文章目录
- 1. Go语言的出现
- 2. go版本的hello world
- 3. 数据类型
- 3.0 定义变量
- 3.0.1 如果变量没有初始化
- 3.0.2 如果变量没有指定类型
- 3.0.3 :=符号
- 3.0.4 多变量声明
- 3.0.5 匿名变量
- 3.0.6 变量作用域
- 3.1 基本类型
- 3.2 指针
- 3.2.1 指针声明和初始化
- 3.2.2 空指针
- 3.3 数组
- 3.3.1 声明数组
- 3.3.2 初始化数组
- 3.3.3 go中的数组名意义
- 3.3.4 数组指针
- 3.4 结构体
- 3.4.1 声明结构体
- 3.4.2 访问结构体成员
- 3.4.3 结构体指针
- 3.5 字符串
- 3.5.1 字符串定义和初始化
- 3.5.2 字符串UTF8编码
- 3.5.3 字符串的强制类型转换
- 3.6 slice
- 3.6.1 slice定义
- 3.6.2 添加元素
- 3.6.3 删除元素
- 3.7 函数
- 3.7.1 函数分类
- 3.7.2 函数声明和定义
- 3.7.3 函数传参
- 3.7.4 函数返回值
- 3.7.5 递归调用
- 3.8 方法
- 3.9 接口
- 3.9.1 什么是接口
- 3.9.2 结构体类型
- 3.9.3 具体类型向接口类型赋值
- 3.9.4 获取接口类型数据的具体类型信息
- 3.10 channel
- 3.10.1 相关结构体定义
- 3.10.2 阻塞式读写channel操作
- 3.10.3 非阻塞式读写channel操作
- 3.11 map
- 3.11.1 插入数据
- 3.11.2 删除数据
- 3.11.3 查找数据
- 3.11.4 扩容
- 4. 常用语句及关键字
- 4.1 条件语句
- 4.2 循环语句
- 4.2.1 循环处理语句
- 4.2.1 循环控制语句
- 4.3 关键字
1. Go语言的出现
在具体学习go语言的基础语法之前,我们来了解一下go语言出现的时机及其特点。
Go语言最初由Google公司的Robert Griesemer、Ken Thompson和Rob Pike三个大牛于2007年开始设计发明,他们最终的目标是设计一种适应网络和多核时代的C语言。所以Go语言很多时候被描述为“类C语言”,或者是“21世纪的C语言”,当然从各种角度看,Go语言确实是从C语言继承了相似的表达式语法、控制流结构、基础数据类型、调用参数传值、指针等诸多编程思想。但是Go语言更是对C语言最彻底的一次扬弃,它舍弃了C语言中灵活但是危险的指针运算,还重新设计了C语言中部分不太合理运算符的优先级,并在很多细微的地方都做了必要的打磨和改变。
2. go版本的hello world
在这一部分我们只是使用“hello world”的程序来向大家介绍一下go语言的所编写的程序的基本组成。
package main
import "fmt"
func main() {
// 终端输出hello world
fmt.Println("Hello world!")
}
和C语言相似,go语言的基本组成有:
- 包声明,编写源文件时,必须在非注释的第一行指明这个文件属于哪个包,如
package main。 - 引入包,其实就是告诉Go 编译器这个程序需要使用的包,如
import "fmt"其实就是引入了fmt包。 - 函数,和c语言相同,即是一个可以实现某一个功能的函数体,每一个可执行程序中必须拥有一个main函数。
- 变量,Go 语言变量名由字母、数字、下划线组成,其中首个字符不能为数字。
- 语句/表达式,在 Go 程序中,一行代表一个语句结束。每个语句不需要像 C 家族中的其它语言一样以分号 ; 结尾,因为这些工作都将由 Go 编译器自动完成。
- 注释,和c语言中的注释方式相同,可以在任何地方使用以 // 开头的单行注释。以 /* 开头,并以 */ 结尾来进行多行注释,且不可以嵌套使用,多行注释一般用于包的文档描述或注释成块的代码片段。
需要注意的是:标识符是用来命名变量、类型等程序实体。一个标识符实际上就是一个或是多个字母和数字、下划线_组成的序列,但是第一个字符必须是字母或下划线而不能是数字。
- 当标识符(包括常量、变量、类型、函数名、结构字段等等)以一个大写字母开头,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的 public);
- 标识符如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的 protected)。
3. 数据类型
在 Go 编程语言中,数据类型用于声明函数和变量。
数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存。具体分类如下:
| 类型 | 详解 |
|---|---|
| 布尔型 | 布尔型的值只可以是常量 true 或者 false。 |
| 数字类型 | 整型 int 和浮点型 float。Go 语言支持整型和浮点型数字,并且支持复数,其中位的运算采用补码。 |
| 字符串类型 | 字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。 |
| 派生类型 | (a) 指针类型(Pointer)(b) 数组类型© 结构化类型(struct)(d) Channel 类型(e) 函数类型(f) 切片类型(g) 接口类型(interface)(h) Map 类型 |
3.0 定义变量
声明变量的一般形式是使用 var 关键字,具体格式为:var identifier typename。如下的代码中我们定义了一个类型为int的变量。
package main
import "fmt"
func main() {
var a int = 27
fmt.Println(a);
}
3.0.1 如果变量没有初始化
在go语言中定义了一个变量,指定变量类型,如果没有初始化,则变量默认为零值。零值就是变量没有做初始化时系统默认设置的值。
| 类型 | 零值 |
|---|---|
| 数值类型 | 0 |
| 布尔类型 | false |
| 字符串 | “”(空字符串) |
3.0.2 如果变量没有指定类型
在go语言中如果没有指定变量类型,可以通过变量的初始值来判断变量类型。如下代码
package main
import "fmt"
func main() {
var d = true
fmt.Println(d)
}
3.0.3 :=符号
当我们定义一个变量后又使用该符号初始化变量,就会产生编译错误,因为该符号其实是一个声明语句。
使用格式:typename := value
也就是说intVal := 1相等于:
var intVal int
intVal =1
3.0.4 多变量声明
可以同时声明多个类型相同的变量(非全局变量),如下图所示:
var x, y int
var c, d int = 1, 2
g, h := 123, "hello"
关于全局变量的声明如下:
var ( vname1 v_type1 vname2 v_type2 )
具体举例如下:
var (
