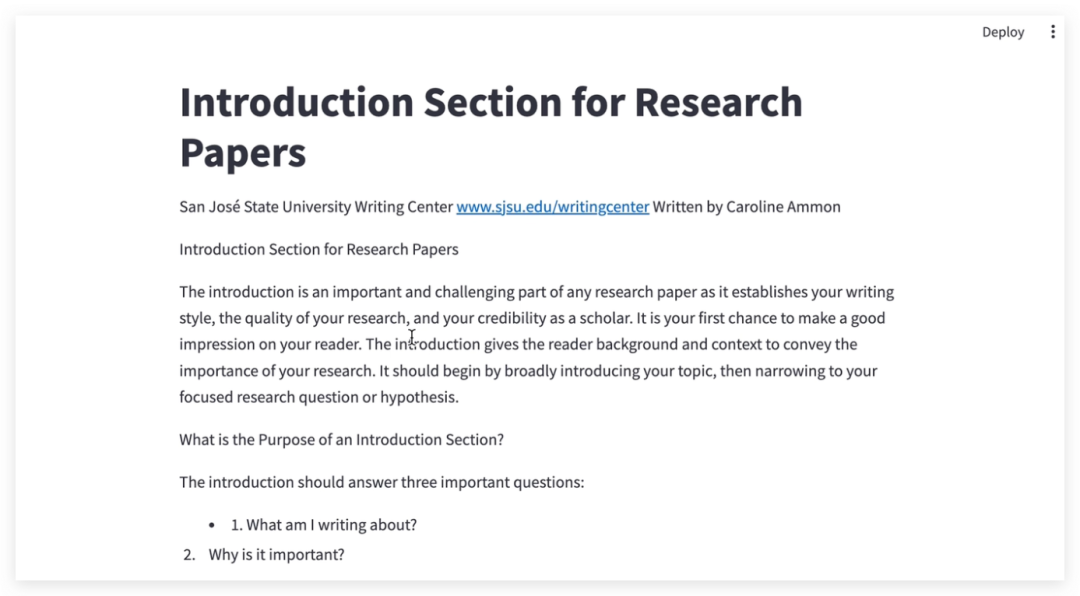
(5) 后续处理
得到解析结果后,可以根据项目需求对这些数据进行进一步的处理。如将文本内容输入到大型语言模型中进行语义分析,或者使用边界框信息来重构文档的视觉布局等。
04 操作步骤
前置条件
1. 操作系统:应与大多数 Linux 发行版兼容,并已在 Ubuntu 22.04 上进行了测试。
2. Docker:系统上必须安装有 docker。具体来说,我们已经在 Ubuntu 22.04 上使用 Docker Engine 社区版 25.0.1 测试了这个演示。
3. OpenAI API 密钥(可选):如果希望在此演示中使用 ChatGPT 功能,需要 OpenAI API 密钥。请注意,此 API 的使用受 OpenAI 的定价和使用政策的约束。我们使用 OpenAI 文本生成模型来优化解析某些特殊组件(如标题或表格等)。没有这个 API 密钥,仍然可以尝试所有三种方法。
4. LlamaParse API 密钥:如果希望尝试新推出的 LlamaParse API 服务,需要从 其网页门户获取 API 密钥。没有这个 API 密钥,将无法尝试 LlamaParse。
本机电脑(Mac,非GPU配置,已安装 Docker)
以下是在 本机电脑(Mac,非GPU配置,已安装 Docker) 上启动演示的操作指南:
1. 选择合适路径,右键 Open in Terminal,输入如下命令克隆仓库:
git clone https://github.com/LinkTime-Corp/llm-in-containers.git
cd llm-in-containers/pdf2md2.若需要使用 OpenAI 的模型进行推理,将您的OpenAI API 密钥设置到conf/config.json的“OPENAI_API_KEY”中,包括:替换API 密钥 ‘{your-openai-api-key}’ 和 ‘{your-llamaparse-api-key}’ ,使用以下的命令:
export OPENAI_API_KEY={your-openai-api-key}
export LLAMAPARSE_API_KEY={your-llamaparse-api-key}如果用户的OpenAI 未进行订阅,这里则需要修改model为:"OPENAI_API_MODEL": "gpt-3.5-turbo",
3.打开 Docker Desktop
4.启动演示:
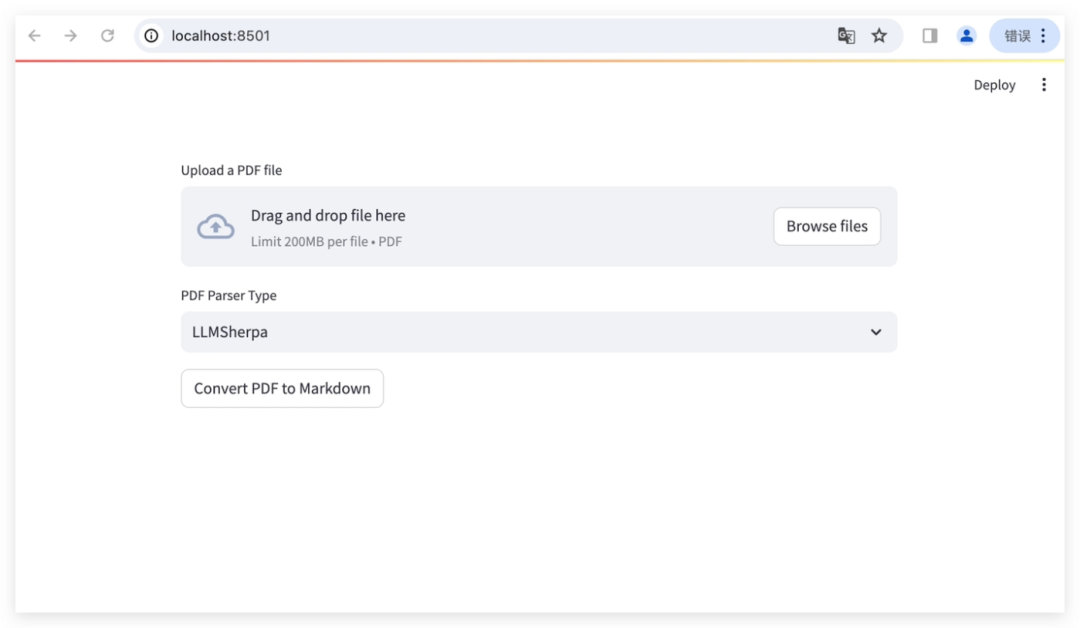
bash run.sh5.访问 http://localhost:8501/ 上的用户界面
在用户界面上,您可以选择“LLMSherpa”,“Unstructured”或“LlamaParse”来解析上传的PDF文件
6.关闭演示
bash shutdown.sh在阿里云/AWS服务器运行
