👦个人主页:@Weraphael
✍🏻作者简介:目前学习计网、mysql和算法
✈️专栏:MySQL学习
🐋 希望大家多多支持,咱一起进步!😁
如果文章对你有帮助的话
欢迎 评论💬 点赞👍🏻 收藏 📂 加关注✨
目录
- 一、数据库的基本概念
- 1.1 区分mysql和mysqld
- 1.2 数据库存储介质
- 二、见见猪跑
- 2.1 连接数据库
- 2.2 使用案例
- 三、服务器、数据库、表关系
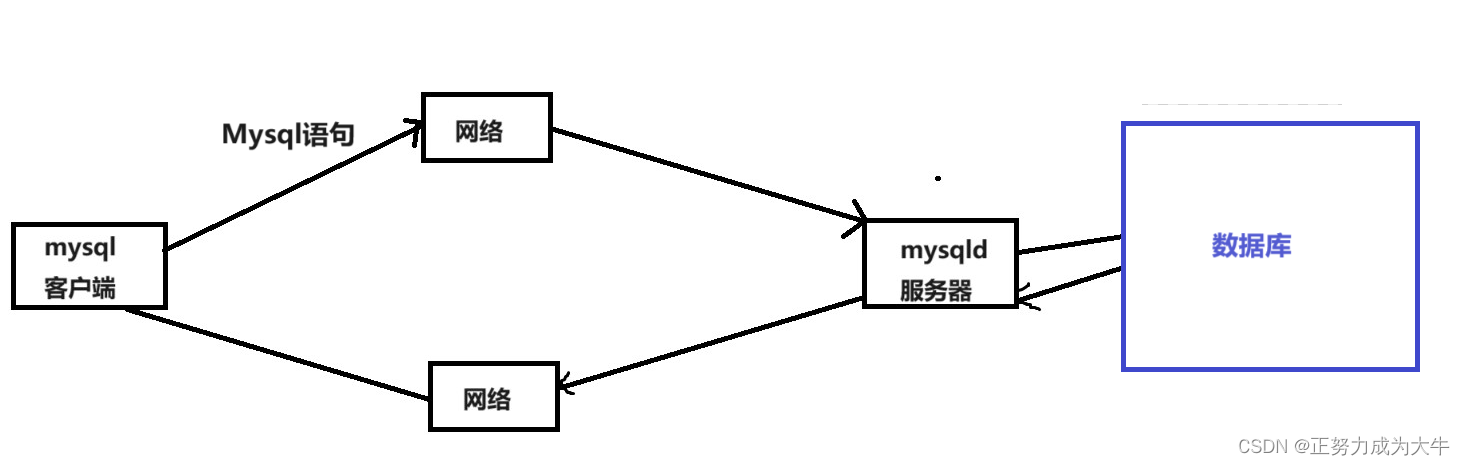
- 四、MySQL架构
- 五、Mysql语句分类
- 六、 存储引擎
一、数据库的基本概念
1.1 区分mysql和mysqld
我们在连接MySQL服务器的时候使用mysql命令;而启动MySQL服务时又使用mysqld,它们的区别是什么呢?
-
mysql:数据库服务的客户端。 -
mysqld:数据库服务的服务端(服务器)。负责接收客户端请求,然后处理数据库操作、维护数据等核心功能。当启动MySQL服务器时,实际上就是在运行mysqld进程。