a int
b bool
)
3.0.5 匿名变量
匿名变量的特点是一个下画线_,这本身就是一个特殊的标识符,被称为空白标识符。它可以像其他标识符那样用于变量的声明或赋值(任何类型都可以赋值给它),但任何赋给这个标识符的值都将被抛弃,因此这些值不能在后续的代码中使用,也不可以使用这个标识符作为变量对其它变量进行赋值或运算。
使用匿名变量时,只需要在变量声明的地方使用下画线替换即可。
示例代码如下:
func GetData() (int, int) {
return 10, 20
}
func main(){
a, _ := GetData()
_, b := GetData()
fmt.Println(a, b)
}
需要注意的是匿名变量不占用内存空间,不会分配内存。匿名变量与匿名变量之间也不会因为多次声明而无法使用。
3.0.6 变量作用域
作用域指的是已声明的标识符所表示的常量、类型、函数或者包在源代码中的作用范围,在此我们主要看一下go中变量的作用域,根据变量定义位置的不同,可以分为一下三个类型:
- 函数内定义的变量为局部变量,这种局部变量的作用域只在函数体内,函数的参数和返回值变量都属于局部变量。这种变量在存在于函数被调用时,销毁于函数调用结束后。
- 函数外定义的变量为全局变量,全局变量只需要在一个源文件中定义,就可以在所有源文件中使用,甚至可以使用import引入外部包来使用。全局变量声明必须以 var 关键字开头,如果想要在外部包中使用全局变量的首字母必须大写。
- 函数定义中的变量成为形式参数,定义函数时函数名后面括号中的变量叫做形式参数(简称形参)。形式参数只在函数调用时才会生效,函数调用结束后就会被销毁,在函数未被调用时,函数的形参并不占用实际的存储单元,也没有实际值。形式参数会作为函数的局部变量来使用。
3.1 基本类型
| 类型 | 描述 |
|---|---|
| uint8 / uint16 / uint32 / uint64 | 无符号 8 / 16 / 32 / 64位整型 |
| int8 / int16 / int32 / int64 | 有符号8 / 16 / 32 / 64位整型 |
| float32 / float64 | IEEE-754 32 / 64 位浮点型数 |
| complex64 / complex128 | 32 / 64 位实数和虚数 |
| byte | 类似 uint8 |
| rune | 类似 int32 |
| uintptr | 无符号整型,用于存放一个指针 |
以上就是go语言基本的数据类型,有了数据类型,我们就可以使用这些类型来定义变量,Go 语言变量名由字母、数字、下划线组成,其中首个字符不能为数字。
3.2 指针
与C相同,Go语言让程序员决定何时使用指针。变量其实是一种使用方便的占位符,用于引用计算机内存地址。Go 语言中的的取地址符是&,放到一个变量前使用就会返回相应变量的内存地址。
指针变量其实就是用于存放某一个对象的内存地址。
3.2.1 指针声明和初始化
和基础类型数据相同,在使用指针变量之前我们首先需要申明指针,声明格式如下:var var_name *var-type,其中的var-type 为指针类型,var_name 为指针变量名,* 号用于指定变量是作为一个指针。
代码举例如下:
var ip *int /* 指向整型*/
var fp *float32 /* 指向浮点型 */
指针的初始化就是取出相对应的变量地址对指针进行赋值,具体如下:
var a int= 20 /* 声明实际变量 */
var ip *int /* 声明指针变量 */
ip = &a /* 指针变量的存储地址 */
3.2.2 空指针
当一个指针被定义后没有分配到任何变量时,它的值为 nil,也称为空指针。它概念上和其它语言的null、NULL一样,都指代零值或空值。
3.3 数组
和c语言相同,Go语言也提供了数组类型的数据结构,数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。
3.3.1 声明数组
Go 语言数组声明需要指定元素类型及元素个数,语法格式如下:
var variable_name [SIZE] variable_type
以上就可以定一个一维数组,我们举例代码如下:
var balance [10] float32
3.3.2 初始化数组
数组的初始化方式有不止一种方式,我们列举如下:
- 直接进行初始化:
var balance = [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0} - 通过字面量在声明数组的同时快速初始化数组:
balance := [5]float32{1000.0, 2.0, 3.4, 7.0, 50.0} - 数组长度不确定,编译器通过元素个数自行推断数组长度,在[ ]中填入
...,举例如下:var balance = [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0}和balance := [...]float32{1000.0, 2.0, 3.4, 7.0, 50.0} - 数组长度确定,指定下标进行部分初始化:
balanced := [5]float32(1:2.0, 3:7.0)
注意:
- 初始化数组中 {} 中的元素个数不能大于 [] 中的数字。
如果忽略 [] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大小。
3.3.3 go中的数组名意义
在c语言中我们知道数组名在本质上是数组中第一个元素的地址,而在go语言中,数组名仅仅表示整个数组,是一个完整的值,一个数组变量即是表示整个数组。
所以在go中一个数组变量被赋值或者被传递的时候实际上就会复制整个数组。如果数组比较大的话,这种复制往往会占有很大的开销。所以为了避免这种开销,往往需要传递一个指向数组的指针,这个数组指针并不是数组。关于数组指针具体在指针的部分深入的了解。
3.3.4 数组指针
通过数组和指针的知识我们就可以定义一个数组指针,代码如下:
var a = [...]int{1, 2, 3} // a 是一个数组
var b = &a // b 是指向数组的指针
数组指针除了可以防止数组作为参数传递的时候浪费空间,还可以利用其和for range来遍历数组,具体代码如下:
for i, v := range b { // 通过数组指针迭代数组的元素
fmt.Println(i, v)
}
具体关于go语言的循环语句我们在后文中再进行详细介绍。
3.4 结构体
通过上述数组的学习,我们就可以直接定义多个同类型的变量,但这往往也是一种限制,只能存储同一种类型的数据,而我们在结构体中就可以定义多个不同的数据类型。
3.4.1 声明结构体
在声明结构体之前我们首先需要定义一个结构体类型,这需要使用type和struct,type用于设定结构体的名称,struct用于定义一个新的数据类型。具体结构如下:
type struct_variable_type struct {
member definition
member definition
...