过程类似,详情可参见完整博客内容:https://blog.gopenai.com/running-pdf-parsers-in-docker-containers-5e7a7ed829c8
05 要点笔记
PDF解析器选择
在选择PDF解析器时,不仅要考虑敏感信息的处理、成本因素,还需要评估各种工具的准确性和兼容性等。通过在实际文件上进行测试和评估,结合对不同场景的理解,选择或组合最适合您需求的解析器。
敏感信息处理:如果 PDF 文件包含敏感信息,并且对数据的安全性和隐私性有较高要求,在私有服务器上使用开源解决方案可能是最佳选择。LLMSherpa 和 Unstructured 都可在私人服务器上部署的开源 PDF 解析器,可以为处理敏感文档提供更高的安全保障。
成本考虑:如果对成本较为敏感,且 PDF 文件不包含敏感信息,那么可以考虑使用LlamaParse 或 ChatDoc。LlamaParse 目前提供免费的预览模式,而ChatDoc 虽然需要申请获得使用权限,但可能在未来推出收费的高级服务。
准确性和兼容性:目前没有任何工具或服务能够保证 100% 准确无误地解析所有 PDF 文件。PDF 格式的复杂性意味着解析器在处理不同结构或布局的文档时可能遇到挑战。因此,可以在特定的文件上测试不同的解析器,以确定哪个工具在准确性和功能性方面最能满足需求。
混合使用方案:可以在处理非敏感信息时使用LlamaParse 或 ChatDoc,而对于需要更高安全性的敏感文档,则转而使用 LLMSherpa 或Unstructured。
LLMSherpa:解析PDF文件以及层次布局信息
LLMSherpa 的 LayoutPDFReader 提供了一种高效的方法来解析 PDF 文件及其层次布局信息,利用其“智能分块”技术,能够识别文档中的不同部分和小节以及它们的嵌套结构,将文本行合并成连贯的段落并建立部分之间的联系。
尽管在大多数情况下 LayoutPDFReader 的性能表现出色,但也存在一些限制,如某些部分可能不会被正确地分类。对于需要 PDF 文件中信息的上下文感知分块,同时能够接受偶尔出现的分类不准确情况的 LLM 应用,LLMSherpa 的 LayoutPDFReader 成为了一个值得尝试的选项。
Unstructured:使用正确的模型来检测PDF文档中的元素
在处理PDF文档时,正确选择用于检测文档中元素的模型,将直接影响到文档解析的效率和准确性。Unstructured Python 库提供了几种不同的模型选项,以适应不同的需求和应用场景:
detectron2_onnx:是基于Facebook AI的计算机视觉模型,使用ONNX Runtime,提供了快速的对象检测和分割能力。如果主要关注点是速度,并且需要高效的对象检测功能,detectron2_onnx 可以是最佳选择。
yolox:是基于YOLOv3并且进行了优化的单阶段实时对象检测器,使用了DarkNet53作为主干网络。适用于需要实时对象检测同时关注模型准确度的场景。