因此,数据库其实是一种 基于 CS 模式的网络服务,是一套提供数据存储服务的网络程序。用户只需要通过客户端向服务器发出 SQL 语句,然后等待服务器将数据返回即可。
CS:首先它是客户端Client和服务器Server开头首字母的缩写。因此,客户端C代表mysql,服务器S代表mysqld
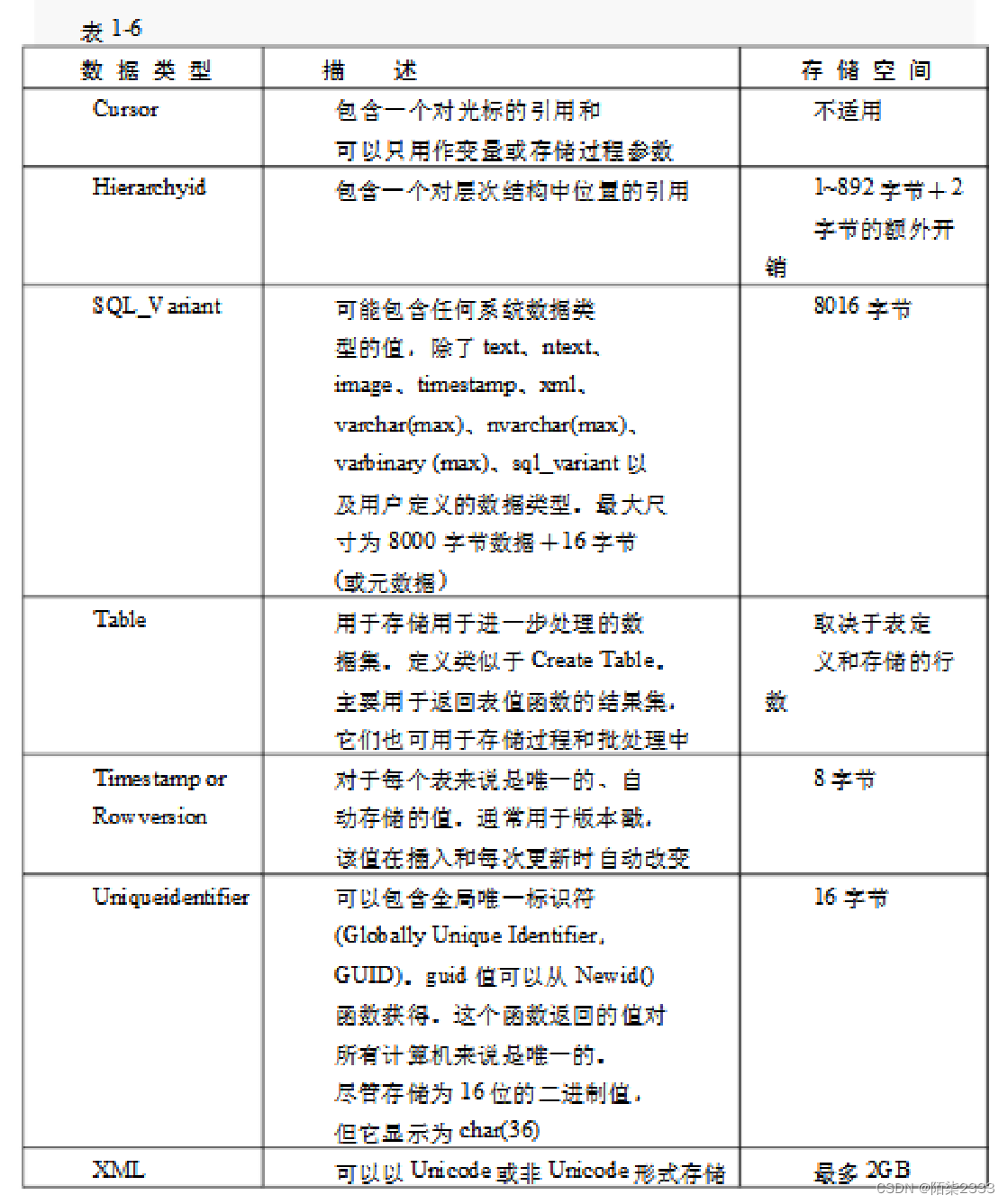
1.2 数据库存储介质
那么数据库中的数据是以什么样的形式存储的呢?
实际上,
MySQL中的数据就是以文件的形式存储在磁盘上的。这些文件可不是一般的文件,它包括数据库文件、表文件等。当在MySQL中创建新的数据库、表,或者进行数据操作时,数据会被写入这些文件中。这样的设计可以确保数据持久化,即使服务器重新启动或断电,数据仍然可以被恢复。
那么为什么不能简单地把数据以普通文件的形式存储,而使用专门的数据库管理系统?