member definition
}
定义好了结构体类型,我们就可以使用该结构体声明这样一个结构体变量,语法如下:
variable_name := structure_variable_type {value1, value2...valuen}
variable_name := structure_variable_type { key1: value1, key2: value2..., keyn: valuen}
3.4.2 访问结构体成员
如果要访问结构体成员,需要使用点号 . 操作符,格式为:结构体变量名.成员名。举例代码如下:
package main
import "fmt"
type Books struct {
title string
author string
}
func main() {
var book1 Books
Book1.title = "Go 语言入门"
Book1.author = "mars.hao"
}
3.4.3 结构体指针
关于结构体指针的定义和申明同样可以套用前文中讲到的指针的相关定义,从而使用一个指针变量存放一个结构体变量的地址。
定义一个结构体变量的语法:var struct_pointer *Books。
这种指针变量的初始化和上文指针部分的初始化方式相同struct_pointer = &Book1,但是和c语言中有所不同,使用结构体指针访问结构体成员仍然使用.操作符。格式如下:struct_pointer.title
3.5 字符串
一个字符串是一个不可改变的字节序列,字符串通常是用来包含人类可读的文本数据。和数组不同的是,字符串的元素不可修改,是一个只读的字节数组。每个字符串的长度虽然也是固定的,但是字符串的长度并不是字符串类型的一部分。
3.5.1 字符串定义和初始化
Go语言字符串的底层结构在reflect.StringHeader中定义,具体如下:
type StringHeader struct {
Data uintptr
Len int
}
也就是说字符串结构由两个信息组成:第一个是字符串指向的底层字节数组,第二个是字符串的字节的长度。
字符串其实是一个结构体,因此字符串的赋值操作也就是reflect.StringHeader结构体的复制过程,并不会涉及底层字节数组的复制,所以我们也可以将字符串数组看作一个结构体数组。
字符串和数组类似,内置的len函数返回字符串的长度。
3.5.2 字符串UTF8编码
根据Go语言规范,Go语言的源文件都是采用UTF8编码。因此,Go源文件中出现的字符串面值常量一般也是UTF8编码的(对于转义字符,则没有这个限制)。提到Go字符串时,我们一般都会假设字符串对应的是一个合法的UTF8编码的字符序列。
Go语言的字符串中可以存放任意的二进制字节序列,而且即使是UTF8字符序列也可能会遇到坏的编码。如果遇到一个错误的UTF8编码输入,将生成一个特别的Unicode字符‘\uFFFD’,这个字符在不同的软件中的显示效果可能不太一样,在印刷中这个符号通常是一个黑色六角形或钻石形状,里面包含一个白色的问号‘�’。
下面的字符串中,我们故意损坏了第一字符的第二和第三字节,因此第一字符将会打印为“�”,第二和第三字节则被忽略;后面的“abc”依然可以正常解码打印(错误编码不会向后扩散是UTF8编码的优秀特性之一)。代码如下:
fmt.Println("\xe4\x00\x00\xe7\x95\x8cabc") // �界abc
不过在for range迭代这个含有损坏的UTF8字符串时,第一字符的第二和第三字节依然会被单独迭代到,不过此时迭代的值是损坏后的0:
// 0 65533 // \uFFFD, 对应 �
// 1 0 // 空字符
// 2 0 // 空字符
// 3 30028 // 界
// 6 97 // a
// 7 98 // b
// 8 99 // c
3.5.3 字符串的强制类型转换
在上文中我们知道源代码往往会采用UTF8编码,如果不想解码UTF8字符串,想直接遍历原始的字节码:
- 可以将字符串强制转为[]byte字节序列后再行遍历(这里的转换一般不会产生运行时开销):
- 采用传统的下标方式遍历字符串的字节数组
除此以外,字符串相关的强制类型转换主要涉及到[]byte和[]rune两种类型。每个转换都可能隐含重新分配内存的代价,最坏的情况下它们的运算时间复杂度都是O(n)。
不过字符串和[]rune的转换要更为特殊一些,因为一般这种强制类型转换要求两个类型的底层内存结构要尽量一致,显然它们底层对应的[]byte和[]int32类型是完全不同的内部布局,因此这种转换可能隐含重新分配内存的操作。
3.6 slice
简单地说,切片就是一种简化版的动态数组。因为动态数组的长度不固定,切片的长度自然也就不能是类型的组成部分了。数组虽然有适用它们的地方,但是数组的类型和操作都不够灵活,而切片则使用得相当广泛。
切片高效操作的要点是要降低内存分配的次数,尽量保证append操作(在后续的插入和删除操作中都涉及到这个函数)不会超出cap的容量,降低触发内存分配的次数和每次分配内存大小。
3.6.1 slice定义
我们先看看切片的结构定义,reflect.SliceHeader:
type SliceHeader struct {
Data uintptr // 指向底层的的数组指针
Len int // 切片长度
Cap int // 切片最大长度
}
和数组一样,内置的len函数返回切片中有效元素的长度,内置的cap函数返回切片容量大小,容量必须大于或等于切片的长度。
切片可以和nil进行比较,只有当切片底层数据指针为空时切片本身为nil,这时候切片的长度和容量信息将是无效的。如果有切片的底层数据指针为空,但是长度和容量不为0的情况,那么说明切片本身已经被损坏了
只要是切片的底层数据指针、长度和容量没有发生变化的话,对切片的遍历、元素的读取和修改都和数组是一样的。在对切片本身赋值或参数传递时,和数组指针的操作方式类似,只是复制切片头信息(reflect.SliceHeader),并不会复制底层的数据。对于类型,和数组的最大不同是,切片的类型和长度信息无关,只要是相同类型元素构成的切片均对应相同的切片类型。
当我们想定义声明一个切片时可以如下:
在对切片本身赋值或参数传递时,和数组指针的操作方式类似,只是复制切片头信息·(reflect.SliceHeader),并不会复制底层的数据。对于类型,和数组的最大不同是,切片的类型和长度信息无关,只要是相同类型元素构成的切片均对应相同的切片类型。
3.6.2 添加元素
append() :内置的泛型函数,可以向切片中增加元素。
- 在切片尾部追加N个元素
var a []int
a = append(a, 1) // 追加1个元素
a = append(a, 1, 2, 3) // 追加多个元素, 手写解包方式
a = append(a, []int{1,2,3}...) // 追加一个切片, 切片需要解包
注意:尾部添加在容量不足的条件下需要重新分配内存,可能导致巨大的内存分配和复制数据代价。即使容量足够,依然需要用append函数的返回值来更新切片本身,因为新切片的长度已经发生了变化。
- 在切片开头位置添加元素
var a = []int{1,2,3}
a = append([]int{0}, a...) // 在开头位置添加1个元素
a = append([]int{-3,-2,-1}, a...) // 在开头添加1个切片
注意:在开头一般都会导致内存的重新分配,而且会导致已有的元素全部复制1次。因此,从切片的开头添加元素的性能一般要比从尾部追加元素的性能差很多。
- append链式操作
var a []int
a = append(a[:i], append([]int{x}, a[i:]...)...) // 在第i个位置插入x
a = append(a[:i], append([]int{1,2,3}, a[i:]...)...) // 在第i个位置插入切片
每个添加操作中的第二个append调用都会创建一个临时切片,并将a[i:]的内容复制到新创建的切片中,然后将临时创建的切片再追加到a[:i]。
- append和copy组合
a = append(a, 0) // 切片扩展1个空间
copy(a[i+1:], a[i:]) // a[i:]向后移动1个位置
a[i] = x // 设置新添加的元素
第三个操作中会创建一个临时对象,我们可以借用copy函数避免这个操作,这种方式操作语句虽然冗长了一点,但是相比前面的方法,可以减少中间创建的临时切片。
3.6.3 删除元素
根据要删除元素的位置有三种情况:
- 从开头位置删除;
- 直接移动数据指针,代码如下:
a = []int{1, 2, 3, ...}
a = a[1:] // 删除开头1个元素
a = a[N:] // 删除开头N个元素
- 将后面的数据向开头移动,使用append原地完成(所谓原地完成是指在原有的切片数据对应的内存区间内完成,不会导致内存空间结构的变化)
a = []int{1, 2, 3, ...}
a = append(a[:0], a[1:]...) // 删除开头1个元素
a = append(a[:0], a[N:]...) // 删除开头N个元素
- 使用copy将后续数据向前移动,代码如下:
a = []int{1, 2, 3}
a = a[:copy(a, a[1:])] // 删除开头1个元素
a = a[:copy(a, a[N:])] // 删除开头N个元素
- 从中间位置删除;
对于删除中间的元素,需要对剩余的元素进行一次整体挪动,同样可以用append或copy原地完成:
- append删除操作如下:
a = []int{1, 2, 3, ...}
a = append(a[:i], a[i+1], ...)