yolox_quantized:它的运行速度比 YoloX 快,其速度更接近Detectron2。如果寻找一个既快速又相对准确的解决方案,yolox_quantized 是一个不错的选择。
chipper (beta version):chipper 是 Unstructured 内置的图像到文本模型,基于Transformer 架构的视觉文档理解(VDU)模型。适用于需要从图像中提取文本并进行深度理解的复杂应用场景。由于它还处于beta版本,可能需要进一步的测试和调整以满足特定的需求。
您还可以参考此文档https://unstructured-io.github.io/unstructured/best_practices/models.html#bring-your-own-models,将定制模型引入到这个库。
06 链接
本文Github 链接:
https://github.com/LinkTime-Corp/llm-in-containers/tree/main/pdf2md
博客原文:
https://blog.gopenai.com/running-pdf-parsers-in-docker-containers-5e7a7ed829c8
[1] LLMSherpa
https://github.com/nlmatics/llmsherpa
[2] Unstructured
https://github.com/Unstructured-IO/unstructured
[3] LlamaParse
https://github.com/run-llama/llama_parse
作者:宋文欣,智领云科技联合创始人兼CTO
武汉大学计算机系本科及硕士,美国纽约州立大学石溪分校计算机专业博士。曾先后就职于Ask.com和EA(电子艺界)。在Ask.com期间,担任大数据部门技术负责人及工程经理,使用Hadoop集群处理实时搜索数据,形成全球规模领先的Search Ads Arbitrage用户;在EA期间,担任数字平台部门高级研发经理,从无到有组建EA数据平台团队,建设公司大数据平台,为EA全球工作室提供数据能力支持。
2016年回国联合创立智领云科技有限公司,组建智领云技术团队,开发了BDOS大数据平台操作系统。
- Fin -

更多精彩推荐
容器中的大模型(二) | 利用大模型,使用自然语言查询SQL数据库
容器中的⼤模型(一)| 三行命令,大模型让Excel直接回答问题
开篇语 | 容器中的⼤模型 (LLM in Containers)
👇点击阅读原文,访问中文博客原文


![Unicode转码 [ASIS 2019]Unicorn shop1](https://img-blog.csdnimg.cn/direct/61dafcee5ff64e1c94a6d331cf758c4d.png)