普通文件确实提供了数据存储功能,但并没有提供很好的数据管理能力(只提供读写),比如对一个
10亿行的文档的内容要求快速增删查改某个字段,那么要遍历文件信息,效率是非常低的(文件对内容管理效率低下)
而 数据库是在磁盘上对数据内容存储了一套解决方案,用户只需给数据库字段或要求,然后等待数据库直接给用户返回结果就行。具备简单、高效、可靠管理数据的特性,可以轻而易举的对数据进行操作。

二、见见猪跑
2.1 连接数据库
- 连接数据库前需要确保
MySQL服务已启动
systemctl start musqld
- 连接数据库
mysql -h IP地址 -P 端口号 -u 用户 -p
选项说明:
-
-h指定要连接的MySQL服务器的IP地址。默认情况下,127.0.0.1是本地IP -
-P指定要连接的MySQL服务器的端口号。默认情况下,MySQL使用3306端口号;当然了,也可以自己在my.cnf配置文件中修改端口号。 vim /etc/my.cnf 修改完后需要手动重启MySQL服务,以便配置文件生效 systemctl restart mysqld -
-u:指定登录用户。 -
-p:登录MySQL需要输入密码。后面也能跟密码,如-p密码
指令也可以简写成如下
mysql -u root -p
2.2 使用案例
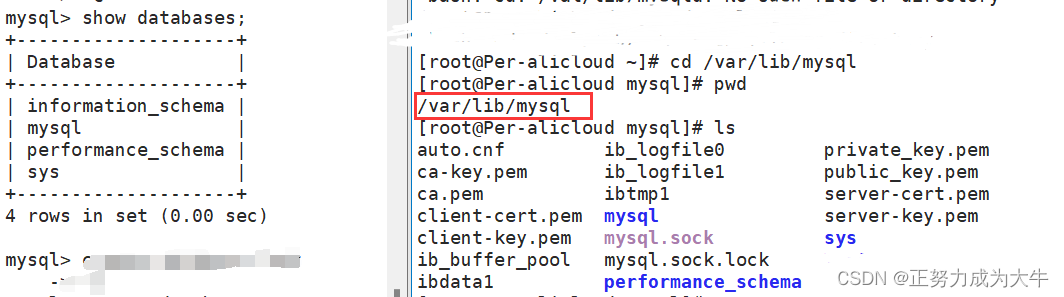
- 查看当前服务器上的数据库
show databases;
# 分号不能省略

我们在配置数据库文件时说过,mysql数据存放的路径在/var/lib/mysql
- 创建数据库
create database [名称];
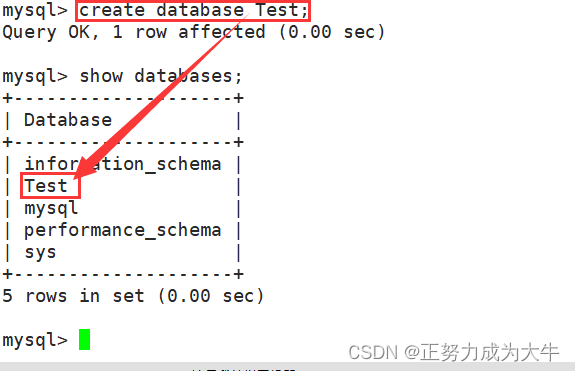
我们可以对比没建立此数据库之前,确实/var/lib/mysql路径下增加了[Test]目录。因此,建立数据库本质就是在Linux中新建一个目录。
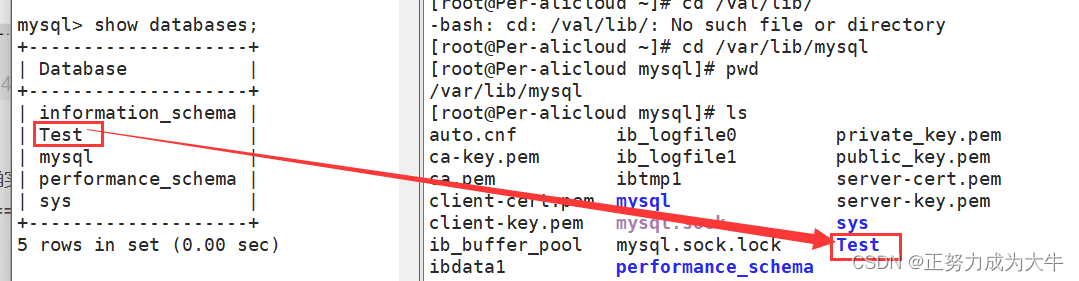
- 创建数据库表
在这么多数据库列表中,首先要确定使用哪个数据库
use [数据库名称];
然后再创建数据库表
create table [表名](
id int,
name varchar(32),
gender varchar(32)
);
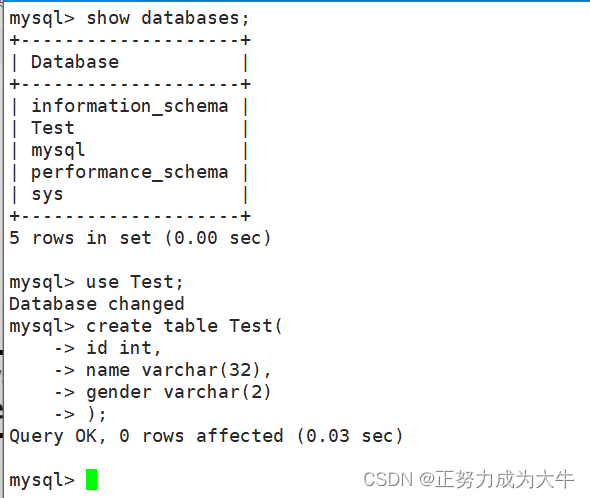