a = append(a[:i], a[i+N:], ...)
- copy删除操作如下:
a = []int{1, 2, 3}
a = a[:copy(a[:i], a[i+1:])] // 删除中间1个元素
a = a[:copy(a[:i], a[i+N:])] // 删除中间N个元素
- 从尾部删除。
代码如下所示:
a = []int{1, 2, 3, ...}
a = a[:len(a)-1] // 删除尾部1个元素
a = a[:len(a)-N] // 删除尾部N个元素
删除切片尾部的元素是最快的
3.7 函数
为完成某一功能的程序指令(语句)的集合,称为函数。
3.7.1 函数分类
在Go语言中,函数是第一类对象,我们可以将函数保持到变量中。函数主要有具名和匿名之分,包级函数一般都是具名函数,具名函数是匿名函数的一种特例,当匿名函数引用了外部作用域中的变量时就成了闭包函数,闭包函数是函数式编程语言的核心。
举例代码如下:
- 具名函数:就和c语言中的普通函数意义相同,具有函数名、返回值以及函数参数的函数。
func Add(a, b int) int {
return a+b
}
- 匿名函数:指不需要定义函数名的一种函数实现方式,它由一个不带函数名的函数声明和函数体组成。
var Add = func(a, b int) int {
return a+b
}
解释几个名词如下:
- 闭包函数:返回为函数对象,不仅仅是一个函数对象,在该函数外还包裹了一层作用域,这使得,该函数无论在何处调用,优先使用自己外层包裹的作用域。
- 一级对象:支持闭包的多数语言都将函数作为第一级对象,就是说函数可以存储到变量中作为参数传递给其他函数,最重要的是能够被函数动态创建和返回。
- 包:go的每一个文件都是属于一个包的,也就是说go是以包的形式来管理文件和项目目录结构的。
3.7.2 函数声明和定义
Go 语言函数定义格式如下:
func fuction_name([parameter list])[return types]{
函数体
}
| 解析 | |
|---|---|
| func | 函数由func开始声明 |
| function_name | 函数名称 |
| parameter list | 参数列表 |
| return_types | 返回类型 |
| 函数体 | 函数定义的代码集合 |
3.7.3 函数传参
Go语言中的函数可以有多个参数和多个返回值,参数和返回值都是以传值的方式和被调用者交换数据。在语法上,函数还支持可变数量的参数,可变数量的参数必须是最后出现的参数,可变数量的参数其实是一个切片类型的参数。
当可变参数是一个空接口类型时,调用者是否解包可变参数会导致不同的结果,我们解释一下解包的含义,代码如下:
func main(){
var a = []int{1, 2, 3}
Print(a...) // 解包
Print(a) // 未解包
}
func Print(a ...int{}) {
fmt.Println(a...)
}
以上当传入参数为a...时即是对切片a进行了解包,此时其实相当于直接调用Print(1,2,3)。当传入参数直接为 a时等价于直接调用Print([]int{}{1,2,3})
3.7.4 函数返回值
不仅函数的参数可以有名字,也可以给函数的返回值命名。
举例代码如下:
func Find(m map[int]int, key int)(value int, ok bool) {
value,ok = m[key]
return
}
如果返回值命名了,可以通过名字来修改返回值,也可以通过defer语句在return语句之后修改返回值,举例代码如下:
func mian() {
for i := 0 ; i<3; i++ {
defer func() { println(i) }
}
}
// 该函数最终的输出为:
// 3
// 3
// 3
以上代码中如果没有defer其实返回值就是0,1,2,但defer语句会在函数return之后才会执行,也就是或只有以上函数在执行结束return之后才会执行defer语句,而该函数return时的i值将会达到3,所以最终的defer语句执行printlin的输出都是3。
defer语句延迟执行的其实是一个匿名函数,因为这个匿名函数捕获了外部函数的局部变量v,这种函数我们一般叫闭包。闭包对捕获的外部变量并不是传值方式访问,而是以引用的方式访问。
这种方式往往会带来一些问题,修复方法为在每一轮迭代中都为defer函数提供一个独有的变量,修改代码如下:
func main() {
for i := 0; i < 3; i++ {
i := i // 定义一个循环体内局部变量i
defer func(){ println(i) } ()
}
}
func main() {
for i := 0; i < 3; i++ {
// 通过函数传入i
// defer 语句会马上对调用参数求值
// 不再捕获,而是直接传值
defer func(i int){ println(i) } (i)
}
}
3.7.5 递归调用
Go语言中,函数还可以直接或间接地调用自己,也就是支持递归调用。Go语言函数的递归调用深度逻辑上没有限制,函数调用的栈是不会出现溢出错误的,因为Go语言运行时会根据需要动态地调整函数栈的大小。这部分的知识将会涉及goroutint和动态栈的相关知识,我们将会在之后的博文中向大家解释。
它的语法和c很相似,格式如下:
func recursion() {
recursion() /* 函数调用自身 */
}
func main() {
recursion()
}
3.8 方法
方法一般是面向对象编程(OOP)的一个特性,在C++语言中方法对应一个类对象的成员函数,是关联到具体对象上的虚表中的。但是Go语言的方法却是关联到类型的,这样可以在编译阶段完成方法的静态绑定。一个面向对象的程序会用方法来表达其属性对应的操作,这样使用这个对象的用户就不需要直接去操作对象,而是借助方法来做这些事情。
实现C语言中的一组函数如下:
// 文件对象
type File struct {
fd int
}
// 打开文件
func OpenFile(name string) (f *File, err error) {
// ...
}
// 关闭文件
func CloseFile(f *File) error {
// ...
}
// 读文件数据
func ReadFile(f *File, offset int64, data []byte) int {
// ...
}
以上的三个函数都是普通的函数,需要占用包级空间中的名字资源。不过CloseFile和ReadFile函数只是针对File类型对象的操作,这时候我们更希望这类函数和操作对象的类型紧密绑定在一起。
所以在go语言中我们修改如下:
// 关闭文件
func (f *File) CloseFile() error {
// ...
}
// 读文件数据
func (f *File) ReadFile(offset int64, data []byte) int {
// ...
}
将CloseFile和ReadFile函数的第一个参数移动到函数名的开头,这两个函数就成了File类型独有的方法了(而不是File对象方法)
从代码角度看虽然只是一个小的改动,但是从编程哲学角度来看,Go语言已经是进入面向对象语言的行列了。我们可以给任何自定义类型添加一个或多个方法。每种类型对应的方法必须和类型的定义在同一个包中,因此是无法给int这类内置类型添加方法的(因为方法的定义和类型的定义不在一个包中)。对于给定的类型,每个方法的名字必须是唯一的,同时方法和函数一样也不支持重载。
3.9 接口
3.9.1 什么是接口
Go 语言提供了另外一种数据类型即接口,它把所有的具有共性的方法定义在一起,任何其他类型只要实现了这些方法就是实现了这个接口。
Go的接口类型是对其它类型行为的抽象和概括;因为接口类型不会和特定的实现细节绑定在一起,通过这种抽象的方式我们可以让对象更加灵活和更具有适应能力。很多面向对象的语言都有相似的接口概念,但Go语言中接口类型的独特之处在于它是满足隐式实现的鸭子类型。
所谓鸭子类型说的是:只要走起路来像鸭子、叫起来也像鸭子,那么就可以把它当作鸭子。Go语言中的面向对象就是如此,如果一个对象只要看起来像是某种接口类型的实现,那么它就可以作为该接口类型使用。
就比如说在c语言中,使用printf在终端输出的时候只能输出有限类型的几个变量,而在go中可以使用fmt.Printf,实际上是fmt.Fprintf向任意自定义的输出流对象打印,甚至可以打印到网络甚至是压缩文件,同时打印的数据不限于语言内置的基础类型,任意隐士满足fmt.Stringer接口的对象都可以打印,不满足fmt.Stringer接口的依然可以通过反射的技术打印。
3.9.2 结构体类型
interface实际上就是一个结构体,包含两个成员。其中一个成员是指向具体数据的指针,另一个成员中包含了类型信息。空接口和带方法的接口略有不同,下面分别是空接口的数据结构:
struct Eface
{
Type* type;
void* data;
};
其中的Type指的是:
struct Type
{
uintptr size;
uint32 hash;
uint8 _unused;
uint8 align;
uint8 fieldAlign;
uint8 kind;
Alg *alg;
void *gc;
String *string;
UncommonType *x;
Type *ptrto;
};
和带方法的接口使用的数据结构:
struct Iface
{
Itab* tab;
void* data;
};
其中的Iface指的是:
struct Itab
{
InterfaceType* inter;
Type* type;
Itab* link;
int32 bad;
int32 unused;
void (*fun[])(void); // 方法表
};
3.9.3 具体类型向接口类型赋值
将一个具体类型数据赋值给interface这样的抽象类型,需要进行类型转换。这个转换过程中涉及哪些操作呢?
如果转换为空接口,返回一个Eface,将Eface中的data指针指向原型数据,type指针会指向数据的Type结构体。
如果将其转化为带方法的interface,需要进行一次检测,该类型必须实现interface中声明的所有方法才可以进行转换,这个检测将会在编译过程中进行。检测过程具体实现式通过比较具体类型的方法表和接口类型的方法表来进行的。
- 具体类型方法表:Type的UncommonType中有一个方法表,某个具体类型实现的所有方法都会被收集到这张表中。
- 接口类型方法表:Iface的Itab的InterfaceType中也有一张方法表,这张方法表中是接口所声明的方法。Iface中的Itab的func域也是一张方法表,这张表中的每一项就是一个函数指针,也就是只有实现没有声明。
这两处方法表都是排序过的,只需要一遍顺序扫描进行比较,应该可以知道Type中否实现了接口中声明的所有方法。最后还会将Type方法表中的函数指针,拷贝到Itab的fun字段中。Iface中的Itab的func域也是一张方法表,这张表中的每一项就是一个函数指针,也就是只有实现没有声明。
3.9.4 获取接口类型数据的具体类型信息
接口类型转换为具体类型(也就是反射,reflect),也涉及到了类型转换。reflect包中的TypeOf和ValueOf函数来得到接口变量的Type和Value。
3.10 channel
3.10.1 相关结构体定义
go中的channel是可以被存储在变量中,可以作为参数传递给函数,也可以作为函数返回值返回,我们先来看一下channel的结构体定义:
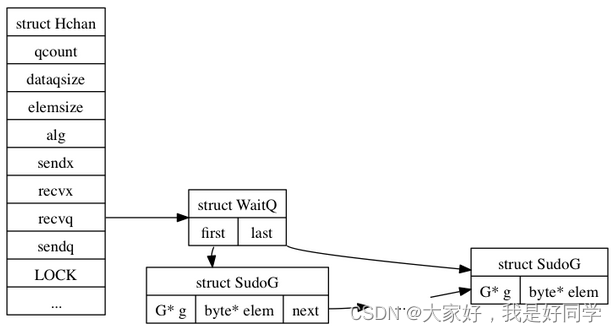
struct Hchan
{
uintgo qcount; // 队列q中的总数据数量
uintgo dataqsize; // 环形队列q的数据大小