我们可以再次看看Test目录下有什么变化

从以上图片可以看到目录下确实多了一个名为 [Test] 的相关文件。因此,创建数据库表的本质是在Linux下创建文件
结合以上操作,我们得出:数据库本质也是文件!只不过这些文件不需要程序员直接操作,而是由数据库服务mysqld在帮我们操作
- 向表中插入数据
insert into student (id, name, gender) values (1, '张三', '男');
insert into student (id, name, gender) values (2, '李四', '女');
insert into student (id, name, gender) values (3, '王五', '男');
- 查询表中的数据
select * from [表名];
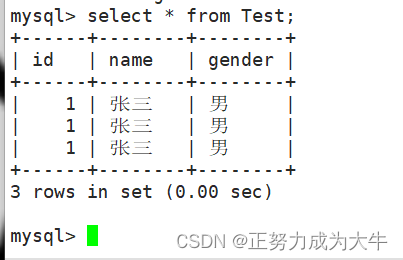
- 清屏操作
system clear;
- 退出
quit;
# exit;
三、服务器、数据库、表关系
从以上案例可以得出:数据库呈现结果通常以表格的形式展示,这是因为关系型数据库使用了关系型数据模型,而表格是关系型数据模型中最基本的数据组织形式。
而表格形式符合人们对数据的直观认知,便于我们快速查看数据信息
-
行:代表一个记录或实体
-
列:代表一个字段或属性

在关系型数据库中,服务器承担着提供数据存储和处理能力的角色,数据库负责组织和存储数据,而表则是数据的具体载体,用于存储和管理实际的数据记录。这三者之间的关系可以理解为:服务器上托管了一个或多个数据库,每个数据库中包含了多个表,而表则包含了实际的数据记录。
四、MySQL架构
MySQL是一个可移植的数据库,几乎能在当前所有的操作系统上运行,如Unix/Linux、Windows、Mac等。各种系统在底层实现方面各有不同,但是 MySQL 基本上能保证在各个平台上的物理体系结构的一致性。
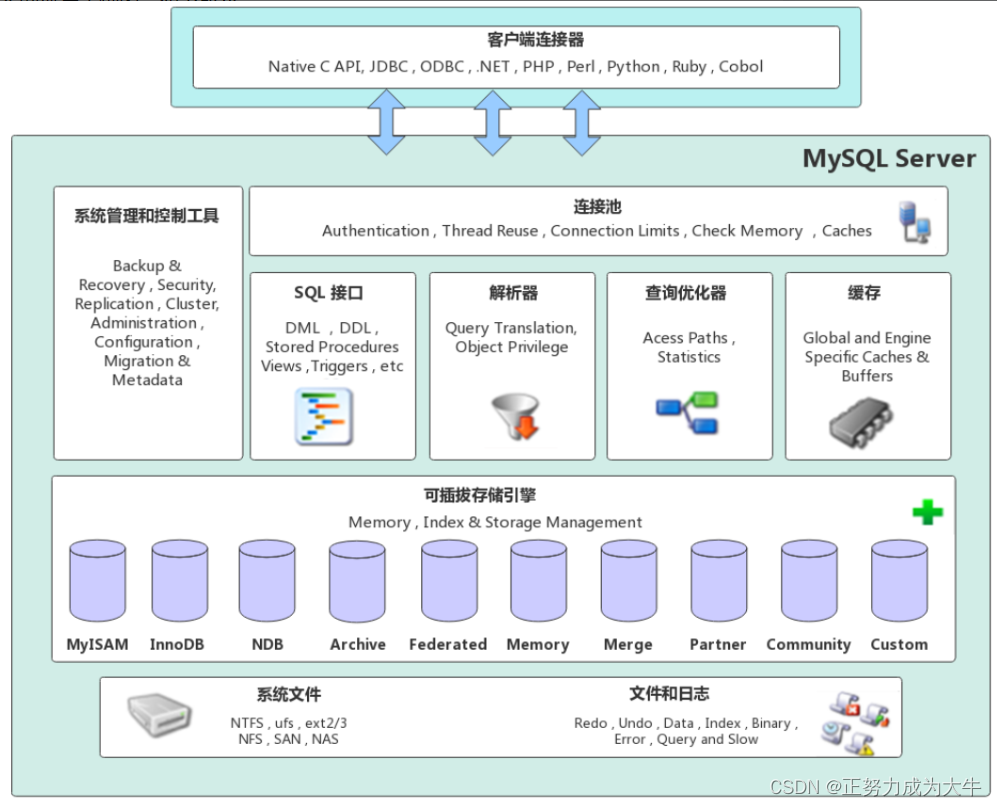
-
连接池: 用于管理客户端与服务器之间的连接。连接池负责处理客户端请求的连接管理,包括连接的建立、维护和释放,以提高数据库访问的效率和性能。
-
管理服务和工具: 包括各种管理和监控工具,用于配置、监视和管理
MySQL服务器实例的运行状态和参数设置。 -
解析器: 负责解析和分析客户端提交的
SQL查询语句。 -