uint16 elemsize; // 当前队列的使用量
bool closed;
uint8 elemalign;
Alg* elemalg; // interface for element type
uintgo sendx; // 发送index
uintgo recvx; // 接收index
WaitQ recvq; // 因recv而阻塞的等待队列
WaitQ sendq; // 因send而阻塞的等待队列
Lock;
};
Hchan结构体中的核心部分是存放channel数据的环形队列,相关数据的作用已经在其后做出了备注。在该结构体中没有存放数据的域,如果是带缓冲区的chan,则缓冲区数据实际上是紧接着Hchan结构体中分配的。
另一个重要部分就是recvq和sendq两个链表,一个是因读这个通道而导致阻塞的goroutine,另一个是因为写这个通道而阻塞的goroutine。如果一个goroutine阻塞于channel了,那么它就被挂在recvq或sendq中。WaitQ是链表的定义,包含一个头结点和一个尾结点,该链表中中存放的成员是一个sudoG结构体变量,具体定义如下:
struct SudoG
{
G* g; // g and selgen constitute
uint32 selgen; // a weak pointer to g
SudoG* link;
int64 releasetime;
byte* elem; // data element
};
该结构体中最主要的是g和elem。elem用于存储goroutine的数据。读通道时,数据会从Hchan的队列中拷贝到SudoG的elem域。写通道时,数据则是由SudoG的elem域拷贝到Hchan的队列中。
Hchan结构如下:
3.10.2 阻塞式读写channel操作
写操作代码如下,其中的c就是channel,v指的是数据:
c <- v
事实上基本的阻塞模式写channel操作在底层运行时库中对应的是一个runtime.chansend函数。具体如下:
void runtime·chansend(ChanType *t, Hchan *c, byte *ep, bool *pres, void *pc)
其中的ep指的是变量v的地址,这里的传值约定是调用者负责分配好ep的空间,仅需要简单的取变量地址就好了,pres是在select中的通道操作中使用的。
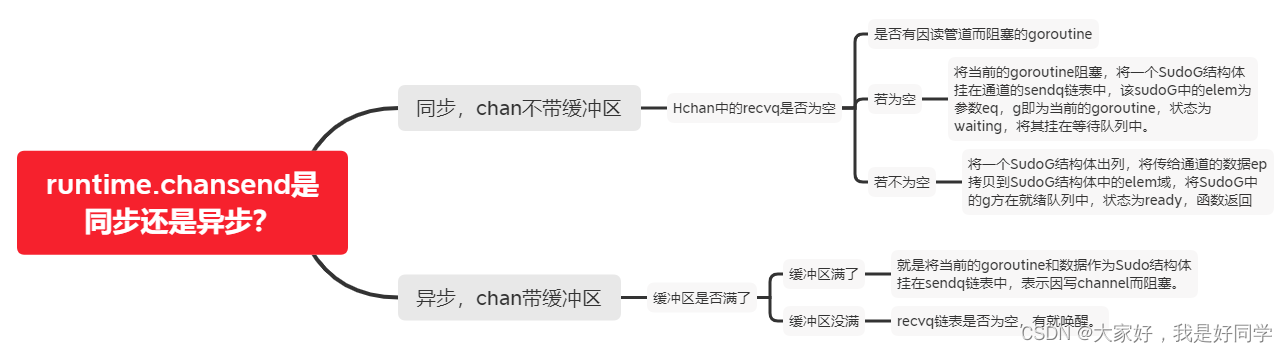
阻塞模式读操作的核心函数有两种包装如下:
chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool)
以及
chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected)
这两种的区别主要在于返回值是否会返回一个bool类型值,该值只是用于判断channel是否能读取出数据。
读写操作的以上阻塞的过程类似,故而不再做出说明,我们补充三个细节:
- 以上我们都强调是阻塞式的读写操作,其实相对应的也有非阻塞的读写操作,使用过select-case来进行调用的。
- 空通道,指的是将一个channel赋值为nil,或者调用后不适用make进行初始化。读写空通道是永远阻塞的。
- 关闭的通道,永远不会阻塞,会返回一个通道数据类型的零值。首先将closed置为1,第二步收集读等待队列recvq的所有sg,每个sg的elem都设为类型零值,第三步收集写等待队列sendq的所有sg,每个sg的elem都设为nil,最后唤醒所有收集的sg。
3.10.3 非阻塞式读写channel操作
如上文所说,非阻塞式其实就是使用select-case来实现,在编译时将会被编译为if-else。
如:
select {
case v = <-c:
...foo
default:
...bar
}
就会被编译为:
if selectnbrecv(&v, c) {
...foo
} else {
...bar
}
至于其中的selectnbrecv相关的函数简单地调runtime.chanrecv函数,设置了一个参数,告诉runtime.chanrecv函数,当不能完成操作时不要阻塞,而是返回失败。
但是select中的case的执行顺序是随机的,而不像switch中的case那样一条一条的顺序执行。让每一个select都对应一个Select结构体。在Select数据结构中有个Scase数组,记录下了每一个case,而Scase中包含了Hchan。然后pollorder数组将元素随机排列,这样就可以将Scase乱序了。
3.11 map
map表的底层原理是哈希表,其结构体定义如下:
type Map struct {
Key *Type // Key type
Elem *Type // Val (elem) type
Bucket *Type // 哈希桶
Hmap *Type // 底层使用的哈希表元信息
Hiter *Type // 用于遍历哈希表的迭代器
}
其中的Hmap 的具体化数据结构如下:
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // map目前的元素数目
flags uint8 // map状态(正在被遍历/正在被写入)
B uint8 // 哈希桶数目以2为底的对数(哈希桶的数目都是 2 的整数次幂,用位运算来计算取余运算的值, 即 N mod M = N & (M-1)))
noverflow uint16 //溢出桶的数目, 这个数值不是恒定精确的, 当其 B>=16 时为近似值
hash0 uint32 // 随机哈希种子
buckets unsafe.Pointer // 指向当前哈希桶的指针
oldbuckets unsafe.Pointer // 扩容时指向旧桶的指针
nevacuate uintptr // 桶进行调整时指示的搬迁进度
extra *mapextra // 表征溢出桶的变量
}
以上hmap基本都是涉及到了哈希桶和溢出桶,我们首先看一下它的数据结构,如下:
type bmap struct {
topbits [8]uint8 // 键哈希值的高8位
keys [8]keytype // 哈希桶中所有键
elems [8]elemtype // 哈希桶中所有值
//pad uintptr(新的 go 版本已经移除了该字段, 我未具体了解此处的 change detail, 之前设置该字段是为了在 nacl/amd64p32 上的内存对齐)
overflow uintptr
}
我们会发现哈希桶bmap一般指定其能保存8个键值对,如果多于8个键值对,就会申请新的buckets,并将其于之前的buckets链接在一起。
其中的联系如图所示:
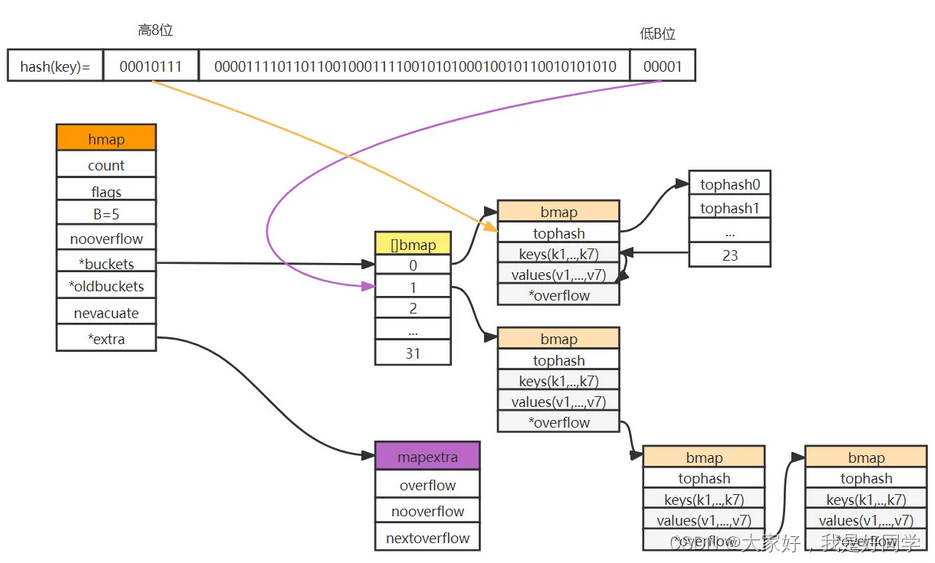
在具体插入时,首先会根据key值采用相应的hash算法计算对应的哈希值,将哈希值的低8位作为Hmap结构体中buckets数组的索引,找到key值所对应的bucket,将哈希值的高8位催出在bucket的tophash中。
特点如下:
- map是无序的(原因为无序写入以及扩容导致的元素顺序发生变化),每次打印出来的map都会不一样,它不能通过index获取,而必须通过key获取
- map的长度是不固定的,也就是和slice一样,也是一种引用类型
- 内置的len函数同样适用于map,返回map拥有的key的数量
- map的key可以是所有可比较的类型,如布尔型、整数型、浮点型、复杂型、字符串型……也可以键。
如下方式即可进行初始化:
var a map[keytype]valuetype
| 类型名 | 意义 |
|---|---|
| a | map表名字 |
| keytype | 键类型 |
| valuetype | 键对应的值的类型 |
除此以外还可以使用make进行初始化,代码如下:
map_variable = make(map[key_data_type]value_data_type)
我们还可以使用初始值进行初始化,如下:
var m map[string]int = map[string]int{"hunter":12,"tony":10}
3.11.1 插入数据
map的数据插入代码如下:
map_variable["mars"] = 27
插入过程如下:
- 根据key值计算出哈希值
- 取哈希值低位和hmap.B取模确定bucket位置
- 查找该key是否已经存在,如果存在则直接更新值
- 如果没有找到key,则将这一对key-value插入
3.11.2 删除数据
delete(map, key) 函数用于删除集合的元素, 参数为 map 和其对应的 key。删除函数不返回任何值。相关代码如下:
countryCapitalMap := map[string] string {"France":"Paris","Italy":"Rome","Japan":"Tokyo","India":"New Delhi"}
/* 删除元素 */
delete(countryCapitalMap,"France");
3.11.3 查找数据
通过key获取map中对应的value值。语法为:map[key] .但是当key如果不存在的时候,我们会得到该value值类型的默认值,比如string类型得到空字符串,int类型得到0。但是程序不会报错。
所以我们可以使用ok-idiom获取值,如下:value, ok := map[key] ,其中的value是返回值,ok是一个bool值,可知道key/value是否存在。
在map表中的查找过程如下:
- 查找或者操作map时,首先key经过hash函数生成hash值
- 通过哈希值的低8位来判断当前数据属于哪个桶
- 找到桶之后,通过哈希值的高八位与bucket存储的高位哈希值循环比对
- 如果相同就比较刚才找到的底层数组的key值,如果key相同,取出value
- 如果高八位hash值在此bucket没有,或者有,但是key不相同,就去链表中下一个溢出bucket中查找,直到查找到链表的末尾
- 如果查找不到,也不会返回空值,而是返回相应类型的0值。
3.11.4 扩容
哈希表就是以空间换时间,访问速度是直接跟填充因子相关的,所以当哈希表太满之后就需要进行扩容。
如果扩容前的哈希表大小为2B扩容之后的大小为2(B+1),每次扩容都变为原来大小的两倍,哈希表大小始终为2的指数倍,则有(hash mod 2B)等价于(hash & (2B-1))。这样可以简化运算,避免了取余操作。
触发扩容的条件?
- 负载因子(负载因子 = 键数量/bucket数量) > 6.5时,也即平均每个bucket存储的键值对达到6.5个。
- 溢出桶(overflow)数量 > 2^15时,也即overflow数量超过32768时。
什么是增量扩容呢?
如果负载因子>6.5时,进行增量扩容。这时会新建一个桶(bucket),新的bucket长度是原来的2倍,然后旧桶数据搬迁到新桶。每个旧桶的键值对都会分流到两个新桶中
主要是缩短map容器的响应时间。假如我们直接将map用作某个响应实时性要求非常高的web应用存储,如果不采用增量扩容,当map里面存储的元素很多之后,扩容时系统就会卡往,导致较长一段时间内无法响应请求。不过增量扩容本质上还是将总的扩容时间分摊到了每一次哈希操作上面。
什么是等量扩容?它的触发条件是什么?进行等量扩容后的优势是什么?