查询优化器: 用于对查询执行计划进行优化,选择最佳的查询执行策略,以提高查询性能和效率。
-
缓存: 包括查询缓存和数据缓冲池,用于缓存查询结果和数据页,减少磁盘
I/O操作,提高数据访问速度。 -
存储引擎: 如何存储数据、管理索引、处理事务等功能。
-
日志组件: 记录数据库操作日志,包括事务日志、错误日志、慢查询日志等,用于数据恢复、故障排查和性能优化。
五、Mysql语句分类
MySQL语句可以根据其功能和用途分为多个主要分类,常见的分类包括:
- 数据操作语句(Data Manipulation Language,DML):用来维护存储数据的结构,常用于对数据库、表进行操作。
select # 用于从数据库中检索数据。
insert # 用于向数据库表中插入新记录。
update # 用于更新数据库表中的记录。
delete # 用于从数据库表中删除记录。
- 数据定义语句(Data Definition Language,DDL):用来对数据进行操作,比如对表中的数据进行增删改查。
create # 用于创建数据库对象,如表、索引等。
alter # 用于修改数据库对象的结构。
drop # 用于删除数据库对象。
- 数据控制语句(Data Control Language,DCL):主要负责权限和事务的管理,可以给用户赋予数据库的权限
grant # 用于赋予用户权限。
revoke # 用于撤销用户权限。
六、 存储引擎
- 存储引擎:数据库管理系统如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法
MySQL的核心就是插件式存储引擎,支持多种存储引擎。
MySQL中可以选择使用不同的存储引擎,不同的存储引擎所带来的效果不同
如何查看当前支持哪些存储引擎?
show engines;
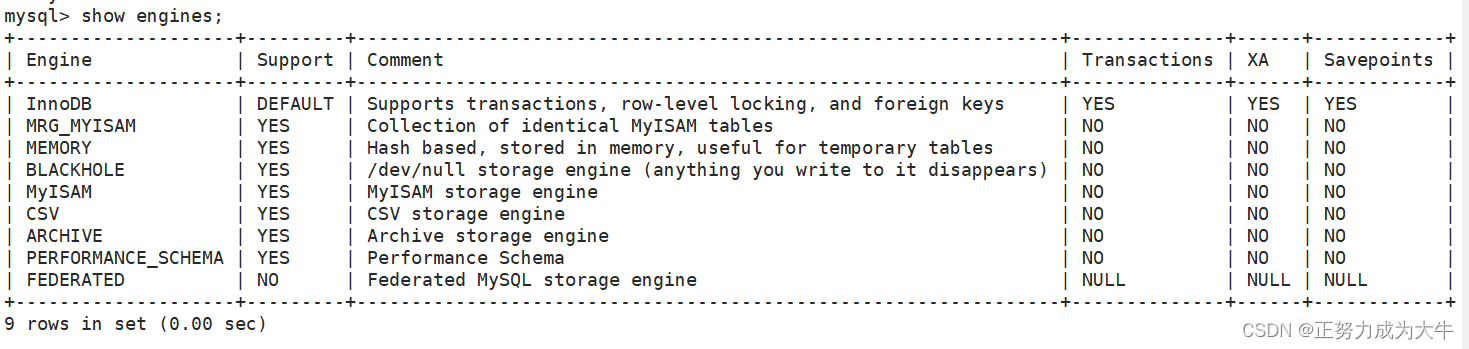
存储引擎有很多,主要记住两个就行了:InnoDB 和 MyISAM,至于它们的区别:
InnoDB适合需要事务支持、数据完整性和高并发性能的应用MyISAM可能适用于只读数据、全文搜索或特定用途的应用


![Unicode转码 [ASIS 2019]Unicorn shop1](https://img-blog.csdnimg.cn/direct/61dafcee5ff64e1c94a6d331cf758c4d.png)