等量扩容,就是创建和旧桶数目一样多的新桶,然后把原来的键值对迁移到新桶中,重新做一遍类似增量扩容的搬迁动作。
触发条件:负载因子没超标,溢出桶较多。这个较多的评判标准为:
- 如果常规桶数目不大于2^15,那么使用的溢出桶数目超过常规桶就算是多了;
- 如果常规桶数目大于215,那么使用溢出桶数目一旦超过215就算多了。
这样做的目的是把松散的键值对重新排列一次,能够存储的更加紧凑,进而减少溢出桶的使用,以使bucket的使用率更高,进而保证更快的存取。
4. 常用语句及关键字
接下来我们了解一下关于go语言语句的基本内容。
4.1 条件语句
和c语言类似,相关的条件语句如下表所示:
| 语句 | 描述 |
|---|---|
| if 语句 | if 语句 由一个布尔表达式后紧跟一个或多个语句组成。 |
| if…else 语句 | if 语句 后可以使用可选的 else 语句, else 语句中的表达式在布尔表达式为 false 时执行。 |
| switch 语句 | switch 语句用于基于不同条件执行不同动作。 |
| select 语句 | select 语句类似于 switch 语句,但是select会随机执行一个可运行的case。如果没有case可运行,它将阻塞,直到有case可运行。 |
- if语句
语法如下:
if 布尔表达式 {
/* 在布尔表达式为 true 时执行 */
}
- if-else语句
if 布尔表达式 {
/* 在布尔表达式为 true 时执行 */
} else {
/* 在布尔表达式为 false 时执行 */
}
- switch语句
其中的变量v可以是任何类型,val1和val2可以是同类型的任意值,类型不局限为常量或者整数,或者最终结果为相同类型的表达式。
switch v {
case val1:
...
case val2:
...
default:
...
}
- select语句
select 是 Go 中的一个控制结构,类似于用于通信的 switch 语句。每个 case 必须是一个通信操作,要么是发送要么是接收。它将会随机执行一个可运行的 case。如果没有 case 可运行,它将阻塞,直到有 case 可运行。一个默认的子句应该总是可运行的。
select {
case communication clause :
statement(s);
case communication clause :
statement(s);
/* 你可以定义任意数量的 case */
default : /* 可选 */
statement(s);
}
注意:
- 每个case必须都是一个通信
- 所有channel表达式都会被求值,所有被发送的表达式都会被求值
- 如果任意某一个通信都可以,它就执行,其他就忽略
- 如果有多个case都可以运行,select就会随机挑选一个来执行。
- 如果没有一个case可以被运行:如果有default子句,就执行default子句,select将被阻塞,直到某个通信可以运行,从而避免饥饿问题。
4.2 循环语句
4.2.1 循环处理语句
go中时使用for实现循环的,共有三种形式:
| 语法 | |
|---|---|
| 和c语言中的for相同 | for init; condition; post {} |
| 和c语言中的while相同 | for condition{} |
和c语言中的for(;;)相同 | for{} |
除此以外,for循环还可以直接使用range对slice、map、数组以及字符串等进行迭代循环,格式如下:
for key, value := range oldmap {
newmap[key] = value
}
4.2.1 循环控制语句
| 控制语句 | 详解 |
|---|---|
| break | 中断跳出循环或者switch语句 |
| continue | 跳过当前循环的剩余语句,然后继续下一轮循环 |
| goto语句 | 将控制转移到被标记的语句 |
- break
break主要用于循环语句跳出循环,和c语言中的使用方式是相同的。且在多重循环的时候还可以使用label标出想要break的循环。
实例代码如下:
a := 0
for a<5 {
fmt.Printf("%d\n", a)
a++
if a==2 {
break;
}
}
/* output
0
1
2
*/
- continue
Go 语言的 continue 语句 有点像 break 语句。但是 continue 不是跳出循环,而是跳过当前循环执行下一次循环语句。在多重循环中,可以用标号 label 标出想 continue 的循环。
实例代码如下:
// 不使用标记
fmt.Println("---- continue ---- ")
for i := 1; i <= 3; i++ {
fmt.Printf("i: %d\n", i)
for i2 := 11; i2 <= 13; i2++ {
fmt.Printf("i2: %d\n", i2)
continue
}
}
/* output
i: 1
i2: 11
i2: 12
i2: 13
i: 2
i2: 11
i2: 12
i2: 13
i: 3
i2: 11
i2: 12
i2: 13
*/
// 使用标记
fmt.Println("---- continue label ----")
re:
for i := 1; i <= 3; i++ {
fmt.Printf("i: %d", i)
for i2 := 11; i2 <= 13; i2++ {
fmt.Printf("i2: %d\n", i2)
continue re
}
}
/* output
i: 1
i2: 11
i: 2
i2: 11
i: 3
i2: 11
*/
- goto
goto语句主要是无条件转移到过程中指定的行。goto语句通常和条件语句配合使用,可用来实现条件转移、构成循环以及跳出循环体等功能。但是并不主张使用goto语句,以免造成程序流程混乱。
示例代码如下:
var a int = 0
LOOP: for a<5 {
if a == 2 {
a = a+1
goto LOOP
}
fmt.Printf("%d\n", a)
a++
}
/*
output:
0
1
2
3
4
*/
以上代码中的LOOP就是一个标签,当运行到goto语句的时候,此时执行流就会跳转到LOOP标志的哪一行上。
4.3 关键字
我们这一部分直接列表供大家了解go中的关键字如下:
| 关键字 | 用法 |
|---|---|
| import | 导入相应的包文件 |
| package | 创建包文件,用于标记该文件归属哪个包 |
| chan | channal,通道 |
| var | 变量控制,用于简短声明定义变量(:=符号只能在函数内部使用,不能全局使用) |
| const | 常量声明,任何时候const和var都可以同时出现 |
| func | 定义函数和方法 |
| interface | 接口,是一种具有一组方法的类型,这些方法定义了interface的行为 |
| map | 哈希表 |
| struct | 定义结构体 |
| type | 声明类型,取别名 |
| for | for是go中唯一的循环结构,上文中已经介绍过它的用法 |
| break | 中止,跳出循环 |
| continue | 继续下一轮循环 |
| select | 选择流程,可以同时等待多个通道操作 |
| switch | 多分枝选择,上文中已经详细介绍过它的用法 |
| case | 和switch配套使用 |
| default | 用于选择结构的默认选型 |
| defer | 用于资源释放,会在函数返回之前进行调用 |
| if | 分支选择 |
| else | 和if配套使用 |
| go | 通过go func()来开启一个goroutine |
| goto | 跳转至标志点的代码块,不推荐使用 |
| fallthrouth | |
| range | 用于遍历slice类型数据 |
| return | 用于标注函数返回值 |






![[隐私计算实训营学习笔记] 第1讲 数据要素流通](https://img-blog.csdnimg.cn/direct/a13ba60cc0f5489bb77d3d8f815d010e.png#pic_center)